Evaluating the Comparability of Scores from Achievement Test Variations
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

List of Tech Levels for 2017 Performance Tables
2017 16 to 19 performance tables: qualifications in the tech level category February 2015 (replaces December 2014 version) Contents Introduction 3 Headline performance measures for 16-19 year olds 4 Qualifications that will be included in the tech level category in the 2017 16-19 performance tables 5 Tech levels in agriculture, horticulture and animal care 5 Tech levels in arts, media and publishing 9 Tech levels in accounting and finance, business, administration and law 11 Tech levels in child development and well-being 12 Tech levels in construction, planning and the built environment 13 Tech levels in engineering, manufacturing and transportation operations 16 Tech levels in health, public services and care 20 Tech levels in information and communication technology 21 Tech levels in leisure, sport, travel and tourism 22 Tech levels in retail, hospitality and commercial enterprise 23 2 Introduction This is the final list of qualifications that have been approved by the Department for Education (DfE) for teaching to 16 to 19 year olds from September 2015. These qualifications will be reported in the tech level category of the 2017 16-19 performance tables (to be published in early 2018). They will be reported alongside qualifications such as A Levels and other vocational qualifications. Qualifications that will be reported in performance tables for the first time in 2017 have an asterisk (*) after the title. Qualifications that were added to the list in February 2015 are indicated with a hash symbol (#) after the title. Tech levels are rigorous advanced (level 3) technical qualifications on a par with A Levels and recognised by employers. -

Academic Studies for Officers
University VIENNA and National Defense Academy VIENNA Academic Studies for Officers A Central European Perspective (Presentations of the First International Conference in Vienna, 15 – 19 March 1999) Published by Brigadier-General Gernot ALBRECHT Vienna, April 2001 SUMMARY OF CONTENTS WOLFGANG GREISENEGGER..................................................3 Welcome Address......................................................................................3 ERNEST KÖNIG..........................................................................5 Welcome Address......................................................................................5 GERNOT ALBRECHT .................................................................9 Opening Statement....................................................................................9 ARMIN A. STEINKAMM ............................................................10 The Bundeswehr University [UDBW]..................................................10 JÖRG E. P. KELLER.................................................................17 Academic Officer Training within and for the Armed Forces – a German Perspective ....................................................................................................................17 BEAT A. KÄCH .........................................................................32 The Swiss Military College ....................................................................32 ALTERO FASANO.....................................................................43 -

Referencing the Scottish Credit & Qualifications Framework (SCQF)
Referencing the Scottish Credit & Qualifications Framework (SCQF) to the European Qualifications Framework (EQF) Report 2019 Referencing the Scottish Credit & Qualifications Framework (SCQF to the European Qualifications Framework (EQF) Referencing Report 2019 1 This page has been left blank deliberately. Referencing the Scottish Credit & Qualifications Framework (SCQF to the European Qualifications Framework (EQF) Referencing Report 2019 2 PREFACE The Scottish Credit and Qualifications Framework (SCQF) was first referenced to the European Qualifications Framework (EQF) in 2009. This referencing was published in 2010 as part of a report on the referencing of the National Qualifications Frameworks (NQFs) of the four UK countries to the EQF. In the intervening eight years since publication, the SCQF has developed considerably, with the revision of SCQF Level Descriptors, the redefinition of SCQF Principles and a considerable expansion in the range and number of qualifications on the Framework. In 2015/16, a pilot project was undertaken to establish if the original referencing outcomes continued to be a true reflection of links between the SCQF and EQF. This report builds on the work completed in the pilot and provides a revised and updated analysis of the SCQF/EQF referencing. This report sets out the evidence that the SCQF continues to meet the ten criteria and ten quality assurance principles which govern referencing to the EQF. To provide a context for the reader, it also describes political, legal and social context in which the SCQF operates, explains the nature of the learning landscape in Scotland insofar as it relates to the SCQF, and describes the different kinds of qualifications in the Framework. -

