Fault Injection Framework for Time-Triggered Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
On Ttethernet for Integrated Fault-Tolerant Spacecraft Networks
On TTEthernet for Integrated Fault-Tolerant Spacecraft Networks Andrew Loveless∗ NASA Johnson Space Center, Houston, TX, 77058 There has recently been a push for adopting integrated modular avionics (IMA) princi- ples in designing spacecraft architectures. This consolidation of multiple vehicle functions to shared computing platforms can significantly reduce spacecraft cost, weight, and de- sign complexity. Ethernet technology is attractive for inclusion in more integrated avionic systems due to its high speed, flexibility, and the availability of inexpensive commercial off-the-shelf (COTS) components. Furthermore, Ethernet can be augmented with a variety of quality of service (QoS) enhancements that enable its use for transmitting critical data. TTEthernet introduces a decentralized clock synchronization paradigm enabling the use of time-triggered Ethernet messaging appropriate for hard real-time applications. TTEther- net can also provide two forms of event-driven communication, therefore accommodating the full spectrum of traffic criticality levels required in IMA architectures. This paper explores the application of TTEthernet technology to future IMA spacecraft architectures as part of the Avionics and Software (A&S) project chartered by NASA's Advanced Ex- ploration Systems (AES) program. Nomenclature A&S = Avionics and Software Project AA2 = Ascent Abort 2 AES = Advanced Exploration Systems Program ANTARES = Advanced NASA Technology Architecture for Exploration Studies API = Application Program Interface ARM = Asteroid Redirect Mission -

Wireless Technologies for the Next-Generation Train Control and Monitoring System
Wireless Technologies for the Next-Generation Train Control and Monitoring System Jérôme Härri Aitor Arriola Pedro Aljama Communication Systems Communication Systems Communication Systems EURECOM Ikerlan Ikerlan Sophia-Antipolis, France Arrasate-Mondragón, Spain Arrasate-Mondragón, Spain [email protected] [email protected] [email protected] Igor Lopez Uwe Fuhr Marvin Straub Technology Division TCMS Communcations TCMS Communcations CAF R&D Bombardier Transportation Bombardier Transportation Beasain, Spain Mannheim, Germany Mannheim, Germany [email protected] [email protected] [email protected] Abstract—The Next Generation Train Control and functionalities (e.g. [4]). Yet, a study introducing the global Monitoring System (NG-TCMS) represents a major innovation NG-TCMS requirements and matching with a technology- of the European Railway industry introducing a wireless agnostic survey of various available wireless technologies is architecture as an enabler to enhanced automation, flexible train still missing. management and increased railway capacity. This paper surveys various available and future wireless technologies matching the In this paper, we describe the vision and functionalities of requirements both at train backbone and consist levels. the NG-TCMS, putting into perspective the performance Illustrating the challenges for a single technology to match all requirements of wireless links for the WLTB and WLCN with requirements, this paper also highlights the benefits of the the performance of selected wireless technologies. Our upcoming 5G technology for future NG-TCMS. contributions are threefold: (i) we introduce the future NG- TCMS, in particular the WLTB and WLCN, (ii) we provide a Keywords—5G-V2X, LTE-V2X, Wireless Train Backbone, technology-agnostic comparison of selected technologies Wireless Consist Network, 5G, NG-TCMS. -

