Production and Perception of Local Variants in Liverpool English Change, Salience, Exemplar Priming
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A New Test for Exemplar Theory: Varying Versus Non-Varying General Linguistics Glossa Words in Spanish
a journal of Pycha, Anne. 2017. A new test for exemplar theory: Varying versus non-varying general linguistics Glossa words in Spanish. Glossa: a journal of general linguistics 2(1): 82. 1–31, DOI: https://doi.org/10.5334/gjgl.240 RESEARCH A new test for exemplar theory: Varying versus non-varying words in Spanish Anne Pycha University of Wisconsin, Milwaukee, US [email protected] We used a Deese-Roediger-McDermott false memory paradigm to compare Spanish words in which the phonetic realization of /s/ can vary (word-medial positions: bu[s]to ~ bu[h]to ‘chest’, word-final positions:remo [s] ~ remo[h] ‘oars’) to words in which it cannot (word-initial positions: [s]opa ~ *[h]opa ‘soup’). At study, participants listened to lists of nine words that were phonological neighbors of an unheard critical item (e.g., popa, sepa, soja, etc. for the critical item sopa). At test, participants performed free recall and yes/no recognition tasks. Replicating previous work in this paradigm, results showed robust false memory effects: that is, participants were more likely to (falsely) remember a critical item than a random intrusion. When the realization of /s/ was consistent across conditions (Experiment 1), false memory rates for varying versus non-varying words did not significantly differ. However, when the realization of /s/ varied between [s] and [h] in those positions which allow it (Experiment 2), false recognition rates for varying words like busto were significantly higher than those for non-varying words likesopa . Assuming that higher false memory rates are indicative of greater lexical activation, we interpret these results to support the predictions of exemplar theory, which claims that words with heterogeneous versus homogeneous acoustic realizations should exhibit distinct patterns of activation. -

The Past, Present, and Future of English Dialects: Quantifying Convergence, Divergence, and Dynamic Equilibrium
Language Variation and Change, 22 (2010), 69–104. © Cambridge University Press, 2010 0954-3945/10 $16.00 doi:10.1017/S0954394510000013 The past, present, and future of English dialects: Quantifying convergence, divergence, and dynamic equilibrium WARREN M AGUIRE AND A PRIL M C M AHON University of Edinburgh P AUL H EGGARTY University of Cambridge D AN D EDIU Max-Planck-Institute for Psycholinguistics ABSTRACT This article reports on research which seeks to compare and measure the similarities between phonetic transcriptions in the analysis of relationships between varieties of English. It addresses the question of whether these varieties have been converging, diverging, or maintaining equilibrium as a result of endogenous and exogenous phonetic and phonological changes. We argue that it is only possible to identify such patterns of change by the simultaneous comparison of a wide range of varieties of a language across a data set that has not been specifically selected to highlight those changes that are believed to be important. Our analysis suggests that although there has been an obvious reduction in regional variation with the loss of traditional dialects of English and Scots, there has not been any significant convergence (or divergence) of regional accents of English in recent decades, despite the rapid spread of a number of features such as TH-fronting. THE PAST, PRESENT AND FUTURE OF ENGLISH DIALECTS Trudgill (1990) made a distinction between Traditional and Mainstream dialects of English. Of the Traditional dialects, he stated (p. 5) that: They are most easily found, as far as England is concerned, in the more remote and peripheral rural areas of the country, although some urban areas of northern and western England still have many Traditional Dialect speakers. -

George Harrison
COPYRIGHT 4th Estate An imprint of HarperCollinsPublishers 1 London Bridge Street London SE1 9GF www.4thEstate.co.uk This eBook first published in Great Britain by 4th Estate in 2020 Copyright © Craig Brown 2020 Cover design by Jack Smyth Cover image © Michael Ochs Archives/Handout/Getty Images Craig Brown asserts the moral right to be identified as the author of this work A catalogue record for this book is available from the British Library All rights reserved under International and Pan-American Copyright Conventions. By payment of the required fees, you have been granted the non-exclusive, non-transferable right to access and read the text of this e-book on-screen. No part of this text may be reproduced, transmitted, down-loaded, decompiled, reverse engineered, or stored in or introduced into any information storage and retrieval system, in any form or by any means, whether electronic or mechanical, now known or hereinafter invented, without the express written permission of HarperCollins. Source ISBN: 9780008340001 Ebook Edition © April 2020 ISBN: 9780008340025 Version: 2020-03-11 DEDICATION For Frances, Silas, Tallulah and Tom EPIGRAPHS In five-score summers! All new eyes, New minds, new modes, new fools, new wise; New woes to weep, new joys to prize; With nothing left of me and you In that live century’s vivid view Beyond a pinch of dust or two; A century which, if not sublime, Will show, I doubt not, at its prime, A scope above this blinkered time. From ‘1967’, by Thomas Hardy (written in 1867) ‘What a remarkable fifty years they -

