Classification of Melodic Motifs in Raga Music with Time-Series Matching
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Music Academy, Madras 115-E, Mowbray’S Road
Tyagaraja Bi-Centenary Volume THE JOURNAL OF THE MUSIC ACADEMY MADRAS A QUARTERLY DEVOTED TO THE ADVANCEMENT OF THE SCIENCE AND ART OF MUSIC Vol. XXXIX 1968 Parts MV srri erarfa i “ I dwell not in Vaikuntha, nor in the hearts of Yogins, nor in the Sun; (but) where my Bhaktas sing, there be I, Narada l ” EDITBD BY V. RAGHAVAN, M.A., p h .d . 1968 THE MUSIC ACADEMY, MADRAS 115-E, MOWBRAY’S ROAD. MADRAS-14 Annual Subscription—Inland Rs. 4. Foreign 8 sh. iI i & ADVERTISEMENT CHARGES ►j COVER PAGES: Full Page Half Page Back (outside) Rs. 25 Rs. 13 Front (inside) 20 11 Back (Do.) „ 30 „ 16 INSIDE PAGES: 1st page (after cover) „ 18 „ io Other pages (each) „ 15 „ 9 Preference will be given to advertisers of musical instruments and books and other artistic wares. Special positions and special rates on application. e iX NOTICE All correspondence should be addressed to Dr. V. Raghavan, Editor, Journal Of the Music Academy, Madras-14. « Articles on subjects of music and dance are accepted for mblication on the understanding that they are contributed solely o the Journal of the Music Academy. All manuscripts should be legibly written or preferably type written (double spaced—on one side of the paper only) and should >e signed by the writer (giving his address in full). The Editor of the Journal is not responsible for the views expressed by individual contributors. All books, advertisement moneys and cheques due to and intended for the Journal should be sent to Dr. V. Raghavan Editor. Pages. -
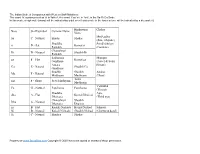
Note Staff Symbol Carnatic Name Hindustani Name Chakra Sa C
The Indian Scale & Comparison with Western Staff Notations: The vowel 'a' is pronounced as 'a' in 'father', the vowel 'i' as 'ee' in 'feet', in the Sa-Ri-Ga Scale In this scale, a high note (swara) will be indicated by a dot over it and a note in the lower octave will be indicated by a dot under it. Hindustani Chakra Note Staff Symbol Carnatic Name Name MulAadhar Sa C - Natural Shadaj Shadaj (Base of spine) Shuddha Swadhishthan ri D - flat Komal ri Rishabh (Genitals) Chatushruti Ri D - Natural Shudhh Ri Rishabh Sadharana Manipur ga E - Flat Komal ga Gandhara (Navel & Solar Antara Plexus) Ga E - Natural Shudhh Ga Gandhara Shudhh Shudhh Anahat Ma F - Natural Madhyam Madhyam (Heart) Tivra ma F - Sharp Prati Madhyam Madhyam Vishudhh Pa G - Natural Panchama Panchama (Throat) Shuddha Ajna dha A - Flat Komal Dhaivat Dhaivata (Third eye) Chatushruti Shudhh Dha A - Natural Dhaivata Dhaivat ni B - Flat Kaisiki Nishada Komal Nishad Sahsaar Ni B - Natural Kakali Nishada Shudhh Nishad (Crown of head) Så C - Natural Shadaja Shadaj Property of www.SarodSitar.com Copyright © 2010 Not to be copied or shared without permission. Short description of Few Popular Raags :: Sanskrut (Sanskrit) pronunciation is Raag and NOT Raga (Alphabetical) Aroha Timing Name of Raag (Karnataki Details Avroha Resemblance) Mood Vadi, Samvadi (Main Swaras) It is a old raag obtained by the combination of two raags, Ahiri Sa ri Ga Ma Pa Ga Ma Dha ni Så Ahir Bhairav Morning & Bhairav. It belongs to the Bhairav Thaat. Its first part (poorvang) has the Bhairav ang and the second part has kafi or Så ni Dha Pa Ma Ga ri Sa (Chakravaka) serious, devotional harpriya ang. -

