Heterogeneous Embedding for Subjective Artist Similarity
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
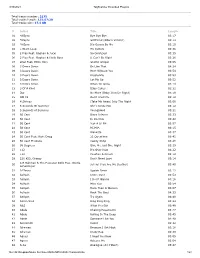
3/30/2021 Tagscanner Extended Playlist File:///E:/Dropbox/Music For
3/30/2021 TagScanner Extended PlayList Total tracks number: 2175 Total tracks length: 132:57:20 Total tracks size: 17.4 GB # Artist Title Length 01 *NSync Bye Bye Bye 03:17 02 *NSync Girlfriend (Album Version) 04:13 03 *NSync It's Gonna Be Me 03:10 04 1 Giant Leap My Culture 03:36 05 2 Play Feat. Raghav & Jucxi So Confused 03:35 06 2 Play Feat. Raghav & Naila Boss It Can't Be Right 03:26 07 2Pac Feat. Elton John Ghetto Gospel 03:55 08 3 Doors Down Be Like That 04:24 09 3 Doors Down Here Without You 03:54 10 3 Doors Down Kryptonite 03:53 11 3 Doors Down Let Me Go 03:52 12 3 Doors Down When Im Gone 04:13 13 3 Of A Kind Baby Cakes 02:32 14 3lw No More (Baby I'ma Do Right) 04:19 15 3OH!3 Don't Trust Me 03:12 16 4 Strings (Take Me Away) Into The Night 03:08 17 5 Seconds Of Summer She's Kinda Hot 03:12 18 5 Seconds of Summer Youngblood 03:21 19 50 Cent Disco Inferno 03:33 20 50 Cent In Da Club 03:42 21 50 Cent Just A Lil Bit 03:57 22 50 Cent P.I.M.P. 04:15 23 50 Cent Wanksta 03:37 24 50 Cent Feat. Nate Dogg 21 Questions 03:41 25 50 Cent Ft Olivia Candy Shop 03:26 26 98 Degrees Give Me Just One Night 03:29 27 112 It's Over Now 04:22 28 112 Peaches & Cream 03:12 29 220 KID, Gracey Don’t Need Love 03:14 A R Rahman & The Pussycat Dolls Feat. -
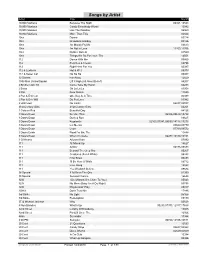
Songs by Artist
Songs by Artist Artist Title DiscID 10,000 Maniacs Because The Night 00321,15543 10,000 Maniacs Candy Everybody Wants 10942 10,000 Maniacs Like The Weather 05969 10,000 Maniacs More Than This 06024 10cc Donna 03724 10cc Dreadlock Holiday 03126 10cc I'm Mandy Fly Me 03613 10cc I'm Not In Love 11450,14336 10cc Rubber Bullets 03529 10cc Things We Do For Love, The 14501 112 Dance With Me 09860 112 Peaches & Cream 09796 112 Right Here For You 05387 112 & Ludacris Hot & Wet 05373 112 & Super Cat Na Na Na 05357 12 Stones Far Away 12529 1999 Man United Squad Lift It High (All About Belief) 04207 2 Brothers On 4th Come Take My Hand 02283 2 Evisa Oh La La La 03958 2 Pac Dear Mama 11040 2 Pac & Eminem One Day At A Time 05393 2 Pac & Eric Will Do For Love 01942 2 Unlimited No Limits 02287,03057 21st Century Girls 21st Century Girls 04201 3 Colours Red Beautiful Day 04126 3 Doors Down Be Like That 06336,09674,14734 3 Doors Down Duck & Run 09625 3 Doors Down Kryptonite 02103,07341,08699,14118,17278 3 Doors Down Let Me Go 05609,05779 3 Doors Down Loser 07769,09572 3 Doors Down Road I'm On, The 10448 3 Doors Down When I'm Gone 06477,10130,15151 3 Of Hearts Arizona Rain 07992 311 All Mixed Up 14627 311 Amber 05175,09884 311 Beyond The Grey Sky 05267 311 Creatures (For A While) 05243 311 First Straw 05493 311 I'll Be Here A While 09712 311 Love Song 12824 311 You Wouldn't Believe 09684 38 Special If I'd Been The One 01399 38 Special Second Chance 16644 3LW I Do (Wanna Get Close To You) 05043 3LW No More (Baby I'm A Do Right) 09798 3LW Playas Gon' Play -

Ally Confusion, Back Page
