Spatial Analysis of Factors Predicting Bicycle Ridership
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Monitoring Use of Minnesota State Trails Considerations and Recommendations for Implementation
Monitoring Use of Minnesota State Trails Considerations and Recommendations for Implementation MURP Capstone Paper In Partial Fulfillment of the Master of Urban and Regional Planning Degree Requirements The Hubert H. Humphrey School of Public Affairs The University of Minnesota Tom Holmes Jake Knight Darin Newman Xinyi Wu May 20, 2016 Date of oral presentation: Approval date of final paper: May 6, 2016 May 20, 2016 Capstone Instructor: Dr. Greg Lindsey, Professor Photo credit: www.flickr.com/photos/zavitkovski/6266747939/ Monitoring Use of Minnesota State Trails Considerations and Recommendations for Implementation Prepared for the Minnesota Department of Natural Resources Tom Holmes Jake Knight Darin Newman Xinyi Wu May 20, 2016 Advisor: Dr. Greg Lindsey Capstone Paper In Partial Fulfillment of the Master of Urban and Regional Planning Degree Requirements The Hubert H. Humphrey School of Public Affairs The University of Minnesota Monitoring Use of Minnesota State Trails | MURP Capstone Paper Table of Contents Executive Summary 1. Introduction 1 1.1. Project Methodology 3 2. Project Context 5 2.1. Historical DNR Trail Surveys 5 2.2. Project Purpose 7 2.3. Project Scope 7 3. Counting Methods 9 3.1. Duration 9 3.2. Visits 10 3.3. Traffic 10 3.4. Case Study 1: Differentiating Duration, Visits, and Traffic on the Gateway State Trail 12 3.5. Recommendation: Traffic Counts 13 4. Considerations for Automated Traffic Counts 15 4.1 How to Implement Automated Traffic Counts 15 4.2. Case Study 2: Gateway and Brown’s Creek State Trail AADT 17 4.3. Seven Decisions for Program Design 20 5. -

A Study of Bicycle Commuting in Minneapolis: How Much Do Bicycle-Oriented Paths
A STUDY OF BICYCLE COMMUTING IN MINNEAPOLIS: HOW MUCH DO BICYCLE-ORIENTED PATHS INCREASE RIDERSHIP AND WHAT CAN BE DONE TO FURTHER USE? by EMMA PACHUTA A THESIS Presented to the Department of Planning, Public Policy and Management and the Graduate School of the University of Oregon in partial fulfillment of the requirements for the degree of 1-1aster of Community and Regional Planning June 2010 11 ''A Study of Bicycle Commuting in Minneapolis: How Much do Bicycle-Oriented Paths Increase Ridership and What Can be Done to Further Use?" a thesis prepared by Emma R. Pachuta in partial fulfillment of the requirements for the Master of Community and Regional Planning degree in the Department of Planning, Public Policy and Management. This thesis has been approved and accepted by: - _ Dr. Jean oclcard, Chair of the ~_ . I) .).j}(I) Date {).:........:::.=...-.-/---------'-------'-----.~--------------- Committee in Charge: Dr. Jean Stockard Dr. Marc Schlossberg, AICP Lisa Peterson-Bender, AICP Accepted by: 111 An Abstract of the Thesis of Emma Pachuta for the degree of Master of Community and Regional Planning in the Department of Planning, Public Policy and Management to be taken June 2010 Title: A STUDY OF BICYCLE COMMUTING IN MINNEAPOLIS: HOW MUCH DO BICYCLE-ORIENTED PATHS INCREASE RIDERSHIP AND WHAT CAN BE DONE TO FURTHER USE? Approved: _~~ _ Dr. Jean"'stockard Car use has become the dominant form of transportation, contributing to the health, environmental, and sprawl issues our nation is facing. Alternative modes of transport within urban environments are viable options in alleviating many of these problems. This thesis looks the habits and trends of bicyclists along the Midtown Greenway, a bicycle/pedestrian pathway that runs through Minneapolis, Minnesota and questions whether implementing non-auto throughways has encouraged bicyclists to bike further and to more destinations since its completion in 2006. -

