Principle and Praxis in the Experience Web: a Case Study in Social Music
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
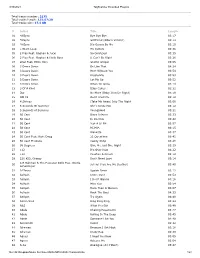
3/30/2021 Tagscanner Extended Playlist File:///E:/Dropbox/Music For
3/30/2021 TagScanner Extended PlayList Total tracks number: 2175 Total tracks length: 132:57:20 Total tracks size: 17.4 GB # Artist Title Length 01 *NSync Bye Bye Bye 03:17 02 *NSync Girlfriend (Album Version) 04:13 03 *NSync It's Gonna Be Me 03:10 04 1 Giant Leap My Culture 03:36 05 2 Play Feat. Raghav & Jucxi So Confused 03:35 06 2 Play Feat. Raghav & Naila Boss It Can't Be Right 03:26 07 2Pac Feat. Elton John Ghetto Gospel 03:55 08 3 Doors Down Be Like That 04:24 09 3 Doors Down Here Without You 03:54 10 3 Doors Down Kryptonite 03:53 11 3 Doors Down Let Me Go 03:52 12 3 Doors Down When Im Gone 04:13 13 3 Of A Kind Baby Cakes 02:32 14 3lw No More (Baby I'ma Do Right) 04:19 15 3OH!3 Don't Trust Me 03:12 16 4 Strings (Take Me Away) Into The Night 03:08 17 5 Seconds Of Summer She's Kinda Hot 03:12 18 5 Seconds of Summer Youngblood 03:21 19 50 Cent Disco Inferno 03:33 20 50 Cent In Da Club 03:42 21 50 Cent Just A Lil Bit 03:57 22 50 Cent P.I.M.P. 04:15 23 50 Cent Wanksta 03:37 24 50 Cent Feat. Nate Dogg 21 Questions 03:41 25 50 Cent Ft Olivia Candy Shop 03:26 26 98 Degrees Give Me Just One Night 03:29 27 112 It's Over Now 04:22 28 112 Peaches & Cream 03:12 29 220 KID, Gracey Don’t Need Love 03:14 A R Rahman & The Pussycat Dolls Feat. -

May July June August
19861986 MAY JUNE 1. Greatest Love Of All…Whitney Houston 1. On My Own…Patti LaBelle & Michael McDonald 2. Addicted To Love…Robert Palmer 2. Live To Tell…Madonna 3. West End Girls…Pet Shop Boys 3. Crush On You…The Jets 4. Why Can’t This Be Love…Van Halen 4. I Can’t Wait…Nu Shooz 5. What Have You Done For Me Lately…Janet Jackson 5. All I Need Is A Miracle…Mike + The Mechanics 6. If You Leave…Orchestral Manoeuvres In The Dark 6. A Different Corner…George Michael 7. Harlem Shuffle…Rolling Stones 7. Nothin’ At All…Heart 8. Your Love…The Outfield 8. I Wanna Be A Cowboy…Boys Don’t Cry 9. Take Me Home…Phil Collins 9. Vienna Calling…Falco 10. Something About You…Level 42 10. Rain On The Scarecrow…John Cougar Mellencamp 11. Bad Boy…Miami Sound Machine 11. One Hit (To The Body)…The Rolling Stones 12. Is It Love…Mr. Mister 12. The Love Parade…The Dream Academy 13. Be Good To Yourself…Journey 13. Out Of Mind Out Of Sight…Models 14. Move Away…Culture Club 14. The Finest…The S.O.S. Band 15. American Storm…Bob Seger 15. I Must Be Dreaming…Giuffria 16. Never As Good As The First Time…Sade' 16. Headed For The Future…Neil Diamond 17. Rough Boy…ZZ Top 17. Listen Like Thieves…INXS 18. Tomorrow Doesn’t Matter Tonight…Starship 18. Don Quichotte…Magazine 60 19. Mothers Talk…Tears For Fears 19. Living On Video…Trans-X 20. All The Things She Said…Simple Minds 20. -

