Hunting Down Stars with Unusual Infrared Properties Using Supervised Machine Learning
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Planetas Extrasolares
Local Extrasolar Planets Universidad Andres Bello ESO Vitacura 4 June 2015 Foto: Dante Joyce Minniti Pullen The big picture 1. Increase human resources and networks for national Astronomy 2. Develop new areas of research and do quality science 3. Promote science in Chile Universidad Andres Bello ESO Vitacura 4 June 2015 Dante Minniti The Pioneers Wolfgang Gieren Maria Teresa Ruiz Grzegorz Pietrzynski Dante Minniti School on Extrasolar Planets and Brown Dwarfs Santiago, 2003 Invited Lecturers: Michel Mayor, Scott Tremaine, Gill Knapp, France Allard Universidad Andres Bello ESO Vitacura 4 June 2015 Dante Minniti It is all about time... Telescope time is the most precious... Universidad Andres Bello ESO Vitacura 4 June 2015 Dante Minniti The Pioneers Wolfgang Gieren Maria Teresa Ruiz Grzegorz Pietrzynski Dante Minniti The first exoplanet for us: M. Konacki, G. Torres, D. D. Sasselov, G. Pietrzynski, A. Udalski, S. Jha, M. T. Ruiz, W. Gieren, & D. Minniti, “A Transiting Extrasolar Giant Planet Around the Star OGLE-TR-113'', 2004, ApJ, 609, L37” Universidad Andres Bello ESO Vitacura 4 June 2015 Dante Minniti The Pioneers Paul Butler Debra Fischer Dante Minniti The First Planets from the N2K Consortium Fischer et al., ``A Hot Saturn Planet Orbiting HD 88133, from the N2K Consortium", 2005, The Astrophysical Journal, 620, 481 Sato, et al., ``The N2K Consortium. II. A Transiting Hot Saturn around HD 149026 with a Large Dense Core", 2005, The Astrophysical Journal, 633, 465 Universidad Andres Bello ESO Vitacura 4 June 2015 Dante Minniti The Pioneers -

Appendix 1 Some Astrophysical Reminders
Appendix 1 Some Astrophysical Reminders Marc Ollivier 1.1 A Physics and Astrophysics Overview 1.1.1 Star or Planet? Roughly speaking, we can say that the physics of stars and planets is mainly governed by their mass and thus by two effects: 1. Gravitation that tends to compress the object, thus releasing gravitational energy 2. Nuclear processes that start as the core temperature of the object increases The mass is thus a good parameter for classifying the different astrophysical objects, the adapted mass unit being the solar mass (written Ma). As the mass decreases, three categories of objects can be distinguished: ∼ 1. if M>0.08 Ma ( 80MJ where MJ is the Jupiter mass) the mass is sufficient and, as a consequence, the gravitational contraction in the core of the object is strong enough to start hydrogen fusion reactions. The object is then called a “star” and its radius is proportional to its mass. 2. If 0.013 Ma <M<0.08 Ma (13 MJ <M<80 MJ), the core temperature is not high enough for hydrogen fusion reactions, but does allow deuterium fu- sion reactions. The object is called a “brown dwarf” and its radius is inversely proportional to the cube root of its mass. 3. If M<0.013 Ma (M<13 MJ) the temperature a the center of the object does not permit any nuclear fusion reactions. The object is called a “planet”. In this category one distinguishes giant gaseous and telluric planets. This latter is not massive enough to accrete gas. The mass limit between giant and telluric planets is about 10 terrestrial masses. -

Naming the Extrasolar Planets
Naming the extrasolar planets W. Lyra Max Planck Institute for Astronomy, K¨onigstuhl 17, 69177, Heidelberg, Germany [email protected] Abstract and OGLE-TR-182 b, which does not help educators convey the message that these planets are quite similar to Jupiter. Extrasolar planets are not named and are referred to only In stark contrast, the sentence“planet Apollo is a gas giant by their assigned scientific designation. The reason given like Jupiter” is heavily - yet invisibly - coated with Coper- by the IAU to not name the planets is that it is consid- nicanism. ered impractical as planets are expected to be common. I One reason given by the IAU for not considering naming advance some reasons as to why this logic is flawed, and sug- the extrasolar planets is that it is a task deemed impractical. gest names for the 403 extrasolar planet candidates known One source is quoted as having said “if planets are found to as of Oct 2009. The names follow a scheme of association occur very frequently in the Universe, a system of individual with the constellation that the host star pertains to, and names for planets might well rapidly be found equally im- therefore are mostly drawn from Roman-Greek mythology. practicable as it is for stars, as planet discoveries progress.” Other mythologies may also be used given that a suitable 1. This leads to a second argument. It is indeed impractical association is established. to name all stars. But some stars are named nonetheless. In fact, all other classes of astronomical bodies are named. -

