AI on the Edge: Don't Forget the Memories
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chapter 3 Semiconductor Memories
Chapter 3 Semiconductor Memories Jin-Fu Li Department of Electrical Engineering National Central University Jungli, Taiwan Outline Introduction Random Access Memories Content Addressable Memories Read Only Memories Flash Memories Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 2 Overview of Memory Types Semiconductor Memories Read/Write Memory or Random Access Memory (RAM) Read Only Memory (ROM) Random Access Non-Random Access Memory (RAM) Memory (RAM) •Mask (Fuse) ROM •Programmable ROM (PROM) •Erasable PROM (EPROM) •Static RAM (SRAM) •FIFO/LIFO •Electrically EPROM (EEPROM) •Dynamic RAM (DRAM) •Shift Register •Flash Memory •Register File •Content Addressable •Ferroelectric RAM (FRAM) Memory (CAM) •Magnetic RAM (MRAM) Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 3 Memory Elements – Memory Architecture Memory elements may be divided into the following categories Random access memory Serial access memory Content addressable memory Memory architecture 2m+k bits row decoder row decoder 2n-k words row decoder row decoder column decoder k column mux, n-bit address sense amp, 2m-bit data I/Os write buffers Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 4 1-D Memory Architecture S0 S0 Word0 Word0 S1 S1 Word1 Word1 S2 S2 Word2 Word2 A0 S3 S3 A1 Decoder Ak-1 Sn-2 Storage Sn-2 Wordn-2 element Wordn-2 Sn-1 Sn-1 Wordn-1 Wordn-1 m-bit m-bit Input/Output Input/Output n select signals are reduced n select signals: S0-Sn-1 to k address signals: A0-Ak-1 Advanced Reliable Systems (ARES) Lab. Jin-Fu Li, EE, NCU 5 Memory Architecture S0 Word0 Wordi-1 S1 A0 A1 Ak-1 Row Decoder Sn-1 Wordni-1 A 0 Column Decoder Aj-1 Sense Amplifier Read/Write Circuit m-bit Input/Output Advanced Reliable Systems (ARES) Lab. -
Section 10 Flash Technology
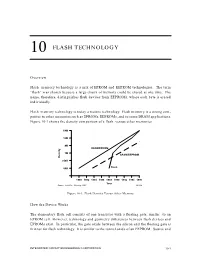
10 FLASH TECHNOLOGY Overview Flash memory technology is a mix of EPROM and EEPROM technologies. The term “flash” was chosen because a large chunk of memory could be erased at one time. The name, therefore, distinguishes flash devices from EEPROMs, where each byte is erased individually. Flash memory technology is today a mature technology. Flash memory is a strong com- petitor to other memories such as EPROMs, EEPROMs, and to some DRAM applications. Figure 10-1 shows the density comparison of a flash versus other memories. 64M 16M 4M DRAM/EPROM 1M SRAM/EEPROM Density 256K Flash 64K 1980 1982 1984 1986 1988 1990 1992 1994 1996 Year Source: Intel/ICE, "Memory 1996" 18613A Figure 10-1. Flash Density Versus Other Memory How the Device Works The elementary flash cell consists of one transistor with a floating gate, similar to an EPROM cell. However, technology and geometry differences between flash devices and EPROMs exist. In particular, the gate oxide between the silicon and the floating gate is thinner for flash technology. It is similar to the tunnel oxide of an EEPROM. Source and INTEGRATED CIRCUIT ENGINEERING CORPORATION 10-1 Flash Technology drain diffusions are also different. Figure 10-2 shows a comparison between a flash cell and an EPROM cell with the same technology complexity. Due to thinner gate oxide, the flash device will be more difficult to process. CMOS Flash Cell CMOS EPROM Cell Mag. 10,000x Mag. 10,000x Flash Memory Cell – Larger transistor – Thinner floating gate – Thinner oxide (100-200Å) Photos by ICE 17561A Figure 10-2. -

