Prestructuring Multilayer Perceptrons Based on Information-Theoretic
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Statistical Fallacy: a Menace to the Field of Science
International Journal of Scientific and Research Publications, Volume 9, Issue 6, June 2019 297 ISSN 2250-3153 Statistical Fallacy: A Menace to the Field of Science Kalu Emmanuel Ogbonnaya*, Benard Chibuike Okechi**, Benedict Chimezie Nwankwo*** * Department of Ind. Maths and Applied Statistics, Ebonyi State University, Abakaliki ** Department of Psychology, University of Nigeria, Nsukka. *** Department of Psychology and Sociological Studies, Ebonyi State University, Abakaliki DOI: 10.29322/IJSRP.9.06.2019.p9048 http://dx.doi.org/10.29322/IJSRP.9.06.2019.p9048 Abstract- Statistical fallacy has been a menace in the field of easier to understand but when used in a fallacious approach can sciences. This is mostly contributed by the misconception of trick the casual observer into believing something other than analysts and thereby led to the distrust in statistics. This research what the data shows. In some cases, statistical fallacy may be investigated the conception of students from selected accidental or unintentional. In others, it is purposeful and for the departments on statistical concepts as it relates statistical fallacy. benefits of the analyst. Students in Statistics, Economics, Psychology, and The fallacies committed intentionally refer to abuse of Banking/Finance department were randomly sampled with a statistics and the fallacy committed unintentionally refers to sample size of 36, 43, 41 and 38 respectively. A Statistical test misuse of statistics. A misuse occurs when the data or the results was conducted to obtain their conception score about statistical of analysis are unintentionally misinterpreted due to lack of concepts. A null hypothesis which states that there will be no comprehension. The fault cannot be ascribed to statistics; it lies significant difference between the students’ conception of with the user (Indrayan, 2007). -

Informal Fallacies 2
Ashford University - Ed Tech | Informal_Fallacies_2 JUSTIN Hi, everybody. This is going to be a continuation of the informal logical fallacy HARRISON: discussion. The next one we're going to be talking about is the relativist fallacy. This is a common one that you see. Even in intellectual circles, you see really smart people falling into this fallacy. Well, I guess you can be consistent, but it's very hard to be consistent. The relativist fallacy occurs when you say that, for example, different cultures have different beliefs so what's right in one culture or what's right for one group is right and good. And then something that's opposite in another group is considered right and good. And those two things are right and good for both cultures or groups or whatever it might be. Well, there are different types of relativism, but cultural relativism would say things like, well, we can't judge other cultures because their actions are right based on their own definitions of what is right. And our definitions of what is right and wrong are different. Therefore, what they believe is right is right and what we believe is right is right. And hopefully you can see the problem with this is that-- let's say that we're confronting a culture that subjugates women. And in that culture, it is right or morally acceptable to gang rape a woman, which is actually-- this happens in the world-- when she's been accused of some crime-- often a crime that she didn't commit, but she's just been accused of it. -

Misuse of Statistics in Surgical Literature
Statistics Corner Misuse of statistics in surgical literature Matthew S. Thiese1, Brenden Ronna1, Riann B. Robbins2 1Rocky Mountain Center for Occupational & Environment Health, Department of Family and Preventive Medicine, 2Department of Surgery, School of Medicine, University of Utah, Salt Lake City, Utah, USA Correspondence to: Matthew S. Thiese, PhD, MSPH. Rocky Mountain Center for Occupational & Environment Health, Department of Family and Preventive Medicine, School of Medicine, University of Utah, 391 Chipeta Way, Suite C, Salt Lake City, UT 84108, USA. Email: [email protected]. Abstract: Statistical analyses are a key part of biomedical research. Traditionally surgical research has relied upon a few statistical methods for evaluation and interpretation of data to improve clinical practice. As research methods have increased in both rigor and complexity, statistical analyses and interpretation have fallen behind. Some evidence suggests that surgical research studies are being designed and analyzed improperly given the specific study question. The goal of this article is to discuss the complexities of surgical research analyses and interpretation, and provide some resources to aid in these processes. Keywords: Statistical analysis; bias; error; study design Submitted May 03, 2016. Accepted for publication May 19, 2016. doi: 10.21037/jtd.2016.06.46 View this article at: http://dx.doi.org/10.21037/jtd.2016.06.46 Introduction the most commonly used statistical tests of the time (6,7). Statistical methods have since become more complex Research in surgical literature is essential for furthering with a variety of tests and sub-analyses that can be used to knowledge, understanding new clinical questions, as well as interpret, understand and analyze data. -