Extremely Extended Dust Shells Around Evolved Intermediate Mass Stars: Probing Mass Loss Histories,Thermal Pulses and Stellar Evolution
EXTREMELY EXTENDED DUST SHELLS AROUND EVOLVED INTERMEDIATE MASS STARS: PROBING MASS LOSS HISTORIES,THERMAL PULSES AND STELLAR EVOLUTION A Thesis presented to the Faculty of the Graduate School at the University of Missouri In Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy by BASIL MENZI MCHUNU Dr. Angela K. Speck December 2011 The undersigned, appointed by the Dean of the Graduate School, have examined the dissertation entitled: EXTREMELY EXTENDED DUST SHELLS AROUND EVOLVED INTERMEDIATE MASS STARS PROBING MASS LOSS HISTORIES, THERMAL PULSES AND STELLAR EVOLUTION USING FAR-INFRARED IMAGING PHOTOMETRY presented by Basil Menzi Mchunu, a candidate for the degree of Doctor of Philosophy and hereby certify that, in their opinion, it is worthy of acceptance. Dr. Angela K. Speck Dr. Sergei Kopeikin Dr. Adam Helfer Dr. Bahram Mashhoon Dr. Haskell Taub DEDICATION This thesis is dedicated to my family, who raised me to be the man I am today under challenging conditions: my grandfather Baba (Samuel Mpala Mchunu), my grandmother (Ma Magasa, Nonhlekiso Mchunu), my aunt Thembeni, and my mother, Nombso Betty Mchunu. I would especially like to thank my mother for all the courage she gave me, bringing me chocolate during my undergraduate days to show her love when she had little else to give, and giving her unending support when I was so far away from home in graduate school. She passed away, when I was so close to graduation. To her, I say, ′′Ulale kahle Macingwane.′′ I have done it with the help from your spirit and courage. I would also like to thank my wife, Heather Shawver, and our beautiful children, Rosemary and Brianna , for making me see life with a new meaning of hope and prosperity. -

Arxiv:0809.1275V2
How eccentric orbital solutions can hide planetary systems in 2:1 resonant orbits Guillem Anglada-Escud´e1, Mercedes L´opez-Morales1,2, John E. Chambers1 [email protected], [email protected], [email protected] ABSTRACT The Doppler technique measures the reflex radial motion of a star induced by the presence of companions and is the most successful method to detect ex- oplanets. If several planets are present, their signals will appear combined in the radial motion of the star, leading to potential misinterpretations of the data. Specifically, two planets in 2:1 resonant orbits can mimic the signal of a sin- gle planet in an eccentric orbit. We quantify the implications of this statistical degeneracy for a representative sample of the reported single exoplanets with available datasets, finding that 1) around 35% percent of the published eccentric one-planet solutions are statistically indistinguishible from planetary systems in 2:1 orbital resonance, 2) another 40% cannot be statistically distinguished from a circular orbital solution and 3) planets with masses comparable to Earth could be hidden in known orbital solutions of eccentric super-Earths and Neptune mass planets. Subject headings: Exoplanets – Orbital dynamics – Planet detection – Doppler method arXiv:0809.1275v2 [astro-ph] 25 Nov 2009 Introduction Most of the +300 exoplanets found to date have been discovered using the Doppler tech- nique, which measures the reflex motion of the host star induced by the planets (Mayor & Queloz 1995; Marcy & Butler 1996). The diverse characteristics of these exoplanets are somewhat surprising. Many of them are similar in mass to Jupiter, but orbit much closer to their 1Carnegie Institution of Washington, Department of Terrestrial Magnetism, 5241 Broad Branch Rd. -