Cholland Masters Thesis Final Draft
Copyright By Christopher Paul Holland 2010 The Thesis committee for Christopher Paul Holland Certifies that this is the approved version of the following thesis: Rethinking Qawwali: Perspectives of Sufism, Music, and Devotion in North India APPROVED BY SUPERVISING COMMITTEE: Supervisor: __________________________________ Syed Akbar Hyder ___________________________________ Gail Minault Rethinking Qawwali: Perspectives of Sufism, Music, and Devotion in North India by Christopher Paul Holland B.A. Thesis Presented to the Faculty of the Graduate School of the University of Texas at Austin in Partial Fulfillment of the Requirements for the Degree of Master of Arts The University of Texas at Austin May 2010 Rethinking Qawwali: Perspectives of Sufism, Music, and Devotion in North India by Christopher Paul Holland, M.A. The University of Texas at Austin, 2010 SUPERVISOR: Syed Akbar Hyder Scholarship has tended to focus exclusively on connections of Qawwali, a north Indian devotional practice and musical genre, to religious practice. A focus on the religious degree of the occasion inadequately represents the participant’s active experience and has hindered the discussion of Qawwali in modern practice. Through the examples of Nusrat Fateh Ali Khan’s music and an insightful BBC radio article on gender inequality this thesis explores the fluid musical exchanges of information with other styles of Qawwali performances, and the unchanging nature of an oral tradition that maintains sociopolitical hierarchies and gender relations in Sufi shrine culture. Perceptions of history within shrine culture blend together with social and theological developments, long-standing interactions with society outside of the shrine environment, and an exclusion of the female body in rituals. -

The Role of Radio in Promoting the Folk and Sufiana Music in the Kashmir Valley
Journal of Advances and Scholarly Researches in Allied Education Vol. XII, Issue No. 23, October-2016, ISSN 2230-7540 The Role of Radio in Promoting the Folk and Sufiana Music in the Kashmir Valley Afshana Shafi* Research Scholar, M.D.U., Rohtak, Haryana Abstract – In this Research work the Researcher reveals the role of All India Radio Srinagar in promoting the folk and sufiana music of Kashmir. Sufiana music is also known as the classical music of Kashmir. There was a time when the radio was considered to be a kind of entertainment only. At that sphere of time, All India Radio Kashmir was also touching the sky from its potential. Radio was widely heard among masses. Radio plays a significant role in the promoting of kashmiri music and the musicians of Kashmir. In this research work the researcher has written about role of Radio in Kashmiri music and in the success of kashmiri musicians. - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - X - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - As you have heard very different stories about Kashmir evening, in this way Radio Kashmir has been a major yet, but apart from it, Kashmir is full of colors‘. So, let‘s contributor to promoting folk music of Kashmir. talk about those same colors of Kashmir. Kashmiri Music has created a name throughout the world, yes I As the people of Kashmir, living in remote areas, do am talking about sufiana music but before that we will not have access the other source of information and talk about the folk music of Kashmir. The chief source of entertainment, apart from the limited local traditional entertainment is only Music, and an important element activities, for the majority of the people,but as its said governing popularity or unpopularity of the service change is the law of nature but inspite of this radio ―points out H.R Luthra . -

Fusion Without Confusion Raga Basics Indian
Fusion Without Confusion Raga Basics Indian Rhythm Basics Solkattu, also known as konnakol is the art of performing percussion syllables vocally. It comes from the Carnatic music tradition of South India and is mostly used in conjunction with instrumental music and dance instruction, although it has been widely adopted throughout the world as a modern composition and performance tool. Similarly, the music of North India has its own system of rhythm vocalization that is based on Bols, which are the vocalization of specific sounds that correspond to specific sounds that are made on the drums of North India, most notably the Tabla drums. Like in the south, the bols are used in musical training, as well as composition and performance. In addition, solkattu sounds are often referred to as bols, and the practice of reciting bols in the north is sometimes referred to as solkattu, so the distinction between the two practices is blurred a bit. The exercises and compositions we will discuss contain bols that are found in both North and South India, however they come from the tradition of the North Indian tabla drums. Furthermore, the theoretical aspect of the compositions is distinctly from the Hindustani, (north Indian) tradition. Hence, for the purpose of this presentation, the use of the term Solkattu refers to the broader, more general practice of Indian rhythmic language. South Indian Percussion Mridangam Dolak Kanjira Gattam North Indian Percussion Tabla Baya (a.k.a. Tabla) Pakhawaj Indian Rhythm Terms Tal (also tala, taal, or taala) – The Indian system of rhythm. Tal literally means "clap". -