Bicycle and Pedestrian Data Collection Manual - Draft July 2015 6
View the updated report: Bicycle and Pedestrian Data Collection Manual - JULY 17, 2015 The Minnesota Department of Transportation Draft is developing a statewide bicycle and pedestrian data collection program. This manual summarizes main elements of this program, including data collection goals, types of data to collect and best practices for sensor calibration and data analysis. The research phase of the program is expected to be completed in 2016, at which time the manual will be updated and issued as a final document. Minnesota Department of Transportation MnDOT Report No. MN/RC 2015-33 Office of Transit, Bicycle / Pedestrian Section [email protected] www.dot.state.mn.us/bike To request this document in an alternate format call 651-366-4718 or 1-800-657-3774 (Greater Minnesota) or email your request to [email protected]. Please request at least one week in advance. Technical Report Documentation Page 1. Report No. 2. 3. Recipients Accession No. MN/RC 2015-33 4. Title and Subtitle 5. Report Date Bicycle and Pedestrian Data Collection Manual - Draft July 2015 6. 7. Author(s) 8. Performing Organization Report No. Erik Minge, Cortney Falero, Greg Lindsey, Michael Petesch 9. Performing Organization Name and Address 10. Project/Task/Work Unit No. SRF Consulting Group Inc. Humphrey School of Public One Carlson Parkway North Affairs, Office 295 11. Contract (C) or Grant (G) No. Plymouth, MN 55447 University of Minnesota (c) 04301 301 19th Avenue South Minneapolis, MN 55455 12. Sponsoring Organization Name and Address 13. Type of Report and Period Covered Minnesota Department of Transportation Draft Manual Office of Transit, Bicycle/Pedestrian Section Mail Stop 315 395 14. -

Above the Falls Master Plan Chapter Four
SECTION 4 Visitor Demand ABOVE THE FALLS REGIONAL PARK MASTER PLAN PARK MASTER PLAN Minneapolis Park & Recreation Board PAGE 4-1 Demands on parks and recreation facilities continue to intensify. Park and trail usage is expected to increase as the population grows and as the trails network expands. According to the Metropolitan Council Regional Population Forecast, the population in the metropolitan area is expected to increase substantially in the next 10 – 20 years. Further, Minneapolis is expected to grow 15% by the year 2030 to 439,100, up from the 2010 census of 382,578. With an increasing population comes increasing park visitation. According to the Metropolitan Council, use of regional parks and trails will increase 9% between the years 2005 and 2020. This increase is in addition to the almost 10% increase in regional Watching the River Rats water-ski team park use from 1995 to 2005 and a 12% increase in regional trail use within this from park land along West River Road same time period. North is a popular activity. TableRegional 10: Visitation parks estimates and trails by agency in the for operationsTwin Cities and and within Minneapolis are maintenancedestinations fundi forng formulavisitors purposes from across - 2016 the region, state, nation, and world. As shown in Figure 4.1, roughly 201636% Visitation of regional Percentage park and of trail visits in the Twin Agency (1,000's) total 1 AnokaCities County are visits to the Minneapolis3,360.04 system. Above the7.04% Falls Regional Park is one Bloomingtonof eight regional parks (in addition to755.16 ten regional trails)1.58% in Minneapolis. -

2020-244 MC MPRB Shingle Creek RT MP
Committee Report Business Item No. 2020-244 Community Development Committee Report For the Metropolitan Council meeting of October 28, 2020 Subject: Shingle Creek Regional Trail Master Plan, Minneapolis Park and Recreation Board, Review File No. 50218-1 Proposed Action That the Metropolitan Council: 1. Approve Minneapolis Park and Recreation Board’s Shingle Creek Regional Trail Master Plan, including the supplemental information provided in the “Clarification of Submittal of Shingle Creek Regional Trail Master Plan” letter dated September 2, 2020. 2. Require that Minneapolis Park and Recreation Board, prior to initiating any new development of the regional trail corridor, send preliminary plans to the Environmental Services Assistant Manager at the Metropolitan Council’s Environmental Services Division. Summary of Committee Discussion/Questions Colin Kelly, Planning Analyst, presented the staff report to the Community Development Committee at its meeting on October 19, 2020. Council Member Atlas-Ingebretson noted how the design concepts respond directly to community engagement with underrepresented populations. Council Member Lindstrom asked when the recommended improvements in this master plan may be funded and implemented. Kelly responded that three to five years is a reasonable estimate. Council Member Wulff raised some concerns about mixing local and regional park amenities and suggested “drawing a line along the trail” to distinguish regional trail-appropriate facilities from those that are considered local. Facilities outside of -