AUSTRALIAN FOOD SLANG Abstract
UNIWERSYTET HUMANISTYCZNO-PRZYRODNICZY IM. JANA DŁUGOSZA W CZĘSTOCHOWIE Studia Neofilologiczne 2020, z. XVI, s. 151–170 http://dx.doi.org/10.16926/sn.2020.16.08 Dana SERDITOVA https://orcid.org/0000-0003-1206-8507 (University of Heidelberg) AUSTRALIAN FOOD SLANG Abstract The article analyzes Australian food slang. The first part of the research deals with the definition and etymology of the word ‘slang’, the purpose of slang and its main characteristics, as well as the history of Australian slang. In the second part, an Australian food slang classification consisting of five categories is provided: -ie/-y/-o and other abbreviations, words that underwent phonetic change, words with new meaning, Australian rhyming slang, and words of Australian origin. The definitions of each word and examples from the corpora and various dictionaries are provided. The paper also dwells on such particular cases as regional varieties of the word ‘sausage’ (including the map of sausages) and drinking slang. Keywords: Australian food slang, Australian English, varieties of English, linguistic and culture studies. Australian slang is a vivid and picturesque part of an extremely fascinating variety of English. Just like Australian English in general, the slang Down Under is influenced by both British and American varieties. Australian slang started as a criminal language, it moved to Australia together with the British convicts. Naturally, the attitude towards slang was negative – those who were not part of the criminal culture tried to exclude slang words from their vocabulary. First and foremost, it had this label of criminality and offense. This attitude only changed after the World War I, when the soldiers created their own slang, parts of which ended up among the general public. -
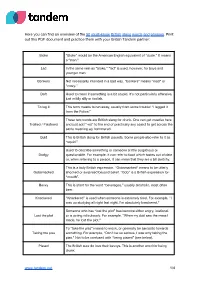
1/4 Here You Can Find an Overview of the 50 Must
Here you can find an overview of the 50 must-know British slang words and phrases. Print out this PDF document and practice them with your British Tandem partner: Bloke “Bloke” would be the American English equivalent of “dude.” It means a “man.” Lad In the same vein as “bloke,” “lad” is used, however, for boys and younger men. Bonkers Not necessarily intended in a bad way, “bonkers” means “mad” or “crazy.” Daft Used to mean if something is a bit stupid. It’s not particularly offensive, just mildly silly or foolish. To leg it This term means to run away, usually from some trouble! “I legged it from the Police.” These two words are British slang for drunk. One can get creative here Trollied / Plastered and just add “-ed” to the end of practically any object to get across the same meaning eg. hammered. Quid This is British slang for British pounds. Some people also refer to it as “squid.” Used to describe something or someone a little suspicious or Dodgy questionable. For example, it can refer to food which tastes out of date or, when referring to a person, it can mean that they are a bit sketchy. This is a truly British expression. “Gobsmacked” means to be utterly Gobsmacked shocked or surprised beyond belief. “Gob” is a British expression for “mouth”. Bevvy This is short for the word “beverages,” usually alcoholic, most often beer. Knackered “Knackered” is used when someone is extremely tired. For example, “I was up studying all night last night, I’m absolutely knackered.” Someone who has “lost the plot” has become either angry, irrational, Lost the plot or is acting ridiculously. -

Standard Southern British English As Referee Design in Irish Radio Advertising
Joan O’Sullivan Standard Southern British English as referee design in Irish radio advertising Abstract: The exploitation of external as opposed to local language varieties in advertising can be associated with a history of colonization, the external variety being viewed as superior to the local (Bell 1991: 145). Although “Standard English” in terms of accent was never an exonormative model for speakers in Ireland (Hickey 2012), nevertheless Ireland’s history of colonization by Britain, together with the geographical proximity and close socio-political and sociocultural connections of the two countries makes the Irish context an interesting one in which to examine this phenomenon. This study looks at how and to what extent standard British Received Pronunciation (RP), now termed Standard Southern British English (SSBE) (see Hughes et al. 2012) as opposed to Irish English varieties is exploited in radio advertising in Ireland. The study is based on a quantitative and qualitative analysis of a corpus of ads broadcast on an Irish radio station in the years 1977, 1987, 1997 and 2007. The use of SSBE in the ads is examined in terms of referee design (Bell 1984) which has been found to be a useful concept in explaining variety choice in the advertising context and in “taking the ideological temperature” of society (Vestergaard and Schroder 1985: 121). The analysis is based on Sussex’s (1989) advertisement components of Action and Comment, which relate to the genre of the discourse. Keywords: advertising, language variety, referee design, language ideology. 1 Introduction The use of language variety in the domain of advertising has received considerable attention during the past two decades (for example, Bell 1991; Lee 1992; Koslow et al. -