Christina Milian, Snooze You Lose Christina Milian Guest Artists: None Album: Christina Milian Track
Christina Milian, Snooze You Lose Christina Milian Guest Artists: none Album: Christina Milian Track- Chorus: Snooze you gonna lose and she won't want you back again. The way you keep on playin' it's impossible to win. Soon you're going to see you have to up and end. You're going to hit and missYou snooze you lose baby! Verse1: Hey boy, you haven't been payin' attention to my friend. I know you think you're the man, the way you do your thing. And I bet you're havin' fun when you hag out with your boys. Well, your relationship with your girl is coming to an end. Bridge: You keep thinkin' that she won't leave. But again and again you go on and on and the next thing you'll know- she'll be gone! Chorus: Snooze you gonna lose and she won't want you back again. The way you keep on playin' it's impossible to win. Soon you're going to see you have to up and end. You're going to hit and missYou snooze you lose baby! Verse2: Now you're prolly don't believe me- i'm tellin' you it's true. 'Cause you told me she had a problem, her problem was you. So you're walkin' up in ice and I'm breakin' you the news. You better be on your toes, 'cause soon she's gonna go. Bridge: You keep thinkin' that she won't leave. But again and again you go on and on and the next thing you'll know- she'll be gone! Chorus2x: Snooze you gonna lose and she won't want you back again. -

1. Summer Rain by Carl Thomas 2. Kiss Kiss by Chris Brown Feat T Pain 3
1. Summer Rain By Carl Thomas 2. Kiss Kiss By Chris Brown feat T Pain 3. You Know What's Up By Donell Jones 4. I Believe By Fantasia By Rhythm and Blues 5. Pyramids (Explicit) By Frank Ocean 6. Under The Sea By The Little Mermaid 7. Do What It Do By Jamie Foxx 8. Slow Jamz By Twista feat. Kanye West And Jamie Foxx 9. Calling All Hearts By DJ Cassidy Feat. Robin Thicke & Jessie J 10. I'd Really Love To See You Tonight By England Dan & John Ford Coley 11. I Wanna Be Loved By Eric Benet 12. Where Does The Love Go By Eric Benet with Yvonne Catterfeld 13. Freek'n You By Jodeci By Rhythm and Blues 14. If You Think You're Lonely Now By K-Ci Hailey Of Jodeci 15. All The Things (Your Man Don't Do) By Joe 16. All Or Nothing By JOE By Rhythm and Blues 17. Do It Like A Dude By Jessie J 18. Make You Sweat By Keith Sweat 19. Forever, For Always, For Love By Luther Vandros 20. The Glow Of Love By Luther Vandross 21. Nobody But You By Mary J. Blige 22. I'm Going Down By Mary J Blige 23. I Like By Montell Jordan Feat. Slick Rick 24. If You Don't Know Me By Now By Patti LaBelle 25. There's A Winner In You By Patti LaBelle 26. When A Woman's Fed Up By R. Kelly 27. I Like By Shanice 28. Hot Sugar - Tamar Braxton - Rhythm and Blues3005 (clean) by Childish Gambino 29. -
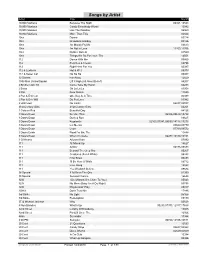
Songs by Artist
Songs by Artist Artist Title DiscID 10,000 Maniacs Because The Night 00321,15543 10,000 Maniacs Candy Everybody Wants 10942 10,000 Maniacs Like The Weather 05969 10,000 Maniacs More Than This 06024 10cc Donna 03724 10cc Dreadlock Holiday 03126 10cc I'm Mandy Fly Me 03613 10cc I'm Not In Love 11450,14336 10cc Rubber Bullets 03529 10cc Things We Do For Love, The 14501 112 Dance With Me 09860 112 Peaches & Cream 09796 112 Right Here For You 05387 112 & Ludacris Hot & Wet 05373 112 & Super Cat Na Na Na 05357 12 Stones Far Away 12529 1999 Man United Squad Lift It High (All About Belief) 04207 2 Brothers On 4th Come Take My Hand 02283 2 Evisa Oh La La La 03958 2 Pac Dear Mama 11040 2 Pac & Eminem One Day At A Time 05393 2 Pac & Eric Will Do For Love 01942 2 Unlimited No Limits 02287,03057 21st Century Girls 21st Century Girls 04201 3 Colours Red Beautiful Day 04126 3 Doors Down Be Like That 06336,09674,14734 3 Doors Down Duck & Run 09625 3 Doors Down Kryptonite 02103,07341,08699,14118,17278 3 Doors Down Let Me Go 05609,05779 3 Doors Down Loser 07769,09572 3 Doors Down Road I'm On, The 10448 3 Doors Down When I'm Gone 06477,10130,15151 3 Of Hearts Arizona Rain 07992 311 All Mixed Up 14627 311 Amber 05175,09884 311 Beyond The Grey Sky 05267 311 Creatures (For A While) 05243 311 First Straw 05493 311 I'll Be Here A While 09712 311 Love Song 12824 311 You Wouldn't Believe 09684 38 Special If I'd Been The One 01399 38 Special Second Chance 16644 3LW I Do (Wanna Get Close To You) 05043 3LW No More (Baby I'm A Do Right) 09798 3LW Playas Gon' Play -