Rakti in Raga and Laya
VEDAVALLI SPEAKS Sangita Kalanidhi R. Vedavalli is not only one of the most accomplished of our vocalists, she is also among the foremost thinkers of Carnatic music today with a mind as insightful and uncluttered as her music. Sruti is delighted to share her thoughts on a variety of topics with its readers. Rakti in raga and laya Rakti in raga and laya’ is a swara-oriented as against gamaka- complex theme which covers a oriented raga-s. There is a section variety of aspects. Attempts have of exponents which fears that ‘been made to interpret rakti in the tradition of gamaka-oriented different ways. The origin of the singing is giving way to swara- word ‘rakti’ is hard to trace, but the oriented renditions. term is used commonly to denote a manner of singing that is of a Yo asau Dhwaniviseshastu highly appreciated quality. It swaravamavibhooshitaha carries with it a sense of intense ranjako janachittaanaam involvement or engagement. Rakti Sankarabharanam or Bhairavi? rasa raga udaahritaha is derived from the root word Tyagaraja did not compose these ‘ranj’ – ranjayati iti ragaha, ranjayati kriti-s as a cluster under the There is a reference to ‘dhwani- iti raktihi. That which is pleasing, category of ghana raga-s. Older visesha’ in this sloka from Brihaddcsi. which engages the mind joyfully texts record these five songs merely Scholars have suggested that may be called rakti. The term rakti dhwanivisesha may be taken th as Tyagaraja’ s compositions and is not found in pre-17 century not as the Pancharatna kriti-s. Not to connote sruti and that its texts like Niruktam, Vyjayanti and only are these raga-s unsuitable for integration with music ensures a Amarakosam. -

Harmonic Progressions of Hindi Film Songs Based on North Indian Ragas
UNIVERSITI PUTRA MALAYSIA HARMONIC PROGRESSIONS OF HINDI FILM SONGS BASED ON NORTH INDIAN RAGAS WAJJAKKARA KANKANAMALAGE RUWIN RANGEETH DIAS FEM 2015 40 HARMONIC PROGRESSIONS OF HINDI FILM SONGS BASED ON NORTH INDIAN RAGAS UPM By WAJJAKKARA KANKANAMALAGE RUWIN RANGEETH DIAS COPYRIGHT Thesis Submitted to the School of Graduate Studies, Universiti Putra Malaysia, © in Fulfilment of the Requirements for the Degree of Doctor of Philosophy December 2015 All material contained within the thesis, including without limitation text, logos, icons, photographs and all other artwork, is copyright material of Universiti Putra Malaysia unless otherwise stated. Use may be made of any material contained within the thesis for non-commercial purposes from the copyright holder. Commercial use of material may only be made with the express, prior, written permission of Universiti Putra Malaysia. Copyright © Universiti Putra Malaysia UPM COPYRIGHT © Abstract of thesis presented of the Senate of Universiti Putra Malaysia in fulfilment of the requirements for the degree of Doctor of Philosophy HARMONIC PROGRESSIONS OF HINDI FILM SONGS BASED ON NORTH INDIAN RAGAS By WAJJAKKARA KANKANAMALAGE RUWIN RANGEETH DIAS December 2015 Chair: Gisa Jähnichen, PhD Faculty: Human Ecology UPM Hindi film music directors have been composing raga based Hindi film songs applying harmonic progressions as experienced through various contacts with western music. This beginning of hybridization reached different levels in the past nine decades in which Hindi films were produced. Early Hindi film music used mostly musical genres of urban theatre traditions due to the fact that many musicians and music directors came to the early film music industry from urban theatre companies. -

