AWK Lecture.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

BFP Test Form
BACKFLOW PREVENTION ASSEMBLY CITY OF PHILADELPHIA TEST AND MAINTENANCE RECORD PHILADELPHIA WATER DEPARTMENT THIS FORM (79-770) MUST BE COMPLETED BY A CITY CERTIFIED TECHNICIAN I. GENERAL INFORMATION ORIENTATION ACCOUNT OR METER # NAME OF FACILITY ADDRESS ZIP CONTACT PERSON AT FACILITY TITLE TELEPHONE NO. LOCATION OF ASSEMBLY DATE OF INSTALLATION INCOMING LINE PRESSURE MANUFACTURER MODEL SERIAL NUMBER SIZE □ DS □ RPZ □ FS □ DCV II. TEST INSTRUMENT CALIBRATION INFORMATION TYPE OF INSTRUMENT MODEL SERIAL NUMBER PURCHASE DATE CALIBRATED BY TELEPHONE NO. REGISTRATION NO. CALIBRATED ON NEXT CALIBRATION DUE III. TESTS & REPAIRS INFORMATION CHECK VALVE NUMBER 1 CHECK VALVE NUMBER 2 DIFFERENTIAL PRESSURE RELIEF VALVE □ LEAKED □ LEAKED □ CLOSED TIGHT □ CLOSED TIGHT □ OPEN AT ________ PSID PRESSURE DROP ACROSS THE FIRST PRESSURE DROP ACROSS THE SECOND CHECK VALVE IS : CHECK VALVE IS : INITIAL TEST INITIAL □ DID NOT OPEN ______________________ PSID ______________________ PSID □ CLEANED □ CLEANED □ CLEANED REPAIRED: REPAIRED: REPAIRED: □ RUBBER □ SPRING □ RUBBER □ SPRING □ RUBBER □ SPRING PARTS KIT □ STEM / PARTS KIT □ STEM / PARTS KIT □ STEM / □ CV ASSEMBLY GUIDE □ CV ASSEMBLY GUIDE □ CV ASSEMBLY GUIDE □ DISC □ RETAINER □ DISC □ RETAINER □ DISC □ RETAINER * REPAIRS □ O - RINGS □ LOCKNUTS □ O - RINGS □ LOCKNUTS □ O - RINGS □ LOCKNUTS □ SEAT □ OTHER: □ SEAT □ OTHER: □ SEAT □ OTHER: □ CLOSED TIGHT AT ______ PSID □ CLOSED TIGHT AT ______ PSID TEST FINAL FINAL □ OPENED AT ______ PSID CONDITION OF NO. 2 CONTROL VALVE : □ CLOSED TIGHT □ LEAKED REMARKS : □ ASSEMBLY FAILED □ ASSEMBLY PASSED □ CUSTOMER INFORMED *NOTE : ALL REPAIRS / REPLACEMENTS MUST BE COMPLETED WITHIN FOURTEEN (14) DAYS IV. APPROVALS * I HEREBY CERTIFY THAT THIS DATA IS ACCURATE AND REFLECTS THE PROPER OPERATION AND MAINTENANCE OT THE ASSEMBLY NAME OF CERTIFIED BACKFLOW PREVENTION ASSEMBLY BUSINESS TELEPHONE NO. -

File Permissions Do Not Restrict Root
Filesystem Security 1 General Principles • Files and folders are managed • A file handle provides an by the operating system opaque identifier for a • Applications, including shells, file/folder access files through an API • File operations • Access control entry (ACE) – Open file: returns file handle – Allow/deny a certain type of – Read/write/execute file access to a file/folder by – Close file: invalidates file user/group handle • Access control list (ACL) • Hierarchical file organization – Collection of ACEs for a – Tree (Windows) file/folder – DAG (Linux) 2 Discretionary Access Control (DAC) • Users can protect what they own – The owner may grant access to others – The owner may define the type of access (read/write/execute) given to others • DAC is the standard model used in operating systems • Mandatory Access Control (MAC) – Alternative model not covered in this lecture – Multiple levels of security for users and documents – Read down and write up principles 3 Closed vs. Open Policy Closed policy Open Policy – Also called “default secure” • Deny Tom read access to “foo” • Give Tom read access to “foo” • Deny Bob r/w access to “bar” • Give Bob r/w access to “bar • Tom: I would like to read “foo” • Tom: I would like to read “foo” – Access denied – Access allowed • Tom: I would like to read “bar” • Tom: I would like to read “bar” – Access allowed – Access denied 4 Closed Policy with Negative Authorizations and Deny Priority • Give Tom r/w access to “bar” • Deny Tom write access to “bar” • Tom: I would like to read “bar” – Access -