Jpc-Final-Program.Pdf
49th AIAA/ASME/SAE/ASEE Joint Propulsion Conference and Exhibit (JPC) Advancing Propulsion Capabilities in a New Fiscal Reality 14–17 July 2013 San Jose Convention Center 11th International Energy Conversion San Jose, California Engineering Conference (IECEC) FINAL PROGRAM www.aiaa.org/jpc2013 www.iecec.org #aiaaPropEnergy www.aiaa.org/jpc2013 • www.iecec.org 1 #aiaaPropEnergy GET YOUR CONFERENCE INFO ON THE GO! Download the FREE Conference Mobile App FEATURES • Browse Program – View the program at your fingertips • My Itinerary – Create your own conference schedule • Conference Info – Including special events • Take Notes – Take notes during sessions • Venue Map – San Jose Convention Center • City Map – See the surrounding area • Connect to Twitter – Tweet about what you’re doing and who you’re meeting with #aiaaPropEnergy HOW TO DOWNLOAD Any version can be run without an active Internet connection! You can also sync an Compatible with itinerary you created online with the app by entering your unique itinerary name. iPhone/iPad, MyItinerary Mobile App MyItinerary Web App Android, and • For optimal use, we recommend • For optimal use, we recommend: rd BlackBerry! iPhone 3GS, iPod Touch (3 s iPhone 3GS, iPod Touch (3rd generation), iPad iOS 4.0, or later generation), iPad iOS 4.0, • Download the MyItinerary app by or later searching for “ScholarOne” in the s Most mobile devices using Android App Store directly from your mobile 2.2 or later with the default browser device. Or, access the link below or scan the QR code to access the iTunes s BlackBerry Torch or later device Sponsored by: page for the app. -

Marta L. Bryan
Marta L. Bryan 501 Campbell Hall #3411 Email: [email protected] University of California at Berkeley Homepage: w.astro.berkeley.edu/∼martalbryan Berkeley, CA 94720-3411 Appointments NASA Hubble Fellowship Program Sagan Fellow, UC Berkeley Astronomy Fall 2021 - present Department 51 Pegasi b Postdoctoral Fellow, UC Berkeley Astronomy Department 2018 - Fall 2021 Education PhD in Astrophysics, California Institute of Technology May 2018 Advisor: Prof. Heather Knutson Thesis: Lurking in the Shadows: Wide-Separation Gas Giants as Tracers of Planet Formation MS in Astrophysics, California Institute of Technology June 2014 BA cum laude with High Honors in Astrophysics, Harvard University June 2012 Undergraduate Thesis Advisor: Prof. David Latham Thesis: Characterizing Qatar-2b: A Hot Jupiter Orbiting a K Dwarf Research Interests Exploring the formation, evolution, and architectures of planetary systems Characterizing exoplanet rotation rates and atmospheres using high-resolution spectroscopy High-contrast AO imaging of exoplanets and brown dwarfs Constraining the frequencies of gas giants in systems hosting different populations of terrestrial and ice giant planets Bridging the gap between radial velocity and direct imaging survey sensitivities to planets using radial velocity trends Awards and Honors NASA Hubble Fellowship Program Sagan Fellowship 2021 51 Pegasi b Postdoctoral Fellowship 2018 NASA Hubble Fellowship Program Sagan Fellowship (declined) 2018 David and Barbara Groce Grant to attend the Exoplanets I meeting in Davos 2016 Switzerland, California Institute of Technology AAS 2015 International Travel Grant 2015 National Science Foundation Graduate Research Fellowship Honorable Mention 2014, 2013 Chambliss Astronomy Achievement Student Award Honorable Mention, AAS 2014 Moffet Fellowship, California Institute of Technology 2012-2013 Origins of Life Research Grant, Harvard University 2011-2012 Leo Goldberg Prize for outstanding undergraduate thesis work, Harvard University 2011 U.S. -
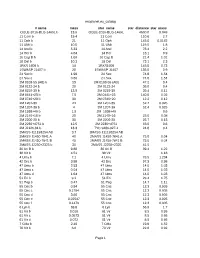
Exoplanet.Eu Catalog Page 1 # Name Mass Star Name
exoplanet.eu_catalog # name mass star_name star_distance star_mass OGLE-2016-BLG-1469L b 13.6 OGLE-2016-BLG-1469L 4500.0 0.048 11 Com b 19.4 11 Com 110.6 2.7 11 Oph b 21 11 Oph 145.0 0.0162 11 UMi b 10.5 11 UMi 119.5 1.8 14 And b 5.33 14 And 76.4 2.2 14 Her b 4.64 14 Her 18.1 0.9 16 Cyg B b 1.68 16 Cyg B 21.4 1.01 18 Del b 10.3 18 Del 73.1 2.3 1RXS 1609 b 14 1RXS1609 145.0 0.73 1SWASP J1407 b 20 1SWASP J1407 133.0 0.9 24 Sex b 1.99 24 Sex 74.8 1.54 24 Sex c 0.86 24 Sex 74.8 1.54 2M 0103-55 (AB) b 13 2M 0103-55 (AB) 47.2 0.4 2M 0122-24 b 20 2M 0122-24 36.0 0.4 2M 0219-39 b 13.9 2M 0219-39 39.4 0.11 2M 0441+23 b 7.5 2M 0441+23 140.0 0.02 2M 0746+20 b 30 2M 0746+20 12.2 0.12 2M 1207-39 24 2M 1207-39 52.4 0.025 2M 1207-39 b 4 2M 1207-39 52.4 0.025 2M 1938+46 b 1.9 2M 1938+46 0.6 2M 2140+16 b 20 2M 2140+16 25.0 0.08 2M 2206-20 b 30 2M 2206-20 26.7 0.13 2M 2236+4751 b 12.5 2M 2236+4751 63.0 0.6 2M J2126-81 b 13.3 TYC 9486-927-1 24.8 0.4 2MASS J11193254 AB 3.7 2MASS J11193254 AB 2MASS J1450-7841 A 40 2MASS J1450-7841 A 75.0 0.04 2MASS J1450-7841 B 40 2MASS J1450-7841 B 75.0 0.04 2MASS J2250+2325 b 30 2MASS J2250+2325 41.5 30 Ari B b 9.88 30 Ari B 39.4 1.22 38 Vir b 4.51 38 Vir 1.18 4 Uma b 7.1 4 Uma 78.5 1.234 42 Dra b 3.88 42 Dra 97.3 0.98 47 Uma b 2.53 47 Uma 14.0 1.03 47 Uma c 0.54 47 Uma 14.0 1.03 47 Uma d 1.64 47 Uma 14.0 1.03 51 Eri b 9.1 51 Eri 29.4 1.75 51 Peg b 0.47 51 Peg 14.7 1.11 55 Cnc b 0.84 55 Cnc 12.3 0.905 55 Cnc c 0.1784 55 Cnc 12.3 0.905 55 Cnc d 3.86 55 Cnc 12.3 0.905 55 Cnc e 0.02547 55 Cnc 12.3 0.905 55 Cnc f 0.1479 55 -