CARNATIC MUSIC (CODE – 032) CLASS – X (Melodic Instrument) 2020 – 21 Marking Scheme
CARNATIC MUSIC (CODE – 032) CLASS – X (Melodic Instrument) 2020 – 21 Marking Scheme Time - 2 hrs. Max. Marks : 30 Part A Multiple Choice Questions: Attempts any of 15 Question all are of Equal Marks : 1. Raga Abhogi is Janya of a) Karaharapriya 2. 72 Melakarta Scheme has c) 12 Chakras 3. Identify AbhyasaGhanam form the following d) Gitam 4. Idenfity the VarjyaSwaras in Raga SuddoSaveri b) GhanDharam – NishanDham 5. Raga Harikambhoji is a d) Sampoorna Raga 6. Identify popular vidilist from the following b) M. S. Gopala Krishnan 7. Find out the string instrument which has frets d) Veena 8. Raga Mohanam is an d) Audava – Audava Raga 9. Alankaras are set to d) 7 Talas 10 Mela Number of Raga Maya MalawaGoula d) 15 11. Identify the famous flutist d) T R. Mahalingam 12. RupakaTala has AksharaKals b) 6 13. Indentify composer of Navagrehakritis c) MuthuswaniDikshitan 14. Essential angas of kriti are a) Pallavi-Anuppallavi- Charanam b) Pallavi –multifplecharanma c) Pallavi – MukkyiSwaram d) Pallavi – Charanam 15. Raga SuddaDeven is Janya of a) Sankarabharanam 16. Composer of Famous GhanePanchartnaKritis – identify a) Thyagaraja 17. Find out most important accompanying instrument for a vocal concert b) Mridangam 18. A musical form set to different ragas c) Ragamalika 19. Identify dance from of music b) Tillana 20. Raga Sri Ranjani is Janya of a) Karahara Priya 21. Find out the popular Vena artist d) S. Bala Chander Part B Answer any five questions. All questions carry equal marks 5X3 = 15 1. Gitam : Gitam are the simplest musical form. The term “Gita” means song it is melodic extension of raga in which it is composed. -

The Melodic Power of Thumri by : INVC Team Published on : 16 Sep, 2018 05:32 AM IST
The melodic power of thumri By : INVC Team Published On : 16 Sep, 2018 05:32 AM IST INVC NEWS New Delhi , Delhi government’s Sahitya Kala Parishad kick started their eighth edition of Thumri Festival- a celebration of light classical music, on 14th September 2018 (Friday) at Kamani Auditorium. The 3 day musical event was inaugurated by the chief guest Sh. Rajendra Pal Gautam, Hon’ble Minister for Social Welfare, Govt. Of NCT of Delhi. The evening began with the performance of critically acclaimed Indian classical singer Padmaja Chakraborty, who sang Khamaj Thumri in Jat taal, Tappa in Raga Kafi and Kajri in Raag Mishra Pilu in Keherwa taal. The second performance was by the renowned vocalist and doyen of Kirana Gharana - Sri Jayateerth Mevundi. The classical singer, known for the ease and felicity of his singing style, mesmerized the audience with Raag Tilang Thumri, kafi Thumri, Jogiya Thumri, and Raag Pahadi in different raag and tal. The evening was culminated with a power packed performance by Shubha Mudgal who performed on Bol Banau Thumri and Bandish ki Thumri in which she sang rare types of Thumri for the audience. This musical fare is designed to showcase veteran Thumri singers along with the upcoming young talents who will share the space and light up the evening with their performances. About thumri : Thumri is a beautiful blend of Hindustani classical music with traits of folk literature. Thumri holds a history of over 500 years in Hindustani Classical music. Thumri used to be sung in the royal kingdoms and palaces and its background originates from Varanasi, Gwalior and Awadh were they used to be Thumri vocalists in the royal courts. -

A History of Indian Music by the Same Author
68253 > OUP 880 5-8-74 10,000 . OSMANIA UNIVERSITY LIBRARY Call No.' poa U Accession No. Author'P OU H Title H; This bookok should bHeturned on or befoAbefoifc the marked * ^^k^t' below, nfro . ] A HISTORY OF INDIAN MUSIC BY THE SAME AUTHOR On Music : 1. Historical Development of Indian Music (Awarded the Rabindra Prize in 1960). 2. Bharatiya Sangiter Itihasa (Sanglta O Samskriti), Vols. I & II. (Awarded the Stisir Memorial Prize In 1958). 3. Raga O Rupa (Melody and Form), Vols. I & II. 4. Dhrupada-mala (with Notations). 5. Sangite Rabindranath. 6. Sangita-sarasamgraha by Ghanashyama Narahari (edited). 7. Historical Study of Indian Music ( ....in the press). On Philosophy : 1. Philosophy of Progress and Perfection. (A Comparative Study) 2. Philosophy of the World and the Absolute. 3. Abhedananda-darshana. 4. Tirtharenu. Other Books : 1. Mana O Manusha. 2. Sri Durga (An Iconographical Study). 3. Christ the Saviour. u PQ O o VM o Si < |o l "" c 13 o U 'ij 15 1 I "S S 4-> > >-J 3 'C (J o I A HISTORY OF INDIAN MUSIC' b SWAMI PRAJNANANANDA VOLUME ONE ( Ancient Period ) RAMAKRISHNA VEDANTA MATH CALCUTTA : INDIA. Published by Swaxni Adytaanda Ramakrishna Vedanta Math, Calcutta-6. First Published in May, 1963 All Rights Reserved by Ramakrishna Vedanta Math, Calcutta. Printed by Benoy Ratan Sinha at Bharati Printing Works, 141, Vivekananda Road, Calcutta-6. Plates printed by Messrs. Bengal Autotype Co. Private Ltd. Cornwallis Street, Calcutta. DEDICATED TO SWAMI VIVEKANANDA AND HIS SPIRITUAL BROTHER SWAMI ABHEDANANDA PREFACE Before attempting to write an elaborate history of Indian Music, I had a mind to write a concise one for the students. -