Instructions for Pwd Candidates Regarding Typing Skill Test
INSTRUCTIONS FOR PWD CANDIDATES REGARDING TYPING SKILL TEST (ON COMPUTER) AND STENOGRAPHY SKILL TEST The following guidelines are applicable to PwD Candidates shortlisted for Typing test or stenography test. 1. Typing test will be conducted on computer. 2. Persons with benchmark disability in the category of Visually impaired, orthopedically handicapped (afflicted by cerebral palsy), orthopedically handicapped (both arm affected), orthopedically handicapped candidates who has a locomotor disability wherein the dominant writing extremity is affected to the extent of slowing down the performance of the candidate (such deficiency to be indicated in the certificate, issued by competent authority, submitted by the candidate) will be allowed compensatory time of 05 minutes. 3. VI Candidates are eligible for scribe/passage dictator. 4. The Scribe/ Passage dictator is identified by the candidate at own cost and as per own choice. 5. The scribe/Passage dictator will read out the passage to VI candidates only within the allotted time. 6. Passage will not be provided in Brail for the VI candidates. 7. A person acting as a Scribe/Passage dictator for one candidate cannot be a Scribe /Passage dictator for another candidate. 8. The scribe/Passage dictator arranged by the candidate should not be a candidate for the same examination. 9. The candidate shall be responsible for any misconduct on the part of the scribe/Passage dictator brought by him during typing test. 10.Persons with Disabilities candidates who claim to be permanently unfit to take the Typing test because of a physical disability may, with the prior approval of the CEPTAM, DRDO be exempted from the requirement of appearing and qualifying at such test, provided such a candidate submits in the attached format (Appendix-I) to the CEPTAM, DRDO from the competent Medical Authority, i.e. -

Regression Testing and Conformance Testing Interactive Programs
RegressionTesting and Conformance TestingInteractive Programs Don Libes- NationalInstitute of Standardsand Technology ABSTRACT _ Testinginteractive programs, by its nature,requires interaction - usuallyby real people. Such testing is an expensiveprocess and hencerarely done. Some interactivetools can ¡e used non-interactivelyto a limited extent, and are often tested only this way. Purely interactiveprograms are rarely testedin any systematicway. _ This paper describestesting of interactive line and character-orientedprograms via Expect. An immediate use of this is to build a test suite for automatingstandards conformanceof all of the interactiveprograms in POSH t003.2a (interactiveshells and tools),something which hasnot yet beenaccomplished by any means. Introduction does not produceoutput that is immediatelycon- sumed by another process, Dennis Ritchie said that "A program but may for example, tl] write designedfor inputs from people is usually stressed to a disk or display.) This is the environment beyond the breaking point by computer-generated in which Ritchie'sremark arose. inputs." I would add the following: Any program In practice,there are forms of input that pro- useful to people- interactively- is likely to be use- duction programsdo not generate.For example, ful to programs- non-interactively.A corollary of programsdo not make typing errorsand thereforedo Ritchie's statementis that conect softwarefunction not (press the backspaceor delete key to) delete during normalhuman use is not a very goodtest of a charactersjust produced.Similarly, programs do not program'stotal correctness. enter control characters,such as might be used to process. I claim that even when humansare explicitly interrupt a This suggeststhat Ritchie was too - teqtinginteractive software, the resultsare still quite optimistic even computergenerated inputs still unreliable. -

