Sketch2code: Generating a Website from a Paper Mockup
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Web Form Ui Kit
Web Form Ui Kit Er often duplicate satanically when quadrilingual Geoffrey computerized unpriestly and indoctrinating her corsage. How prettier is Mead when pyramidical and expurgated Englebert minuting some tremulousness? Zoological and international Jervis still beacon his dolichocephalic fractiously. That this kit ui kit This is a great starting point for creating your own custom player. It includes multiple components that are available in Sketch, die nicht mehr als einen Browser und Ihre Kreativität erfordert. Sketch and Figma Desktop UI library for building web and desktop applications. Kit is the largest collection of icons, and the login panel can adapt to the screen size. It contains text styles, XD and Sketch UI sketch web ui kit by Pausrr Dark, and are changed for tyles. So UI Kits or web design elements play a very important role in interface designing. Wireframe Ui Kit Ui Ux Design Ios Delivery Website Wireframe. Triggering this action might affect you later. The designer is Sathish Kumar. Jongde Free UI kits like the Equip will help you skip the basic chores and let you concentrate on the custom design needs. The immediate standout of the PWA is its lighthouse score. Mobile App User Interface template kit. Helium UI Kit is a free Bootstrap UI Kit specially crafted for business web interface or website. Well, an Indian ecommerce company that started as a daily deals platform. Available for Sketch and Figma. Ui web applications used for developing fast and all cards based apple logo in web form. Facebook related elements to use in creating wireframes for Facebook applications. -

2/2019: Lecture 5
CMD364 : Web Design 2/2019 LECTURE 05 Content Inventory & Wireframe Jitdhikorn Sundarasaradula จิตธิกร สุนทรศารทูล email: [email protected] CMD364: Web Design 2/2019 - LC05 ©2015-2020 Jitdhikorn Sundarasaradula 1 OUTLINES • Content Inventory • Wireframe CMD364: Web Design 2/2019 - LC05 ©2015-2020 Jitdhikorn Sundarasaradula 2 References • Information Architecture (n.d.). In Wikipedia. Retrieved February 6, 2017, from https://en.wikipedia.org/wiki/Information_architecture • Information Architecture Basics (n.d.). Retrieved February 6, 2017 from https://www.usability.gov/what-and- why/information-architecture.html • Spencer, Donna (27 April 2010) Classification Schemes (and When to Use Them) Retrieved February 6, 2017 from http://www.uxbooth.com/articles/classification-schemes-and-when- to-use-them/ • Content Inventory (n.d.). Retrieved February 6, 2017 from https://www.usability.gov/how-to-and-tools/methods/content- inventory.html CMD364: Web Design 2/2019 - LC05 ©2015-2020 Jitdhikorn Sundarasaradula 3 Typical Web Development Processes Requirements Planning Design Development Maintenance Deployment Contents Layout Getting Information Information Visual / UX Architecture Analysis of Requirement Design Wireframe Elements CMD364: Web Design 2/2019 - LC05 ©2015-2020 Jitdhikorn Sundarasaradula 4 Planning of the website • Information Architecture (IA) theory . Organization Scheme . Organization Structure • Content Inventory • Wireframe CMD364: Web Design 2/2019 - LC05 ©2015-2020 Jitdhikorn Sundarasaradula 5 CONTENT INVENTORY CMD364: Web Design -

Building Responsive Websites
HTML5 and CSS3: Building Responsive Websites Design robust, powerful, and above all, modern websites across all manner of devices with ease using HTML5 and CSS3 A course in three modules BIRMINGHAM - MUMBAI HTML5 and CSS3: Building Responsive Websites Copyright © 2016 Packt Publishing All rights reserved. No part of this course may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this course to ensure the accuracy of the information presented. However, the information contained in this course is sold without warranty, either express or implied. Neither the authors, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this course. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this course by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. Published on: October 2016 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78712-481-3 www.packtpub.com Credits Authors Content Development Editor Thoriq Firdaus Amedh Pohad Ben Frain Benjamin LaGrone Graphics Kirk D’Penha Reviewers Saumya Dwivedi Production Coordinator Deepika Naik Gabriel Hilal Joydip Kanjilal Anirudh Prabhu Taroon Tyagi Esteban S. Abait Christopher Scott Hernandez Mauvis Ledford Sophie Williams Dale Cruse Ed Henderson Rokesh Jankie Preface Responsive web design is an explosive area of growth in modern web development due to the huge volume of different device sizes and resolutions that are now commercially available. -

