Subtyping: an Introduction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1=Haskell =1=Making Our Own Types and Typeclasses
Haskell Making Our Own Types and Typeclasses http://igm.univ-mlv.fr/~vialette/?section=teaching St´ephaneVialette LIGM, Universit´eParis-Est Marne-la-Vall´ee November 13, 2016 Making Our Own Types and Typeclasses Algebraic data types intro So far, we've run into a lot of data types: Bool, Int, Char, Maybe, etc. But how do we make our own? One way is to use the data keyword to define a type. Let's see how the Bool type is defined in the standard library. data Bool= False| True data means that we're defining a new data type. Making Our Own Types and Typeclasses Algebraic data types intro data Bool= False| True The part before the = denotes the type, which is Bool. The parts after the = are value constructors. They specify the different values that this type can have. The | is read as or. So we can read this as: the Bool type can have a value of True or False. Both the type name and the value constructors have to be capital cased. Making Our Own Types and Typeclasses Algebraic data types intro We can think of the Int type as being defined like this: data Int=-2147483648|-2147483647| ...|-1|0|1|2| ...| 2147483647 The first and last value constructors are the minimum and maximum possible values of Int. It's not actually defined like this, the ellipses are here because we omitted a heapload of numbers, so this is just for illustrative purposes. Shape let's think about how we would represent a shape in Haskell. -

A Polymorphic Type System for Extensible Records and Variants
A Polymorphic Typ e System for Extensible Records and Variants Benedict R. Gaster and Mark P. Jones Technical rep ort NOTTCS-TR-96-3, November 1996 Department of Computer Science, University of Nottingham, University Park, Nottingham NG7 2RD, England. fbrg,[email protected] Abstract b oard, and another indicating a mouse click at a par- ticular p oint on the screen: Records and variants provide exible ways to construct Event = Char + Point : datatyp es, but the restrictions imp osed by practical typ e systems can prevent them from b eing used in ex- These de nitions are adequate, but they are not par- ible ways. These limitations are often the result of con- ticularly easy to work with in practice. For example, it cerns ab out eciency or typ e inference, or of the di- is easy to confuse datatyp e comp onents when they are culty in providing accurate typ es for key op erations. accessed by their p osition within a pro duct or sum, and This pap er describ es a new typ e system that reme- programs written in this way can b e hard to maintain. dies these problems: it supp orts extensible records and To avoid these problems, many programming lan- variants, with a full complement of p olymorphic op era- guages allow the comp onents of pro ducts, and the al- tions on each; and it o ers an e ective type inference al- ternatives of sums, to b e identi ed using names drawn gorithm and a simple compilation metho d. -

Java Secrets.Pdf
Java Secrets by Elliotte Rusty Harold IDG Books, IDG Books Worldwide, Inc. ISBN: 0764580078 Pub Date: 05/01/97 Buy It Preface About the Author Part I—How Java Works Chapter 1—Introducing Java SECRETS A Little Knowledge Can Be a Dangerous Thing What’s in This Book? Part I: How Java Works Part II: The sun Classes Part III: Platform-Dependent Java Why Java Secrets? Broader applicability More power Inspiration Where Did the Secrets Come From? Where is the documentation? The source code The API documentation What Versions of Java Are Covered? Some Objections Java is supposed to be platform independent Why aren’t these things documented? FUD (fear, uncertainty, and doubt) How secret is this, anyway? Summary Chapter 2—Primitive Data Types Bytes in Memory Variables, Values, and Identifiers Place-Value Number Systems Binary notation Hexadecimal notation Octal notation Integers ints Long, short, and byte Floating-Point Numbers Representing floating-point numbers in binary code Special values Denormalized floating-point numbers CHAR ASCII ISO Latin-1 Unicode UTF8 Boolean Cross-Platform Issues Byte order Unsigned integers Integer widths Conversions and Casting Using a cast The mechanics of conversion Bit-Level Operators Some terminology Bitwise operators Bit shift operators Summary Chapter 2—Primitive Data Types Bytes in Memory Variables, Values, and Identifiers Place-Value Number Systems Binary notation Hexadecimal notation Octal notation Integers ints Long, short, and byte Floating-Point Numbers Representing floating-point numbers in binary code -