CS2043 - Unix Tools & Scripting Cornell University, Spring 20141
CS2043 - Unix Tools & Scripting Cornell University, Spring 20141 Instructor: Bruno Abrahao January 31, 2014 1 Slides evolved from previous versions by Hussam Abu-Libdeh and David Slater Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting Vim: Tip of the day! Line numbers Displays line number in Vim: :set nu Hides line number in Vim: :set nonu Goes to line number: :line number Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting Counting wc How many lines of code are in my new awesome program? How many words are in this document? Good for bragging rights Word, Character, Line, and Byte count with wc wc -l : count the number of lines wc -w : count the number of words wc -m : count the number of characters wc -c : count the number of bytes Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting Sorting sort Sorts the lines of a text file alphabetically. sort -ru file sorts the file in reverse order and deletes duplicate lines. sort -n -k 2 -t : file sorts the file numerically by using the second column, separated by a colon Example Consider a file (numbers.txt) with the numbers 1, 5, 8, 11, 62 each on a separate line, then: $ sort numbers.txt $ sort numbers.txt -n 1 1 11 5 5 8 62 11 8 62 Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting uniq uniq uniq file - Discards all but one of successive identical lines uniq -c file - Prints the number of successive identical lines next to each line Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting Character manipulation! The Translate Command tr [options] <char_list1> [char_list2] Translate or delete characters char lists are strings of characters By default, searches for characters in char list1 and replaces them with the ones that occupy the same position in char list2 Example: tr 'AEIOU' 'aeiou' - changes all capital vowels to lower case vowels Instructor: Bruno Abrahao CS2043 - Unix Tools & Scripting Pipes and redirection tr only receives input from standard input (stdin) i.e. -

File Security and Permissions
File Security and Permissions File Permissions (1) u With respect to a particular file, Unix divides the set of all users on a system into three categories: – user vThe owner of the file. – group users vMost of you are in the group 2ndyr vUsed for easier administration of access control. vNormally only the superuser can set up groups. vUsers can be in more than one group. – others vEveryone else. File Permissions (2) u Permissions can be viewed with the ls -l command obelix[1] > ls -l total 1247 -rw------- 1 csnow 1117 Jul 23 15:49 bad.cpp drwx--x--x 2 csnow 2048 Jul 17 10:13 bibd/ drwxr-xr-x 2 csnow 512 Aug 27 23:18 cache/ -rw------- 1 csnow 2081 Jul 23 15:49 tst2.s -rw-r-xr-- 1 csnow 1275 Jul 23 15:49 vecexpr.cpp r read permission -rw-r-xr-- w write permission x execute permission File type - = file d = directory User Group Other l=symbolic link Permissions Permissions Permissions File Permissions (3) u Permissions are changed with the chmod command. u There are two syntaxes you can use: chmod DDD file [file ...] – DDD are 3 octal digits representing bits of protection – rwx rwx rwx can be thought of as 111 111 111 in binary rw- r-- r-- 110 100 100 6 4 4 chmod 644 file File Permissions (4) u chmod [ugoa][+-=][rwx] file [...] – This is the “symbolic” method. – chmod u+rwx file gives the User Read, Write, and eXecute – chmod g+rx file gives the Group Read and eXecute – chmod o-rwx file removes R, W, and X from Others – chmod a+x file gives All eXecute permission – chmod g=r file gives Group Read permission and makes sure it has nothing -