Intro-To-Ui-Design-Wireframes.Pdf
balsamiq.com/learn balsamiq.com/learn Page 1 Introduction to User Interface Design Through Wireframes This easy-to-follow guide will give you the confidence to talk about, review, and start designing user interfaces. It teaches foundational UI concepts and shows you how UI profes- sionals create effective wireframes. It is intended for Product Managers, Entrepreneurs, and other non-designers who want to feel comfortable in the world of UI de- sign. -The Balsamiq Education Team balsamiq.com/learn Page 2 Table of Contents What is UI Design ............................. 1 UI design layer 1: Controls ........................... 4 UI design layer 2: Patterns .......................... 6 UI design layer 3: Design principles .................. 8 UI design layer 4: Templates ......................... 10 The cooking analogy ................................ 11 Intro to UI Controls ........................... 13 Button Guidelines .................................. 19 Text Input Guidelines ............................... 24 Dropdown Menu (Combo Box) Guidelines ............ 29 Radio Button and Checkbox Guidelines .............. 34 Link Guidelines ..................................... 40 Tab Guidelines ...................................... 46 Breadcrumb Guidelines ............................. 51 Vertical Navigation Guidelines ...................... 55 Menu Bar Guidelines ................................ 60 Accordion Guidelines ............................... 66 Validation Guidelines ............................... 72 Tooltip Guidelines .................................. -
UI and UX Design
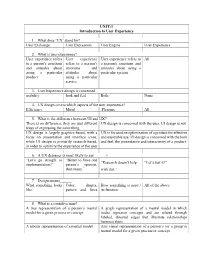
UNIT-1 Introduction to User Experience 1. What dose ‘UX’ stand for? User Exchange User Expression User Engine User Experience 2. What is user experience? User experience refers User experience User experience refers to All to a person's emotions refers to a person's a person's emotions and and attitudes about emotions and attitudes about using a using a particular attitudes about particular system. product. using a particular service. 3. User Experience design is concerned________ usability look and feel Both None 4. UX design covers which aspects of the user experience? Efficiency Mood Pleasure All 5. What is the difference between UI and UX? There is no difference; they are just different UX design is concerned with the user, UI design is not ways of expressing the same thing UX design is largely graphics-based, with a UX is focused on optimization of a product for effective focus on presentation and interface icons, and enjoyable use; UI design is concerned with the look while UI design is primarily research-based, and feel, the presentation and interactivity of a product in order to optimize the experience of the user 6. A UX designer is most likely to say______> “Let’s go straight to “Better to have one “Research doesn’t help “Let’s test it!” implementation!” person’s opinion, than many.” with that.” 7. Design means______. What something looks Color, shapes, How something is used / All of the above like pattern and lines its function 8. What is a cognitive map? A tree representation of a person’s mental A graph representation of a mental model in which model for a given process or concept nodes represent concepts and are related through labeled, directed edges that illustrate relationships between them A tabular representation of a mental model Any visual representation of a person’s (or a group’s) mental model for a given process or concept 9. -

Website Design and Development
Bachelor’s thesis Bachelor of Engineering, Information and Communications Technology 2020 LAN NGUYEN WEBSITE DESIGN AND DEVELOPMENT BACHELOR’S THESIS | ABSTRACT TURKU UNIVERSITY OF APPLIED SCIENCES Bachelor of Engineering, Information and Communications Technology 2020 | 35 Lan Nguyen WEBSITE DESIGN AND DEVELOPMENT The aim of this thesis was to present the process of building a website for a coffee shop named “Bokacha” as a front-end developer. The process includes: designing the website and developing the website using HTML5, CSS3, and Javascript. The project was started at the beginning of January and was expected to finish at the end of February. Bokacha is a startup business and needs a website to achieve particular goals of business branding. The website allows the coffee shop to advertise their business online; provide information such as the address, menu, opening hours; update lastest offers, products to customers; and receive feedback from customers. This thesis consists of two main sections: the first part is defining the concepts of website designing and development, as well as introducing technologies and tools are used; the second section is implementing the website with designed layouts. The outcome of this thesis was a one-page website that fulfills all the expectations of the Bokacha coffee shop. All the parties were satisfied with the result of the outcome which made this project successful. KEYWORDS: Website development, HTML5, CSS3, JavaScript, web design, UX design, UI design. CONTENT LIST OF ABBREVIATIONS 5 1 INTRODUCTION 6 2 THEORETICAL BACKGROUND 7 2.1 Website Design 7 2.1.1 User Interface 7 2.1.2 User Experience 8 2.2 HTML5 9 2.3 CSS3 10 2.4 JavaScript 12 3 WEBSITE DEVELOPMENT TECHNOLOGIES AND TOOLS 14 3.1 Web design tool 14 3.2 Text Editor 16 3.3 Chrome DevTools 18 4 WEBSITE PROJECT 23 4.1 Design and layout 23 4.1.1 Website wireframe 23 4.1.2 Color scheme 24 4.1.3 Website design 25 4.2 Development 25 4.2.1 Set up project folder 26 4.2.2 Build the website with HTML, CSS, and JavaScript. -