United Nations Fundamental Principles of Official Statistics
UNITED NATIONS United Nations Fundamental Principles of Official Statistics Implementation Guidelines United Nations Fundamental Principles of Official Statistics Implementation guidelines (Final draft, subject to editing) (January 2015) Table of contents Foreword 3 Introduction 4 PART I: Implementation guidelines for the Fundamental Principles 8 RELEVANCE, IMPARTIALITY AND EQUAL ACCESS 9 PROFESSIONAL STANDARDS, SCIENTIFIC PRINCIPLES, AND PROFESSIONAL ETHICS 22 ACCOUNTABILITY AND TRANSPARENCY 31 PREVENTION OF MISUSE 38 SOURCES OF OFFICIAL STATISTICS 43 CONFIDENTIALITY 51 LEGISLATION 62 NATIONAL COORDINATION 68 USE OF INTERNATIONAL STANDARDS 80 INTERNATIONAL COOPERATION 91 ANNEX 98 Part II: Implementation guidelines on how to ensure independence 99 HOW TO ENSURE INDEPENDENCE 100 UN Fundamental Principles of Official Statistics – Implementation guidelines, 2015 2 Foreword The Fundamental Principles of Official Statistics (FPOS) are a pillar of the Global Statistical System. By enshrining our profound conviction and commitment that offi- cial statistics have to adhere to well-defined professional and scientific standards, they define us as a professional community, reaching across political, economic and cultural borders. They have stood the test of time and remain as relevant today as they were when they were first adopted over twenty years ago. In an appropriate recognition of their significance for all societies, who aspire to shape their own fates in an informed manner, the Fundamental Principles of Official Statistics were adopted on 29 January 2014 at the highest political level as a General Assembly resolution (A/RES/68/261). This is, for us, a moment of great pride, but also of great responsibility and opportunity. In order for the Principles to be more than just a statement of noble intentions, we need to renew our efforts, individually and collectively, to make them the basis of our day-to-day statistical work. -

Mocidade.Pdf
TRABALHO DE CONCLUSÃO DE CURSO PROFESSOR ORIENTADOR: MARCELO GUEDES ALUNOS: DANIELA PADUA, MARIANA BIASIOLI, PAULO HENRIQUE OLIVEIRA. Índice Analítico Agradecimentos ___________________________________________________________________________ 9 Resumo executivo ________________________________________________________________________ 11 Breve descrição da escola __________________________________________________________________ 11 Identificação do problema e a proposta estratégica _______________________________________________ 11 Introdução 14 I. ANÁLISE EXTERNA ______________________________________________ 18 I.1.1. Mercado ______________________________________________________________________ 19 I.1.1.1. Histórico ______________________________________________________________________ 19 I.1.1.1.1. As raízes do termo ______________________________________________________________ 19 I.1.1.1.2. Conceito e origem _______________________________________________________________ 19 I.1.1.1.3. Período de duração _______________________________________________________________ 20 I.1.1.1.4. Carnaval no Brasil _______________________________________________________________ 20 I.1.1.1.5. Bailes de carnaval ________________________________________________________________ 21 I.1.1.1.6. Escolas de samba ________________________________________________________________ 21 I.1.2. Tamanho do mercado ____________________________________________________________ 23 I.1.3. Sazonalidade ___________________________________________________________________ 25 -

