Evaluating Prerequisite Qualities for Learn
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

In English C Writing U
U Writing C in nglish -VolumeE - XV/2016 U Writing C English -Volume XV/2016~ Preface to the Poetry Section “We don’t read and write poetry because it’s cute. We read and write This collection contains part of the fruits of our learning. Here you will poetry because we are members of the human race. And the human find the languages of simplicity and relative sophistication; throbbing race is filled with passion. And medicine, law, business, engineering, tales of love, loss, joy, rage, remorse, and so on; most importantly, you these are noble pursuits and necessary to sustain life. But poetry, will hear the rhythms of thirty beating hearts. However different they beauty, romance, love, these are what we stay alive for.” sound, they are the same in the sense that they hope those outpourings —John Keating, ‘Dead Poets Society’ of the soul might, at certain points, perhaps help prove how poetry keeps us alive. Similarly, we appreciate and attempt to write poetry not only for aesthetic pleasure or intellectual fireworks; we love poetry because it Thank you. shows us the breadth and depth of humanity. Poetry awakens the most innate human qualities in us, distils our human essence, and shows us Carren Wong, Gabrielle Tsui, Liz Wan what it truly means to be human. Editors Of course, being merely students, we are far from being able to demonstrate the divine qualities of poetry; rather, through learning to write poems, we have gained insight into the beauty and magic of acclaimed poetry, and by engaging with those masterpieces, we have found more and better ways to express ourselves. -
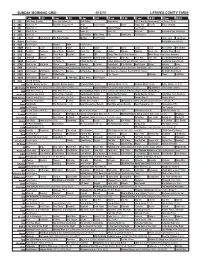
Sunday Morning Grid 4/12/15 Latimes.Com/Tv Times
SUNDAY MORNING GRID 4/12/15 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) Bull Riding Remembers 2015 Masters Tournament Final Round. (N) Å 4 NBC News (N) Å Meet the Press (N) Å News Paid Program Luna! Poppy Cat Tree Fu Figure Skating 5 CW News (N) Å In Touch Hour Of Power Paid Program 7 ABC News (N) Å This Week News (N) News (N) News Å Explore Incredible Dog Challenge 9 KCAL News (N) Joel Osteen Mike Webb Paid Woodlands Paid Program 11 FOX In Touch Joel Osteen Fox News Sunday Midday Paid Program I Love Lucy I Love Lucy 13 MyNet Paid Program Red Lights ›› (2012) 18 KSCI Paid Program Church Faith Paid Program 22 KWHY Cosas Local Jesucristo Local Local Gebel Local Local Local Local RescueBot RescueBot 24 KVCR Painting Dewberry Joy of Paint Wyland’s Paint This Painting Kitchen Mexico Cooking Chefs Life Simply Ming Lidia 28 KCET Raggs Space Travel-Kids Biz Kid$ News TBA Things That Aren’t Here Anymore More Things Aren’t Here Anymore 30 ION Jeremiah Youssef In Touch Bucket-Dino Bucket-Dino Doki (TVY) Doki Ad Dive, Olly Dive, Olly E.T. the Extra-Terrestrial 34 KMEX Paid Program Al Punto (N) Fútbol Central (N) Fútbol Mexicano Primera División: Toluca vs Atlas República Deportiva (N) 40 KTBN Walk in the Win Walk Prince Carpenter Liberate In Touch PowerPoint It Is Written Best Praise Super Kelinda Jesse 46 KFTR Paid Program Hocus Pocus ›› (1993) Bette Midler. -

