Contraction of Online Response to Major Events
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Read the Westchester Guardian
Vol. VI, No. XVII Thursday, April 26, 2012,,,,$1.00 Westchester’s Most Influential Weekly SHERIF AWAD WPPD Officer Hart Calls Him Go Nagai, Go! “Nigger!” Page 4 LARRY M. ELKIN Con Ed Delivers Fiscal Abuse Page 8 ROBERT SCOTT From Rugs to Riches Page 10 RAYMOND IBRAHIM Muslim Persecution of Christians Page 12 JOHN SIMON Mixed-Up Bag Page 18 MARY C. MARVIN Savoring Spring Page 20 WPPD Officer Carelli PEGGY GODFREY MOU Approved Shoots Page 21 U.S. Marine Kenneth Chamberlain, Sr. EDWARD I. KOCH Time to Reexamine Dead Welfare Reform Law Page 23 WWW.WESTCHESTERGUARDIAN.COM Page 26 THE WESTCHESTER GUARDIAN THURSDAY, FEBRUARY 23, 2012 CLASSIFIED ADS LEGAL NOTICES Office Space Available- FAMILY COURT OF THE STATE OF NEW YORK Prime Location, Yorktown Heights COUNTY OF WESTCHESTER 1,000 Sq. Ft.: $1800. Contact Wilca: 914.632.1230 In the Matter of ORDER TO SHOW CAUSE SUMMONS AND INQUEST NOTICE Prime Retail - Westchester County Chelsea Thomas (d.o.b. 7/14/94), Best Location in Yorktown Heights A Child Under 21 Years of Age Dkt Nos. NN-10514/15/16-10/12C 1100 Sq. Ft. Store $3100; 1266 Sq. Ft. store $2800 and 450 Sq. Ft. THE WESTCHESTER GUARDIAN THURSDAY, FEBRUARY 23, 2012 Store $1200. Page 3 Adjudicated to be Neglected by NN-2695/96-10/12B FU No.: 22303 Page 2 THE WTHEEST CWESTCHESTERHESTER GUARD IGUARDIANAN THURSDAY,THURSDAY,THURSDAY FEBRUARY MARCH APRIL 23, 2012Suitable 29,26, 2012 for any type of business. Contact Wilca: 914.632.1230Page 3 Tiffany Ray and Kenneth Thomas, Respondents. X RADIO HELP WANTED NOTICE: PLACEMENT OF YOUR CHILD IN FOSTER CARE MAY RESULT IN YOUR LOSS OF YOUR Of Significance A non profit Performing Arts Center is seeking two job positions- 1) Direc- Of Significance RADIORADIO RIGHTS TO YOUR CHILD. -

Official Media Guide
OFFICIAL MEDIA GUIDE OCTOBER 6-11, 2015 &$ " & "#"!" !"! %'"# Table of Contents The Presidents Cup Summary ................................................................. 2 Chris Kirk ...............................................................................52 Media Facts ..........................................................................................3-8 Matt Kuchar ..........................................................................53 Schedule of Events .............................................................................9-10 Phil Mickelson .......................................................................54 Acknowledgements ...............................................................................11 Patrick Reed ..........................................................................55 Glossary of Match-Play Terminology ..............................................12-13 Jordan Spieth ........................................................................56 1994 Teams and Results/Player Records........................................14-15 Jimmy Walker .......................................................................57 1996 Teams and Results/Player Records........................................16-17 Bubba Watson.......................................................................58 1998 Teams and Results/Player Records ......................................18-19 International Team Members ..................................................59-74 2000 Teams and Results/Player Records -