Astrometrically Registered Maps of H2O and Sio Masers Toward VX Sagittarii
ARTICLE DOI: 10.1038/s41467-018-04767-8 OPEN Astrometrically registered maps of H2O and SiO masers toward VX Sagittarii Dong-Hwan Yoon1,2, Se-Hyung Cho2,3, Youngjoo Yun2, Yoon Kyung Choi2, Richard Dodson4, María Rioja4,5, Jaeheon Kim6, Hiroshi Imai7, Dongjin Kim3, Haneul Yang1,2 & Do-Young Byun2 The supergiant VX Sagittarii is a strong emitter of both H2O and SiO masers. However, previous VLBI observations have been performed separately, which makes it difficult to 1234567890():,; spatially trace the outward transfer of the material consecutively. Here we present the astrometrically registered, simultaneous maps of 22.2 GHz H2O and 43.1/42.8/86.2/129.3 GHz SiO masers toward VX Sagittarii. The H2O masers detected above the dust-forming layers have an asymmetric distribution. The multi-transition SiO masers are nearly circular ring, suggesting spherically symmetric wind within a few stellar radii. These results provide the clear evidence that the asymmetry in the outflow is enhanced after the smaller molecular gas clump transform into the inhomogeneous dust layers. The 129.3 GHz maser arises from the outermost region compared to that of 43.1/42.8/86.2 GHz SiO masers. The ring size of the 129.3 GHz maser is maximized around the optical maximum, suggesting that radiative pumping is dominant. 1 Astronomy Program, Department of Physics and Astronomy, Seoul National University, 1 Gwanak-ro, Gwanak-gu, Seoul 08826, Korea. 2 Korea Astronomy and Space Science Institute, 776 Daedeokdae-ro, Yuseong-gu, Daejeon 34055, Korea. 3 Department of Astronomy, Yonsei University, 50 Yonsei-ro, Seodaemun-gu, Seoul 03722, Korea. -

Mètodes De Detecció I Anàlisi D'exoplanetes
MÈTODES DE DETECCIÓ I ANÀLISI D’EXOPLANETES Rubén Soussé Villa 2n de Batxillerat Tutora: Dolors Romero IES XXV Olimpíada 13/1/2011 Mètodes de detecció i anàlisi d’exoplanetes . Índex - Introducció ............................................................................................. 5 [ Marc Teòric ] 1. L’Univers ............................................................................................... 6 1.1 Les estrelles .................................................................................. 6 1.1.1 Vida de les estrelles .............................................................. 7 1.1.2 Classes espectrals .................................................................9 1.1.3 Magnitud ........................................................................... 9 1.2 Sistemes planetaris: El Sistema Solar .............................................. 10 1.2.1 Formació ......................................................................... 11 1.2.2 Planetes .......................................................................... 13 2. Planetes extrasolars ............................................................................ 19 2.1 Denominació .............................................................................. 19 2.2 Història dels exoplanetes .............................................................. 20 2.3 Mètodes per detectar-los i saber-ne les característiques ..................... 26 2.3.1 Oscil·lació Doppler ........................................................... 27 2.3.2 Trànsits -