Above the Falls Regional Park Master Plan Draft
DRAFT DRAFT Above the FAlls RegionAl PARk MAsteR PlAn DRAFT FOR PUBLIC COMMENT JUNE, 2013 MINNEAPOLIS PARK & RECREATION BOARD Acknowledgements The Minneapolis Park & Recreation Board is grateful to the many individuals, organizations and agency staff who contributed to this regional park plan. The planning process began in 2010 and continued through early 2013, and included the following outreach: • The Minneapolis Riverfront Development Initiative’s 6 large pubilc meetings and dozens of community events in 2011; • Ongoing collaboration with the Above the Falls Citizen Advisory Committe to help shape the planning process and plan content; • More than 60 meetings with community organizations, and 3 large public engagement meetings dedicated to the plan in 2012 and 2013, including multi-lingual outreach conducted in English, Spanish, Hmong and Lao; • Press releases, web postings and comment cards; and • Ongoing inter-agency coordination through the Riverfornt Technical Advisory Committee: • City of Minneapolis • Hennepin County • Mississippi Watershed Management Organization • University of Minnesota • National Park Service • Friends of the Mississippi River • Minneapolis Riverfront Partnership • US Army Corps of Engineers • Minnesota Department of Natural Resources • Minnesota Historical Society • Minnesota Department of Transportation • Minneapolis Park an&d Recreation Board Images used in this document are property of the Minneapolis Park & Recreation Board unless otherwise credited. More information about this plan and the planning process is available here: http://www.minneapolisparks.org/abovethefalls Notes about this document This DRAFT Above the Falls Regional Park Master Plan (ATF Park Plan) is for public review and comment. Following a 45-day public comment, a final draft will be presented to the Park Board for their consideration. -

Above the Falls Regional Park Master Plan
SECTION 4 Visitor Demand ABOVE THE FALLS REGIONAL PARK MASTER PLAN PARK MASTER PLAN Minneapolis Park & Recreation Board PAGE 4-1 Demands on parks and recreation facilities continue to intensify. Park and trail usage is expected to increase as the population grows and as the trails network expands. According to the Metropolitan Council Regional Population Forecast, the population in the metropolitan area is expected to increase substantially in the next 10 – 20 years. Further, the city of Minneapolis is expected to grow 15% by the year 2030 to 439,100, up from the 2010 census of 382,578. With an increasing population comes increasing park visitation. According to the Metropolitan Council, use of regional parks and trails will increase 9% between the years 2005 and 2020. This increase is in addition to the almost 10% increase Watching the River Rats water-ski team in regional park use from 1995 to 2005 and a 12% increase in regional trail use from park land along West River Road within this same time period. North is a popular activity. TableRegional 10: Visitation parks estimatesand trails by in agency Minneapolis for operations continue and to be a destination for visitors maintenancefrom all over funding the formula region, purposes state, nation - 2016 and world. As shown in Figure 4.1 below, 35.9% of all regional park and 2016trail Visitation visits are toPercentage Minneapolis of Park and Recreation Agency (1,000's) total 1 AnokaBoard County facilities. Above the Falls Regional3,360.04 Park is one7.04% of eight regional parks (in Bloomingtonaddition to ten Regional Trails) within755.16 the City of Minneapolis1.58% celebrating the Carver County 582.79 1.22% Dakotaheritage, County environment, and recreational1,293.74 opportunities2.71% of the Mississippi River. -