Storage Systems and Technologies - Jai Menon and Clodoaldo Barrera
INFORMATION TECHNOLOGY AND COMMUNICATIONS RESOURCES FOR SUSTAINABLE DEVELOPMENT - Storage Systems and Technologies - Jai Menon and Clodoaldo Barrera STORAGE SYSTEMS AND TECHNOLOGIES Jai Menon IBM Academy of Technology, San Jose, CA, USA Clodoaldo Barrera IBM Systems Group, San Jose, CA, USA Keywords: Storage Systems, Hard disk drives, Tape Drives, Optical Drives, RAID, Storage Area Networks, Backup, Archive, Network Attached Storage, Copy Services, Disk Caching, Fiber Channel, Storage Switch, Storage Controllers, Disk subsystems, Information Lifecycle Management, NFS, CIFS, Storage Class Memories, Phase Change Memory, Flash Memory, SCSI, Caching, Non-Volatile Memory, Remote Copy, Storage Virtualization, Data De-duplication, File Systems, Archival Storage, Storage Software, Holographic Storage, Storage Class Memory, Long-Term data preservation Contents 1. Introduction 2. Storage devices 2.1. Storage Device Industry Overview 2.2. Hard Disk Drives 2.3. Digital Tape Drives 2.4. Optical Storage 2.5. Emerging Storage Technologies 2.5.1. Holographic Storage 2.5.2. Flash Storage 2.5.3. Storage Class Memories 3. Block Storage Systems 3.1. Storage System Functions – Current 3.2. Storage System Functions - Emerging 4. File and Archive Storage Systems 4.1. Network Attached Storage 4.2. Archive Storage Systems 5. Storage Networks 5.1. SAN Fabrics 5.2. IP FabricsUNESCO – EOLSS 5.3. Converged Networking 6. Storage SoftwareSAMPLE CHAPTERS 6.1. Data Backup 6.2. Data Archive 6.3. Information Lifecycle Management 6.4. Disaster Protection 7. Concluding Remarks Acknowledgements Glossary Bibliography Biographical Sketches ©Encyclopedia of Life Support Systems (EOLSS) INFORMATION TECHNOLOGY AND COMMUNICATIONS RESOURCES FOR SUSTAINABLE DEVELOPMENT - Storage Systems and Technologies - Jai Menon and Clodoaldo Barrera Summary Our world is increasingly becoming a data-centric world. -

Nanotechnology ? Nram (Nano Random Access
International Journal Of Engineering Research and Technology (IJERT) IFET-2014 Conference Proceedings INTERFACE ECE T14 INTRACT – INNOVATE - INSPIRE NANOTECHNOLOGY – NRAM (NANO RANDOM ACCESS MEMORY) RANJITHA. T, SANDHYA. R GOVERNMENT COLLEGE OF TECHNOLOGY, COIMBATORE 13. containing elements, nanotubes, are so small, NRAM technology will Abstract— NRAM (Nano Random Access Memory), is one of achieve very high memory densities: at least 10-100 times our current the important applications of nanotechnology. This paper has best. NRAM will operate electromechanically rather than just been prepared to cull out answers for the following crucial electrically, setting it apart from other memory technologies as a questions: nonvolatile form of memory, meaning data will be retained even What is NRAM? when the power is turned off. The creators of the technology claim it What is the need of it? has the advantages of all the best memory technologies with none of How can it be made possible? the disadvantages, setting it up to be the universal medium for What is the principle and technology involved in NRAM? memory in the future. What are the advantages and features of NRAM? The world is longing for all the things it can use within its TECHNOLOGY palm. As a result nanotechnology is taking its head in the world. Nantero's technology is based on a well-known effect in carbon Much of the electronic gadgets are reduced in size and increased nanotubes where crossed nanotubes on a flat surface can either be in efficiency by the nanotechnology. The memory storage devices touching or slightly separated in the vertical direction (normal to the are somewhat large in size due to the materials used for their substrate) due to Van der Waal's interactions. -