R Kelly Double up Album Zip
1 / 5 R Kelly Double Up Album Zip The R. Kelly album spawned three platinum hit singles: "You Remind Me of ... Kelly began his Double Up tour with Ne-Yo, Keyshia Cole and J. Holiday opening .... R. Kelly, Happy People - U Saved Me (CD 2) Full Album Zip ... Saved Me is the sixth studio album and the second double album by R&B singer R. Kelly, where ... Kelly grew up in a house full of women, who he said would act .... R. kelly double up songbook . Manchester, tn june 15 r kelly performs during the 2013 bonnaroo music . Machine gun kelly ft quavo ty dolla sign trap paris video .. siosynchmaty/r-kelly-double-up-album-zip. siosynchmaty/r-kelly- double-up-album-zip. By siosynchmaty. R Kelly Double Up Album Zip. Container. OverviewTags.. For your search query R Kelly Double Up Album MP3 we have found 1000000 songs matching your query but showing only top 10 results. Now we recommend .... Kelly's 13th album, The Buffet, aims to be a return to form after spending nearly 10 ... Enter City and State or Zip Code ... Instead, this "Buffet" celebrates Kelly's renowned musical diversity, serving up equal parts lust and love. ... Up Everybody" drips with sexuality without the eye-rolling double-entendres.. kelly discography, r kelly discography, machine gun kelly ... R. Commin' Up 5. ... is the sixth studio album and the second double album by R&B singer R. 94 ... itunes deluxe version 2012 zip Ne-Yo - R. His was lame as HELL .. literally. The singer has been enjoying some time-off of her Prismatic World tour, which picks back up in September, and decided to spread her ... -

Christina Milian Dip It
Dip It Low Christina Milian Says he wants you He says he needs you If it's real talk then why not make him wait for you If he really wants you If he really needs you Take your time and feel him out When he's a good boy (A really really good boy) Why not let him lay with you (When you give it to him good) Dip it low Pick it up slow Roll it all around poke it out like your back broke Pop, pop, pop that thang I'ma show you how to make your man say "ooh" Dip it low Pick it up slow Roll it all around poke it out like your back broke Pop, pop, pop that thang I'ma show you how to make your man say "ooh" You gettin' bold He's growin' cold It's just the symptoms of young love Growin' old You think it's time (And you thinkin', but give it time) It's late at night He's coming home Meet him at the door with nothin' on Take him by the hand Let him know what's on If you understand me (ooh) All the ladies wind it up if you know just how to move All my fellas jump behind her show her what you wanna do All the ladies wind it up if you know just how to move All my fellas jump behind her show her what you wanna do (ooh, ooh) Dip it low Pick it up slow Roll it all around poke it out like your back broke Pop, pop, pop that thang I'ma show you how to make your man say "ooh" Dip it low Pick it up slow Roll it all around poke it out like your back broke Pop, pop, pop that thang I'ma show you how to make your man say "ooh" (Fabolous) Yeah, uh, yeah, uh Baby girl I want you to pop, pop, pop that thang I might stop to shop and cop you things You know I drop the -