Higher Education Entrance Qualifications and Exams in Europe: a Comparison
DIRECTORATE-GENERAL FOR INTERNAL POLICIES POLICY DEPARTMENT B: STRUCTURAL AND COHESION POLICIES CULTURE AND EDUCATION HIGHER EDUCATION ENTRANCE QUALIFICATIONS AND EXAMS IN EUROPE: A COMPARISON STUDY This document was requested by the European Parliament's Committee on Culture and Education. AUTHORS Cecile Hoareau McGrath, Marie Louise Henham, Anne Corbett, Niccolo Durazzi, Michael Frearson, Barbara Janta, Bregtje W. Kamphuis, Eriko Katashiro, Nina Brankovic, Benoit Guerin, Catriona Manville, Inga Schwartz, Daniel Schweppenstedde RESPONSIBLE ADMINISTRATOR Markus J. Prutsch Policy Department B: Structural and Cohesion Policies European Parliament B-1047 Brussels E-mail: [email protected] EDITORIAL ASSISTANCE Lyna Pärt LINGUISTIC VERSIONS Original: EN Translation: DE, FR ABOUT THE PUBLISHER To contact the Policy Department or to subscribe to its monthly newsletter please write to: [email protected] Manuscript completed in May 2014 Brussels © European Union, 2014 This document is available on the Internet at: http://www.europarl.europa.eu/studies DISCLAIMER The opinions expressed in this document are the sole responsibility of the authors and do not necessarily represent the official position of the European Parliament. Reproduction and translation for non-commercial purposes are authorized, provided the source is acknowledged and the publisher is given prior notice and sent a copy. DIRECTORATE-GENERAL FOR INTERNAL POLICIES POLICY DEPARTMENT B: STRUCTURAL AND COHESION POLICIES CULTURE AND EDUCATION HIGHER EDUCATION ENTRANCE QUALIFICATIONS AND EXAMS IN EUROPE: A COMPARISON STUDY Abstract The study analyses admission systems to higher education across ten countries, covering some countries of the European Union (France, Germany, Italy, Slovenia, Sweden and the United Kingdom), a candidate country (Turkey) as well as commonly used international comparators (Australia, Japan and the US). -

Higher Technical Qualifications in Chemistry and Related Subjects
Royal Society of Chemistry: Higher Technical Qualifications in chemistry and related subjects. Research report written by: Jane Powell, Lena WWW.SHIFT-MEMBERSHIP.CO.UK Karlin, Tilly Barkway and Octavia Browett ©SHIFT INSIGHT 2020 Executive summary Methods Learners' journeys This report follows a literature review phase • Learners of HTQs choose them because they need a more accessible learning and presents findings from 51 qualitative interviews route or have a preference for a more applied, rather than academic, qualification. with employers, providers and learners of Higher • HTQs have diverse and mixed cohorts and tend to bring together learners from Technical Qualifications*. a wide range of work and educational backgrounds, genders and age groups. Qualitative evidence indicates that HTQs are more inclusive for non-traditional Providers' needs learners compared to university degrees. • Accounts of employers, providers and learners suggest HTQs are used to achieve • The sector is volatile, with providers describing a triple purpose: as an entry route to a variety of industries; to achieve how they responded to changing conditions progression and promotion within their current workplace or sector; and to by switching, tweaking and considering new progress into science-based undergraduate courses. HTQs currently seem to be HTQs. more successful at facilitating the last two outcomes, as school leavers with no • The reported cohort sizes were usually small and relevant work experience sometimes have a poor understanding of the diversity, could fluctuate considerably year on year, with or specifics, of careers these qualifications can lead to. projected demand sometimes not materialising in enrolments. Employers' perceptions • Individual cases suggest employer engagement • While most employers indicated that they did not have a shortage of applicants is important in making new HTQs viable. -

2019-2020 Program of Studies
Greater Lowell Technical High School 2019-2020 Program of Studies Joseph Mastrocola, Superintendent-Director Jill Davis, Assistant Superintendent/Principal Core Values A core value is a central belief deeply understood and shared by every member of an organization. Greater Lowell Technical High School has established a set of core values to guide the actions of all students and staff and that are reflected daily in their performance building quality lives and a positive school culture conductive to learning for all. All members of the Greater Lowell Technical High School Learning Community will strive to: R.E.A.C.H. Respect - We treat ourselves, others and our surroundings with dignity through words and actions Effort- We work to the best of our abilities to make continuous progress without giving up or giving in Accountability - We own our words and actions and have the courage to accept responsibility for our decisions Commitment- We show dedication to our success, our school and our community Honesty- We act with integrity and value the importance of truthfulness Greater Lowell Technical High School School Committee Fred W. Bahou, Jr. Curtis J. LeMay Chairperson Dracut, Vice-Chair Lowell, Secretary Raymond J. Boutin Paul E. Morin George W. O’Hare Lowell Dracut Lowell Matthew J. Sheehan George A. Tatseos Kempton P. Giggey Dracut Tyngsboro Dunstable Administration Joseph Mastrocola Superintendent-Director Jill Davis Assistant Superintendent/Principal Jeffrey Albert Director-Special Education Tracy Encarnacao Director-Guidance & Counseling Services Michael Barton Director-Curriculum/Instruction & Assessment Directors Stacy Bezanson Director-Cooperative Education/Placement Mark Byrne Director-Plant Services Jamie Costa Senior Assistant Principal Lisa Martinez Director-Technology, Enrollment & Information Kristin Foti Director-Media and Professional Development Christine Messina Director-Practical Nursing & Continuing Ed. -