Lecture Slides
Outline Meta-Classes Guy Wiener Introduction AOP Classes Generation 1 Introduction Meta-Classes in Python Logging 2 Meta-Classes in Python Delegation Meta-Classes vs. Traditional OOP 3 Meta-Classes vs. Traditional OOP Outline Meta-Classes Guy Wiener Introduction AOP Classes Generation 1 Introduction Meta-Classes in Python Logging 2 Meta-Classes in Python Delegation Meta-Classes vs. Traditional OOP 3 Meta-Classes vs. Traditional OOP What is Meta-Programming? Meta-Classes Definition Guy Wiener Meta-Program A program that: Introduction AOP Classes One of its inputs is a program Generation (possibly itself) Meta-Classes in Python Its output is a program Logging Delegation Meta-Classes vs. Traditional OOP Meta-Programs Nowadays Meta-Classes Guy Wiener Introduction AOP Classes Generation Compilers Meta-Classes in Python Code Generators Logging Delegation Model-Driven Development Meta-Classes vs. Traditional Templates OOP Syntactic macros (Lisp-like) Meta-Classes The Problem With Static Programming Meta-Classes Guy Wiener Introduction AOP Classes Generation Meta-Classes How to share features between classes and class hierarchies? in Python Logging Share static attributes Delegation Meta-Classes Force classes to adhere to the same protocol vs. Traditional OOP Share code between similar methods Meta-Classes Meta-Classes Guy Wiener Introduction AOP Classes Definition Generation Meta-Classes in Python Meta-Class A class that creates classes Logging Delegation Objects that are instances of the same class Meta-Classes share the same behavior vs. Traditional OOP Classes that are instances of the same meta-class share the same behavior Meta-Classes Meta-Classes Guy Wiener Introduction AOP Classes Definition Generation Meta-Classes in Python Meta-Class A class that creates classes Logging Delegation Objects that are instances of the same class Meta-Classes share the same behavior vs. -

Haskell-Style Type Classes with Isabelle/Isar
Isar ∀ Isabelle= α λ β → Haskell-style type classes with Isabelle/Isar Florian Haftmann 20 February 2021 Abstract This tutorial introduces Isar type classes, which are a convenient mech- anism for organizing specifications. Essentially, they combine an op- erational aspect (in the manner of Haskell) with a logical aspect, both managed uniformly. 1 INTRODUCTION 1 1 Introduction Type classes were introduced by Wadler and Blott [8] into the Haskell lan- guage to allow for a reasonable implementation of overloading1. As a canon- ical example, a polymorphic equality function eq :: α ) α ) bool which is overloaded on different types for α, which is achieved by splitting introduc- tion of the eq function from its overloaded definitions by means of class and instance declarations: 2 class eq where eq :: α ) α ) bool instance nat :: eq where eq 0 0 = True eq 0 - = False eq - 0 = False eq (Suc n)(Suc m) = eq n m instance (α::eq; β::eq) pair :: eq where eq (x1; y1) (x2; y2) = eq x1 x2 ^ eq y1 y2 class ord extends eq where less-eq :: α ) α ) bool less :: α ) α ) bool Type variables are annotated with (finitely many) classes; these annotations are assertions that a particular polymorphic type provides definitions for overloaded functions. Indeed, type classes not only allow for simple overloading but form a generic calculus, an instance of order-sorted algebra [5, 6, 10]. From a software engineering point of view, type classes roughly correspond to interfaces in object-oriented languages like Java; so, it is naturally desirable that type classes do not only provide functions (class parameters) but also state specifications implementations must obey. -