Use External Storage Devices Like Pen Drives, Cds, and Dvds
External Intel® Learn Easy Steps Activity Card Storage Devices Using external storage devices like Pen Drives, CDs, and DVDs loading Videos Since the advent of computers, there has been a need to transfer data between devices and/or store them permanently. You may want to look at a file that you have created or an image that you have taken today one year later. For this it has to be stored somewhere securely. Similarly, you may want to give a document you have created or a digital picture you have taken to someone you know. There are many ways of doing this – online and offline. While online data transfer or storage requires the use of Internet, offline storage can be managed with minimum resources. The only requirement in this case would be a storage device. Earlier data storage devices used to mainly be Floppy drives which had a small storage space. However, with the development of computer technology, we today have pen drives, CD/DVD devices and other removable media to store and transfer data. With these, you store/save/copy files and folders containing data, pictures, videos, audio, etc. from your computer and even transfer them to another computer. They are called secondary storage devices. To access the data stored in these devices, you have to attach them to a computer and access the stored data. Some of the examples of external storage devices are- Pen drives, CDs, and DVDs. Introduction to Pen Drive/CD/DVD A pen drive is a small self-powered drive that connects to a computer directly through a USB port. -

MSP430 Flash Memory Characteristics (Rev. B)
Application Report SLAA334B–September 2006–Revised August 2018 MSP430 Flash Memory Characteristics ........................................................................................................................ MSP430 Applications ABSTRACT Flash memory is a widely used, reliable, and flexible nonvolatile memory to store software code and data in a microcontroller. Failing to handle the flash according to data-sheet specifications can result in unreliable operation of the application. This application report explains the physics behind these specifications and also gives recommendations for the correct management of flash memory on MSP430™ microcontrollers (MCUs). All examples are based on the flash memory used in the MSP430F1xx, MSP430F2xx, and MSP430F4xx microcontroller families. Contents 1 Flash Memory ................................................................................................................ 2 2 Simplified Flash Memory Cell .............................................................................................. 2 3 Flash Memory Parameters ................................................................................................. 3 3.1 Data Retention ...................................................................................................... 3 3.2 Flash Endurance.................................................................................................... 5 3.3 Cumulative Program Time......................................................................................... 5 4 -

Uebayasi's Simple Template
eXecute In Place support in NetBSD Masao “uebs” Uebayashi <[email protected]> BSDCan 2010 2010.5.13 Who am I NetBSD developer Japanese Living in Yokohama Self-employed Since Dec. 15 2008 Tombi Inc. Agenda Demonstration Introduction Program execution VM Virtual memory management Physical memory management Fault handler, pager : Design of XIP Demonstration XIP on NetBSD/arm (i.MX35) Introduction What is XIP? Execute programs directly from devices No memory copy Only about userland programs (Kernel XIP is another story) Introduction Who needs XIP? Embedded devices Memory saving for less power consumption Boot time Mainframes (Linux) Memory saving for virtualized instances : “Nothing in between” Introduction How to achieve XIP? Don't copy programs to memory when executing it “Execute” == mmap() : : : : : What does that *actually* mean? Goals No hacks Keep code cleanliness Keep abstraction Including device handling : : Performance Latency Memory efficiency Program execution execve(2) → sys_execve() Prepare Read program header using I/O Map sections Set program entry point Execute Page fault is triggered Load pages using VM Execution is resumed Program execution I/O part needs no changes If block device interface (d_strategy()) is provided VM part needs changes!!! Virtual memory management http://en.wikipedia.org/wiki/Virtual_memory Virtual memory is a computer system technique which gives an application program the impression that it has contiguous working memory (an address space), while in fact it may be physically fragmented and may even overflow on to disk storage. Developed for multitasking kernels, virtual memory provides two primary functions: Each process has its own address space, thereby not required to be relocated nor required to use relative addressing mode. -