CONGRESSIONAL RECORD— Extensions of Remarks E522 HON
E522 CONGRESSIONAL RECORD — Extensions of Remarks April 16, 2012 support each other on the defensive end Mitch Barnhart, and University of Kentucky Bubba’s strong character, athletic prowess, translated into selflessness in their offensive President Eli Capiluto who, in his first year as and commitment to family and community attack, with a different player leading all scor- president, is now one-for-one in national bas- make it all the more enjoyable to call him ers on any given night. The senior anchor to ketball championships. ‘‘Masters Champion.’’ His nail-biting win after these young ’Cats was Darius Miller, one of In closing I would like to once again join the two playoff holes on Sunday afternoon may be Kentucky’s favorite sons and a high school Mr. Big Blue Nation in congratulating the team, ev- his first in a major tournament, but it will likely Basketball from Mason County. During his eryone affiliated with the University and UK not be his last. freshman season, Kentucky failed to make the fans around the world on a terrific season and On behalf of the United States Congress NCAA Tournament for the first time in 18 our eighth national championship. What a ban- and the citizens of Northwest Florida, I con- years. After that disappointment, Miller has ner year it has been! gratulate Bubba for his extraordinary victory. been a mainstay of teams under Coach John f My wife Vicki joins me in offering our best Calipari that have gone undefeated at home wishes to Bubba; his wife, Angie; and their for three seasons, earning two Final Fours, an RECOGNIZING PROFESSIONAL son, Caleb, for their continued success. -

2012 Qschool Application
APPLICATION TO ENTER 2012 PGA TOUR QUALIFYING TOURNAMENT (FOR THE PGA TOUR AND WEB.COM TOUR) CONDUCTED BY THE PGA TOUR ENTRY DEADLINES: Pre-Qualifying - 5:00 p.m. EDT, Wednesday, August 22, 2012 First, Second or Final Qualifying Stages – 5:00 p.m. EDT, Wednesday, September 26, 2012 Applications to Enter the 2012 PGA TOUR Qualifying Tournament must be received at PGA TOUR Headquarters by the applicable entry deadline Without Exception and will not be accepted at tournament sites. Entries by telephone, telegraph, facsimile or e-mail are NOT acceptable. An Application to Enter must be completely executed for an applicant to be entered in the Qualifying Tournament. Applicants may submit an Application to Enter on-line at pgatour.com. Entry fee payment by credit card (MasterCard or Visa in the name of the applicant) is only acceptable with submission of the on-line Application to Enter. Entry fee payment by cashier’s check or money order is only acceptable with submission of a hard copy Application to Enter. The undersigned hereby applies to enter the 2012 PGA TOUR Qualifying Tournament. Although membership in the PGA TOUR and Web.com Tour is based principally on this competition, PGA TOUR reserves the right to apply other reasonable criteria (including, but not limited to; character; conduct; financial responsibility etc.) to all applicants for membership. In accordance with PGA TOUR Tournament Regulations, a player must be 18 years of age or older to be eligible for membership. A player under the age of 18 may enter the PGA TOUR Qualifying Tournament, provided the player turns 18 on or before the first scheduled round of the final official money PGA TOUR tournament of the following season. -

Annual Dinner Auction SATURDAY, FEBRUARY 16TH Kniatg the HT AUCTION RULES MASTERS
ST. FRANCIS BORGIA REGIONAL HIGH SCHOOL presents KNIatG the HT MASTERS 2019 Annual Dinner Auction SATURDAY, FEBRUARY 16TH KNIatG the HT AUCTION RULES MASTERS LIVE AUCTION 1. The Live Auction will begin at 7:30 p.m. in the gym and will continue until all items are sold. 2. Please use your bid cards. Raise your bidding number high to attract the attention of the spotters and auctioneers. 3. Title to the item and/or services will pass to the highest bidder who then assumes the full risk and responsibility for the item. Bids must be made quickly as the Auction will be fast paced. The high bidder will be acknowledged by the auctioneer. The auctioneer reserves the right to announce conditions of a sale at any time. In the event of a dispute, the auctioneer will have sole and final discretion in these matters. 4. If the auctioneer determines that an opening bid, or any subsequent bid, is not commensurate with the value of the items offered, he may reject the bid and withdraw the item for sale, and, if having acknowledged an opening bid, he decides that an advance thereafter is not a sufficient amount, he may reject the advance. The auctioneer retains the right to add or delete any item. 5. Cash, check, MasterCard, Visa, AmEx and Discover are accepted. Payment in full must be made tonight, February 16, 2019. 6. The winning bidder will be notified via GiveSmart - present your smart device or ask attendant for assistance of claiming auction item. 7. Please make sure you pick up a certificate for any item or service not physically present. -