The Minnesota Bicycle and Pedestrian Counting Initiative: Methodologies for Non-Motorized Traffic Monitoring
The Minnesota Bicycle and Pedestrian Counting Initiative: Methodologies for Non-motorized Traffic Monitoring Greg Lindsey, Principal Investigator Hubert H. Humphrey School of Public Affairs University of Minnesota October 2013 Research Project Final Report 2013-24 To request this document in an alternative format, call Bruce Lattu at 651-366-4718 or 1-800- 657-3774 (Greater Minnesota); 711 or 1-800-627-3529 (Minnesota Relay). You may also send an e-mail to [email protected]. (Please request at least one week in advance). Technical Report Documentation Page 1. Report No. 2. 3. Recipients Accession No. MN/RC 2013-24 4. Title and Subtitle 5. Report Date October 2013 The Minnesota Bicycle and Pedestrian Counting Initiative: 6. Methodologies for Non-motorized Traffic Monitoring 7. Author(s) 8. Performing Organization Report No. Greg Lindsey, Steve Hankey, Xize Wang, and Junzhou Chen 9. Performing Organization Name and Address 10. Project/Task/Work Unit No. Humphrey School of Public Affairs CTS Project # 2012006 University of Minnesota 11. Contract (C) or Grant (G) No. th 301 19 Avenue South (C) 99008 (WO) 8 Minneapolis, MN 55455 12. Sponsoring Organization Name and Address 13. Type of Report and Period Covered Minnesota Department of Transportation Final Report Research Services 14. Sponsoring Agency Code 395 John Ireland Boulevard, MS 330 St. Paul, MN 55155 15. Supplementary Notes http://www.lrrb.org/pdf/201324.pdf 16. Abstract (Limit: 250 words) The purpose of this project was to develop methodologies for monitoring non-motorized traffic in Minnesota. The project included an inventory of bicycle and pedestrian monitoring programs; development of guidance for manual, field counts; pilot field counts in 43 Minnesota communities; and analyses of automated, continuous-motorized counts from locations in Minneapolis. -

Annual Use Estimate of the Metropolitan Regional Parks System for 2008
This document is made available electronically by the Minnesota Legislative Reference Library as part of an ongoing digital archiving project. http://www.leg.state.mn.us/lrl/lrl.asp Annual Use Estimate of the Metropolitan Regional Parks System for 2008 Based on a four-year average of visitation data from 2005 through 2008 June 2009 390 North Robert Street, St. Paul, Minnesota Metropolitan Council Members Peter Bell Chair Roger Scherer District 1 Natalie Haas Steffen District 9 Tony Pistilli District 2 Kris Sanda District 10 Robert McFarlin District 3 Georgeanne Hilker District 11 Craig Peterson District 4 Sherry Broecker District 12 Polly Bowles District 5 Richard Aguilar District 13 Peggy Leppik District 6 Kirstin Sersland Beach District 14 Annette Meeks District 7 Daniel Wolter District 15 Lynette Wittsack District 8 Wendy Wulff District 16 The mission of the Metropolitan Council is to develop, in cooperation with local communities, a comprehensive regional planning framework, focusing on transportation, wastewater, parks and aviation systems that guide the efficient growth of the metropolitan area. The Council operates transit and wastewater services and administers housing and other grant programs. General phone 651-602-1000 Regional Data Center 651-602-1140 TTY 651-291-0904 Metro Info Line 651-602-1888 E-mail [email protected] Council Web site www.metrocouncil.org On request, this publication will be made available in alternative formats to people with disabilities. Please call the Metropolitan Council Data Center at 651-602-1140 or TTY 651-291- 0904. Printed on recycled paper with a minimum of 20% post-consumer waste. -
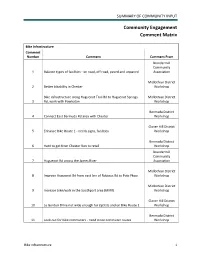
Community Engagement Comment Matrix
SUMMARY OF COMMUNITY INPUT Community Engagement Comment Matrix Bike Infrastructure Comment Number Comment Comment From Brandermill Community 1 Balance types of facilities - on road, off road, paved and unpaved Association Midlothian District 2 Better bikability in Chester Workshop Bike infrastructure along Huguenot Trail Rd to Huguenot Springs Midlothian District 3 Rd, work with Powhatan Workshop Bermuda District 4 Connect East Bermuda Rd area with Chester Workshop Clover Hill District 5 Enhance Bike Route 1 - needs signs, facilities Workshop Bermuda District 6 Hard to get from Chester Run to retail Workshop Brandermill Community 7 Huguenot Rd across the James River Association Midlothian District 8 Improve Huguenot Rd from east line of Robious Rd to Polo Pkwy Workshop Midlothian District 9 Increase bike/walk in the Southport area (MIRR) Workshop Clover Hill District 10 Le Gordon Drive not wide enough for cyclists and on Bike Route 1 Workshop Bermuda District 11 Look out for bike commuters - need more commuter routes Workshop Bike Infrastructure 1 SUMMARY OF COMMUNITY INPUT Brandermill Community 12 Lucks Lane should have bike/walk facilities Association Make bike/pedestrian connections from Midlothian High School to Clover Hill District 13 Ivymont Shopping Center Workshop Need sidewalks/paths (safe places to walk and bike) along Belmont Matoaca District 14 and Turner Roads Workshop (2) Clover Hill District 15 Provide bike options for short trips Workshop Bermuda District 16 Support businesses with bike and pedestrian infrastructure Workshop -