OMG Meta Object Facility (MOF) Core Specification
Date : October 2019 OMG Meta Object Facility (MOF) Core Specification Version 2.5.1 OMG Document Number: formal/2019-10-01 Standard document URL: https://www.omg.org/spec/MOF/2.5.1 Normative Machine-Readable Files: https://www.omg.org/spec/MOF/20131001/MOF.xmi Informative Machine-Readable Files: https://www.omg.org/spec/MOF/20131001/CMOFConstraints.ocl https://www.omg.org/spec/MOF/20131001/EMOFConstraints.ocl Copyright © 2003, Adaptive Copyright © 2003, Ceira Technologies, Inc. Copyright © 2003, Compuware Corporation Copyright © 2003, Data Access Technologies, Inc. Copyright © 2003, DSTC Copyright © 2003, Gentleware Copyright © 2003, Hewlett-Packard Copyright © 2003, International Business Machines Copyright © 2003, IONA Copyright © 2003, MetaMatrix Copyright © 2015, Object Management Group Copyright © 2003, Softeam Copyright © 2003, SUN Copyright © 2003, Telelogic AB Copyright © 2003, Unisys USE OF SPECIFICATION - TERMS, CONDITIONS & NOTICES The material in this document details an Object Management Group specification in accordance with the terms, conditions and notices set forth below. This document does not represent a commitment to implement any portion of this specification in any company's products. The information contained in this document is subject to change without notice. LICENSES The companies listed above have granted to the Object Management Group, Inc. (OMG) a nonexclusive, royalty-free, paid up, worldwide license to copy and distribute this document and to modify this document and distribute copies of the modified version. Each of the copyright holders listed above has agreed that no person shall be deemed to have infringed the copyright in the included material of any such copyright holder by reason of having used the specification set forth herein or having conformed any computer software to the specification. -
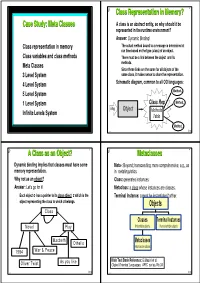
Metaclasses 4 ◆ Dynamic Binding Implies That Classes Must Have Some ◆ Meta-: Beyond; Transcending; More Comprehensive; E.G., As Memory Representation
® 1 ® Class Representation in Memory? 2 Case Study: Meta Classes ◆ A class is an abstract entity, so why should it be represented in the runtime environment? ◆ Answer: Dynamic Binding! ◆ Class representation in memory ● The actual method bound to a message is determined at run time based on the type (class) of an object. ◆ Class variables and class methods ● There must be a link between the object and its ◆ Meta Classes methods. ● Since these links are the same for all objects of the ◆ 3 Level System same class, it makes sense to share the representation. ◆ ◆ 4 Level System Schematic diagram, common to all OO languages: Method ◆ 5 Level System 1 Method ◆ 1 Level System Class Rep 2 ◆ Msg Object Methods Infinite Levels System Table Methodn oop Õ Ö oop Õ Ö ® A Class as an Object? 3 ® Metaclasses 4 ◆ Dynamic binding implies that classes must have some ◆ Meta-: Beyond; transcending; more comprehensive; e.g., as memory representation. in metalinguistics. ◆ Why not as an object? ◆ Class: generates instances. ◆ Answer: Let's go for it! ◆ Metaclass: a class whose instances are classes. ● Each object o has a pointer to its class object c which is the ◆ Terminal Instance: cannot be instantiated further. object representing the class to which o belongs. Objects Class Classes Terminal Instances Novel Play Instantiable objects Non instantiable objects Macbeth Othello Metaclasses Instances are classes 1984 War & Peace As you like Main Text Book Reference: G.Masini et al. Oliver Twist Object-Oriented Languages, APIC series, No.34 oop Õ Ö oop Õ Ö ® 5 ® 6 Taxonomy of Metaclass Systems The 3 Level System ◆ 1-Level System: Objects only Object ● Each object describes itself INSTANCE _OF ● No need for classes: objects are ìinstantiatedî or ìinheritedî from SUBCLASS _OF other objects Class Example: Self VARIABLES instance_of ,167$1&(B2) ◆ 2-Level System: Objects, Classes METHODS .. -

Java Class Types 12 September
CSCI 136: Fall 2018 Handout 3 Java Class Types 12 September Class Types We noted earlier that the String type in Java was not a primitive (or array) type. It is what Java calls a class- based (or class) type—this is the third category of types in Java. Class types, are based on class declarations. Class declarations allow us to create objects that can hold more complex collections of data, along with operations for accessing/modifying that data. For example public class Student { private int age; private String name; private char grade; public Student(int theAge, String theName, char theGrade) { age = theAge; name = theName; grade = theGrade; } public int getAge() { return age;} public String getName() { return name;} public char getGrade() { return grade;} public void setAge(int newAge) { age = newAge;} public void setGrade(char grade) { this.grade = grade;} } The above, grotesquely oversimplified, class declaration specifies the data components (instance variables) of a Stu- dent object, along with a method (called a constructor∗) describing how to create such objects, and several short methods for accessing/modifying the data components (fields/instance variables) of a Student object. Given such a class declaration, one can write programs that declare (and create) variables of type Student: Student a; Student b; a = new Student(18, "Patti Smith", ’A’); b = new Student(20, "Joan Jett", ’B’); Or, combining the declaration of the variables and creation (instantiation) of the corresponding values (objects): Student a = new Student(18, "Patti Smith", ’A’); Student b = new Student(20, "Joan Jett", ’B’); The words public and private are called access level modifiers; they control the extent to which other classes can create, access, or modify objects, their fields, and their methods. -

First-Class Type Classes
First-Class Type Classes Matthieu Sozeau1 and Nicolas Oury2 1 Univ. Paris Sud, CNRS, Laboratoire LRI, UMR 8623, Orsay, F-91405 INRIA Saclay, ProVal, Parc Orsay Universit´e, F-91893 [email protected] 2 University of Nottingham [email protected] Abstract. Type Classes have met a large success in Haskell and Is- abelle, as a solution for sharing notations by overloading and for spec- ifying with abstract structures by quantification on contexts. However, both systems are limited by second-class implementations of these con- structs, and these limitations are only overcomed by ad-hoc extensions to the respective systems. We propose an embedding of type classes into a dependent type theory that is first-class and supports some of the most popular extensions right away. The implementation is correspond- ingly cheap, general and integrates well inside the system, as we have experimented in Coq. We show how it can be used to help structured programming and proving by way of examples. 1 Introduction Since its introduction in programming languages [1], overloading has met an important success and is one of the core features of object–oriented languages. Overloading allows to use a common name for different objects which are in- stances of the same type schema and to automatically select an instance given a particular type. In the functional programming community, overloading has mainly been introduced by way of type classes, making ad-hoc polymorphism less ad hoc [17]. A type class is a set of functions specified for a parametric type but defined only for some types. -