ally Confusion, Back Page The ather Today: unny, Windy, 30°F (-1°C) 0 Tonight: lear, old OaF (_17 ) Tomorrow: loudy 20°F (-7°C) Details Page 2 02139 AS to dis ibu Part of Techs om or oa By Jennifer Krishnan Board had decided to revoke The EWSEDITOR Tech's space at today's Activities The Executive Board of the Midway. After a hearing yesterday, ssociation of tudent ctivities held at the reque t of The Tech, subtracted about one-fourth of The however the board amended the Tech's office pace as a sanction for anction. violating ASA ru h rule . The deci ion is not appealable to This is the first time the A A has the SA Executive Board, but The revoked office space for ru h rules Tech may choose to appeal to A sis- violation, said A Pre ident tant Dean for Student Activitie lvar aenz-Otero G. Tracy F. Purinton or Dean for tu- Tech Chairman Jordan Rubin 02 dent Life Larry G. Benedict aenz- called the ruling "inappropriate ... I Otero aid. don't think what they've accused us Rubin said The Tech plans to of doing is even a crime at all.' he make uch an appeal. said. KAlLAS NARE DRAN-TJlE TECH "The A A ruling is based on Hou d Jeffrey C. Barrett '02 tests the Bucking Bronco of Death during East Campus rush on Monday. several recruitment adverti ements Among the offenses The Tech i place both in the general section of being sanctioned for are several The Tech as well as in the Daily "house ad " - advertisements Confu ion," aenz-Otero said. -

Executive of the Week: Carbon Fiber Music President Franklin
Bulletin YOUR DAILY ENTERTAINMENT NEWS UPDATE AUGUST 27, 2021 Page 1 of 28 INSIDE Executive of the Week: • Roblox’s Music Play: ‘Hundreds’ Carbon Fiber Music President of Daily Concerts, Building a Franklin Martínez Digital Vegas & NMPA Lawsuit BY LEILA COBO • UK Festival Industry Primed for Biggest Farruko’s “Pepas,” an EDM/reggaetón track about Enter “Pepas,” which kicks off with Farruko sing- Weekend Since pill-popping partygoers, hit No.1 this week on Bill- ing gently over simple chords, almost as if it were a Pandemic Began board’s Hot Latin Songs and Hot Dance/Electronic love song, before it pumps up, finessed by a sextet of Songs charts. Equally impressive is the fact that producers: IAmChino, Sharo Towers, Keriel “K4G” • Apple to Make Changes to “Pepas” is not a multi-artist collaboration, but a Far- Quiroz, Victor Cárdenas, White Star and Axel Ra- App Store Rules in ruko solo single, bolstered by an irresistible, anthemic fael Quezada Fulgencio “Ghetto.” Settlement With chorus that sent fans wild at the recent Baja Beach The song was released June 24 on Sony Music Latin U.S. Developers Fest in Rosarito, Mexico despite the fact that the song with little fanfare — there wasn’t even a video ready • Bruno Mars’ is only two months old. — and debuted at No. 28 on the Hot Latin Songs chart Las Vegas Show That’s all sweet news for Farruko (real name Carlos dated July 17. It jumped to the top 10 four weeks later, Grosses More Than Efrén Reyes Rosado), a reggaetón star who’s had eight reaching No. -
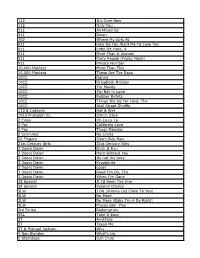
112 It's Over Now 112 Only You 311 All Mixed up 311 Down
