Nosql and Newsql
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Smart Methods for Retrieving Physiological Data in Physiqual
University of Groningen Bachelor thesis Smart methods for retrieving physiological data in Physiqual Marc Babtist & Sebastian Wehkamp Supervisors: Frank Blaauw & Marco Aiello July, 2016 Contents 1 Introduction 4 1.1 Physiqual . 4 1.2 Problem description . 4 1.3 Research questions . 5 1.4 Document structure . 5 2 Related work 5 2.1 IJkdijk project . 5 2.2 MUMPS . 6 3 Background 7 3.1 Scalability . 7 3.2 CAP theorem . 7 3.3 Reliability models . 7 4 Requirements 8 4.1 Scalability . 8 4.2 Reliability . 9 4.3 Performance . 9 4.4 Open source . 9 5 General database options 9 5.1 Relational or Non-relational . 9 5.2 NoSQL categories . 10 5.2.1 Key-value Stores . 10 5.2.2 Document Stores . 11 5.2.3 Column Family Stores . 11 5.2.4 Graph Stores . 12 5.3 When to use which category . 12 5.4 Conclusion . 12 5.4.1 Key-Value . 13 5.4.2 Document stores . 13 5.4.3 Column family stores . 13 5.4.4 Graph Stores . 13 6 Specific database options 13 6.1 Key-value stores: Riak . 14 6.2 Document stores: MongoDB . 14 6.3 Column Family stores: Cassandra . 14 6.4 Performance comparison . 15 6.4.1 Sensor Data Storage Performance . 16 6.4.2 Conclusion . 16 7 Data model 17 7.1 Modeling rules . 17 7.2 Data model Design . 18 2 7.3 Summary . 18 8 Architecture 20 8.1 Basic layout . 20 8.2 Sidekiq . 21 9 Design decisions 21 9.1 Keyspaces . 21 9.2 Gap determination . -

(DDL) Reference Manual
Data Definition Language (DDL) Reference Manual Abstract This publication describes the DDL language syntax and the DDL dictionary database. The audience includes application programmers and database administrators. Product Version DDL D40 DDL H01 Supported Release Version Updates (RVUs) This publication supports J06.03 and all subsequent J-series RVUs, H06.03 and all subsequent H-series RVUs, and G06.26 and all subsequent G-series RVUs, until otherwise indicated by its replacement publications. Part Number Published 529431-003 May 2010 Document History Part Number Product Version Published 529431-002 DDL D40, DDL H01 July 2005 529431-003 DDL D40, DDL H01 May 2010 Legal Notices Copyright 2010 Hewlett-Packard Development Company L.P. Confidential computer software. Valid license from HP required for possession, use or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor's standard commercial license. The information contained herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein. Export of the information contained in this publication may require authorization from the U.S. Department of Commerce. Microsoft, Windows, and Windows NT are U.S. registered trademarks of Microsoft Corporation. Intel, Itanium, Pentium, and Celeron are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. -