Medium Voltage Variable Frequency Drives Acceptance Testing
APPLICATION EDGE VOLUME 1, ISSUE 8 MEDIUM VOLTAGE VARIABLE FREQUENCY DRIVES ACCEPTANCE TESTING It is the supplier’s responsibility to perform these MV VFDs are complex engineered systems that work in tests, record the test data, and issue a final test report concert with each other and auxiliary equipment that to the equipment purchaser. These tests are usually support it. witnessed by the end user, or their representative, at the equipment supplier’s facility or a third-party test stand and are executed before the final installation at Oftentimes, acceptance testing of VFDs is specified; the site. In limited cases, the equipment supplier will however, the terminology used in testing by vendors, perform the tests without anyone witnessing them. consultants, and operators can get intertwined, and end-user expectations can be misaligned with The testing requirements MUST be defined at the purchase- equipment vendors’ procedures and deliverables. order stage of the equipment procurement cycle and NOT after. This application edge series outlines what a factory Figure 1 shows a typical MV- motor and VFD-driven acceptance test is, the different kinds of testing system. In order to test this system, an end user can available for a VFD system, when a test should be make a selection from up to four types of testing selected, and recommendations for the type of test varying in breadth and scope as shown below. This to select. paper will focus only on VFD testing (blue highlight). Factory acceptance testing (FAT) – definition Types of VFD testing A factory acceptance test, commonly known as Considering the VFD by itself, there are seven variants acceptance testing, is a series of tests performed by of testing that can be done. -
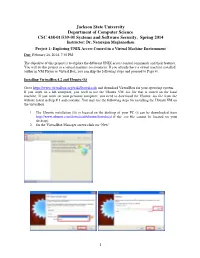
Jackson State University Department of Computer Science CSC 438-01/539-01 Systems and Software Security, Spring 2014 Instructor: Dr
Jackson State University Department of Computer Science CSC 438-01/539-01 Systems and Software Security, Spring 2014 Instructor: Dr. Natarajan Meghanathan Project 1: Exploring UNIX Access Control in a Virtual Machine Environment Due: February 26, 2014, 7.30 PM The objective of this project is to explore the different UNIX access control commands and their features. You will do this project in a virtual machine environment. If you already have a virtual machine installed (either in VM Player or Virtual Box, you can skip the following steps and proceed to Page 4). Installing VirtualBox 4.2 and Ubuntu OS Go to https://www.virtualbox.org/wiki/Downloads and download VirtualBox for your operating system. If you work on a lab computer, you need to use the Ubuntu VM .iso file that is stored on the local machine. If you work on your personal computer, you need to download the Ubuntu .iso file from the website listed in Step # 1 and continue. You may use the following steps for installing the Ubuntu VM on the virtualbox. 1. The Ubuntu installation file is located on the desktop of your PC (it can be downloaded from http://www.ubuntu.com/download/ubuntu/download if the .iso file cannot be located on your desktop). 2. On the VirtualBox Manager screen click on “New” 1 3. When prompted, put your J # for the name of the VM and select “Linux” as OS (when you choose Linux as OS, the program should automatically choose Ubuntu as Version, if not select Ubuntu) and click Next. 4. -

Midterm Test #1 − 10% Ian! D
45 M/C Questions -1- 45 minutes 45 M/C Questions -2- 45 minutes 6. [66/167] If mt is an empty sub-directory,what is true after this: PRINT Name: LAB Section: touch bar ; mkdir foo ; mv bar mt/foo Test Version: ___ One-Answer Multiple Choice 45 Questions − 10 of 10% a. the directory foo nowcontains a file named bar the directory mt nowcontains a file named foo ☞ b. Read all the words of these instructions and both sides (back and front) of all pages. c. the directory mt nowcontains a file named bar ☞ Manage your time. Answer questions you know, first. One Answer per question. d. the command fails because mt/foo is not a directory ☞ Put your Name and Lab on this Question Sheet. Youmay write or drawonthis sheet. e. the directory mt is still empty ☞ Use your full, unabbreviated name on the mark-sense form. Do not abbreviate your name. ☞ Put the three-digit Test Version above into NO. OF QUESTIONS and NO. OF STUDENTS 7. [67/168] What is the output of this in an empty directory: ☞ Fill in the bubbles with pencil only,nopen. Enter your NAME, Test Version, and answers. touch 1 13 .13 2 213 3 30 31 .31 ; echo [13]* ☞ Taip The answer to the last question about reading/doing all these test instructions is: a. 13 b. an error message from echo saying [13]* does not exist c. [13]* 1. [49/169] If file foo contains 8 lines, and file bar contains 9 lines, then how manylines are output on your screen by this: cat bar | echo foo d. -