An Extension of the Omnet++ INET Framework for Simulating Real-Time Ethernet with High Accuracy
An Extension of the OMNeT++ INET Framework for Simulating Real-time Ethernet with High Accuracy Till Steinbach, Hermand Dieumo Kenfack, Franz Korf, Thomas C. Schmidt HAW-Hamburg, Department Informatik Berliner Tor 7, D-20099 Hamburg, Germany {till.steinbach, hermand.dieumo, korf, schmidt}@informatik.haw-hamburg.de ABSTRACT those fields; real-time Ethernet is a promising candidate for Real-time extensions to standard switched Ethernet widen the upcoming tasks. the realm of computer networking into the time-critical do- Ethernet has proven to be a flexible, widely deployed, and main. These technologies have started to establish in pro- highly scalable protocol. Current Ethernet is a technology cess automation, while Ethernet-based communication in- based on switching that also allows to increase the amount of frastructures in vehicles are novel and challenged by particu- traffic simultaneously transferred, by using segregated com- larly hard real-time constraints. Simulation tools are of vital munication in groups. However, due to its randomised me- importance to explore the technical feasibility and facilitate dia access and best effort approach, it does not provide re- the distributed process of vehicle infrastructure design. liable temporal performance bounds. Real-time extensions This paper introduces an extension of the OMNeT++ to Ethernet promise to overcome those obstacles. INET framework for simulating real-time Ethernet with high In process automation, several Ethernet-based products temporal accuracy. Our module implements the TTEther- already provide real-time functionality for tasks with strict net protocol, a real-time extension to standard Ethernet that temporal constraints. The use of real-time Ethernet in an is proposed for standardisation. -

Deliverable Title
Contract No. H2020 – 826098 CONTRIBUTING TO SHIFT2RAIL'S NEXT GENERATION OF HIGH CAPABLE AND SAFE TCMS. PHASE II. D1.1 – Specification of evolved Wireless TCMS Due date of deliverable: 31/12/2019 Actual submission date: 20/12/2019 Leader/Responsible of this Deliverable: Igor Lopez (CAF) Reviewed: Y Project funded from the European Union’s Horizon 2020 research and innovation programme Dissemination Level PU Public X CO Confidential, restricted under conditions set out in Model Grant Agreement Start date: 01/10/2018 Duration: 30 months CTA2-T1.1-D-CAF-005-09 Page 1 of 175 20/12/2019 Contract No. H2020 – 826098 Document status Revision Date Description First issue. Executive summary, Introduction and General 01 27/11/2018 architecture 02 27/06/2019 Contributions of sections 3.1, 3.2, 4.2, 5.2, 5.3, 6.1, 6.2, 6.3, 8 03 03/09/2019 Section 4.1 added. Updated sections 5, 6 and 8 Doc template: corrected footer Abbreviations and Acronyms list: updated Section 3.2: corrected internal references according to CTA2- 04 22/11/2019 T1.1-I-BTD-008-04 Sections 6: updated accoding to CTA2-T1.1-I-BTD-030-09, added new references, corrected internal references 05 05/12/2019 Section 4.2.3: content added 06 06/12/2019 Updated according to CTA2-T1.1-R-SNF-061-01 07 08/12/2019 Section 5.2 and 5.3 added. 08 17/12/2019 Reviews to new contributions applied Whole Document review from CTA2 T1.1 members, TMT and 09 20/12/2019 Safe4RAIL-2 members Disclaimer The information in this document is provided “as is”, and no guarantee or warranty is given that the information is fit for any particular purpose. -