DOCUMENT RESUME the Development of Technical And
DOCUMENT RESUME ED 411 471 CE 074 838 TITLE The Development of Technical and Vocational Education in Africa. INSTITUTION United Nations Educational, Scientific, and Cultural Organization, Dakar (Senegal). Regional Office for Education in Africa. ISBN ISBN-92-9091-054-2 PUB DATE 1996-00-00 NOTE 411p.; Product of the International Project on Technical and Vocational Education (UNEVOC). PUB TYPE Reports Research (143) EDRS PRICE MF01/PC17 Plus Postage. DESCRIPTORS Case Studies; *Developing Nations; Economic Development; Education Work Relationship; Educational Cooperation; *Educational Development; Educational Legislation; *Educational Policy; Foreign Countries; Industry; *Role of Education; *School Business Relationship; *Vocational Education IDENTIFIERS *Africa ABSTRACT The 13 chapters in this book depict the challenges facing African nations in their efforts to develop their technical and vocational education (TVE) systems. Chapter 1,"TVE in Africa: A Synthesis of Case Studies" (B. Wanjala Kerre), presents a synthesis of the case studies in which the following major trends taking place within the existing socioeconomic context are discussed: TVE within existing educational structures; cooperation between TVE institutions and enterprises; major challenges facing the nations in their efforts to develop TVE; and the innovative measures undertaken in response to the problems and constraints experienced. The remaining 12 chapters are individual case studies giving a more detailed picture of natural efforts and challenges encountered in the development of TVE. Chapters 2-8 focus on the role of TVE in educational systems: "TVE in Cameroon" (Lucy Mbangwana); "TVE in Congo" (Gilbert Ndimina); "TVE in Ghana"(F. A. Baiden); "TVE in Kenya"(P. 0. Okaka); "TVE in Madagascar" (Victor Monantsoa); "TVE in Nigeria" (Egbe T. -

Course Entry Requirement Statement for 2021 Entry
Course Entry Requirements Statement for 2021 Entry Course Entry Requirement Statement for 2021 Entry Contents Scope and Purpose ........................................................................................ 3 UK QUALIFICATIONS ......................................................................................... 4 GCSEs and equivalent qualifications .................................................................... 4 A’Levels and equivalent qualifications ................................................................. 4 EU AND INTERNATIONAL QUALIFICATIONS .............................................................. 19 Maritime Courses ........................................................................................ 31 ENGLISH LANGUAGE REQUIREMENTS .................................................................... 29 APPENDIX A: EXEMPTIONS AND EXCEPTIONS ......................................................... 29 APPENDIX B: ACCEPTABLE ENGLISH LANGUAGE QUALIFICATIONS FOR STUDENTS REQUIRING A STUDENT ROUTE VISA ................................................................................... 32 APPENDIX C: EUROPEAN SCHOOL LEAVING/MATRICULATION CERTIFICATES EQUIVALENT TO IELTS (ACADEMIC) 6.0 OVERALL ....................................................................... 38 External Relations | Admissions and Enrolment 2 Updated April 2021 Course Entry Requirements Statement for 2021 Entry Scope and Purpose 1. This document is designed for use by Solent University (SU) staff when evaluating applicants for entry -

Specification for the UCAS Data for HESA (*J) 2018/19
Title: Specification of the UCAS data for HESA Transaction (*J) 2018 Date: 11th October 2018 Version: V1.2 Status: Final Version Security Marking: Private Security Marking: PRIVATE Page 1 of 108 Document Owner: UCAS Last updated: 11/10/2018 1. Overview ............................................................................................................ 3 a. Basis of specification ...................................................................................... 3 b. Providers’ access to transaction ..................................................................... 3 c. Timing ............................................................................................................. 3 d. Structure ......................................................................................................... 3 e. Coverage ........................................................................................................ 3 f. Changes to specification ................................................................................. 4 3. Housekeeping .................................................................................................... 4 a. Document Change Control ............................................................................. 4 4. Changes to data specification for 2018/19 .......................................................... 5 5. Field Specification .............................................................................................. 6 6. UCAS *J file format: UCAS November 2018 .................................................... -