Oracle Vs. Nosql Vs. Newsql Comparing Database Technology
Oracle vs. NoSQL vs. NewSQL Comparing Database Technology John Ryan Senior Solution Architect, Snowflake Computing Table of Contents The World has Changed . 1 What’s Changed? . 2 What’s the Problem? . .. 3 Performance vs. Availability and Durability . 3 Consistecy vs. Availability . 4 Flexibility vs . Scalability . 5 ACID vs. Eventual Consistency . 6 The OLTP Database Reimagined . 7 Achieving the Impossible! . .. 8 NewSQL Database Technology . 9 VoltDB . 10 MemSQL . 11 Which Applications Need NewSQL Technology? . 12 Conclusion . 13 About the Author . 13 ii The World has Changed The world has changed massively in the past 20 years. Back in the year 2000, a few million users connected to the web using a 56k modem attached to a PC, and Amazon only sold books. Now billions of people are using to their smartphone or tablet 24x7 to buy just about everything, and they’re interacting with Facebook, Twitter and Instagram. The pace has been unstoppable . Expectations have also changed. If a web page doesn’t refresh within seconds we’re quickly frustrated, and go elsewhere. If a web site is down, we fear it’s the end of civilisation as we know it. If a major site is down, it makes global headlines. Instant gratification takes too long! — Ladawn Clare-Panton Aside: If you’re not a seasoned Database Architect, you may want to start with my previous articles on Scalability and Database Architecture. Oracle vs. NoSQL vs. NewSQL eBook 1 What’s Changed? The above leads to a few observations: • Scalability — With potentially explosive traffic growth, IT systems need to quickly grow to meet exponential numbers of transactions • High Availability — IT systems must run 24x7, and be resilient to failure. -
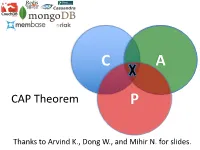
CAP Theorem P
C A CAP Theorem P Thanks to Arvind K., Dong W., and Mihir N. for slides. CAP Theorem • “It is impossible for a web service to provide these three guarantees at the same time (pick 2 of 3): • (Sequential) Consistency • Availability • Partition-tolerance” • Conjectured by Eric Brewer in ’00 • Proved by Gilbert and Lynch in ’02 • But with definitions that do not match what you’d assume (or Brewer meant) • Influenced the NoSQL mania • Highly controversial: “the CAP theorem encourages engineers to make awful decisions.” – Stonebraker • Many misinterpretations 2 CAP Theorem • Consistency: – Sequential consistency (a data item behaves as if there is one copy) • Availability: – Node failures do not prevent survivors from continuing to operate • Partition-tolerance: – The system continues to operate despite network partitions • CAP says that “A distributed system can satisfy any two of these guarantees at the same time but not all three” 3 C in CAP != C in ACID • They are different! • CAP’s C(onsistency) = sequential consistency – Similar to ACID’s A(tomicity) = Visibility to all future operations • ACID’s C(onsistency) = Does the data satisfy schema constraints 4 Sequential consistency • Makes it appear as if there is one copy of the object • Strict ordering on ops from same client • A single linear ordering across client ops – If client a executes operations {a1, a2, a3, ...}, client b executes operations {b1, b2, b3, ...} – Then, globally, clients observe some serialized version of the sequence • e.g., {a1, b1, b2, a2, ...} (or whatever) Notice -

Concurrency Control Basics
Outline l Introduction/problems, l definitions Introduction/ (transaction, history, conflict, equivalence, Problems serializability, ...), Definitions l locking. Chapter 2: Locking Concurrency Control Basics Klemens Böhm Distributed Data Management: Concurrency Control Basics – 1 Klemens Böhm Distributed Data Management: Concurrency Control Basics – 2 Atomicity, Isolation Synchronisation, Distributed (1) l Transactional guarantees – l Essential feature of databases: in particular, atomicity and isolation. Many users can access the same data concurrently – be it read, be it write. Introduction/ l Atomicity Introduction/ Problems Problems u Example, „bank scenario“: l Consistency must be guaranteed – Definitions Definitions task of synchronization component. Locking Number Person Balance Locking Klemens 5000 l Multi-user mode shall be hidden from users as far as possible: concurrent processing Gunter 200 of requests shall be transparent, u Money transfer – two elementary operations. ‚illusion‘ of being the only user. – debit(Klemens, 500), – credit(Gunter, 500). l Isolation – can be explained with this example, too. l Transactions. Klemens Böhm Distributed Data Management: Concurrency Control Basics – 3 Klemens Böhm Distributed Data Management: Concurrency Control Basics – 4 Synchronisation, Distributed (2) Synchronization in General l Serial execution of application programs Uncontrolled non-serial execution u achieves that illusion leads to other problems, notably inconsistency: l Introduction/ without any synchronization effort, Introduction/ -

Nosql Databases: Yearning for Disambiguation
NOSQL DATABASES: YEARNING FOR DISAMBIGUATION Chaimae Asaad Alqualsadi, Rabat IT Center, ENSIAS, University Mohammed V in Rabat and TicLab, International University of Rabat, Morocco [email protected] Karim Baïna Alqualsadi, Rabat IT Center, ENSIAS, University Mohammed V in Rabat, Morocco [email protected] Mounir Ghogho TicLab, International University of Rabat Morocco [email protected] March 17, 2020 ABSTRACT The demanding requirements of the new Big Data intensive era raised the need for flexible storage systems capable of handling huge volumes of unstructured data and of tackling the challenges that arXiv:2003.04074v2 [cs.DB] 16 Mar 2020 traditional databases were facing. NoSQL Databases, in their heterogeneity, are a powerful and diverse set of databases tailored to specific industrial and business needs. However, the lack of the- oretical background creates a lack of consensus even among experts about many NoSQL concepts, leading to ambiguity and confusion. In this paper, we present a survey of NoSQL databases and their classification by data model type. We also conduct a benchmark in order to compare different NoSQL databases and distinguish their characteristics. Additionally, we present the major areas of ambiguity and confusion around NoSQL databases and their related concepts, and attempt to disambiguate them. Keywords NoSQL Databases · NoSQL data models · NoSQL characteristics · NoSQL Classification A PREPRINT -MARCH 17, 2020 1 Introduction The proliferation of data sources ranging from social media and Internet of Things (IoT) to industrially generated data (e.g. transactions) has led to a growing demand for data intensive cloud based applications and has created new challenges for big-data-era databases. -