NATO Feb 05 NL.Indd
February 2005 NANATOTO of California/NevadaCalifornia/Nevada Information for the California and Nevada Motion Picture Theatre Industry THE CALIFORNIA POPCORN TAX CALENDAR By Duane Sharpe, Hutchinson and Bloodgood LLP of EVENTS & The California State Board of Equalization (the Board) recently issued an Opinion on a refund HOLIDAYS of sales tax to a local theatre chain (hereafter, the Theatre). The detail of the refund wasn’t discussed in the opinion, but the Board did focus on two specifi c issues that affected the refund. February 6 California tax law requires the assessment of sales tax on the sale of all food products when sold Super Bowl Sunday for consumption within a place that charges admission. The Board noted that in all but one loca- tion, the Theatre had changed their operations regarding admissions to its theatre buildings. Instead February 12 of requiring customers to fi rst purchase tickets to enter into the theatre building lobby in which all Lincoln’s Birthday food and drinks were sold, the Theatre opened each lobby to the general public without requiring tickets. The Theatre only required tickets for the customers to enter further into the inside movie February 14 viewing areas of the theatres. This admission policy allowed the Theatre not to charge sales tax on Valentine’s Day “popcorn sales.” California tax law requires the assessment of sales tax on the sale of “hot prepared food products.” The issue before the Board was whether the popcorn sold by the Theatre was a hot February 21 prepared food product. President’s Day From the Opinion: “Claimant’s process for making popcorn starts with a popper. -

A Study on International Communication Strategies of Chinese-Language Films Liang Dinga and Wenjing Zhangb No
2018 3rd International Conference on Society Science and Economics Development (ICSSED 2018) ISBN: 978-1-60595-031-0 A Study on International Communication Strategies of Chinese-language Films Liang Dinga and Wenjing Zhangb No. 462, Heyan Road, Qixia District, Nanjing City, Jiangsu Prov., China [email protected], [email protected] Keywords: Chinese-language Films, International Communication, Strategies. Abstract. Starting with the characteristics of Chinese-language films, this paper focuses on analyzing the international influence of Chinese-language films and the problems of their international communication, as well as explores the relative strategies in order to promote the international communication of Chinese-language films, and enhance their international influence at the same time. 1.Introduction The Chinese-language film is an important way to show the image of our country to the world and also spread Chinese culture, so as to improve the international understanding of Chinese culture. Since 20th century, Chinese-language films have gradually gone global wide and begun to spread abroad. Chinese-language films have the characteristics of being commercial, artistic, international and comprehensive, which has an important influence on the development of films around the world. However, in the process of international communication, Chinese-language films also face the problems of cultural and language barriers, insufficient use of international market, similar themes, imperfect international marketing and so forth, so that their international communication has not achieved the intended effect. In view of this situation, China actively explores the scientific approach to international communication of Chinese-language films with the purpose of strengthening their international influence. -

Written & Directed by and Starring Stephen Chow
CJ7 Written & Directed by and Starring Stephen Chow East Coast Publicity West Coast Publicity Distributor IHOP Public Relations Block Korenbrot PR Sony Pictures Classics Jeff Hill Melody Korenbrot Carmelo Pirrone Jessica Uzzan Judy Chang Leila Guenancia 853 7th Ave, 3C 110 S. Fairfax Ave, #310 550 Madison Ave New York, NY 10019 Los Angeles, CA 90036 New York, NY 10022 212-265-4373 tel 323-634-7001 tel 212-833-8833 tel 212-247-2948 fax 323-634-7030 fax 212-833-8844 fax 1 Short Synopsis: From Stephen Chow, the director and star of Kung Fu Hustle, comes CJ7, a new comedy featuring Chow’s trademark slapstick antics. Ti (Stephen Chow) is a poor father who works all day, everyday at a construction site to make sure his son Dicky Chow (Xu Jian) can attend an elite private school. Despite his father’s good intentions to give his son the opportunities he never had, Dicky, with his dirty and tattered clothes and none of the “cool” toys stands out from his schoolmates like a sore thumb. Ti can’t afford to buy Dicky any expensive toys and goes to the best place he knows to get new stuff for Dicky – the junk yard! While out “shopping” for a new toy for his son, Ti finds a mysterious orb and brings it home for Dicky to play with. To his surprise and disbelief, the orb reveals itself to Dicky as a bizarre “pet” with extraordinary powers. Armed with his “CJ7” Dicky seizes this chance to overcome his poor background and shabby clothes and impress his fellow schoolmates for the first time in his life. -