2019 Media Guide 2019 Media Guide
2019 MASTERS MEDIA GUIDE 2019 MEDIA GUIDE 2019 MEDIA GUIDE masters.com | April 8-14 | @TheMasters Printed on Recycled Paper Fred S. Ridley Chairman Joe T. Ford Vice Chairman James B. Hyler, Jr. Chairman, Competition Committees Media Committee: The Media Committee is dedicated to providing the press with the best tools and working environment possible. The Masters Tournament staff is available to assist the media, when possible, during the week of the Tournament and throughout the year. Craig Heatley Chairman, Media Committee For more information, please contact: Steven P. Ethun Director of Communications (706) 667-6705 - Direct (706) 832-1352 - Mobile e-mail: [email protected] Address: Post Office Box 2047 2604 Washington Road Augusta, GA 30903 Augusta, GA 30904 Telephone: (706) 667-6000 Website: masters.com Social Media: Twitter: @TheMasters Instagram: @TheMasters Facebook: facebook.com/TheMasters On the Cover: No. 12, Golden Bell Not for Resale For Media Use Only ©2019 by Augusta National, Inc. The 2019 Masters Media Guide is published for use by the media. Permission is hereby granted for excerpts from this work to be used in articles written for newspapers, magazines and the internet and for television and radio reports. Photographs and other pictorial material, and Masters or Augusta National Golf Club logos, may not be reprinted or reused without the express written permission of Augusta National, Inc. All other rights reserved. • Masters Electronic Device Policy: Electronic devices (including phones, laptops, tablets, and beepers) are strictly prohibited on the grounds at all times. Any device being used to record and/or transmit voice, video, or data is strictly prohibited. -

2015 Hero World Challenge Albany Golf Course December 3-6, 2015 Albany, Bahamas Par/Yards
2015 Hero World Challenge Albany Golf Course December 3-6, 2015 Albany, Bahamas Par/Yards: 36-36—72/7,267 Purse: $3,500,000 Final-Round Notes – Sunday, December 6, 2015 Weather: Cloudy. High of 83. Winds ENE 10-15 mph, gusting to 20 mph. Play was suspended due to heavy rain at 12:15 p.m. and resumed at 12:30 p.m. Final-Round Leaderboard Bubba Watson 67-67-63-66—263 (-25) Patrick Reed 69-65-66-66—266 (-22) Rickie Fowler 70-68-65-64—267 (-21) Bubba Watson wins Hero World Challenge Bubba Watson followed a third-round 9-under 63 with a 6-under 66 Sunday, winning the 2015 Hero World Challenge by three strokes over Patrick Reed and four over Rickie Fowler. Watson won with a 72-hole total of 25-under 263, one shy of the Hero World Challenge record of 26-under 262 set by Jordan Spieth in 2014. Prior to Spieth, Tiger Woods held the scoring record with a winning score of 22-under 266 in 2007. Watson owns eight official victories on the PGA TOUR: 2010 Travelers Championship, 2011 Farmers Insurance Open, 2011 Zurich Classic of New Orleans, 2012 Masters Tournament, 2014 Northern Trust Open, 2014 Masters Tournament, 15 World Golf Championships-HSBC Champions, 2015 Travelers Championship, 2015 Hero World Challenge (unofficial). Watson wins the Hero World Challenge at the age of 37 years, 1 month and 1 day. Watson wins in his sixth start at the Hero World Challenge (T14/2010, T6/2011, T9/2012, T3/2013, T11/2014, 1/2015). -
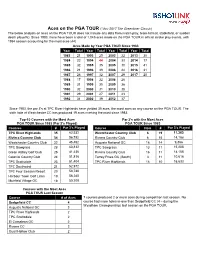
Aces on the PGA TOUR (*Thru 2017 the Greenbrier Classic) the Below Analysis on Aces on the PGA TOUR Does Not Include Any Data Fr
Aces on the PGA TOUR (*thru 2017 The Greenbrier Classic) The below analysis on aces on the PGA TOUR does not include any data from match play, team format, stableford, or sudden death playoffs). Since 1983, there have been a total of 1,045 aces made on the PGA TOUR in official stroke play events, with 1994 season accounting for the most aces (44). Aces Made by Year PGA TOUR Since 1983 Year Total Year Total Year Total Year Total 1983 21 1993 25 2003 32 2013 30 1984 22 1994 44 2004 33 2014 17 1985 32 1995 35 2005 30 2015 41 1986 21 1996 39 2006 24 2016 31 1987 28 1997 32 2007 29 2017 20 1988 17 1998 32 2008 26 1989 31 1999 30 2009 36 1990 32 2000 31 2010 38 1991 29 2001 27 2011 23 1992 31 2002 39 2012 37 Since 1983, the par 3’s at TPC River Highlands have yielded 35 aces, the most aces on any course on the PGA TOUR. The sixth hole at Westchester CC has produced 19 aces marking the most since 1983. Top-10 Courses with the Most Aces Par 3’s with the Most Aces PGA TOUR Since 1983 (Par 3’s Played) PGA TOUR Since 1983 Courses # Par 3’s Played Course Hole # Par 3’s Played TPC River Highlands 35 62,532 Westchester Country Club 6 19 11,363 Riviera Country Club 34 56,752 Riviera Country Club 6 15 14,188 Westchester Country Club 32 45,452 Augusta National GC 16 14 9,366 TPC Sawgrass 28 60,832 TPC Sawgrass 13 11 15,208 Glean Abbey Golf Club 25 41,436 Riviera Country Club 16 11 14,188 Colonial Country Club 24 51,816 Torrey Pines GC (South) 3 11 10,616 TPC Scottsdale 23 51,404 TPC River Highlands 16 10 15,633 TPC Southwind 21 52,972 TPC Four Season Resort 20 53,740 Harbour Town Golf Links 19 56,280 Muirfield Village GC 19 50,708 Courses with the Most Aces PGA TOUR Last Season Course # of Aces 7 courses produced 2 or more aces during competition last season. -