“Freedom and Friendship to Ireland”: Ribbonism in Early Nineteenth
"Freedom and Friendship to Ireland": Ribbonism in Early Nineteenth-Century Liverpool* JOHN BELCHEM Summary: The paper examines the role of "nationalist" secret societies among the rapidly growing Irish community in Britain in the 1830s and 1840s. The main port of entry, Liverpool occupied a pivotal role as the two main "Ribbon" societies developed secret networks to provide migrant members with political sanctuary and a range of "tramping" benefits. Through its welfare provision, offered irrespective of skill or trade, Ribbonism engendered a sense of identity wider than that of the familial and regional affiliations through which chain migration typically operated. A proactive influence among immigrant Irish Catholic workers, Ribbonism helped to construct a national or ethnic awareness, initiating the process by which ethnic-sectarian formations came to dominate popular politics in nineteenth-century Liverpool, the nation's second city. This ethnic associational culture was at least as functional, popular and inclusive as the class-based movements and party structures privileged in conventional British historiography. By decoding the ritual, symbolism and violence of secret societies, histo- rians have gained important insights into peasant and community resist- ance to modernization, centralization and change. Given their myriad forms, however, secret societies were not always the preserve of "primitive rebels". In nineteenth-century Ireland, where secret societies were prob- ably most endemic, traditionalist agrarian redresser movements operated alongside urban-based networks which combined labour protection and collective mutuality with forward-looking political and/or nationalist goals.1 There was considerable, often confusing, overlap and fluidity in aims and functions, hence the difficulty in classifying and categorizing Rib- bonism, a new type of secret society which emerged in Ireland around 1811. -

Not Taking Yourself Too Seriously in Australian English: Semantic Explications, Cultural Scripts, Corpus Evidence
Not taking yourself too seriously in Australian English: Semantic explications, cultural scripts, corpus evidence Author Goddard, Cliff Published 2009 Journal Title Intercultural Pragmatics Version Version of Record (VoR) DOI https://doi.org/10.1515/IPRG.2009.002 Copyright Statement © 2009 Walter de Gruyter & Co. KG Publishers. The attached file is reproduced here in accordance with the copyright policy of the publisher. Please refer to the journal's website for access to the definitive, published version. Downloaded from http://hdl.handle.net/10072/44428 Griffith Research Online https://research-repository.griffith.edu.au Not taking yourself too seriously in Australian English: Semantic explications, cultural scripts, corpus evidence CLIFF GODDARD Abstract In the mainstream speech culture of Australia (as in the UK, though per- haps more so in Australia), taking yourself too seriously is culturally proscribed. This study applies the techniques of Natural Semantic Meta- language (NSM) semantics and ethnopragmatics (Goddard 2006b, 2008; Wierzbicka 1996, 2003, 2006a) to this aspect of Australian English speech culture. It first develops a semantic explication for the language-specific ex- pression taking yourself too seriously, thus helping to give access to an ‘‘in- sider perspective’’ on the practice. Next, it seeks to identify some of the broader communicative norms and social attitudes that are involved, using the method of cultural scripts (Goddard and Wierzbicka 2004). Finally, it investigates the extent to which predictions generated from the analysis can be supported or disconfirmed by contrastive analysis of Australian English corpora as against other English corpora, and by the use of the Google search engine to explore di¤erent subdomains of the World Wide Web. -