IBM Cloudant: Database As a Service Fundamentals
Front cover IBM Cloudant: Database as a Service Fundamentals Understand the basics of NoSQL document data stores Access and work with the Cloudant API Work programmatically with Cloudant data Christopher Bienko Marina Greenstein Stephen E Holt Richard T Phillips ibm.com/redbooks Redpaper Contents Notices . 5 Trademarks . 6 Preface . 7 Authors. 7 Now you can become a published author, too! . 8 Comments welcome. 8 Stay connected to IBM Redbooks . 9 Chapter 1. Survey of the database landscape . 1 1.1 The fundamentals and evolution of relational databases . 2 1.1.1 The relational model . 2 1.1.2 The CAP Theorem . 4 1.2 The NoSQL paradigm . 5 1.2.1 ACID versus BASE systems . 7 1.2.2 What is NoSQL? . 8 1.2.3 NoSQL database landscape . 9 1.2.4 JSON and schema-less model . 11 Chapter 2. Build more, grow more, and sleep more with IBM Cloudant . 13 2.1 Business value . 15 2.2 Solution overview . 16 2.3 Solution architecture . 18 2.4 Usage scenarios . 20 2.5 Intuitively interact with data using Cloudant Dashboard . 21 2.5.1 Editing JSON documents using Cloudant Dashboard . 22 2.5.2 Configuring access permissions and replication jobs within Cloudant Dashboard. 24 2.6 A continuum of services working together on cloud . 25 2.6.1 Provisioning an analytics warehouse with IBM dashDB . 26 2.6.2 Data refinement services on-premises. 30 2.6.3 Data refinement services on the cloud. 30 2.6.4 Hybrid clouds: Data refinement across on/off–premises. 31 Chapter 3. -

Cache Serializability: Reducing Inconsistency in Edge Transactions
Cache Serializability: Reducing Inconsistency in Edge Transactions Ittay Eyal Ken Birman Robbert van Renesse Cornell University tributed databases. Until recently, technical chal- Abstract—Read-only caches are widely used in cloud lenges have forced such large-system operators infrastructures to reduce access latency and load on to forgo transactional consistency, providing per- backend databases. Operators view coherent caches as object consistency instead, often with some form of impractical at genuinely large scale and many client- facing caches are updated in an asynchronous manner eventual consistency. In contrast, backend systems with best-effort pipelines. Existing solutions that support often support transactions with guarantees such as cache consistency are inapplicable to this scenario since snapshot isolation and even full transactional atom- they require a round trip to the database on every cache icity [9], [4], [11], [10]. transaction. Our work begins with the observation that it can Existing incoherent cache technologies are oblivious to be difficult for client-tier applications to leverage transactional data access, even if the backend database supports transactions. We propose T-Cache, a novel the transactions that the databases provide: trans- caching policy for read-only transactions in which incon- actional reads satisfied primarily from edge caches sistency is tolerable (won’t cause safety violations) but cannot guarantee coherency. Yet, by running from undesirable (has a cost). T-Cache improves cache consis- cache, client-tier transactions shield the backend tency despite asynchronous and unreliable communication database from excessive load, and because caches between the cache and the database. We define cache- are typically placed close to the clients, response serializability, a variant of serializability that is suitable latency can be improved. -

Exploring the Visualization of Schemas for Aggregate-Oriented Nosql Databases?
Exploring the Visualization of Schemas for Aggregate-Oriented NoSQL Databases? Alberto Hernández Chillón, Severino Feliciano Morales, Diego Sevilla Ruiz, and Jesús García Molina Faculty of Computer Science, University of Murcia Campus Espinardo, Murcia, Spain {alberto.hernandez1,severino.feliciano,dsevilla,jmolina}@um.es Abstract. The lack of an explicit data schema (schemaless) is one of the most attractive NoSQL database features for developers. Being schema- less, these databases provide a greater flexibility, as data with different structure can be stored for the same entity type, which in turn eases data evolution. This flexibility, however, should not be obtained at the expense of losing the benefits provided by having schemas: When writ- ing code that deals with NoSQL databases, developers need to keep in mind at any moment some kind of schema. Also, database tools usu- ally require the knowledge of a schema to implement their functionality. Several approaches to infer an implicit schema from NoSQL data have been proposed recently, and some utilities that take advantage of inferred schemas are emerging. In this article we focus on the requisites for the vi- sualization of schemas for aggregate-oriented NoSQL Databases. Schema diagrams have proven useful in designing and understanding databases. Plenty of tools are available to visualize relational schemas, but the vi- sualization of NoSQL schemas (and the variation that they allow) is still in an immature state, and a great R&D effort is required to achieve tools with the desired capabilities. Here, we study the main challenges to be addressed, and propose some visual representations. Moreover, we outline the desired features to be supported by visualization tools. -