112 It's Over Now 112 Only You 311 All Mixed Up 311 Down 702 Where My Girls At 911 How Do You Want Me To Love You 911 Little Bit More, A 911 More Than A Woman 911 Party People (Friday Night) 911 Private Number 10,000 Maniacs More Than This 10,000 Maniacs These Are The Days 10CC Donna 10CC Dreadlock Holiday 10CC I'm Mandy 10CC I'm Not In Love 10CC Rubber Bullets 10CC Things We Do For Love, The 10CC Wall Street Shuffle 112 & Ludacris Hot & Wet 1910 Fruitgum Co. Simon Says 2 Evisa Oh La La La 2 Pac California Love 2 Pac Thugz Mansion 2 Unlimited No Limits 20 Fingers Short Dick Man 21st Century Girls 21st Century Girls 3 Doors Down Duck & Run 3 Doors Down Here Without You 3 Doors Down Its not my time 3 Doors Down Kryptonite 3 Doors Down Loser 3 Doors Down Road I'm On, The 3 Doors Down When I'm Gone 38 Special If I'd Been The One 38 Special Second Chance 3LW I Do (Wanna Get Close To You) 3LW No More 3LW No More (Baby I'm A Do Right) 3LW Playas Gon' Play 3rd Strike Redemption 3SL Take It Easy 3T Anything 3T Tease Me 3T & Michael Jackson Why 4 Non Blondes What's Up 5 Stairsteps Ooh Child 50 Cent Disco Inferno 50 Cent If I Can't 50 Cent In Da Club 50 Cent In Da Club 50 Cent P.I.M.P. (Radio Version) 50 Cent Wanksta 50 Cent & Eminem Patiently Waiting 50 Cent & Nate Dogg 21 Questions 5th Dimension Aquarius_Let the sunshine inB 5th Dimension One less Bell to answer 5th Dimension Stoned Soul Picnic 5th Dimension Up Up & Away 5th Dimension Wedding Blue Bells 5th Dimension, The Last Night I Didn't Get To Sleep At All 69 Boys Tootsie Roll 8 Stops 7 Question -

Media® JUNE 1, 2002 / VOLUME 20 / ISSUE 23 / £3.95 / EUROS 6.5
Music Media® JUNE 1, 2002 / VOLUME 20 / ISSUE 23 / £3.95 / EUROS 6.5 THE MUCH ANTICIPATED NEW ALBUM 10-06-02 INCLUDES THE SINGLE 'HERE TO STAY' Avukr,m',L,[1] www.korntv.com wwwamymusweumpecun IMMORTam. AmericanRadioHistory.Com System Of A Down AerialscontainsThe forthcoming previously single unreleased released and July exclusive 1 Iostprophetscontent.Soldwww.systemofadown.com out AtEuropean radio now. tour. theFollowing lostprophets massive are thefakesoundofprogressnow success on tour in thethroughout UK and Europe.the US, featuredCatch on huge the new O'Neill single sportwear on"thefakesoundofprogress", MTVwww.lostprophets.com competitionEurope during running May. CreedOne Last Breath TheCommercialwww.creednet.com new single release from fromAmerica's June 17.biggest band. AmericanRadioHistory.Com TearMTVDrowning Europe Away Network Pool Priority! Incubuswww.drowningpool.comCommercialOn tour in Europe release now from with June Ozzfest 10. and own headlining shows. CommercialEuropean release festivals fromAre in JuneAugust.You 17.In? www.sonymusiceurope.cornSONY MUSIC EUROPE www.enjoyincubus.com Music Mediae JUNE 1, 2002 / VOLUME 20 / ISSUE 23 / £3.95 / EUROS 6.5 AmericanRadioHistory.Com T p nTA T_C ROCK Fpn"' THE SINGLE THE ALBUM A label owned by Poko Rekords Oy 71e um!010111, e -e- Number 1in Finland for 4 weeks Number 1in Finland Certified gold Certified gold, soon to become platinum Poko Rekords Oy, P.O. Box 483, FIN -33101 Tampere, Finland I Tel: +358 3 2136 800 I Fax: +358 3 2133 732 I Email: [email protected] I Website: www.poko.fi I www.pariskills.com Two rriot girls and a boy present: Album A label owned by Poko Rekords Oy \member of 7lit' EMI Cji0//p "..rriot" AmericanRadioHistory.Com UPFRONT Rock'snolonger by Emmanuel Legrand, Music & Media editor -in -chief Welcome to Music & Media's firstspecial inahard place issue of the year-an issue that should rock The fact that Ozzy your socks off. -

Grammy Countdown U2, Nelly Furtado Interviews Kedar Massenburg on India.Arie Celine Dion "A New Day Has Come"