JULIANNE “JUJU” WATERS Choreographer
JULIANNE “JUJU” WATERS Choreographer COMMERCIAL CHOREOGRAPHY EXPENSIFY // Expensify This // Dir: Andreas Nilsson KLARNA // The Coronation of Smooth Dogg // Dir: Traktor Frontier // Dream Job // Dir: The Perlorian Wish // Amazing Things // Dir: Filip Engstrom Vitamin Water // Drink Outside the Lines // Dir: Traktor Old Navy // Holiyay, Rockstar Jeans // Dir: Joel Kefali Money Supermarket // Bootylicious // Dir: Fredrik Bond LG // Jason Stathum // Dir: Fredrik Bond Dannon // Stayin Alive // Dir: Fredrik Bond Ritz // Putting on the Ritz // Dir: Fredrik Bond FILM Bring It On Cinco // Dir:Billy Woodruff American Carol // Dir: David Zucker Spring Breakdown // Dir: Ryan Shiraki A Cinderella Story// Dir: M. Rosman Bring It On Again // Dir: D. Santostafano TELEVISION Super Bowl XXXVIII // JANET JACKSON feat. JUSTIN TIMBERLAKE Super Bowl XLV // THE BLACK EYED PEAS feat. USHER Fashion Rocks // “Candyman” // CHRISTINA AGUILERA Good Morning America // “Touch my Body” & “That Chick” // MARIAH CAREY Good Morning America // “With Love” // HILARY DUFF Soul Train Awards // "I Like The Way You Move" // OUTKAST feat. SLEEPY BROWN Dancing with the Stars // KYLIE MINOGUE Dancing with the Stars // FATIMA ROBINSON TRIBUTE American Music Awards // 2009, 2010, 2011 // THE BLACK EYED PEAS American Music Awards // “Better in Time” // LEONA LEWIS American Music Awards // “Fergalicious” // FERGIE American Music Awards // "Lights, Camera, Action" // P DIDDY feat. MR. CHEEKS & SNOOP DOGG Teen Choice Awards // "Promiscuous" // NELLY FURTATO feat. TIMBERLAND Teen Nick // “With Love” // HILARY DUFF Billboard Music Awards // “Fergilicious” // FERGIE VH1 Big in ’06 // “London Bridge & Fergilicious” // FERGIE VIBE Music Awards // “This is How We Do” // THE GAME & 50 CENT Ellen Show // Special Birthday Performance // ELLEN DEGENERES Ellen Show // “With Love” // HILARY DUFF Jay Leno // “With Love” // HILARY DUFF Jay Leno // "She Bangs" // WILLIAM HUNG Jimmey Kimmel // “With Love & Stranger” // HILARY DUFF BET Awards // “Come Watch Me” // JILL SCOTT feat. -

BET Networks Announces the Return of All Inspiring Gospel Competition Series, “Sunday Best,” for Its Ninth Season
BET Networks Announces the Return of All Inspiring Gospel Competition Series, “Sunday Best,” for Its Ninth Season April 18, 2019 Music Icon Kirk Franklin Returns as Host & Mentor, along with Erica Campbell, Kelly Price, and Jonathan McReynolds as Judges “Sunday Best” Premieres Sunday, June 30th on BET in the US and Internationally Beginning Sunday, July 7th NEW YORK--(BUSINESS WIRE)--Apr. 18, 2019-- After a four-year hiatus, America’s most inspirational singing competition, “Sunday Best,” makes its triumphant return to BET, as a new and improved Season 9 takes over Sunday nights beginning in June. The well-established gospel show welcomes back Grammy Award®-winning music legend Kirk Franklin as host, gospel songstress and host of "Get Up Mornings," Erica Campbell as a judge; and adds two Grammy-Award® nominated artists Kelly Price and Jonathan McReynolds as new additions to the panel. With a brand new stage and exciting themed challenges, this season will be the toughest one yet. This press release features multimedia. View the full release here: https://www.businesswire.com/news/home/20190418005527/en/ The new season kicks off with in-person auditions in front of the judges as they narrow the field from 20 to the top 10. For the first time the contestants were able to use an online submissions process, after which the team lead a global search for this year’s contestants, leading up to the much-anticipated live auditions in Dallas, TX, Washington, D.C., Atlanta, GA, and Detroit, MI, Lagos, Nigeria and for the first time-ever London, England and Johannesburg, South Africa, which were open to select international contestants. -