NOVA: a Log-Structured File System for Hybrid Volatile/Non
NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories Jian Xu and Steven Swanson, University of California, San Diego https://www.usenix.org/conference/fast16/technical-sessions/presentation/xu This paper is included in the Proceedings of the 14th USENIX Conference on File and Storage Technologies (FAST ’16). February 22–25, 2016 • Santa Clara, CA, USA ISBN 978-1-931971-28-7 Open access to the Proceedings of the 14th USENIX Conference on File and Storage Technologies is sponsored by USENIX NOVA: A Log-structured File System for Hybrid Volatile/Non-volatile Main Memories Jian Xu Steven Swanson University of California, San Diego Abstract Hybrid DRAM/NVMM storage systems present a host of opportunities and challenges for system designers. These sys- Fast non-volatile memories (NVMs) will soon appear on tems need to minimize software overhead if they are to fully the processor memory bus alongside DRAM. The result- exploit NVMM’s high performance and efficiently support ing hybrid memory systems will provide software with sub- more flexible access patterns, and at the same time they must microsecond, high-bandwidth access to persistent data, but provide the strong consistency guarantees that applications managing, accessing, and maintaining consistency for data require and respect the limitations of emerging memories stored in NVM raises a host of challenges. Existing file sys- (e.g., limited program cycles). tems built for spinning or solid-state disks introduce software Conventional file systems are not suitable for hybrid mem- overheads that would obscure the performance that NVMs ory systems because they are built for the performance char- should provide, but proposed file systems for NVMs either in- acteristics of disks (spinning or solid state) and rely on disks’ cur similar overheads or fail to provide the strong consistency consistency guarantees (e.g., that sector updates are atomic) guarantees that applications require. -

Control Design and Implementation of Hard Disk Drive Servos by Jianbin
Control Design and Implementation of Hard Disk Drive Servos by Jianbin Nie A dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Engineering-Mechanical Engineering in the Graduate Division of the University of California, Berkeley Committee in charge: Professor Roberto Horowitz, Chair Professor Masayoshi Tomizuka Professor David Brillinger Spring 2011 Control Design and Implementation of Hard Disk Drive Servos ⃝c 2011 by Jianbin Nie 1 Abstract Control Design and Implementation of Hard Disk Drive Servos by Jianbin Nie Doctor of Philosophy in Engineering-Mechanical Engineering University of California, Berkeley Professor Roberto Horowitz, Chair In this dissertation, the design of servo control algorithms is investigated to produce high-density and cost-effective hard disk drives (HDDs). In order to sustain the continuing increase of HDD data storage density, dual-stage actuator servo systems using a secondary micro-actuator have been developed to improve the precision of read/write head positioning control by increasing their servo bandwidth. In this dissertation, the modeling and control design of dual-stage track-following servos are considered. Specifically, two track-following control algorithms for dual-stage HDDs are developed. The designed controllers were implemented and evaluated on a disk drive with a PZT-actuated suspension-based dual-stage servo system. Usually, the feedback position error signal (PES) in HDDs is sampled on some spec- ified servo sectors with an equidistant sampling interval, which implies that HDD servo systems with a regular sampling rate can be modeled as linear time-invariant (LTI) systems. However, sampling intervals for HDD servo systems are not always equidistant and, sometimes, an irregular sampling rate due to missing PES sampling data is unavoidable. -

