Design and Evaluation of H4-Writer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UC Berkeley UC Berkeley Electronic Theses and Dissertations
UC Berkeley UC Berkeley Electronic Theses and Dissertations Title Perceptual and Context Aware Interfaces on Mobile Devices Permalink https://escholarship.org/uc/item/7tg54232 Author Wang, Jingtao Publication Date 2010 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California Perceptual and Context Aware Interfaces on Mobile Devices by Jingtao Wang A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Computer Science in the Graduate Division of the University of California, Berkeley Committee in charge: Professor John F. Canny, Chair Professor Maneesh Agrawala Professor Ray R. Larson Spring 2010 Perceptual and Context Aware Interfaces on Mobile Devices Copyright 2010 by Jingtao Wang 1 Abstract Perceptual and Context Aware Interfaces on Mobile Devices by Jingtao Wang Doctor of Philosophy in Computer Science University of California, Berkeley Professor John F. Canny, Chair With an estimated 4.6 billion units in use, mobile phones have already become the most popular computing device in human history. Their portability and communication capabil- ities may revolutionize how people do their daily work and interact with other people in ways PCs have done during the past 30 years. Despite decades of experiences in creating modern WIMP (windows, icons, mouse, pointer) interfaces, our knowledge in building ef- fective mobile interfaces is still limited, especially for emerging interaction modalities that are only available on mobile devices. This dissertation explores how emerging sensors on a mobile phone, such as the built-in camera, the microphone, the touch sensor and the GPS module can be leveraged to make everyday interactions easier and more efficient. -

User Guide Blackberry 8800 Smartphone SWD-280419-0222085634-001 Contents
User Guide BlackBerry 8800 Smartphone SWD-280419-0222085634-001 Contents BlackBerry basics..................................................................................................................................................................................................................................9 Switch applications..........................................................................................................................................................................................................................................9 Assign an application to a Convenience key................................................................................................................................................................................................9 Set owner information......................................................................................................................................................................................................................................9 Turn on standby mode......................................................................................................................................................................................................................................9 About links.........................................................................................................................................................................................................................................................9 -

Video Game Systems Uncovered
Everything You Ever Wanted To Know About... VIDEO GAMES But Never Dared To Ask! Introduction: 1 With the holidays quickly approaching the odds are you will be purchasing some type of video game system. The majority of U.S. households currently have at least one of these systems. With the ever changing technology in the video world it is hard to keep up with the newest systems. There is basically a system designed for every child’s needs, ranging from preschool to young adult. This can overwhelming for parents to choose a system that not only meets your child’s needs but also gives us the best quality system for our money. With the holidays coming that means many retailers will be offering specials on video game systems and of course the release of long awaited games. Now is also the time you can purchase systems in bundles with games included. Inside you will learn about all of these topics as well as other necessities and games to accompany to recent purchase. What you’ll find here: 2 In this ebook you will learn about console and portable video game systems, along with the accessories available. You will also find how many games each system has to offer. You will get an in depth look at the pro’s and con’s of each current system available in stores today, and the upcoming systems available in the near future. As a concerned parent you should also be aware of the rating label of the games and what the rating exactly means. -

Playstation®2 Gets Stunning New Look(Pdf)
PLAYSTATION®2 GETS STUNNING NEW LOOK Smaller, Slimmer and Network Ready PlayStation®2 to Hit the Market Worldwide in November Tokyo, September 21, 2004 – Sony Computer Entertainment Inc. (SCEI), announced today a completely new look for the PlayStation®2 computer entertainment system (SCPH-70000), which will become available in Japan, North America and Europe for the year-end peak selling season. The new model will be available in stores on November 1st in North America and Europe, and on November 3rd in Japan. While inheriting the basic functions and design philosophy of the current PlayStation 2, the internal design architecture has been completely overhauled, resulting in a slimmer and more lightweight design. Internal volume has been reduced by 75%, overall weight has been halved, and thickness trimmed down to 2.8 cm (thickness of current model is 7.8 cm). Its size is almost as small as a hardcover book, making it easier to carry around and enjoy games and DVD videos anytime, anywhere. Equipped with an integrated Ethernet port for network gaming, the new PlayStation 2 sets new standards in the fusion of design and functionality. In North America, approximately 40% (*1) of the PlayStation 2 on-line game users connect their PlayStation 2 to the networks through analog modem and reflecting the American users’ preference, the North American model is equipped with both Ethernet and modem ports. The launch of the new network ready(*2) PlayStation 2 will further expand the universe of on-line gaming, as more and more on-line titles become available worldwide. -more- 1/6 2-2-2-2 PlayStation 2 Gets Stunning New Look Gaining overwhelming support from a wide range of users from all over the world, more than 72 million units of PlayStation 2 have been shipped as of today. -