Universidad Nacional De Chimborazo Facultad De Ingeniería Carrera De Electrónica Y Telecomunicaciones
UNIVERSIDAD NACIONAL DE CHIMBORAZO FACULTAD DE INGENIERÍA CARRERA DE ELECTRÓNICA Y TELECOMUNICACIONES Proyecto de Investigación previo a la obtención del título de Ingeniero en Electrónica y Telecomunicaciones TRABAJO DE TITULACIÓN DISEÑO Y SIMULACIÓN DE UNA RED DE COMUNICACIÓN EN VAGONES DE FERROCARRILES A TRAVÉS DE LA UTILIZACIÓN DE LOS ESTÁNDARES IEC 61375 PARA LA RUTA TREN DEL HIELO I (RIOBAMBA – URBINA – LA MOYA – RIOBAMBA) Autor: Denis Andrés Maigualema Quimbita Tutor: Ing. PhD. Ciro Diego Radicelli García Riobamba - Ecuador Año 2020 I Los miembros del tribunal de graduación del proyecto de investigación de título: “DISEÑO Y SIMULACIÓN DE UNA RED DE COMUNICACIÓN EN VAGONES DE FERROCARRILES A TRAVÉS DE LA UTILIZACIÓN DE LOS ESTÁNDARES IEC 61375 PARA LA RUTA TREN DEL HIELO I (RIOBAMBA – URBINA – LA MOYA – RIOBAMBA)”, presentado por: Denis Andrés Maigualema Quimbita, y dirigido por el Ing. PhD. Ciro Diego Radicelli García. Una vez revisado el informe final del proyecto de investigación con fines de graduación escrito en el cual consta el cumplimento de las observaciones realizadas, remite la presente para uso y custodia en la Biblioteca de la Facultad de Ingeniería de la UNACH. Para constancia de lo expuesto firman. Ing. PhD. Ciro Radicelli Tutor Dr. Marlon Basantes Miembro del tribunal Ing. José Jinez Miembro del tribunal II DECLARACIÓN EXPUESTA DE TUTORÍA En calidad de tutor del tema de investigación: “DISEÑO Y SIMULACIÓN DE UNA RED DE COMUNICACIÓN EN VAGONES DE FERROCARRILES A TRAVÉS DE LA UTILIZACIÓN DE LOS ESTÁNDARES IEC 61375 PARA LA RUTA TREN DEL HIELO I (RIOBAMBA – URBINA – LA MOYA – RIOBAMBA ". Realizado por el Sr. -

Innovative Monitoring and Predictive Maintenance Solutions on Lightweight Wagon
Innovative Monitoring and Predictive Maintenance Solutions on Lightweight Wagon Grant Agreement no.: 730863 - S2R-OC-IP5-03-2015 Project Start Date: 01/11/2016 Project End Date: 30/04/2019 DELIVERABLE D1.1 Benchmark and market drivers for an integrated intelligent and lightweight wagon solution Work Package: WP 1 Deliverable type R Dissemination Level: PU Status: Final Leader beneficiary: UNEW Due date of deliverable: 31/03/2017 Actual submission date: 31/03/2017 Prepared by: Cristian Ulianov and Paul Hyde, Newcastle University (UNEW) Contributors: Sian Evans, Newcastle University (UNEW) Liang Cheng, Newcastle University (UNEW) Emmanuel Matsika, Newcastle University (UNEW) Raluca Marin-Perianu, Inertia Technology B.V. (INE) Martin Wischner, Havelländische Eisenbahn AG (HVLE) Daniele Regazzi, Lucchini RS S.p.A. (LRS) Franco Castagnetti, NewOpera Aisbl (NEWO) Giuseppe Rizzi, NewOpera Aisbl (NEWO) David Vincent, Perpetuum Ltd. (PER) Stefano Bruni, Politecnico di Milano (POLIM) Marco Macchi, Politecnico di Milano (POLIM) Dachuan Shi, Technische Universität Berlin (TUB) Philipp Krause, Technische Universität Berlin (TUB) Florentin Barbuceanu, Uzina de Vagoane Aiud S.A. (UVA) Verified by: Cristian Ulianov Deliverable D1.1 Document history Version Date Author(s) Description D1 02/12/2016 Cristian Ulianov [UNEW] Document initiated, draft structure D2 20/12/2016 Cristian Ulianov [UNEW] Document updated, structure and Paul Hyde [UNEW] content proposed D3 24/01/2017 All Update of structure and content D5 23/02/2017 All Content added and revised -

Industrielle Bussysteme : Ethernet • Ethernet Link Schicht • Medium Access Control • Logical Link Control – LLC Dr