Walpole Public Library DVD List A
Walpole Public Library DVD List [Items purchased to present*] Last updated: 9/17/2021 INDEX Note: List does not reflect items lost or removed from collection A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Nonfiction A A A place in the sun AAL Aaltra AAR Aardvark The best of Bud Abbot and Lou Costello : the Franchise Collection, ABB V.1 vol.1 The best of Bud Abbot and Lou Costello : the Franchise Collection, ABB V.2 vol.2 The best of Bud Abbot and Lou Costello : the Franchise Collection, ABB V.3 vol.3 The best of Bud Abbot and Lou Costello : the Franchise Collection, ABB V.4 vol.4 ABE Aberdeen ABO About a boy ABO About Elly ABO About Schmidt ABO About time ABO Above the rim ABR Abraham Lincoln vampire hunter ABS Absolutely anything ABS Absolutely fabulous : the movie ACC Acceptable risk ACC Accepted ACC Accountant, The ACC SER. Accused : series 1 & 2 1 & 2 ACE Ace in the hole ACE Ace Ventura pet detective ACR Across the universe ACT Act of valor ACT Acts of vengeance ADA Adam's apples ADA Adams chronicles, The ADA Adam ADA Adam’s Rib ADA Adaptation ADA Ad Astra ADJ Adjustment Bureau, The *does not reflect missing materials or those being mended Walpole Public Library DVD List [Items purchased to present*] ADM Admission ADO Adopt a highway ADR Adrift ADU Adult world ADV Adventure of Sherlock Holmes’ smarter brother, The ADV The adventures of Baron Munchausen ADV Adverse AEO Aeon Flux AFF SEAS.1 Affair, The : season 1 AFF SEAS.2 Affair, The : season 2 AFF SEAS.3 Affair, The : season 3 AFF SEAS.4 Affair, The : season 4 AFF SEAS.5 Affair, -

Films Shown by Series
Films Shown by Series: Fall 1999 - Winter 2006 Winter 2006 Cine Brazil 2000s The Man Who Copied Children’s Classics Matinees City of God Mary Poppins Olga Babe Bus 174 The Great Muppet Caper Possible Loves The Lady and the Tramp Carandiru Wallace and Gromit in The Curse of the God is Brazilian Were-Rabbit Madam Satan Hans Staden The Overlooked Ford Central Station Up the River The Whole Town’s Talking Fosse Pilgrimage Kiss Me Kate Judge Priest / The Sun Shines Bright The A!airs of Dobie Gillis The Fugitive White Christmas Wagon Master My Sister Eileen The Wings of Eagles The Pajama Game Cheyenne Autumn How to Succeed in Business Without Really Seven Women Trying Sweet Charity Labor, Globalization, and the New Econ- Cabaret omy: Recent Films The Little Prince Bread and Roses All That Jazz The Corporation Enron: The Smartest Guys in the Room Shaolin Chop Sockey!! Human Resources Enter the Dragon Life and Debt Shaolin Temple The Take Blazing Temple Blind Shaft The 36th Chamber of Shaolin The Devil’s Miner / The Yes Men Shao Lin Tzu Darwin’s Nightmare Martial Arts of Shaolin Iron Monkey Erich von Stroheim Fong Sai Yuk The Unbeliever Shaolin Soccer Blind Husbands Shaolin vs. Evil Dead Foolish Wives Merry-Go-Round Fall 2005 Greed The Merry Widow From the Trenches: The Everyday Soldier The Wedding March All Quiet on the Western Front The Great Gabbo Fires on the Plain (Nobi) Queen Kelly The Big Red One: The Reconstruction Five Graves to Cairo Das Boot Taegukgi Hwinalrmyeo: The Brotherhood of War Platoon Jean-Luc Godard (JLG): The Early Films, -