Received from Comment Cards Wish to Commend the Installation of Flasher Lights at the Intersection of Eden Ave
Received from Comment Cards Wish to commend the installation of flasher lights at the intersection of Eden Ave. + 50th St - I walk across there frequently + it has been precarious It should be expected that sidewalks and bikeways be kept up to the same condition as roadways. In the winter sidewalks are icy and not maintained to the same level as the roads. I have slipped and fallen many, many times when using our sidewalks in the winter over the years. If the inner loop (maybe call it a hub?) has more connectivity to the outer loop. Like a bike wheel. with a hub, spokes and rim? I feel fortunate that our City has invested in this great advisory group! Thank you! Making Edina more accessible for biking and walking is a fine idea but keep in mind that the overwhelming majority of trips today and in the future involve cars. Don't hinder our ability to get around the city by lowering the speed limit or adding "traffic calming" features. For example, the 25 mph limit on 70th street is a joke. That street was designed as a major artery for the city. Thanks for listening. Great plan - I'm an avid biker so the more trails, the better! Question: Does the proposed network of bike trails envision kinking up with the bike trails in Minneapolis, St. Louis Park or Hopkins? Creating a connection up to the greenway in Hopkins would be great. I feel we don't need totally "segregated" bike lanes. If cars don't honor the lines now, they'll run over the separators if they're plastic. -

Annual Use Estimate of the Metropolitan Regional Parks System for 2009
This document is made available electronically by the Minnesota Legislative Reference Library as part of an ongoing digital archiving project. http://www.leg.state.mn.us/lrl/lrl.asp Annual Use Estimate of the Metropolitan Regional Parks System for 2009 Based on a four-year average of visitation data from 2006 through 2009 April 2010 390 North Robert Street, St. Paul, Minnesota Metropolitan Council Members Peter Bell Chair Roger Scherer District 1 Natalie Haas Steffen District 9 Tony Pistilli District 2 Kris Sanda District 10 Robert McFarlin District 3 Georgeanne Hilker District 11 Craig Peterson District 4 Sherry Broecker District 12 Polly Bowles District 5 Richard Aguilar District 13 Peggy Leppik District 6 Kirstin Sersland Beach District 14 Annette Meeks District 7 Daniel Wolter District 15 Lynette Wittsack District 8 Wendy Wulff District 16 The mission of the Metropolitan Council is to develop, in cooperation with local communities, a comprehensive regional planning framework, focusing on transportation, wastewater, parks and aviation systems that guide the efficient growth of the metropolitan area. The Council operates transit and wastewater services and administers housing and other grant programs. General phone 651-602-1000 Regional Data Center 651-602-1140 TTY 651-291-0904 Metro Info Line 651-602-1888 E-mail [email protected] Council Web site www.metrocouncil.org On request, this publication will be made available in alternative formats to people with disabilities. Please call the Metropolitan Council Data Center at 651-602-1140 or TTY 651-291- 0904. Printed on recycled paper with a minimum of 20% post-consumer waste.