Natural Phonetic Tendencies and Social Meaning: Exploring the Allophonic Raising Split of PRICE and MOUTH on the Isles of Scilly
This is a repository copy of Natural phonetic tendencies and social meaning: Exploring the allophonic raising split of PRICE and MOUTH on the Isles of Scilly. White Rose Research Online URL for this paper: http://eprints.whiterose.ac.uk/133952/ Version: Accepted Version Article: Moore, E.F. and Carter, P. (2018) Natural phonetic tendencies and social meaning: Exploring the allophonic raising split of PRICE and MOUTH on the Isles of Scilly. Language Variation and Change, 30 (3). pp. 337-360. ISSN 0954-3945 https://doi.org/10.1017/S0954394518000157 This article has been published in a revised form in Language Variation and Change [https://doi.org/10.1017/S0954394518000157]. This version is free to view and download for private research and study only. Not for re-distribution, re-sale or use in derivative works. © Cambridge University Press. Reuse This article is distributed under the terms of the Creative Commons Attribution-NonCommercial-NoDerivs (CC BY-NC-ND) licence. This licence only allows you to download this work and share it with others as long as you credit the authors, but you can’t change the article in any way or use it commercially. More information and the full terms of the licence here: https://creativecommons.org/licenses/ Takedown If you consider content in White Rose Research Online to be in breach of UK law, please notify us by emailing [email protected] including the URL of the record and the reason for the withdrawal request. [email protected] https://eprints.whiterose.ac.uk/ Title: Natural phonetic tendencies -

The Loyalist Origins of Canada's Identity Crisis
Condemned to Rootlessness: The Loyalist Origins of Canada's Identity Crisis Introduction In the view of the English-speaking Canadian media, Canada has an identity crisis, a situation attributable to divisions within the Canadian body politic that are regularly expressed in constitutional bickering between Quebec and the Rest of Canada and between the provinces and the federal government.1 Yet the identity crisis in the lifeworld of the average English-Canadian appears to possess a somewhat different quality. The following statement from Rod Lamirand, a resident of Surrey, B.C., expresses the subjectivity of this existential unease with remarkable accuracy: 'We [our family] were isolated, self-sufficient, cut off from a close community and from our pasts...Our family was not drawn into a neighborhood of friends because of a shared difference from mainstream society. We didn't have a name for the cultural majority because for the most part they were us. We were part of the dominant cultural society and we had no real culture. The great wash of pale European blood that saturated this continent was uniform in color only. Much of what survived is a hodgepodge of eclectic, meaningless routines...We were the product of white bread and instant coffee, Hollywood and the CBC....'2 (emphasis added) The connection between the Canadian identity crisis mentioned in the English-Canadian media and Lamirand's statement might appear distant. Surely, one might ask, the latter reflects a problem that should be labeled 'English-Canadian' rather than 'Canadian.' It is the position of this paper, however, that the discourses of English-Canadian and Canadian identity are inextricably bound. -

LANGUAGE VARIETY in ENGLAND 1 ♦ Language Variety in England
LANGUAGE VARIETY IN ENGLAND 1 ♦ Language Variety in England One thing that is important to very many English people is where they are from. For many of us, whatever happens to us in later life, and however much we move house or travel, the place where we grew up and spent our childhood and adolescence retains a special significance. Of course, this is not true of all of us. More often than in previous generations, families may move around the country, and there are increasing numbers of people who have had a nomadic childhood and are not really ‘from’ anywhere. But for a majority of English people, pride and interest in the area where they grew up is still a reality. The country is full of football supporters whose main concern is for the club of their childhood, even though they may now live hundreds of miles away. Local newspapers criss-cross the country in their thousands on their way to ‘exiles’ who have left their local areas. And at Christmas time the roads and railways are full of people returning to their native heath for the holiday period. Where we are from is thus an important part of our personal identity, and for many of us an important component of this local identity is the way we speak – our accent and dialect. Nearly all of us have regional features in the way we speak English, and are happy that this should be so, although of course there are upper-class people who have regionless accents, as well as people who for some reason wish to conceal their regional origins. -

Department of English and American Studies English Language And
Masaryk University Faculty of Arts Department of English and American Studies English Language and Literature Jana Krejčířová Australian English Bachelor’s Diploma Thesis Supervisor: PhDr. Kateřina Tomková, Ph. D. 2016 I declare that I have worked on this thesis independently, using only the primary and secondary sources listed in the bibliography. …………………………………………….. Author’s signature I would like to express my sincere gratitude to my supervisor PhDr. Kateřina Tomková, Ph.D. for her patience and valuable advice. I would also like to thank my partner Martin Burian and my family for their support and understanding. Table of Contents Abbreviations ........................................................................................................... 6 Introduction .............................................................................................................. 7 1. AUSTRALIA AND ITS HISTORY ................................................................. 10 1.1. Australia before the arrival of the British .................................................... 11 1.1.1. Aboriginal people .............................................................................. 11 1.1.2. First explorers .................................................................................... 14 1.2. Arrival of the British .................................................................................... 14 1.2.1. Convicts ............................................................................................. 15 1.3. Australia in the