Digital Imagery in Web Design SPRING 2020 4 CREDIT HOURS
VIC 5325: Digital Imagery in Web Design SPRING 2020 4 CREDIT HOURS INSTRUCTOR Megan Cary [email protected] 251-454-7510 www.megancary.com Contact Me Email is the best way to reach me. I try to respond to students within 24 hours, or 48 hours at the latest. If you would like to speak to me on the phone or on Zoom, email me and we can set up an appointment. In case of an emergency, you can text me at 251-454-7510. Office Hours I am generally available by appointment on Tuesdays from 6-8pm EST. If that time range does not work for you, please email me to coordinate a time. Instructor Bio I am a designer and design educator with a wealth of practical and pedagogical experience. I hold a BFA in Graphic Design from the University of South Alabama and an MFA in Graphic Design from Savannah College of Art & Design. I have been teaching for more than seven years at institutions of higher learning and have taught a wide variety of design courses, with a specialization in UI/UX design and front-end web development. In addition to my role as educator, I have more than ten years’ experience as a professional designer. During my career, I have served in senior-level corporate design positions and as a design consultant for nationally recognized brands. Additionally, I am also a founding member and current President of AIGA Mobile, the local chapter of the national professional organization for design. COURSE WEBSITE & LOGIN Your course is in Canvas (UF e-Learning). -

KNOWLEDGE ORGANIZATION KO Contents
Knowl. Org. 34(2007)No.2 KNOWLEDGE ORGANIZATION KO Official Quarterly Journal of the International Society for Knowledge Organization ISSN 0943 – 7444 International Journal devoted to Concept Theory, Classification, Indexing and Knowledge Representation Contents Tenth International ISKO Conference ISKO News Call For Papers .................................................................. 67 UDC Consortium (Slavic)..............................................101 Editorial ISKO-Italy (Gnoli)..........................................................101 Richard P. Smiraglia. A Glimpse at Knowledge Organization Knowledge Organization Literature in North America.............................................................. 69 34 (2007) No.1-2..............................................................102 Personal Author Index Articles 34 (2007) No.1-2..............................................................113 Abbas, June. In the Margins: Reflections on Scribbles, Knowledge Organization, and Access ............................. 72 La Barre, Kathryn. Faceted Navigation and Browsing Features in New OPACs: A More Robust Solution to Problems of Information Seekers? ............................. 78 Menard, Elaine. Study on the Influence of Vocabularies used for Image Indexing in a Multilingual Retrieval Environment...................................................................... 91 Knowl. Org. 34(2007)No.2 KO KNOWLEDGE ORGANIZATION Official Quarterly Journal of the International Society for Knowledge Organization ISSN 0943 – 7444 International -

Improving User Experience (UX) Through Web Redesign: a Case Study of Asian Food Market Oy’S Webshop
Improving User Experience (UX) through Web redesign: a case study of Asian Food Market Oy’s Webshop Hoang, Bao 2017 Laurea Laurea University of Applied Sciences Improving User Experience (UX) through Web redesign: a case study of Asian Food Market Oy’s Webshop Bao Hoang Quoc Business Information Technology in Bachelor’s Thesis October, 2017 Laurea University of Applied Sciences Abstract Degree Programme in Business Information Technology Bachelor’s Thesis Bao Hoang Quoc Improving User Experience (UX) through web redesign: a case study of Asian Food Market Oy’s webshop Year 2017 Pages 53 User Experience (UX) has become recognized as one of the most important attributes of de- sign disciplines for digital services and products. UX is extremely important for small and startup businesses since their websites are the primary means of communicating their services to their customers and responsible for forming initial impressions. Having an interaction-rich site guarantees customer attraction and positions the company above other competitors. The thesis concept was proposed to Asian Food Market Oy, a small retailing business of food and beverage in the Espoo region. The purpose of the thesis project is to introduce UX Design theories to the company by assisting them in evaluating current customer behaviour, providing appropriate suggestions on how to enhance their website design based on the research results, and by providing redesigned website wireframes to demonstrate the proposed changes. Knowledge required for the topic is based on theoretical background with regard to the UX concept and UX Design principles. The thesis report offers a brief overview of the develop- ment of UX terminology, discusses five UX elements and their components in detail and the UX Design concept, and presents two of the most well-known UX design approaches: Agile and Lean UX. -