Bamcinématek Presents Stephen Chow: the King of Comedy, Oct 6—12
BAMcinématek presents Stephen Chow: The King of Comedy, Oct 6—12 “The reigning king of Hong Kong comedy.”—J. Hoberman Co-presented with the Hong Kong Economic and Trade Office in New York. The Wall Street Journal is the title sponsor for BAM Rose Cinemas and BAMcinématek. Brooklyn, NY/Sep 8, 2014—From Monday, October 6 through Sunday, October 12, BAMcinématek presents Stephen Chow: The King of Comedy, an eight-film retrospective of the Hong Kong actor, writer, and director. Chow’s audaciously anarchic comedies combine surreal sight gags, non sequiturs, extensive pop culture quoting, and gravity-defying martial arts to sublimely silly effect. Endlessly inventive, the reigning king of Hong Kong mo lei tau (―nonsense comedy‖) yields unfiltered cinematic pleasure. Initially prominent as a children’s television star, Chow became synonymous with mo lei tau, a style of film comedy in which traditional melodramas and kung fu tales are peppered with rapid- fire, fourth-wall-breaking slapstick bits and corny puns. A bigger box-office draw in his homeland than Jackie Chan or Jet Li, Chow—who cites Spielberg and Kubrick, along with Jim Carrey, as influences—has used his clout in recent years to fashion himself as an auteur, scripting, editing, and directing a series of high-budget, homage-filled blockbusters. Typical of Chow’s earliest hits, Johnnie To’s Justice, My Foot! (1992—Oct 8) casts the actor as a fast-talking lawyer whose mouth gets him into trouble, and whose kung fu-fighting wife gets him out of it—one of many tough, smart heroines Chow uses as foils for his feckless alter egos. -

Build a Be4er Neplix, Win a Million Dollars?
Build a Be)er Ne,lix, Win a Million Dollars? Lester Mackey 2012 USA Science and Engineering FesDval Nelix • Rents & streams movies and TV shows • 100,000 movie Dtles • 26 million customers Recommends “Movies You’ll ♥” Recommending Movies You’ll ♥ Hated it! Loved it! Recommending Movies You’ll ♥ Recommending Movies You’ll ♥ How This Works Top Secret Now I’m Cinematch Computer Program I don’t unhappy! like this movie. Your Predicted Rang: Back at Ne,lix How can we Let’s have a improve contest! Cinematch? What should the prize be? How about $1 million? The Ne,lix Prize October 2, 2006 • Contest open to the world • 100 million movie rangs released to public • Goal: Create computer program to predict rangs • $1 Million Grand Prize for beang Cinematch accuracy by 10% • $50,000 Progress Prize for the team with the best predicDons each year 5,100 teams from 186 countries entered Dinosaur Planet David Weiss David Lin Lester Mackey Team Dinosaur Planet The Rangs • Training Set – What computer programs use to learn customer preferences – Each entry: July 5, 1999 – 100,500,000 rangs in total – 480,000 customers and 18,000 movies The Rangs: A Closer Look Highest Rated Movies The Shawshank RedempDon Lord of the Rings: The Return of the King Raiders of the Lost Ark Lord of the Rings: The Two Towers Finding Nemo The Green Mile Most Divisive Movies Fahrenheit 9/11 Napoleon Dynamite Pearl Harbor Miss Congeniality Lost in Translaon The Royal Tenenbaums How the Contest Worked • Quiz Set & Test Set – Used to evaluate accuracy of computer programs – Each entry: Rang Sept. -