14 U.S. Open (The 31 St of 41 Events in the PGA TOUR Season)
2014 U.S. Open (The 31 st of 41 events in the PGA TOUR Season) Pinehurst Resort & Country Club (No. 2) June 12-15, 2014 FedExCup Pts: 600 Purse: $9,000,000 Village of Pinehurst, N.C. Par/Yards: 35-35—70/7,562 Final-Round Notes – Sunday, June 15, 2014 Weather: Mostly sunny. High of 88. Winds ESE 4-8 mph. Final-Round Leaderboard Martin Kaymer 65-65-72-69—271 (-9) Erik Compton 72-68-67-72—279 (-1) Rickie Fowler 70-70-67-72—279 (-1) Qualifying for the other Majors The top 10 finishers (and ties) are exempt for next year’s (2015) U.S. Open. The top four finishers (and ties) are invited to the 2015 Masters Tournament. How Martin Kaymer won the 2014 U.S. Open Martin Kaymer (65-65) became the first player to record consecutive rounds of 65 or better to open a Major Championship en route to the lowest opening 36-hole score in U.S. Open history (10-under 130) and a six-stroke lead at the halfway point of the 114 th U.S. Open Championship. He added rounds of 72-69 for an eight-stroke victory over Erik Compton and Rickie Fowler, becoming the seventh player (8 times) to win the U.S. Open in wire-to-wire fashion (no ties), joining Walter Hagen (1914), James Barnes (1921), Ben Hogan (1953), Tony Jacklin (1970), Tiger Woods (2000, 2002) and Rory McIlroy (2011). What Martin Kaymer earns for winning the 2014 U.S. Open (if not otherwise eligible) • 10-year U.S. -