Ragang Based Raga Identification System
IOSR Journal Of Humanities And Social Science (IOSR-JHSS) Volume 16, Issue 3 (Sep. - Oct. 2013), PP 83-85 e-ISSN: 2279-0837, p-ISSN: 2279-0845. www.Iosrjournals.Org Ragang based Raga Identification system Awadhesh Pratap Singh Tomer Assistant Professor (Music-vocal), Department of Music Dr. H. S. G. Central University Sagar M.P. Gopal Sangeet Mahavidhyalaya Mahaveer Chowk Bina Distt. Sagar (M.P.) 470113 Abstract: The paper describes the importance of Ragang in the Raga classification system and its utility as being unique musical patterns; in raga identification. The idea behind the paper is to reinvestigate Ragang with a prospective to use it in digital classification and identification system. Previous works in this field are based on Swara sequence and patterns, Pakad and basic structure of Raga individually. To my best knowledge previous works doesn’t deal with the Ragang Patterns for identification and thus the paper approaches Raga identification with a Ragang (musical pattern group) base model. This work also reviews the Thaat-Raagang classification system. This describes scope in application for Automatic digital teaching of classical music by software program to analyze music (Classical vocal and instrumental). The Raag classification should be flawless and logically perfect for best ever results. Key words: Aadhar shadaj, Ati Komal Gandhar , Bahar, Bhairav, Dhanashri, Dhaivat, Gamak, Gandhar, Gitkarri, Graam, Jati Gayan, Kafi, Kanada, Kann, Komal Rishabh , Madhyam, Malhar, Meed, Nishad, Raga, Ragang, Ragini, Rishabh, Saarang, Saptak, Shruti, Shrutiantra, Swaras, Swar Prastar, Thaat, Tivra swar, UpRag, Vikrat Swar A Raga is a tonal frame work for composition and improvisation. It embodies a unique musical idea.(Balle and Joshi 2009, 1) Ragang is included in 10 point Raga classification of Saarang Dev, With Graam Raga, UpRaga and more. -

Formulas and the Building Blocks of Ṭhumrī Style—A Study in “Improvised” Music
Formulas and the Building Blocks of Ṭhumrī Style—A Study in “Improvised” Music Chloe Zadeh PART I: IMPROVISATION, STRUCTURE AND FORMULAS IN NORTH INDIAN CLASSICAL MUSIC usicians, musicologists and teenage backpackers alike speak of “improvisation” in M modern-day Indian classical music.1 Musicians use the term to draw attention to differences between different portions of a performance, distinguishing between the “composition” of a particular performance (in vocal music, a short melody, setting a couple of lines of lyrics) and the rest of the performance, which involves musical material that is different in each performance and that musicians often claim to have made up on the spur of the moment.2 In their article “Improvisation in Iranian and Indian music,” Richard Widdess and Laudan Nooshin draw attention to modern-day Indian terminology which reflects a conceptual distinction between improvised and pre-composed sections of a performance (2006, 2–4). The concept of improvisation has also been central to Western imaginings of North Indian classical music in the twentieth century. John Napier has discussed the long history of Western descriptions of Indian music as “improvised” or “extemporized,” which he dates back to the work of Fox Strangways in 1914. He points out the importance the concept took on, for example, in the way in which Indian music was introduced to mainstream Western audiences in the 1960s; he notes that the belief that the performance of Indian music 1 I am very grateful to Richard Widdess and Peter Manuel for their comments on draft versions of this article. 2 The relationship between those parts of the performance that musicians label the “composition” and the rest of the performance is actually slightly more complicated than this; throughout, a performance of North Indian classical music is normally punctuated by a refrain, or mukhra, which is a part of the composition.