SQL: Triggers, Views, Indexes Introduction to Databases Compsci 316 Fall 2014 2 Announcements (Tue., Sep
SQL: Triggers, Views, Indexes Introduction to Databases CompSci 316 Fall 2014 2 Announcements (Tue., Sep. 23) • Homework #1 sample solution posted on Sakai • Homework #2 due next Thursday • Midterm on the following Thursday • Project mixer this Thursday • See my email about format • Email me your “elevator pitch” by Wednesday midnight • Project Milestone #1 due Thursday, Oct. 16 • See project description on what to accomplish by then 3 Announcements (Tue., Sep. 30) • Homework #2 due date extended to Oct. 7 • Midterm in class next Thursday (Oct. 9) • Open-book, open-notes • Same format as sample midterm (from last year) • Already posted on Sakai • Solution to be posted later this week 4 “Active” data • Constraint enforcement: When an operation violates a constraint, abort the operation or try to “fix” data • Example: enforcing referential integrity constraints • Generalize to arbitrary constraints? • Data monitoring: When something happens to the data, automatically execute some action • Example: When price rises above $20 per share, sell • Example: When enrollment is at the limit and more students try to register, email the instructor 5 Triggers • A trigger is an event-condition-action (ECA ) rule • When event occurs, test condition ; if condition is satisfied, execute action • Example: • Event : some user’s popularity is updated • Condition : the user is a member of “Jessica’s Circle,” and pop drops below 0.5 • Action : kick that user out of Jessica’s Circle http://pt.simpsons.wikia.com/wiki/Arquivo:Jessica_lovejoy.jpg 6 Trigger example -

Oracle Nosql Database EE Data Sheet
Oracle NoSQL Database 21.1 Enterprise Edition (EE) Oracle NoSQL Database is a multi-model, multi-region, multi-cloud, active-active KEY BUSINESS BENEFITS database, designed to provide a highly-available, scalable, performant, flexible, High throughput and reliable data management solution to meet today’s most demanding Bounded latency workloads. It can be deployed in on-premise data centers and cloud. It is well- Linear scalability suited for high volume and velocity workloads, like Internet of Things, 360- High availability degree customer view, online contextual advertising, fraud detection, mobile Fast and easy deployment application, user personalization, and online gaming. Developers can use a single Smart topology management application interface to quickly build applications that run in on-premise and Online elastic configuration cloud environments. Multi-region data replication Enterprise grade software Applications send network requests against an Oracle NoSQL data store to and support perform database operations. With multi-region tables, data can be globally distributed and automatically replicated in real-time across different regions. Data can be modeled as fixed-schema tables, documents, key-value pairs, and large objects. Different data models interoperate with each other through a single programming interface. Oracle NoSQL Database is a sharded, shared-nothing system which distributes data uniformly across multiple shards in a NoSQL database cluster, based on the hashed value of the primary keys. An Oracle NoSQL Database data store is a collection of storage nodes, each of which hosts one or more replication nodes. Data is automatically populated across these replication nodes by internal replication mechanisms to ensure high availability and rapid failover in the event of a storage node failure. -

Database Software Market: Billy Fitzsimmons +1 312 364 5112
Equity Research Technology, Media, & Communications | Enterprise and Cloud Infrastructure March 22, 2019 Industry Report Jason Ader +1 617 235 7519 [email protected] Database Software Market: Billy Fitzsimmons +1 312 364 5112 The Long-Awaited Shake-up [email protected] Naji +1 212 245 6508 [email protected] Please refer to important disclosures on pages 70 and 71. Analyst certification is on page 70. William Blair or an affiliate does and seeks to do business with companies covered in its research reports. As a result, investors should be aware that the firm may have a conflict of interest that could affect the objectivity of this report. This report is not intended to provide personal investment advice. The opinions and recommendations here- in do not take into account individual client circumstances, objectives, or needs and are not intended as recommen- dations of particular securities, financial instruments, or strategies to particular clients. The recipient of this report must make its own independent decisions regarding any securities or financial instruments mentioned herein. William Blair Contents Key Findings ......................................................................................................................3 Introduction .......................................................................................................................5 Database Market History ...................................................................................................7 Market Definitions