The Numbers Game - the Use and Misuse of Statistics in Civil Rights Litigation
Volume 23 Issue 1 Article 2 1977 The Numbers Game - The Use and Misuse of Statistics in Civil Rights Litigation Marcy M. Hallock Follow this and additional works at: https://digitalcommons.law.villanova.edu/vlr Part of the Civil Procedure Commons, Civil Rights and Discrimination Commons, Evidence Commons, and the Labor and Employment Law Commons Recommended Citation Marcy M. Hallock, The Numbers Game - The Use and Misuse of Statistics in Civil Rights Litigation, 23 Vill. L. Rev. 5 (1977). Available at: https://digitalcommons.law.villanova.edu/vlr/vol23/iss1/2 This Article is brought to you for free and open access by Villanova University Charles Widger School of Law Digital Repository. It has been accepted for inclusion in Villanova Law Review by an authorized editor of Villanova University Charles Widger School of Law Digital Repository. Hallock: The Numbers Game - The Use and Misuse of Statistics in Civil Righ 1977-19781 THE NUMBERS GAME - THE USE AND MISUSE OF STATISTICS IN CIVIL RIGHTS LITIGATION MARCY M. HALLOCKt I. INTRODUCTION "In the problem of racial discrimination, statistics often tell much, and Courts listen."' "We believe it evident that if the statistics in the instant matter represent less than a shout, they certainly constitute '2 far more than a mere whisper." T HE PARTIES TO ACTIONS BROUGHT UNDER THE CIVIL RIGHTS LAWS3 have relied increasingly upon statistical 4 analyses to establish or rebut cases of unlawful discrimination. Although statistical evidence has been considered significant in actions brought to redress racial discrimination in jury selection,5 it has been used most frequently in cases of allegedly discriminatory t B.A., University of Pennsylvania, 1972; J.D., Georgetown University Law Center, 1975. -

Summer 2002 PROFILES in FAITH in THIS ISSUE 1 Profiles in Faith: John Calvin (1509–1564) John Calvin by Art Lindsley by Dr
KKNOWINGNOWING A Teaching Quarterly for Discipleship of Heart and Mind C.S. LEWIS INSTITUTE OINGOING &D&D Summer 2002 PROFILES IN FAITH IN THIS ISSUE 1 Profiles in Faith: John Calvin (1509–1564) John Calvin by Art Lindsley by Dr. Art Lindsley Scholar-in-Residence 3 C.S. Lewis Feature Article: C.S. Lewis on Freud and Marx by Art Lindsley 6 A Conversation with: Ravi Zacharias 8 Review & Reflect: Two Giants and the he mere mention of John Calvin’s maintains, “Calvin is the man who, next to St. Giant Question: a name (born July 10, 1509 in Noyon, Paul, has done the most good to mankind.” review of Dr. France – died May 27, Charles Haddon Spurgeon, En- Armand Nicholi’s T book The Ques- 1564 in Geneva, Switzerland) glish preacher, asserts, “The T tion of God produces strong reactions both longer I live the clearer does it ap- by James Beavers pro and con. Erich Fromm, 20th “Taking into pear that John Calvin’s system is century German-born American the nearest to perfection.” 12 Special Feature psychoanalyst and social phi- account all his Basil Hall, Cambridge profes- Article: losopher, says that Calvin “be- sor, once wrote an essay, “The Conversational longed to the ranks of the failings, he Calvin Legend,” in which he ar- Apologetics greatest haters in history.” The gues that formerly those who by Michael must be Ramsden Oxford Dictionary of the Christian depreciated Calvin had at least Church maintains that Calvin reckoned as one read his works, whereas now 24 Upcoming Events was “cruel” and the “unopposed the word “Calvin” or “Calvin- dictator of Geneva.” On the other of the greatest ism” is used as a word with hand, Theodore Beza, Calvin’s negative connotations but with successor, says of Calvin, “I have and best of men little or no content. -
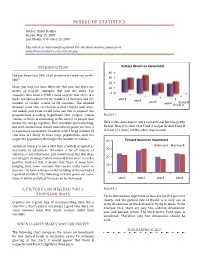
Misuse of Statistics
MISUSE OF STATISTICS Author: Rahul Dodhia Posted: May 25, 2007 Last Modified: October 15, 2007 This article is continuously updated. For the latest version, please go to www.RavenAnalytics.com/articles.php INTRODUCTION Percent Return on Investment 40 Did you know that 54% of all statistics are made up on the 30 spot? 20 Okay, you may not have fallen for that one, but there are 10 plenty of real-life examples that bait the mind. For 0 example, data from a 1988 census suggest that there is a high correlation between the number of churches and the year1 year2 number of violent crimes in US counties. The implied year3 Group B year4 Group A message from this correlation is that religion and crime are linked, and some would even use this to support the preposterous sounding hypothesis that religion causes FIGURE 1 crimes, or there is something in the nature of people that makes the two go together. That would be quite shocking, Here is the same data in more conventional but less pretty but alert statisticians would immediately point out that it format. Now it is clear that Fund A outperformed Fund B is a spurious correlation. Counties with a large number of in 3 out of 4 years, not the other way around. churches are likely to have large populations. And the larger the population, the larger the number of crimes.1 40 Percent Return on Investment Statistical literacy is not a skill that is widely accepted as Group A Group B necessary in education. Therefore a lot of misuse of 30 statistics is not intentional, just uninformed. -