Inhalt • Ethernet Übersicht und Protokolle • Ethernet Schicht-1 Industrielle Bussysteme : Ethernet • Ethernet Link Schicht • Medium Access Control • Logical Link Control – LLC Dr. Leonhard Stiegler Automation • Ergänzende LAN Protokolle www.dhbw-stuttgart.de Industrielle Bussysteme , Teil 1 – Ethernet, L.Stiegler , 1 5. Semester, Automation, 2015 Industrielle Bussysteme , Teil 1 – Ethernet, L.Stiegler , 2 5. Semester, Automation, 2015 Definitionen IEEE 802 Standardisierung Ein Computernetz ist eine Zusammenschaltung von Host-Rechnern, die 802.1 LAN/MAN Architecture Informationen austauschen über WGs: Interworking, - Übertragungsverbindungen und Security, Audio/Video Bridging and Netzknoten - Congestion Management. Ein Lokales Netz (LAN) umfasst in der Regel einen begrenzten 802.2 : Logical Link Control (LLC) geografischen Bereich, wie z.B. ein Gebäude, Stockwerk oder einen 802.3 : Ethernet Campus Basic Ethernet 10 Mbit/s Ethernet ist eine weit verbreitete LAN Technologie. Sie definiert Fast Ethernet 100 Mbit/s over copper or fibre Gbit-Ethernet 1 Gbit/s over copper or fibre - das Übertragungsmedium 10G-Ethernet 10 Gbit/s over optical fibres - den Zugang zum Medium 802.11 : WLAN - die physikalischen Übertragungseigensaften und Prozeduren 802.16 : WMAN Ethernet ist Teil der Standardisierungsfamilie 802 802.17 : Resilient Packet Ring Industrielle Bussysteme , Teil 1 – Ethernet, L.Stiegler , 3 5. Semester, Automation, 2015 Industrielle Bussysteme , Teil 1 – Ethernet, L.Stiegler , 4 5. Semester, Automation, 2015 IEEE 802.3 Standards LAN Characteristika -

Industrial Networking Solutions for Mission Critical Applications
www.hirschmann.com GLOBAL LOCATIONS Industrial Networking Solutions for Mission Critical Applications For more information, please visit us at: www.belden.com/hirschmann Industrial Networking Solutions for Mission Critical Applications Critical Mission Industrial for Networking Solutions UNITED STATES CANADA LATIN AMERICA and the CARIBBEAN ISLANDS Division Headquarters Industrial Networking National Business Regional Office – Americas (Hirschmann/GarrettCom/ Center 6100 Hollywood Boulevard 2200 U.S. Highway 27 South Tofino Security) 2280 Alfred-Nobel Suite 110 Richmond, IN 47374 255 Fourier Ave. Suite 200 Hollywood, Florida 33024 Phone: 765-983-5200 Fremont, CA 94539, USA Saint-Laurent, QC Phone: 954-987-5044 Canada H4S 2A4 Inside Sales: 800-235-3361 Phone: 510-438-9071 Fax: 954-987-8022 Fax: 765-983-5294 Fax: 510-952-3456 Phone: 514-822-2345 [email protected] [email protected] www.belden.com Fax: 514-822-7979 www.belden.com [email protected] Belden 2200 U.S. Highway 27 South Richmond, IN 47374a Inside Sales: 1-800-BELDEN-1 (1-800-235-3361) Industry-specific solutions that can Phone: 765-983-5200 Fax: 765-983-5294 improve productivity and operational [email protected] efficiency today, while laying the foundations for tomorrow‘s IIoT opportunities. Belden, Belden Sending All The Right Signals, GarrettCom, Hirschmann, Lumberg Automation, Tofino Security, Tripwire and the Belden logo are trademarks or registered trademarks of Belden Inc. or its affiliated companies in the United States and other jurisdictions. Belden and other parties may also have trademark rights in other terms used herein. Edition 2017 ©Copyright 2017, Belden Inc. Edition 2017 Printed in Germany HIRSCHMANN-INDUSTRIAL-NETWORKING-SOLUTIONS_CA_INIT_HIR_0117_A_AG Prepare your infrastructure for the Industrial Internet of Things (IIoT) The IIoT is widely considered to be one of the primary trends affecting industrial businesses today and in the future. -