Comparative Study of Generic Programming Features in Object-Oriented Languages1
Comparative Study of Generic Programming Features in Object-Oriented Languages1 Julia Belyakova [email protected] February 3rd 2017 NEU CCIS Programming Language Seminar 1Based on the papers [Belyakova 2016b; Belyakova 2016a] Generic Programming A term “Generic Programming” (GP) was coined in 1989 by Alexander Stepanov and David Musser Musser and Stepanov 1989. Idea Code is written in terms of abstract types and operations (parametric polymorphism). Purpose Writing highly reusable code. Julia Belyakova Generic Programming in OO Languages February 3, 2017 (PL Seminar) 2 / 45 Contents 1 Language Support for Generic Programming 2 Peculiarities of Language Support for GP in OO Languages 3 Language Extensions for GP in Object-Oriented Languages 4 Conclusion Julia Belyakova Generic Programming in OO Languages February 3, 2017 (PL Seminar) 3 / 45 Language Support for Generic Programming Unconstrained Generic Code 1 Language Support for Generic Programming Unconstrained Generic Code Constraints on Type Parameters 2 Peculiarities of Language Support for GP in OO Languages 3 Language Extensions for GP in Object-Oriented Languages 4 Conclusion Julia Belyakova Generic Programming in OO Languages February 3, 2017 (PL Seminar) 4 / 45 Count<T> can be instantiated with any type int[] ints = new int[]{ 3, 2, -8, 61, 12 }; var evCnt = Count(ints, x => x % 2 == 0);//T == int string[] strs = new string[]{ "hi", "bye", "hello", "stop" }; var evLenCnt = Count(strs, x => x.Length % 2 == 0);//T == string Language Support for Generic Programming Unconstrained -

Understanding and Analyzing Java Reflection
Understanding and Analyzing Java Reflection by Yue Li A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN THE SCHOOL OF Computer Science and Engineering 26 July, 2016 All rights reserved. This work may not be reproduced in whole or in part, by photocopy or other means, without the permission of the author. c Yue Li 2016 PLEASE TYPE THE UNIVERSITY OF NEW SOUTH WALES Thesis/Dissertation Sheet Surname or Family name: Li First name: Yue Other name/s: Abbreviation for degree as given in the University calendar: PhD School: Computer Science and Engineering Faculty: Engineering Title: Understanding and Analyzing Java Reflection Abstract 350 words maximum: (PLEASE TYPE) Java reflection is increasingly used in a range of software and framework architectures. It allows a software system to examine itself and make changes that affect its execution at run-time, but creates significant challenges to static analysis. This is because the usages of reflection are quite complicated in real-world Java programs, and their dynamic behaviors are mainly specified by string arguments, which are usually unknown statically. As a result, in almost all the static analysis tools, reflection is either ignored or handled partially, resulting in missed, important behaviors, i.e., unsound results. Improving or even achieving soundness in reflection analysis will provide significant benefits to many clients, such as bug detectors, security analyzers and program verifiers. This thesis first introduces what Java reflection is, and conducts an empirical study on how reflection is used in real-world Java applications. Many useful findings are concluded for guiding the designs of more effective reflection analysis methods and tools. -

Type Systems, Type Inference, and Polymorphism
6 Type Systems, Type Inference, and Polymorphism Programming involves a wide range of computational constructs, such as data struc- tures, functions, objects, communication channels, and threads of control. Because programming languages are designed to help programmers organize computational constructs and use them correctly, many programming languages organize data and computations into collections called types. In this chapter, we look at the reasons for using types in programming languages, methods for type checking, and some typing issues such as polymorphism and type equality. A large section of this chap- ter is devoted to type inference, the process of determining the types of expressions based on the known types of some symbols that appear in them. Type inference is a generalization of type checking, with many characteristics in common, and a representative example of the kind of algorithms that are used in compilers and programming environments to determine properties of programs. Type inference also provides an introduction to polymorphism, which allows a single expression to have many types. 6.1 TYPES IN PROGRAMMING In general, a type is a collection of computational entities that share some common property. Some examples of types are the type Int of integers, the type Int!Int of functions from integers to integers, and the Pascal subrange type [1 .. 100] of integers between 1 and 100. In concurrent ML there is the type Chan Int of communication channels carrying integer values and, in Java, a hierarchy of types of exceptions. There are three main uses of types in programming languages: naming and organizing concepts, making sure that bit sequences in computer memory are interpreted consistently, providing information to the compiler about data manipulated by the program.