Quantifying Aristotle's Fallacies
mathematics Article Quantifying Aristotle’s Fallacies Evangelos Athanassopoulos 1,* and Michael Gr. Voskoglou 2 1 Independent Researcher, Giannakopoulou 39, 27300 Gastouni, Greece 2 Department of Applied Mathematics, Graduate Technological Educational Institute of Western Greece, 22334 Patras, Greece; [email protected] or [email protected] * Correspondence: [email protected] Received: 20 July 2020; Accepted: 18 August 2020; Published: 21 August 2020 Abstract: Fallacies are logically false statements which are often considered to be true. In the “Sophistical Refutations”, the last of his six works on Logic, Aristotle identified the first thirteen of today’s many known fallacies and divided them into linguistic and non-linguistic ones. A serious problem with fallacies is that, due to their bivalent texture, they can under certain conditions disorient the nonexpert. It is, therefore, very useful to quantify each fallacy by determining the “gravity” of its consequences. This is the target of the present work, where for historical and practical reasons—the fallacies are too many to deal with all of them—our attention is restricted to Aristotle’s fallacies only. However, the tools (Probability, Statistics and Fuzzy Logic) and the methods that we use for quantifying Aristotle’s fallacies could be also used for quantifying any other fallacy, which gives the required generality to our study. Keywords: logical fallacies; Aristotle’s fallacies; probability; statistical literacy; critical thinking; fuzzy logic (FL) 1. Introduction Fallacies are logically false statements that are often considered to be true. The first fallacies appeared in the literature simultaneously with the generation of Aristotle’s bivalent Logic. In the “Sophistical Refutations” (Sophistici Elenchi), the last chapter of the collection of his six works on logic—which was named by his followers, the Peripatetics, as “Organon” (Instrument)—the great ancient Greek philosopher identified thirteen fallacies and divided them in two categories, the linguistic and non-linguistic fallacies [1]. -

Chapa Branca” Na Beija-Flor, O Grande Decênio Na Avenida Em 1975 “White Plate” in Beija-Flor, the Great Decene on the Avenue in 1975
a e ARTIGO 217 Arte & Ensaios Arte e Ensaios vol. 26, n. 40, jul./dez. 2020 “Chapa Branca” na Beija-Flor, o grande decênio na avenida em 1975 “White Plate” in Beija-Flor, the great decene on the avenue in 1975 Carlos Carvalho da Silva* 0000-0002-4426-7511 [email protected] Resumo O artigo tem como objetivo analisar o enredo carnavalesco do G.R.E.S. Beija-Flor de Nilópolis no ano de 1975 intitulado “O grande decênio”, desenvolvido pelo jornalista e professor Manuel Antônio Barroso. Buscamos aproximar, através da materialidade criada com o desdobramento do enredo textual para o enredo visual, com as fantasias carnava- lescas como ferramenta de propagação do ideário militar durante o período do “milagre brasileiro”. Os enredos patrióticos desse período, conhecidos nos dias de hoje como “chapa-branca”, proporcionaram às agremiações alinhadas à ideologia militar o estigma de escola patriótica ou ainda como “unidos da arena”. A escola de samba de Nilópolis carregou esse fardo pesado, mesmo após a contratação do carnavalesco Joãozinho Trinta, com o enredo “Sonhar com rei dá leão”, em 1976, que conquistou o campeonato daquele ano. Sendo assim, o carnavalesco e a agremiação foram, ainda assim, criticados e julgados pelas marcas de um passado não distante: o ano de 1975 – o grande decênio. Palavras-chave * Mestre e doutorando Carnaval; chapa-branca; Beija-Flor; militar; fantasia em Artes Visuais pela Escola de Belas Artes PPGAV/UFRJ. Professor Abstract substituto na EBA/ The article aims to analyze the carnival story of G.R.E.S. Beija-Flor of Nilópolis in the year UFRJ no depto. -