Developing Deterministic Networking Technology for Railway Applications Using Ttethernet Software-Based End Systems
INDustrial EXploitation of the genesYS cross-domain architecture Developing deterministic networking technology for railway applications using TTEthernet software-based end systems Project n° 100021 Astrit Ademaj, TTTech Computertechnik AG Outline INDustrial EXploitation of the genesYS cross-domain architecture GENESYS requirements - railway Time-triggered communication TTEthernet SW based implementation of the TTEthernet Conclusion ARTEMISIA Association Title Presentation - 2 GENESYS – GENeric Embedded SYStems INDustrial EXploitation of the genesYS cross-domain architecture Instruction how to build your embedded systems architecture GENESYS: ¾ is a reference architecture template providing specifications and requirements to design a cross domain embedded systems architecture. ¾ architecture style supports a composable, robust and comprehensible, component based framework with strict separation of computation from message based communication ¾ distinguishes between 3 integration levels: • Chip Level (IP cores communicate via a deterministic Network-on-a-Chip) • Device Level (Chips communicate within a device) • System Level (Devices communicate in an open or closed environment) ARTEMISIA Association Title Presentation - 3 GENESYS and the railway domain INDustrial EXploitation of the genesYS cross-domain architecture Safety-critical applications in the railway domain require ¾ deterministic communication networks ¾ robustness and ¾ composability are key issues. GENESYS ¾ architecture style supports a composable, robust and comprehensible, -
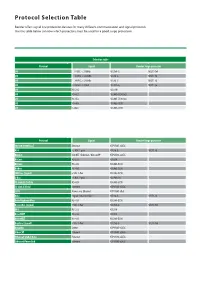
Protocol Selection Table
Protocol Selection Table Bender offers signal line protection devices for many different communication and signal protocols. Use the table below to know which protectors must be used for a good surge protection. Selection table Protocol Signal Bender Surge protector I/O ± 5 VDC, < 250kHz NSL7v5-G NSLT1-7v5 I/O ± 12 VDC, < 250kHz NSL18-G NSLT1-18 I/O ± 24 VDC, < 250kHz NSL36-G NSLT1-36 I/O 0-20mA / 4-20mA NSL420-G NSLT1-36 I/O RS-232 NSL-DH I/O RS-422 NSL485-EC90 (x2) I/O RS-452 NSL485-EC90 (x2) I/O RS-485 NSL485-EC90 I/O 1-Wire NSL485-EC90 Protocol Signal Bender Surge protector 10/100/1000BaseT Ethernet NTP-RJ45-xCAT6 AS-i 32 VDC 1-pair NSL36-G NSLT1-36 BACnet ARCNET / Ethernet / BACnet/IP NTP-RJ45-xCAT6 BACnet RS-232 NSL-DH BACnet RS-485 NSL485-EC90 BitBus RS-485 NSL485-EC90 CAN Bus (Signal) 5 VDC 1-Pair NSL485-EC90 C-Bus 36 VDC 1-pair NSSP6A-38 CC-Link/LT/Safety RS-485 NSL485-EC90 CC-Link IE Field Ethernet NTP-RJ45-xCAT6 CCTV Power over Ethernet NTP-RJ45-xPoE DALI Digital Serial Interface NSL36-G NSLT1-36 Data Highway/Plus RS-485 NSL485-EC90 DeviceNet (Signal) 5 VDC 1-Pair NSL7v5-G NSLT1-7v5 DF1 RS-232 NSL-DH DirectNET RS-232 NSL-DH DirectNET RS-485 NSL485-EC90 Dupline (Signal) 5 VDC 1-Pair NSL7v5-G NSLT1-7v5 Dynalite DyNet NTP-RJ45-xCAT6 EtherCAT Ethernet NTP-RJ45-xCAT6 Ethernet Global Data Ethernet NTP-RJ45-xCAT6 Ethernet Powerlink Ethernet NTP-RJ45-xCAT6 Protocol Signal Bender Surge protector FIP Bus RS-485 NSL485-EC90 FINS Ethernet NTP-RJ45-xCAT6 FINS RS-232 NSL-DH FINS DeviceNet (Signal) NSL7v5-G NSLT1-7v5 FOUNDATION Fieldbus H1 -

A Survey of Channel Measurements and Models