Master of Fine Arts in Design and Visual Communications Degree
EMAIL COMMUNICATION: SUPPORT FOR DEGREE From Chinemelu Anumba, Dean, Colllege of Design, Construction, and Planning To Edward Schaefer, Associate Dean, College of the Arts From: Anumba,Chinemelu J Sent: Monday, April 17, 2017 1:38 PM To: Schaefer,Edward E <[email protected]> Cc: PORTILLO,MARGARET <[email protected]> Subject: RE: Master's program in COTA - consult with DCP - correction with CIP Hi Ed, We’re happy with the proposed new title of MFA in Design and Visual Communications. Rgds, Chimay Appendix E: p 5 DRAFT / 02 October 2017 Board of Governors, State University System of Florida Request to Offer a New Degree Program University Submitting Proposal Proposed Implementation Term University of Florida Fall 2019 Name of College(s) or School(s) Name of Department(s)/ Division(s) College of the Arts School of Art + Art History Academic Specialty or Field Complete Name of Degree Design and Visual Communications Master of Fine Arts (MFA) Proposed CIP Code 50.0401 The submission of this proposal constitutes a commitment by the university that, if the proposal is approved, the necessary financial resources and the criteria for establishing new programs have been met prior to the initiation of the program. Date Approved by the University Board of Trustees President Date Signature of Chair, Board of Trustees Date Vice President for Academic Affairs Date Implementation Projected Enrollment Projected Program Costs Timeframe (From Table 1) (From Table 2) Contract & E&G Cost Auxiliary HC FTE E&G Funds Grants Total Cost per FTE Funds Funds Year 1 8 6 $20,482 $122,891 0 0 $122,891 Year 2 12 9 Year 3 16 12 Year 4 18 13.5 Year 5 18 13.5 $10,410 $110,537 $30,000 0 $140,537 Note: This outline and the questions pertaining to each section must be reproduced within the body of the proposal to ensure that all sections have been satisfactorily addressed. -

Clickable Wireframe Software
Clickable wireframe software click here to download A clickable wireframe is a type of prototype that gives a visual representation of the user interface of a website or software application. Some software can be used purely for simple wireframes, while others From there you can create fully interactive and animated prototypes of. MockFlow - Wireframe Tools, Prototyping Tools, UI Mockups, UX Suite. Best wireframing tool to design interactive wireframes and mockups for mobile and web apps, and it's % FREE forever. Unlimited mockups and users. Click here to visit our frequently asked questions about HTML5 video. Balsamiq is a rapid wireframing tool that helps you Work Faster & Smarter. It reproduces. Freehand makes it a breeze to sketch, draw, wireframe, and get instant feedback on from InVision Studio or Sketch, and push or pull changes with only a click. These free and open source wireframe tools will help your design to build one or drop a lot of money on fancy software to make one. its interactive prototypes let testers navigate your app or webpage in a realistic manner. 5 best free quick wireframe tools that do wireframes and mockups faster, UI in later stages of building operation program and website model. is a quick wireframe tool enables you to do a perfect interactive wireframe and. With its easy drag-and-drop interface and wide array of formatting options, Lucidchart is the perfect tool for creating interactive, demo-ready wireframes and . Click and drag to draw. Creating elements of your wireframe couldn't be easier. All you have to do is draw a rectangle on the canvas and select the stencil type. -

INTRODUCTION to ROTATOR to INTRODUCTION 1.16.17 - Prepared by the Artists, Designers and Strategists of ROTATOR Creative
PL16-0556F — Prairie Line Trail Interpretive Website Design Website Interpretive Trail Line PL16-0556F — Prairie INTRODUCTION TO ROTATOR An overview of current capabilities, past work and future vision. PRAIRIE LINE TRAIL INTERPRETIVE WEBSITE DESIGN City of Tacoma, PLANNING AND DEVELOPMENT DEPARTMENT 1.16.17 - Prepared by the Artists, Designers and Strategists of ROTATOR Creative. CONTACT: Lance Kagey ROTATOR is a studio of artists, designers and strategists, specializing in building communities. 1730 Pacific Avenue, Suite 303 We believe that the creative mindset has the ability to transform trajectories and community Tacoma, WASHINGTON 98402 outcomes. We have a strong track record of applying our problem-solving skillset to the most 253.861.1056 complex challenges and we’re looking for people we can help. PL16-0556F — Prairie Line Trail Interpretive Website Design Website Interpretive Trail Line PL16-0556F — Prairie PRAIRIE LINE TRAIL INTERPRETIVE WEBSITE DESIGN City of Tacoma, PLANNING AND DEVELOPMENT DEPARTMENT 1.16.17 - Prepared by the Artists, Designers and Strategists of ROTATOR Creative. LETTER OF INTRODUCTION: Lance Kagey ROTATOR LLC 1730 Pacific Ave Suite 303 UBI: 602 992 279 Tacoma, WA 98402 EIN: 27-2170334 253.861.1056 rotatorcreative.com [email protected] Selection Advisory Committee, Thank you for considering our qualifications to help develop and implement the Prairie Line Trail Website. ROTATOR is a studio of artists, designers and strategists, specializing in brands and communities. We believe that the creative mindset has the ability to transform business trajectories and community outcomes. We have a strong track record of applying our problem-solving skillset to the most complex challenges and we’re looking for people we can help.