O Segredo É a Alegria 2 ENSAIO GERAL DEVASSA, GENTE BONITA E ANIMAÇÃO NÃO FALTARAM EM 2010, NEM VÃO FALTAR NO CARNAVAL DE 2011
Informativo Ofi cial da LIESA – www.liesa.com.br Ano XVI – Nº 25 RIO CARNAVAL 2011 SAMBA o segredo é a alegria 2 ENSAIO GERAL DEVASSA, GENTE BONITA E ANIMAÇÃO NÃO FALTARAM EM 2010, NEM VÃO FALTAR NO CARNAVAL DE 2011. AGUARDE. ENSAIO GERAL 43 44 ENSAIO GERAL ENSAIO GERAL 3 Informativo Ofi cial da LIESA – www.liesa.com.br Ano XVI – Nº 25 NossaN capa: A Comissão de Frente da Unidos da Tijuca, campeãca de 2010, foi um dos destaques do RIO CARNAVAL 2011 SAMBA desfid le. Foto Henrique Mattos o segredo é a alegria LIGA INDEPENDENTE DAS ESCOLAS DE SAMBA DO RIO DE JANEIRO PRESIDENTE Jorge Luiz Castanheira Alexandre VICE-PRESIDENTE E DIRETOR DE PATRIMÔNIO ÍNDICE Zacarias Siqueira de Oliveira Ranking LIESA 2006-2010 Mensagem do Presidente: DIRETOR FINANCEIRO 5 Parceiros do Sucesso 28 Américo Siqueira Filho DIRETOR SECRETÁRIO Mensagem do Secretário Wagner Tavares de Araújo Especial de Turismo 6 DIRETOR JURÍDICO Está chegando a hora Nelson de Almeida Contrato defi nirá venda DIRETOR COMERCIAL 8 de ingressos Hélio Costa da Motta DIRETOR DE CARNAVAL Os melhores ensaios Elmo José dos Santos 9 da Terra DIRETOR SOCIAL “Forças da Natureza” Jorge Perlingeiro volta em novembro 29 DIRETOR CULTURAL Hiram Araújo ADMINISTRADOR DA CIDADE DO Com a mão na massa SAMBA 30 Ailton Guimarães Jorge Júnior ASSESSOR DE IMPRENSA Onde se aprende a dança Vicente Dattoli 32 do samba CONSELHO SUPERIOR Ailton Guimarães Jorge Cidade do Samba e do Aniz Abrahão David 10 Pagode também! Da Candelária à Luiz Pacheco Drumond 34 Apoteose CONSELHO DELIBERATIVO Como será o desfi le PRESIDENTE Ubiratan T. -

Music 10378 Songs, 32.6 Days, 109.89 GB
Page 1 of 297 Music 10378 songs, 32.6 days, 109.89 GB Name Time Album Artist 1 Ma voie lactée 3:12 À ta merci Fishbach 2 Y crois-tu 3:59 À ta merci Fishbach 3 Éternité 3:01 À ta merci Fishbach 4 Un beau langage 3:45 À ta merci Fishbach 5 Un autre que moi 3:04 À ta merci Fishbach 6 Feu 3:36 À ta merci Fishbach 7 On me dit tu 3:40 À ta merci Fishbach 8 Invisible désintégration de l'univers 3:50 À ta merci Fishbach 9 Le château 3:48 À ta merci Fishbach 10 Mortel 3:57 À ta merci Fishbach 11 Le meilleur de la fête 3:33 À ta merci Fishbach 12 À ta merci 2:48 À ta merci Fishbach 13 ’¡¡ÒàËÇèÒ 3:33 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 14 ’¡¢ÁÔé’ 2:29 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 15 ’¡à¢Ò 1:33 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 16 ¢’ÁàªÕ§ÁÒ 1:36 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 17 à¨éÒ’¡¢Ø’·Í§ 2:07 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 18 ’¡àÍÕé§ 2:23 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 19 ’¡¡ÒàËÇèÒ 4:00 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 20 áÁèËÁéÒ¡ÅèÍÁÅÙ¡ 6:49 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 21 áÁèËÁéÒ¡ÅèÍÁÅÙ¡ 6:23 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 22 ¡ÅèÍÁÅÙ¡â€ÃÒª 1:58 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 23 ¡ÅèÍÁÅÙ¡ÅéÒ’’Ò 2:55 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 24 Ë’èÍäÁé 3:21 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 25 ÅÙ¡’éÍÂã’ÍÙè 3:55 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 26 ’¡¡ÒàËÇèÒ 2:10 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’… 27 ÃÒËÙ≤˨ђ·Ãì 5:24 à≤ŧ¡ÅèÍÁÅÙ¡ªÒÇÊÂÒÁ ʶҺђÇÔ·ÂÒÈÒʵÃì¡ÒÃàÃÕÂ’…