February 15, 2002 Volume 16 Issue 781 $6.00 GRAMMY COUNTDOWN U2, NELLY FURTADO INTERVIEWS KEDAR MASSENBURG ON INDIA.ARIE CELINE DION "A NEW DAY HAS COME" The premiere single from "A New Day Has Come," her first new album in two years and her first studio album since "Let's Talk About Love," which sold over 28 million copies worldwide. IMPACTING RADIO NOW 140 million albums sold worldwide 2,000,000+ cumulative radio plays and over 21 billion in combined audience 6X Grammy' winner Winner of an Academy Award for "My Heart Will Go On" Extensive TV and Press to support release: Week of Release Jprah-Entire program dedicated to Celine The View The Today Show CBS This Morning Regis & Kelly Upcoming Celine's CBS Network Special The Tonight Show Kicks off The Today Show Outdoor Concert Series Single produced by Walter Afanasieff and Aldo Nova, with remixes produced by Ric Wake, Humberto Gatica, and Christian B. Video directed by Dave Meyers will debut in early March. Album in stores Tuesday, March 26 www.epicrecords.com www.celinedion.com I fie, "Epic" and Reg. U.S. Pat. & Tm. Off. Marca Registrada./C 2002 Sony Music Entertainment (Canada) Inc. hyVaiee.sa Cartfoi Produccil6y Ro11Fair 1\lixeJyJo.serli Pui3 A'01c1 RDrecfioi: Ron Fair rkia3erneit: deter allot" for PM M #1 Phones WBLI 600 Spins before 2/18 Impact Early Adds: KITS -FM WXKS Y100 KRBV KHTS WWWQ WBLIKZQZ WAKS WNOU TRL WKZL BZ BUZZWORTHY -2( A&M Records Rolling Stone: "Artist To Watch" feature ras February 15, 2002 Volume 16 Issue 781 DENNIS LAVINTHAL Publisher LENNY BEER THE DIVINE MISS POLLY Editor In Chief EpicRecords Group President Polly Anthony is the diva among divas, as Jen- TONI PROFERA Executive Editor nifer Lopez debuts atop the album chart this week. -

For Immediate Release Chicago Westside Music Festival Announces 2017 Lineup R & B Legends, Lil' Mo, Vivian Green and Dru H
FOR IMMEDIATE RELEASE CHICAGO WESTSIDE MUSIC FESTIVAL ANNOUNCES 2017 LINEUP R & B LEGENDS, LIL’ MO, VIVIAN GREEN AND DRU HILL HEADLINE THE 6TH ANNUAL CHICAGO WESTSIDE MUSIC FESTIVAL CHICAGO, IL (July 31, 2017) – An accomplished singer and songwriter, a Soul Train Award R&B Songstress and a Billboard Award-winning group from Maryland will headline the 2017 Chicago Westside Music Festival (“WSMF”). Presented by the Westside Cultural Foundation, the annual summer festival will feature Lil’ Mo, Vivian Green and Dru Hill for the 6th Annual WSMF on Saturday, August 19, 2017. Hosted by WGCI’s very own Leon Rogers, WSMF will feature local Chicago talent, performing in various genres. All of the festival events are free and open to the public. The annual summer festival will take place from 11 a.m. to 9 p.m. in Douglas Park, 1401 S. Sacramento Drive (at the corner of Ogden and Sacramento), in Chicago, Illinois. “We are excited about the enhancements that we have made to the festival this year, as well as the opportunity to continue to provide such an amazing FREE experience on Chicago’s West Side,” said Lauren Raymond, Executive Director of the Westside Cultural Foundation. The day will begin at 11 a.m. with the End of Summer Celebration, sponsored by the 24th Ward Alderman, Michael Scott, Jr. There will be activities for kids and seniors, along with school supply and backpack giveaways. “I’m proud to continue to partner with the Westside Cultural Foundation to put on this annual event that provides family focused fun to the North Lawndale community, my neighbors on the West Side and the entire Chicagoland area. -