CSIRO Australia Telescope National Facility
ASTRONOMY AND SPACE SCIENCE www.csiro.au CSIRO Australia Telescope National Facility Annual Report 2014 CSIRO Australia Telescope National Facility Annual Report 2014 ISSN 1038-9554 This is the report of the CSIRO Australia Telescope National Facility for the calendar year 2014, approved by the Australia Telescope Steering Committee. Editor: Helen Sim Designer: Angela Finney, Art when you need it Cover image: An antenna of the Australia Telescope Compact Array. Credit: Michael Gal Inner cover image: Children and a teacher from the Pia Wadjarri Remote Community School, visiting CSIRO's Murchison Radio-astronomy Observatory in 2014. Credit: CSIRO ii CSIRO Australia Telescope National Facility – Annual Report 2014 Contents Director’s Report 2 Chair’s Report 4 The ATNF in Brief 5 Performance Indicators 17 Science Highlights 23 Operations 35 Observatory and Project Reports 43 Management Team 53 Appendices 55 A: Committee membership 56 B: Financial summary 59 C: Staff list 60 D: Observing programs 65 E: PhD students 73 F: PhD theses 74 G: Publications 75 H: Abbreviations 84 1 Director’s Report Credit: Wheeler Studios Wheeler Credit: This year has seen some very positive an excellent scorecard from the Australia Dr Lewis Ball, Director, Australia results achieved by the ATNF staff, as well Telescope Users Committee. Telescope National Facility as some significant challenges. We opened We began reducing CSIRO expenditure a new office in the Australian Resources on the Mopra telescope some five years Research Centre building in Perth, installed ago. This year’s funding cut pushed us to phased-array feeds (PAFs) on antennas of take the final step along this path, and we our Australian SKA Pathfinder (ASKAP), and will no longer support Mopra operations collected data with a PAF-equipped array for using CSIRO funds after the end of the 2015 the first time ever in the world. -

AU25: 2, 3, 4.. 50 Estrellas
ars universalis 2, 3, 4… 50 ESTRELLAS Vexilología (II): arte y ciencia de las banderas, pendones y estandartes. De arriba a abajo y de izquierda a derecha, banderas de Australia, Bosnia y Herzegovina, Burundi, Cabo Verde, China (primera columna), Dominica, Guinea Ecuatorial, Granada, Honduras, Micronesia (segunda columna), Nueva Zelanda, Panamá, Papúa Nueva Guinea, San Cristóbal y Nieves, Samoa (tercera columna), Santo Tomé y Príncipe, Eslovenia, Islas Salomón, Siria, Tayikistán (cuarta columna), Tuvalu, Estados Unidos de América y Venezuela (quinta columna). (Cortesía del autor) ste segundo artículo de Nueva Guinea, Samoa y las Islas tralia, Nueva Zelanda, Papúa la serie astrovexilológi- Salomón. Seis las de Australia y Nueva Guinea y Samoa. Las cua- ca está dedicado a veinti- Guinea Ecuatorial (en el escudo tro estrellas en la bandera de trés banderas con dos o de armas). Siete las de Grana- Nueva Zelanda son rojas y file- E 01+02 más estrellas. Dos mullets tienen da y Tayikistán (una estrella so- teadas en blanco: Ácrux ( las banderas de Panamá, San bre cada una de las siete monta- Crucis, B0.5 IV+B1 V, V = 0,76 Cristóbal y Nieves (Saint Kitts ñas con jardines de orquídeas). mag.), Mimosa ( Crucis, 훼B1 IV, and Nevis), Santo Tomé y Prín- Ocho las de Bosnia y Herzego- V = 1,25 mag.), Gacrux ( Cru- cipe y Siria, que representan los vina (en realidad, siete estrellas cis, M3.5 III, V = 훽1,64 mag.) e partidos conservadores y los li- enteras y dos medias, en una su- Imai ( Crucis, B2 IV, V =훾 2,79 berales, dos parejas de islas y la cesión supuestamente infinita; mag.).