Playstation Games
The Video Game Guy, Booths Corner Farmers Market - Garnet Valley, PA 19060 (302) 897-8115 www.thevideogameguy.com System Game Genre Playstation Games Playstation 007 Racing Racing Playstation 101 Dalmatians II Patch's London Adventure Action & Adventure Playstation 102 Dalmatians Puppies to the Rescue Action & Adventure Playstation 1Xtreme Extreme Sports Playstation 2Xtreme Extreme Sports Playstation 3D Baseball Baseball Playstation 3Xtreme Extreme Sports Playstation 40 Winks Action & Adventure Playstation Ace Combat 2 Action & Adventure Playstation Ace Combat 3 Electrosphere Other Playstation Aces of the Air Other Playstation Action Bass Sports Playstation Action Man Operation EXtreme Action & Adventure Playstation Activision Classics Arcade Playstation Adidas Power Soccer Soccer Playstation Adidas Power Soccer 98 Soccer Playstation Advanced Dungeons and Dragons Iron and Blood RPG Playstation Adventures of Lomax Action & Adventure Playstation Agile Warrior F-111X Action & Adventure Playstation Air Combat Action & Adventure Playstation Air Hockey Sports Playstation Akuji the Heartless Action & Adventure Playstation Aladdin in Nasiras Revenge Action & Adventure Playstation Alexi Lalas International Soccer Soccer Playstation Alien Resurrection Action & Adventure Playstation Alien Trilogy Action & Adventure Playstation Allied General Action & Adventure Playstation All-Star Racing Racing Playstation All-Star Racing 2 Racing Playstation All-Star Slammin D-Ball Sports Playstation Alone In The Dark One Eyed Jack's Revenge Action & Adventure -

Quick Reference
Quick Reference SCPH-90002 SCPH-90003 Before using this product, carefully read the supplied documentation and retain it for future reference. 3-289-799-52(1) Read carefully before operating your PlayStation®2 console Warning A few people may experience epileptic seizures when viewing flashing lights or patterns in our daily environment. These persons may experience seizures while To reduce the risk of fire or electric shock, do not expose this apparatus to rain watching TV or playing video games, including DVD-Videos or games played on or moisture. the PlayStation®2 console. Players who have not had any seizures may nonetheless have an undetected epileptic condition. Consult your physician before operating the To prevent fire or shock hazard, do not place a container filled with liquids on PlayStation®2 console if you have an epileptic condition or experience any of the top of the console. following symptoms while watching TV programmes or playing video games: altered vision, muscle twitching, other involuntary movements, loss of awareness of To avoid electrical shock, do not open the cabinet. Refer servicing to qualified your surroundings, mental confusion, and/or convulsions. personnel only. Software title compatibility Caution Some PlayStation® or PlayStation®2 format software titles may perform differently Use of controls or adjustments or performance of procedures other than those on this console than they do on previous PlayStation®2 or PlayStation® consoles, or specified herein may result in hazardous radiation exposure. may not perform properly on this console. For more information, visit our Web site The use of optical instruments with this product will increase eye hazard. -
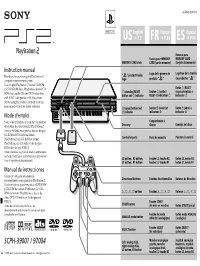
Ps2-SCPH-39001.Pdf
3-076-132-11(1) English Français Español US ➔ P.2 FR ➔ P.24 ES ➔ P.46 Ranuras para Fentes pour MEMORY MEMORY CARD MEMORY CARD slots CARD (carte mémoire) (tarjeta de memoria) Instruction manual Logo de la gamme de Logotipo de la familia Thank you for purchasing the PlayStation®2 “ ” product family produits “ ” de productos “ ” computer entertainment system. logo You can play PlayStation®2 format CD-ROM Botón 1 /RESET and DVD-ROM discs, PlayStation® format CD- 1 Bouton 1 (veille)/ (espera/reinicio) e ROM discs, audio CDs and DVD video discs (standby)/RESET button and 1 indicator RESET et indicateur 1 indicador 1 with NTSC 1 designation with this system. Before using this product, carefully read this manual and retain it for future reference. A (open) button and Bouton A (ouvrir) et Botón A (abrir) e A indicator indicateur A indicador A Mode d’emploi Nous vous remercions d’avoir fait l’acquisition Compartiment à Disc tray disque Bandeja del disco du système de loisir interactif PlayStation®2. Avec ce système, vous pouvez lire des disques CD-ROM et DVD-ROM au format Controller ports Ports de manette Puertos de control PlayStation®2, des CD-ROM au format PlayStation®, des CD audio et des disques DVD vidéo de type NTSC 1. Avant d’utiliser ce produit, lisez attentivement ce mode d’emploi et conservez-le pour pouvoir L2 button, R2 button, Touche L2, touche R2, Botón L2, botón R2, vous y reporter ultérieurememt. L1 button, R1 button touche L1, touche R1 botón L1, botón R1 Manual de instrucciones Gracias por adquirir el sistema de Directional buttons Touches directionnelles Botones de dirección entretenimiento computarizado PlayStation®2. -
SHARE Bibliographic and Cataloging Best Practices for Membership Vote
SHARE Bibliographic and Cataloging Best Practices for Membership Vote 1.Policy for cataloging Playaway Views Playaway View is a device that contains preloaded video content. Catalog as you would a videorecording, with the following special instructions: General material designation (gmd) -- use [electronic resource] Note: Local edit: Add a gmd to RDA records for preloaded video players. Do not add to master records in OCLC. Edition statement Add the edition statement [Playaway View]. This may be added to an existing edition statement, separated by a comma. Note: This is a local edit only. Do not add to master records in OCLC. Example: 245 $h [electronic resource] 250 _ _ $aCollectors edition, [Playaway View]. Physical description “Video media player” is the term in common use in records for this device. Record the term “1 video media player (include time of feature presentation, if available)” in subfield a. Record the term “digital” in subfield b, and the dimensions of the player in subfield c. Example: 300 _ _ $a1 video media player (ca. 51 min.) :$digital. ;$c3 1/2 x 4 1/2 in. Notes If not already in the record, add the following notes, in addition to all other appropriate notes: 500 _ _ $aIssued on Playaway View, a dedicated video media player. 500 _ _ $aPowered by rechargeable battery; container includes one electrical power adapter. 500 _ _ $aEarphones not required for audio playback. Subject headings Add the following subject heading in addition to all other applicable headings: 690 _ _ $aPlayaway View (Preloaded video player) Note: This is a local edit only. -