2001-0113.Pdf
AMERICAN ~----- - 1526 0 VENTURA BOULEYARD -- , ___ , - -, ., .. -5.TB,ELPOR .- . SHERMAN OAKS, CALIFORNIA 91403-5339 TELEPHONE (818) 377-5300 FAX (8 18) 377-5333 WITH CASEY I<ASEM ·website: http://www.pretniereradio .con1 Show Code: #01-02 Show Date: January 13-14, 2001 Disc One/Hour One Track 1 Seg . 1 Open Billboards: GENERIC Content: #40 "I WISH" - R. Kelly #39 "ANGEL" - Shaggy Commercials: :60 Travelocity.com :30 Swiffer Outcue: " ... changing cleaning behavior." Segment time: 12:19 Local Break 1 :30 Seg.2 Track 2 Content: #38 "WHAT'S YOUR FANTASY" - Ludacris #37 "LEAVING TOWN" - Dexter Freebish #36 "NO MORE (BABY l'MA DO RIGHT)"- 3LW Commercials: :30 Jerzees :30 Rate The Music.com :30 Dexatrim Outcue: " ... it's a natural." Segment time: 15:08 Local Break 1: 00 Seg. 3 Track 3 Content:_ #3_5 '.'AROUND THE WORLD" -ATC #34 "THANK YOU FOR LOVING -lvlE" -:: Bon JovI Commercials: :60 Travelocity.com :30 VH1 Top 100 Album Outcue: " ... only on VH1" Segment time: 10:08 Local Break 1:30 Seg.4 Track 4 Content: #33 "BUTTERFLY" - Crazy Town #32 "BABYLON" - David Gray Commercials: :30 Lifetime Television :30 Tampax :30 Jlf Outcue: " ... you choose Jif." Segment time: 10: 23 Local Break 1 :00 Seg. 5 Content: #31 "BETWEEN ME AND YO U" - Ja Rule Segment Time:5:05 Outcue: Jingle Insert local ID over :06 jingle bed " END OF DISC ONE -- -DISC TWO STARTS AT SEGMENT SIX ,/ ***America's Top Hits for Monday (Elton John) is on Track 6*** f ***America's Top Hits for Tuesday (-Dr. Dre/Blackstr;et-) is on Track 7*** ,, AMERICAN :.,,,:,,.,;-,•,,s,,·•" ~---- - . -
Elephant Sanctuary Did You Know That Elephants Are a Lot Shirley and Bunny Have Like People? Both Elephants and People Found a Good Home at the Elephant Sanctuary
release dates: August 30-September 5 35-1 (08) TM TM Go dot to dot and color. © 2008 Universal Press Syndicate BETTY DEBNAM – Founding Editor and Editor at Large from The Mini Page © 2008 Universal Press Syndicate A Peaceful Habitat The Elephant Sanctuary Did you know that elephants are a lot Shirley and Bunny have like people? Both elephants and people found a good home at the Elephant Sanctuary. • are very social, or friendly; Because they are so large, • love to play; they need a great deal of • are very intelligent; food. An elephant may • have long childhoods, becoming weigh from 9,000 to 12,000 pounds. (An average car adults when they are about 20. weighs about 2,000 Many of these smart animals have pounds.) been taken from the wild in Africa or Adult elephants need to eat Asia to live in zoos and circuses. from 150 to 220 pounds of In zoos and circuses, elephants may be food per day, and they eat only plants. They need a lot confined to small spaces. Imagine if you of space to roam and find were forced to sit still in school all day, food. with no recess and no play time after school or on the weekends. It would not photos courtesy The Elephant Sanctuary be healthy for you, and you would not be Carol meets Tarra happy. You might start to feel a little Carol Buckley is the co-founder of the When Carol was a child, she always from The Mini Page © 2008 Universal Press Syndicate crazy. -