The Rise of the Flash Memory Market: Its Impact on Firm
The Rise of the Flash Web version: Memory Market: Its Impact July 2007 on Firm Behavior and Author: Global Semiconductor Falan Yinug1 Trade Patterns Abstract This article addresses three questions about the flash memory market. First, will the growth of the flash memory market be a short- or long-term phenomenon? Second, will the growth of the flash memory market prompt changes in firm behavior and industry structure? Third, what are the implications for global semiconductor trade patterns of flash memory market growth? The analysis concludes that flash memory market growth is a long-term phenomenon to which producers have responded in four distinct ways. It also concludes that the rise in flash memory demand has intensified current semiconductor trade patterns but has not shifted them fundamentally. 1 Falan Yinug ([email protected]) is a International Trade Analyst from the Office of Industries. His words are strictly his own and do not represent the opinions of the US International Trade Commission or of any of its Commissioners. 1 Introduction The past few years have witnessed rapid growth in a particular segment of the 2 semiconductor market known as flash memory. In each of the past five years, for example, flash memory market growth has either outpaced or equaled that 3 of the total integrated circuit (IC) market (McClean et al 2004-2007, section 5). One observer expects flash memory to have the third-strongest market growth rate over the next six years among all IC product categories (McClean et al 2007, 5-6). As a result, the flash memory share of the total IC market has increased from 5.5 percent in 2002, to 8.1 percent in 2005. -

Container-Based Virtualization for Byte-Addressable NVM Data Storage
2016 IEEE International Conference on Big Data (Big Data) Container-Based Virtualization for Byte-Addressable NVM Data Storage Ellis R. Giles Rice University Houston, Texas [email protected] Abstract—Container based virtualization is rapidly growing Storage Class Memory, or SCM, is an exciting new in popularity for cloud deployments and applications as a memory technology with the potential of replacing hard virtualization alternative due to the ease of deployment cou- drives and SSDs as it offers high-speed, byte-addressable pled with high-performance. Emerging byte-addressable, non- volatile memories, commonly called Storage Class Memory or persistence on the main memory bus. Several technologies SCM, technologies are promising both byte-addressability and are currently under research and development, each with dif- persistence near DRAM speeds operating on the main memory ferent performance, durability, and capacity characteristics. bus. These new memory alternatives open up a new realm of These include a ReRAM by Micron and Sony, a slower, but applications that no longer have to rely on slow, block-based very large capacity Phase Change Memory or PCM by Mi- persistence, but can rather operate directly on persistent data using ordinary loads and stores through the cache hierarchy cron and others, and a fast, smaller spin-torque ST-MRAM coupled with transaction techniques. by Everspin. High-speed, byte-addressable persistence will However, SCM presents a new challenge for container-based give rise to new applications that no longer have to rely on applications, which typically access persistent data through slow, block based storage devices and to serialize data for layers of block based file isolation. -

Manufacturing Equipment Technologies for Hard Disk's
Manufacturing Equipment Technologies for Hard Disk’s Challenge of Physical Limits 222 Manufacturing Equipment Technologies for Hard Disk’s Challenge of Physical Limits Kyoichi Mori OVERVIEW: To meet the world’s growing demands for volume information, Brian Rattray not just with computers but digitalization and video etc. the HDD must Yuichi Matsui, Dr. Eng. continually increase its capacity and meet expectations for reduced power consumption and green IT. Up until now the HDD has undergone many innovative technological developments to achieve higher recording densities. To continue this increase, innovative new technology is again required and is currently being developed at a brisk pace. The key components for areal density improvements, the disk and head, require high levels of performance and reliability from production and inspection equipment for efficient manufacturing and stable quality assurance. To meet this demand, high frequency electronics, servo positioning and optical inspection technology is being developed and equipment provided. Hitachi High-Technologies Corporation is doing its part to meet market needs for increased production and the adoption of next-generation technology by developing the technology and providing disk and head manufacturing/inspection equipment (see Fig. 1). INTRODUCTION higher efficiency storage, namely higher density HDDS (hard disk drives) have long relied on the HDDs will play a major role. computer market for growth but in recent years To increase density, the performance and quality of there has been a shift towards cloud computing and the HDD’s key components, disks (media) and heads consumer electronics etc. along with a rapid expansion have most effect. Therefore further technological of data storage applications (see Fig.