Products of Interest
Products of Interest Line 6 Amplifi Guitar Amplifier tone-matching function that allows feedback to the user. Thirty-two and Bluetooth Speaker System guitarists to match the tone of the wave and wavetable-based patches amplifier to tracks found in their are available to choose from and the Line 6’s Amplifi is a guitar amplifier music libraries. Almost 200 clas- user can set the scale and root note, and Bluetooth speaker system com- sic amplifiers, cabinet models, and the pitch range, and stereo delay. A bined into one. The amplifier has five effects are built in and up to eight speaker is built in to the unit and a speakers: two tweeters, two mid-bass effects can be used simultaneously. headphone output is also available. drivers, and a custom-designed Ce- The user can save four presets on the Two line level audio outputs, a pitch lestion guitar speaker (see Figure 1). It amplifier and an unlimited number CV output, and a mini USB jack are is available in two models, a 150-watt on the app. provided on the rear panel. The CV version and a 75-watt portable ver- The Amplifi 150 is listed for US$ output can be set from 0–5V or 0–10V. × sion. The larger amplifier has a 12-in 699.99 and the 75-watt model for The front panel features a 128 speaker and the smaller 75-watt US$ 599.99. Contact: Line 6, 26580 64 pixel backlit LCD screen. Con- model has an 8-in speaker. A gui- Agoura Road Calabasas, California trol knobs are provided for volume, + tar input, mini-jack stereo auxiliary 91302-1921, USA; telephone ( 1-818) pitch correction/quantization, delay + input, full size headphone output, 575-3600; fax ( 1-818) 575-3601; Web amount, and presets. -

SIGCHI Conference Paper Format
CHI 2007 Proceedings · Mobile Interaction Techniques I April 28-May 3, 2007 · San Jose, CA, USA An Alternative to Push, Press, and Tap-tap-tap: Gesturing on an Isometric Joystick for Mobile Phone Text Entry Jacob O. Wobbrock,1,2 Duen Horng Chau2 and Brad A. Myers2 1The Information School 2Human-Computer Interaction Institute University of Washington School of Computer Science Mary Gates Hall, Box 352840 Carnegie Mellon University Seattle, WA 98195-2840 Pittsburgh, PA 15213 USA [email protected] 〈dchau, bam〉@cs.cmu.edu ABSTRACT A gestural text entry method for mobile is presented. Unlike most mobile phone text entry methods, which rely on re- a. b. peatedly pressing buttons, our gestural method uses an isometric joystick and the EdgeWrite alphabet to allow us- ers to write by making letter-like “pressure strokes.” In a 15-session study comparing character-level EdgeWrite to Multitap, subjects’ speeds were statistically indistinguish- able, reaching about 10 WPM. In a second 15-session study comparing word-level EdgeWrite to T9, the same subjects were again statistically indistinguishable, reaching about 16 WPM. Uncorrected errors were low, around 1% or less for each method. In addition, subjective results favored Edge- Write. Overall, results indicate that our isometric joystick- based method is highly competitive with two commercial keypad-based methods, opening the way for keypad-less designs and text entry on tiny devices. Additional results showed that a joystick on the back could be used at about 70% of the speed of the front, and the front joystick could be used eyes-free at about 80% of the speed of normal use. -