A Survey of Channel Measurements and Models for Current and Future Railway Communication Systems Paul Unterhuber, Stephan Pfletschinger, Stephan Sand, Mohamed Soliman, Thomas Jost, Aitor Arriola, Inaki Val, Cristina Cruces, Juan Moreno, Juan Pablo Garcia-Nieto, et al. To cite this version: Paul Unterhuber, Stephan Pfletschinger, Stephan Sand, Mohamed Soliman, Thomas Jost, et al.. A Survey of Channel Measurements and Models for Current and Future Railway Com- munication Systems. Mobile Information Systems, Hindawi/IOS Press, 2016, 2016, pp.7308604. 10.1155/2016/7308604. hal-01578998 HAL Id: hal-01578998 https://hal.archives-ouvertes.fr/hal-01578998 Submitted on 30 Aug 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Hindawi Publishing Corporation Mobile Information Systems Volume 2016, Article ID 7308604, 14 pages http://dx.doi.org/10.1155/2016/7308604 Review Article A Survey of Channel Measurements and Models for Current and Future Railway Communication Systems Paul Unterhuber,1 Stephan Pfletschinger,1 Stephan Sand,1 Mohammad Soliman,1 Thomas Jost,1 Aitor Arriola,2 Iñaki Val,2 Cristina Cruces,2 Juan Moreno,3 Juan Pablo García-Nieto,3 Carlos Rodríguez,3 Marion Berbineau,4 Eneko Echeverría,5 and Imanol Baz5 1 German Aerospace Center (DLR), Oberpfaffenhofen, 82234 Wessling, Germany 2IK4-IKERLAN, Arizmendiarrieta 2, 20500 Mondragon, Spain 3MetrodeMadrid(MDM),CalleCavanilles58,28007Madrid,Spain 4Universite´ Lille Nord de France, IFSTTAR, COSYS, 59650 Villeneuve d’Ascq, France 5Construcciones y Auxiliar de Ferrocarriles (CAF), J.M. -

Read Full Text (PDF)
Industrial networks and IIoT: Now and future trends Downloaded from: https://research.chalmers.se, 2021-09-25 14:32 UTC Citation for the original published paper (version of record): Sari, A., Lekidis, A., Butun, I. (2020) Industrial networks and IIoT: Now and future trends Industrial IoT: Challenges, Design Principles, Applications, and Security: 3-55 http://dx.doi.org/10.1007/978-3-030-42500-5_1 N.B. When citing this work, cite the original published paper. research.chalmers.se offers the possibility of retrieving research publications produced at Chalmers University of Technology. It covers all kind of research output: articles, dissertations, conference papers, reports etc. since 2004. research.chalmers.se is administrated and maintained by Chalmers Library (article starts on next page) 8JJINXHZXXNTSXXYFYXFSIFZYMTWUWTKNQJXKTWYMNXUZGQNHFYNTSFYMYYUX\\\WJXJFWHMLFYJSJYUZGQNHFYNTS ,QGXVWULDO1HWZRUNVDQG,,R71RZDQG)XWXUH7UHQGV (MFUYJW{/ZQ^ )4.D (.9&9.438 7*&)8 FZYMTWX &QUFWXQFS8FWN &QJ]NTX1JPNINX :SN[JWXNY^TK)JQF\FWJFWJ .SYWFHTR9JQJHTR8& 5:'1.(&9.438dddFor(.9&9.438(.9&9 ddd 5:'1.(&9.438ddd(.9&9.438ddd 8**574+.1* 8**574+.1* .XRFNQ'ZYZS (MFQRJWX:SN[JWXNY^TK9JHMSTQTL^ 5:'1.(&9.438ddd(.9&9.438ddd 8**574+.1* 8TRJTKYMJFZYMTWXTKYMNXUZGQNHFYNTSFWJFQXT\TWPNSLTSYMJXJWJQFYJIUWTOJHYXReviewJIUWTOJHYX .S2TYNTS;NJ\UWTOJHY *SJWL^HTSXZRUYNTSKTW.T9X^XYJRX;NJ\UWTOJHY &QQHTSYJSYKTQQT\NSLYMNXUFLJ\FXZUQTFIJIG^&QJ]NTX1JPNINXTS/ZQ^ 9MJZXJWMFXWJVZJXYJIJSMFSHJRJSYTKYMJIT\SQTFIJIKNQJ Industrial networks and IIoT: Now and future trends Alparslan Sari, Alexios Lekidis, and Ismail Butun For Abstractact ConnectivityConnecti is tthe one word summary for Industry 4.0 revolution. The importancemportancetance of InternetIntern of ThinThings (IoT) and Industrial IoT (IIoT) have been increased dramaticallyaticallytically with the rise ofo induindustrialization and industry 4.0. As new opportunities bring theireir own challenges, wwith the massive interconnected devices of the IIoT, cyber securityrity of thosetho netwnetworks anddpr privacy of their users have become an impor- tant aspect.