Brattle Theatre Film Notes: Au Began His Career As a Cine- the 1980S
Brattle Theatre Film Notes: au began his career as a cine- the 1980s. Hong Kong cinema Hong Kong, 2002. R. 101 min. matographer, working on films experienced a resurgence in the Cast: Andy Lau, Tony Leung Chiu Lsuch as “Where’s Officer Tuba?” 1980s and early 1990s with the Wai, Anthony Wong Chau-Sang, in 1986 and “Chungking Express” in release of films like director John Eric Tsang; Writer: Felix Chong; Woo’s “A Better Tomorrow” (1986) Cinematographer: Yiu-Fai Lai; 1994. He started his dire c t o r i a l Pr oducer: Andy Lau; Direc t o r s : career with 1987’s “The Ultimate and “The Killer” (1989) both with ( Wai Keung Lau, Alan Mak ) Vampire” and has since worked on action star Chow Yun-Fat. The films movies like the “Best of the Best” w e re known for their chore o- series (1996), “Young and graphed action as well as the inter- ard-boiled and fast paced is D a n g e rous” series (1996); “The nal moral conflicts of the main char- one way to describe the acters. HHong Kong action thriller Duel” (2000); and “The Park” (2003). “Infernal Affairs.” is co-director, Alan Mak, also nfernal Affairs” also adds a told HKMania.com that the level of intrigue. While the he film, which runs from Nov. movie has some very exciting 19 until Nov. 25 at the Brattle Hscript took three years to “I write. He said that the taste of the action scenes, the psychological TTheatre in Cambridge, herald- Hong Kong public shifted fro m impact of the duplicitous ro l e s ed a new wave of Hong Kong cin- action movies in the 1980s to takes its effect on the undercover ema for many critics. -

Music from the 1990S to the Present
j:,/ � • .. ….......:._. ‘. • '1- ;V . jn/w Tnn • ft ¾( ! \ ..' � •'. I . I .广, I n . .....Vv'Z …'.J I O > 3 . • • I •• . ^ • jr ,' ‘:'. ; , ''Jr ... Hong Kong Film Music from the 1990s to the Present CHENG LingYan A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Philosophy in Ethnomusicology © The Chinese University of Hong Kong June 2004 The Chinese University of Hong Kong holds the copyright of this thesis. Any person(s) intending to use a part or whole of the materials in the thesis in a proposed publication must seek copyright release from the Dean of the Graduate School. ^ST university~7^// ^XLIBRARy SYSTEM^W Abstract i Hong Kong Film Music from the 1990s to the Present Submitted by LingYan CHENG for the degree of Master of Philosophy in Ethnomusicology at The Chinese University of Hong Kong in June 2004 Abstract This thesis focuses on Hong Kong film music from the 1990s to the 2000s. In recent years, there has been much research and theory on western film music, especially the Hollywood film industry, by musicologists and scholars in film studies, popular music studies, and other fields. However, there has been little research on Hong Kong Film music, the system of which is different from that of western film music, and therefore I will apply basic film music concepts, but using the real situation of Hong Kong film music to formulate my own argument. The methodology used in this thesis will include the application of basic concepts used by scholars of film music, such as the functions of music in film, combined with fieldwork and analysis of films. -

Miramax's Asian Experiment: Creating a Model for Crossover Hits Lisa Dombrowski , Wesleyan University, US
Miramax's Asian Experiment: Creating a Model for Crossover Hits Lisa Dombrowski , Wesleyan University, US Prior to 1996, no commercial Chinese-language film had scored a breakout hit in the United States since the end of the 1970s kung fu craze. In the intervening period, the dominant distribution model for Asian films in America involved showcasing subtitled, auteur-driven art cinema in a handful of theaters in New York and Los Angeles, then building to ever more screens in a platform fashion, targeting college towns and urban theaters near affluent, older audiences. With the American fan base for Hong Kong action films steadily growing through video and specialized exhibition during the 1980s, Miramax chieftain Harvey Weinstein recognized the opportunity to market more commercial Chinese-language films to a wider audience outside the art cinema model as a means of generating crossover hits. Beginning in 1995, Weinstein positioned Miramax to become the primary distributor of Hong Kong action films in the United States. Miramax's acquisition and distribution strategy for Hong Kong action films was grounded in a specific set of assumptions regarding how to appeal to mass-market American tastes. The company targeted action-oriented films featuring recognizable genre conventions and brand- name stars, considering such titles both favorites of hardcore Hong Kong film fans and accessible enough to attract new viewers. Rather than booking its Hong Kong theatrical acquisitions into art cinemas, Miramax favored wide releases to multiplexes accompanied by marketing campaigns designed to highlight the action and hide the "foreignness" of the films. Miramax initially adopted a strategy of dubbing, re-scoring, re-editing, and often re-titling its Hong Kong theatrical and video/DVD releases in order to make them more appealing to mainstream American audiences.