The Presidents
Pre-Event Notes - Player bios/stats begin on page 4 For more information, please contact: Chris Reimer Laura Neal Director, Communications Vice President, Communications [email protected] [email protected] 904-806-6614 386-405-7127 What: The Presidents Cup When: October 1-6, 2013 Location: Muirfield Village Golf Club in Dublin-Columbus, Ohio, USA Golf Course Architect Jack Nicklaus (1974) Par/Yardage: Front: 3,660 Par 36 Back: 3,694 Par 36 Total: 7,354 Par 72 Field: The Presidents Cup, a team match play competition featuring 24 of the world’s top golfers – 12 from the United States and 12 from around the world, excluding Europe – is held every two years, and since 1996 has alternated between United States and international venues. Captains – U.S. Team Captain Fred Couples returns in an attempt to win for a record third time after making victories in San Francisco (2009) and Melbourne, Australia (2011). Nick Price makes his debut as International Team Captain. The International Team is looking for its second outright victory. Format: The Presidents Cup competition consists of 34 matches – 11 Foursomes (alternate shot) and 11 Four- ball (better-ball) matches. There are 12 Singles matches involving all players on the final Sunday. All matches are worth one point each, for a total of 34 points. There are no playoffs for Foursomes or Four-ball, with each side receiving ½ a point if the match finishes all-square. Singles matches all square after 18 holes will go extra holes until a team winner is determined. In a change inspired by the events of The Presidents Cup 2003, if the match is deadlocked at the end of play, the competition will be deemed a tie and the teams will share the Cup. -

Official Media Guide
OFFICIAL MEDIA GUIDE FEBRUARY 20-23, 2020 CLUB DE GOLF CHAPULTEPEC, MEXICO CITY, MEXICO Table of Contents Schedule of Events ..........................................................................2 Results of 2008 Accenture Match Play Championship ............ 113 Media Facts ................................................................................. 3-4 Results of 2007 Accenture Match Play Championship ........... .114 Tournament Officials .......................................................................5 Results of 2006 Accenture Match Play Championship ............ 115 Tournament Scorecard ...................................................................6 Results of 2005 Accenture Match Play Championship ............ 116 Results of 2019 Mexico Championship ..........................................7 Results of 2004 Accenture Match Play Championship ............ 117 Results of 2018 Mexico Championship ..........................................8 Results of 2003 Accenture Match Play Championship ............ 118 Results of 2017 Mexico Championship ..........................................9 Results of 2002 Accenture Match Play Championship ............ 119 Results of 2016 Cadillac Championship ......................................10 Results of 2001 Accenture Match Play Championship ............ 120 Results of 2015 Cadillac Championship ......................................11 Results of 2000 Accenture Match Play Championship ............ 121 Results of 2014 Cadillac Championship ......................................12 -
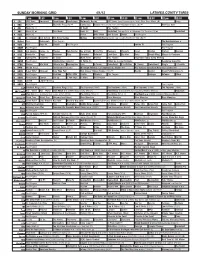
Sunday Morning Grid 4/1/12 Latimes.Com/Tv Times
SUNDAY MORNING GRID 4/1/12 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Horseland Doodlebops Doodlebops Motorcycle Racing ATP Tennis Sony Ericsson Open, Men’s Final. From Miami. (N) Kings 4 NBC News Å Meet the Press (N) Å Conference Hockey Philadelphia Flyers at Pittsburgh Penguins. (N) Å PGA Tour Golf 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) NBA Basketball Chicago Bulls at Oklahoma City Thunder. (N) Å Basketball 9 KCAL News (N) Prince Mike Webb Joel Osteen Shook Paid Program 11 FOX D. Jeremiah Joel Osteen Fox News Sunday Midday NASCAR Racing Sprint Cup: Goody’s Fast Relief 500. (N) Å 13 MyNet Paid Tomorrow’s Paid Program The Benchwarmers › 18 KSCI Paid Hope Hr. Church Paid Program Iranian TV Paid Program 22 KWHY Paid Program Paid Program 24 KVCR Sid Science Curios -ity Thomas Bob Builder Joy of Paint Paint This Dewberry Wyland’s Sara’s Kitchen Kitchen Mexican 28 KCET Hands On Raggs Busytown Peep Pancakes Pufnstuf Land/Lost Hey Kids Taste Simply Ming Moyers & Company 30 ION Turning Pnt. Discovery In Touch Mark Jeske Beyond Paid Program Inspiration Today Camp Meeting 34 KMEX Paid Program Muchachitas Como Tú Al Punto (N) Fútbol de la Liga Mexicana República Deportiva 40 KTBN Rhema Win Walk Miracle-You Redemption Love In Touch PowerPoint It Is Written B. Conley From Heart King Is J.