Investigating Midair Virtual Keyboard Input Using a Head Mounted Display
Michigan Technological University Digital Commons @ Michigan Tech Dissertations, Master's Theses and Master's Reports 2018 INVESTIGATING MIDAIR VIRTUAL KEYBOARD INPUT USING A HEAD MOUNTED DISPLAY Jiban Krishna Adhikary Michigan Technological University, [email protected] Copyright 2018 Jiban Krishna Adhikary Recommended Citation Adhikary, Jiban Krishna, "INVESTIGATING MIDAIR VIRTUAL KEYBOARD INPUT USING A HEAD MOUNTED DISPLAY", Open Access Master's Thesis, Michigan Technological University, 2018. https://doi.org/10.37099/mtu.dc.etdr/704 Follow this and additional works at: https://digitalcommons.mtu.edu/etdr Part of the Graphics and Human Computer Interfaces Commons INVESTIGATING MIDAIR VIRTUAL KEYBOARD INPUT USING A HEAD MOUNTED DISPLAY By Jiban Krishna Adhikary A THESIS Submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE In Computer Science MICHIGAN TECHNOLOGICAL UNIVERSITY 2018 © 2018 Jiban Krishna Adhikary This thesis has been approved in partial fulfillment of the requirements for the Degree of MASTER OF SCIENCE in Computer Science. Department of Computer Science Thesis Advisor: Dr. Keith Vertanen Committee Member: Dr. Scott Kuhl Committee Member: Dr. Elizabeth Veinott Department Chair: Dr. Zhenlin Wang Dedication To my parents who have always been there and provided support in every ups and downs in my life - without which I would neither be who I am nor would this work be what it is today. Contents List of Figures ................................. xi List of Tables .................................. xv Acknowledgments ............................... xvii List of Abbreviations ............................. xix Abstract ..................................... xxi 1 Introduction ................................. 1 2 Related Work ................................ 3 2.1 Midair Text Entry Outside Virtual Environments . 4 2.1.1 Selection Based Techniques . 4 2.1.2 Gesture Based Techniques . -

Edgewrite: a Versatile Design for Text Entry and Control
EdgeWrite: A Versatile Design for Text Entry and Control Jacob O. Wobbrock July 2006 CMU-HCII-06-104 Human-Computer Interaction Institute School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 Thesis Committee: Brad A. Myers, Chair Scott E. Hudson Jennifer Mankoff Richard C. Simpson, University of Pittsburgh Shumin Zhai, IBM Almaden Research Center Submitted in partial fulfillment of the requirements for the Degree of Doctor of Philosophy Copyright © 2006 Jacob O. Wobbrock. All rights reserved. This work was supported in part by the National Science Foundation under grant UA-0308065. Any opinions, findings, conclusions, or recommendations expressed in this material are those of the author and do not necessarily reflect those of the National Science Foundation. Additional support was provided by General Motors, Microsoft, NEC Foundation of America, NISH, Synaptics, and A.T. Sciences. Keywords: Text entry, text input, unistrokes, gestures, assistive technology, computer access, universal access, universal design, motor impairments, situational impairments, mobile device, mobile phone, handheld, PDA, stylus, game controller, displacement joystick, isometric joystick, power wheelchair joystick, touchpad, trackball, on-screen keyboard, capacitive sensors, word prediction, word completion, goal crossing, physical edges, EdgeWrite, Pebbles, Fitts’ law, Hick-Hyman law, Steering law, Zipf’s law. ii Abstract This dissertation presents a versatile design for text entry and control called EdgeWrite. EdgeWrite was designed to provide accessible text entry on a variety of platforms to people with motor impairments and to able-bodied users of small devices. The EdgeWrite design includes a square input area, four corner sensors, corner- sequence recognition, physical edges, goal crossing, and unistroke segmentation.