National Qualifications Framework Developments in Europe 2017
ENENEN NATIONAL QUALIFICATIONS FRAMEWORK DEVELOPMENTS IN EUROPE 2017 National qualifications framework developments in Europe 2017 Luxembourg: Publications Office of the European Union, 2018 Please cite this publication as: Cedefop (2018). National qualifications framework developments in Europe 2017. Luxembourg: Publications Office. http://data.europa.eu/doi/10.2801/029873 A great deal of additional information on the European Union is available on the Internet. It can be accessed through the Europa server (http://europa.eu). Luxembourg: Publications Office of the European Union, 2018 Copyright © European Centre for the Development of Vocational Training (Cedefop), 2018 All rights reserved. PRINT ISBN: 78-92-896-2649-1 doi:10.2801/545730 TI-01-18-117-EN-C PDF ISBN: 978-92-896-2650-7 doi:10.2801/029873 TI-01-18-117-EN-N Designed by Missing Element Prague Printed in the European Union The European Centre for the Development of Vocational Training (Cedefop) is the European Union’s reference centre for vocational education and training. We provide information on and analyses of vocational education and training systems, policies, research and practice. Cedefop was established in 1975 by Council Regulation (EEC) No 337/75. Europe 123, 570 01 Thessaloniki (Pylea), GREECE PO Box 22427, 551 02 Thessaloniki, GREECE Tel. +30 2310490111, Fax +30 2310490020 E-mail: [email protected] www.cedefop.europa.eu Joachim James Calleja, Director Tatjana Babrauskiene, Chair of the Governing Board Foreword Cedefop has been working on transparency and recognition of qualifications since the 1980s and has helped shape the European qualifications framework (EQF), adopted in 2008 and revised in 2017. -
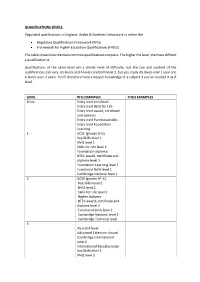
Qualifications Levels Explained
QUALIFICATIONS LEVELS. Regulated qualifications in England, Wales & Northern Ireland are in either the Regulated Qualifications Framework (RFQ) Framework for Higher Education Qualifications (FHEQ) The table shows how the most common qualifications compare. The higher the level, the more difficult a qualification is. Qualifications at the same level are a similar level of difficulty, but the size and content of the qualifications can vary. AS levels and A levels are both level 3, but you study AS levels over 1 year and A levels over 2 years. You’ll therefore have a deeper knowledge of a subject if you’ve studied it at A level. LEVEL RFQ EXAMPLES FHEQ EXAMPLES Entry Entry level certificate Entry level Skills for Life Entry level award, certificate and diploma Entry level Functional skills Entry level Foundation Learning 1 GCSE (grades D-G) Key Skills level 1 NVQ level 1 Skills for Life level 1 Foundation diploma BTEC award, certificate and diploma level 1 Foundation Learning level 1 Functional Skills level 1 Cambridge National level 1 2 GCSE (grades A*-C) Key Skills level 2 NVQ level 2 Skills for Life level 2 Higher diploma BTEC award, certificate and diploma level 2 Functional Skills level 2 Cambridge National level 2 Cambridge Technical level 3 AS and A level Advanced Extension Award Cambridge International award International Baccalaureate Key Skills level 3 NVQ level 3 Advanced diploma Progression diploma BTEC award, certificate and diploma level 3 BTEC National Cambridge Technical level 3 4 HNC Certificate of higher education Certificate -

Numerical Selective List
Iowa Department of Administrative Services – Human Resources Enterprise Selective List Introduction to Selectives Selective certification requirements, known simply as “selectives,” are position-specific additional qualification requirements that are based on the demonstrated job-related needs of an individual position being filled. Not every position will require the use of a selective and some positions may require more than one selective. Each selective used must be directly related to the duties of the job. Using a selective narrows the applicant pool by seeking a more specific type of background within the stated minimum qualifications. Selectives do not take the place of the minimum requirements for a vacancy; rather, selectives are necessary, position-specific requirements that an applicant must meet in addition to the minimum qualifications listed for each vacancy. These selective certification requirements are usually based on technical competencies specific to an individual position. Selectives are often expressed as six months of experience or 12 semester hours of education in the selective area, or a combination of both. However, some others may require possession of a specific license, endorsement, or professional certification instead of education or work experience. Revised June 13, 2019 As the chart above depicts, in the case of vacancies that require a selective, an applicant is qualified if the minimum qualifications and the selective certification requirements are met. An applicant is not qualified for the particular position if the minimum qualifications for the job classification are met but the position-specific selective certification requirements are not met. In that instance, the applicant could still be qualified for another vacancy in the same job classification that does not require a selective or that requires another selective for which the applicant meets the criteria.