Sorted by Artist Music Listing 2005 112 Hot & Wet (Radio)
Sorted by Artist Music Listing 2005 112 Hot & Wet (Radio) WARNING 112 Na Na Na (Super Clean w. Rap) 112 Right Here For You (Radio) (63 BPM) 311 First Straw (80 bpm) 311 Love Song 311 Love Song (Cirrus Club Mix) 702 Blah Blah Blah Blah (Radio Edit) 702 Star (Main) .38 Special Fade To Blue .38 Special Hold On Loosely 1 Giant Leap My Culture (Radio Edit) 10cc I'm Not In Love 1910 Fruitgum Company Simon Says 2 Bad Mice Bombscare ('94 US Remix) 2 Skinnee J's Grow Up [Radio Edit] 2 Unlimited Do What's Good For Me 2 Unlimited Faces 2 Unlimited Get Ready For This 2 Unlimited Here I Go 2 Unlimited Jump For Joy 2 Unlimited Let The Beat Control Your Body 2 Unlimited Magic Friend 2 Unlimited Maximum Overdrive 2 Unlimited No Limit 2 Unlimited No One 2 Unlimited Nothing Like The Rain 2 Unlimited Real Thing 2 Unlimited Spread Your Love 2 Unlimited Tribal Dance 2 Unlimited Twilight Zone 2 Unlimited Unlimited Megajam 2 Unlimited Workaholic 2% of Red Tide Body Bagger 20 Fingers Lick It 2funk Apsyrtides (original mix) 2Pac Thugz Mansion (Radio Edit Clean) 2Pac ft Trick Daddy Still Ballin' (Clean) 1 of 197 Sorted by Artist Music Listing 2005 3 Doors Down Away From The Sun (67 BPM) 3 Doors Down Be Like That 3 Doors Down Here Without You (Radio Edit) 3 Doors Down Kryptonite 3 Doors Down Road I'm On 3 Doors Down When I'm Gone 3k Static Shattered 3LW & P Diddy I Do (Wanna Get Close To You) 3LW ft Diddy & Loan I Do (Wanna Get Close To You) 3LW ft Lil Wayne Neva Get Enuf 4 Clubbers Children (Club Radio Edit) 4 Hero Mr. -
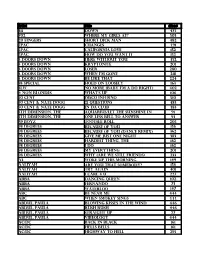
Music List (PDF)
Artist Title disc# 311 Down 475 702 Where My Girls At? 503 20 fingers short dick man 482 2pac changes 491 2Pac California Love 152 2Pac How Do You Want It 152 3 Doors Down Here Without You 452 3 Doors Down Kryptonite 201 3 doors down loser 280 3 Doors Down when I'm gone 218 3 Doors Down Be Like That 224 38 Special Hold On Loosely 163 3lw No more (baby I'm a do right) 402 4 Non Blondes What's Up 106 50 Cent Disco Inferno 510 50 cent & nate dogg 21 questions 483 50 cent & nate dogg in da club 483 5th Dimension, The aquarius/let the sunshine in 91 5th Dimension, The One Less Bell To Answer 93 69 Boyz Tootsee Roll 205 98 Degrees Because Of You 156 98 Degrees Because Of You (Dance Remix) 362 98 degrees Give me just one Night 383 98 Degrees Hardest Thing, the 162 98 Degrees I Do 162 98 Degrees My Everything 201 98 Degrees Why (Are We Still Friends) 233 A3 Woke Up This Morning 149 Aaliyah Are You That Somebody? 156 aaliyah Try again 401 Aaliyah I Care 4 U 227 Abba Dancing Queen 102 ABBA FERNANDO 73 ABBA Waterloo 147 ABC Be Near Me 444 ABC When Smokey Sings 444 ABDUL, PAULA Blowing Kisses In The Wind 446 ABDUL, PAULA Rush Rush 446 ABDUL, PAULA STRAIGHT UP 27 ABDUL, PAULA Vibeology 444 AC/DC Back In Black 161 AC/DC Hells Bells 161 AC/DC Highway To Hell 295 AC/DC Stiff Upper Lip 295 AC/DC Whole Lotta Rosie 295 AC/dc You shook me all night long 108 Ace Of Base Beautiful Life 8 Ace of Base Don't Turn Around 154 Ace Of Base Sign, The 206 AD LIBS BOY FROM NEW YORK CITY, THE 49 adam ant goody two shoes 108 ADAMS, BRYAN (EVERYTHING I DO) I DO IT FOR YOU