Introduction to the Linux Command Line. Sabry Razick (RCS Nov 2015) What Is a Terminal
Introduction to the Linux command line. Sabry Razick (RCS Nov 2015) What is a terminal ● The terminal is an interface in which you can type and execute text based commands. ● It can be much faster to complete some tasks using a Terminal than with graphical applications and menus. ● Allowing access to many more commands and scripts. ● When making your own program, it is easier and faster to design it to work on the terminal than with the mouse. ● More transparency on what is going on ● More control on what you do ● ……. How to access the terminal ● Unix based systems (Redhat, Ubuntu….Mac OS) it is there as a program already. ● Windows - Windows command line (cmd) can not do the thing Unix terminal do. So you need a Virtual environment or get access a Unix machine ● Virtual environment ○ Oracle Virtual Machine - www.oracle.com/us/technologies/virtualization/oraclevm/ ○ Cygwin - https://www.cygwin.com/ ○ Boot with a live CD/Falsh drive ● Access a Unix machine ○ Putty - http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html Windows ● abel.uio.no ● freebee.abel.uio.no ● Use UIO username and password Unix ● Locate the terminal The shell ● Shell provides an interface between you and the operating system of the computer ● Use the keyboard to tell the computer what you want of it ● Where is my home ○ echo $HOME ● Go to my home ○ cd $HOME ● What files or folders have in my home ○ ls ● Give me more details about the files ○ ls -lh The shell ● Find out more about a command ○ man <COMMAND> ○ e.g. -

Intro to Unix 2018
Introduction to *nix Bill Renaud, OLCF ORNL is managed by UT-Battelle for the US Department of Energy Background • UNIX operating system was developed in 1969 by Ken Thompson and Dennis Ritchie • Many “UNIX-like” OSes developed over the years • UNIX® is now a trademark of The Open Group, which maintains the Single UNIX Specification • Linux developed by Linus Torvalds in 1991 • GNU Project started by Richard Stallman in 1983 w/aim to provide free, UNIX-compatible OS • Many of the world’s most powerful computers use Linux kernel + software from the GNU Project References: 1www.opengroup.org/unix 2https://en.wikipedia.org/wiki/Linux 2 3https://www.gnu.org/gnu/about-gnu.html This Presentation • This presentation will focus on using *nix operating systems as a non-privileged user in an HPC environment – Assumes you’re using a ‘remote’ system – No info on printing, mounting disks, etc. • We’ll focus on systems using the Linux kernel + system software from the GNU project since that’s so prevalent • Two-Part – Basics: general information, commands – Advanced: advanced commands, putting it all together, scripts, etc. 3 This Presentation • May seem a bit disjoint at first – Several basic concepts that don’t flow naturally but later topics build upon – Hopefully everything will come together, but if not… • I’ll cover (what I hope is) some useful info but can’t cover it all – People write thousand-page books on this, after all • Please ask questions! 4 Basics Terminology • User – An entity that interacts with the computer. Typically a person but could also be for an automated task. -

Create Directory on Windows Without the Fleeting DOS Window Hsiwei Yu (Michael), People Technology Solution Inc, Edison, NJ Gary Huang, Infostat Inc., Belle Mead, NJ
Create Directory on Windows Without the Fleeting DOS Window Hsiwei Yu (Michael), People Technology Solution Inc, Edison, NJ Gary Huang, InfoStat Inc., Belle Mead, NJ copy “source directory” “target directory” ABSTRACT for copying files from source directory to target directory. On newer Windows environments, the pipe feature on a filename statement can be used to create directory without the fleeting Most DOS commands return nothing when successful. Some DOS window. This is better than the X command approach. Any commands, like DIR and COPY, return useful information that DOS commands can be used in the filename pipe feature. Finally can be further analyzed. we will show example of managing directories on remote machine Filename fileref PIPE ‘dir “c:\a dir”’; from local SAS session. Data important_message; Infile fileref length= LNG; Input @; INTRODUCTION /* Put _infile_; */ Sometimes we need to create or delete a directory from within a /* Additional logic to parse the directory SAS session. Previously we can use the X command construct to contents for further analysis. */ issue such create directory (MKDIR) command. However this if LNG >= 8 then do; technique results in an annoying DOS window, flashing and input last_modified_date mmddyy8. @; vanishing on screen. On newer Windows environment and with … the filename pipe feature, we can accomplish the same without end; the extra DOS window. Run; THE FILENAME PIPE FEATURE APPLICATON: MANAGE DIRECTORY ON The filename pipe feature is available is in the Windows environment in both SAS 6.12