Check out 8 Songs Musical Artists Have
Search TRAILBLAZERS IN MUSIC: CHECK OUT SONGS MUSICAL ARTISTS HAVE SAMPLED FROM WOMEN OF MOTOWN By Brianna Rhodes Photo: Classic Motown - Advertisement - The Sound Of Young America wouldn’t be known for what it is today without the trailblazing Women of Motown. Throughout its 60-year existence, Motown Records made an impact on the world thanks to music genius and founder, Berry Gordy. It's important to note though, that the African- American owned label wouldn’t have reached so many monumental milestones without The Supremes, Martha Reeves & The Vandellas, Mary Wells, The Marvelettes, Tammi Terrell and Gladys Knight. The success of these talented women proved that women voices needed to be heard through radio airwaves everywhere. As a kid, you were probably singing melodies created by these women around the house with family members or even performing the songs in your school’s talent show, not even realizing how much of an impact these women made on Black culture and Black music. This is why it’s important to acknowledge these women during the celebration of the label’s 60th anniversary. The legendary reign of the Women of Motown began back in 1960, with then 17-year-old musical artist Mary Wells with her debut single, “Bye Bye Baby.” Wells, who wrote the song herself, helped Motown attain its first Top 10 R&B hit ever. Wells continued to make history with her chart-topping single, “My Guy” becoming Motown’s fourth No. 1 hit on the Billboard Hot 100 and the company’s first major U.K. single. -

Read Ebook // Christina Milian Discography
QSLRQT836D8G » Doc » Christina Milian Discography Get eBook CHRISTINA MILIAN DISCOGRAPHY Alphascript Publishing. Taschenbuch. Book Condition: Neu. Neuware - Christina Milian is an American R&B and pop singer-songwriter. She has released three studio albums, six singles and one compilation album, in addition to six music videos on record labels Def Jam Recordings and Island Records. Milian's self-titled debut album was released in 2001, and features the singles 'AM to PM' and 'When You Look at Me'; both peaked in the top three on the UK Singles Chart. The singer's second studio... Download PDF Christina Milian Discography Authored by Frederic P. Miller Released at - Filesize: 5.02 MB Reviews An exceptional ebook and the font employed was fascinating to read through. I actually have study and so i am certain that i will likely to read once again yet again in the future. Your life period is going to be change as soon as you complete looking at this book. -- Nelle Schaefer I This kind of publication is every little thing and taught me to looking ahead of time and a lot more. It is packed with wisdom and knowledge Once you begin to read the book, it is extremely difficult to leave it before concluding. -- Ida Herman TERMS | DMCA 8TXSDJ1YW3NP » Book » Christina Milian Discography Related Books When Life Gives You Lemons. at Least You Won t Get Scurvy!: Making the Best of the Crap Life Gives You Thank You God for Me A Little Look at Big Reptiles NF (Blue B) Slave Girl - Return to Hell, Ordinary British Girls are Being Sold into Sex Slavery; I Escaped, But Now I'm Going Back to Help Free Them. -

Ally Confusion, Back Page
ally Confusion, Back Page The ather Today: unny, Windy, 30°F (-1°C) 0 Tonight: lear, old OaF (_17 ) Tomorrow: loudy 20°F (-7°C) Details Page 2 02139 AS to dis ibu Part of Techs om or oa By Jennifer Krishnan Board had decided to revoke The EWSEDITOR Tech's space at today's Activities The Executive Board of the Midway. After a hearing yesterday, ssociation of tudent ctivities held at the reque t of The Tech, subtracted about one-fourth of The however the board amended the Tech's office pace as a sanction for anction. violating ASA ru h rule . The deci ion is not appealable to This is the first time the A A has the SA Executive Board, but The revoked office space for ru h rules Tech may choose to appeal to A sis- violation, said A Pre ident tant Dean for Student Activitie lvar aenz-Otero G. Tracy F. Purinton or Dean for tu- Tech Chairman Jordan Rubin 02 dent Life Larry G. Benedict aenz- called the ruling "inappropriate ... I Otero aid. don't think what they've accused us Rubin said The Tech plans to of doing is even a crime at all.' he make uch an appeal. said. KAlLAS NARE DRAN-TJlE TECH "The A A ruling is based on Hou d Jeffrey C. Barrett '02 tests the Bucking Bronco of Death during East Campus rush on Monday. several recruitment adverti ements Among the offenses The Tech i place both in the general section of being sanctioned for are several The Tech as well as in the Daily "house ad " - advertisements Confu ion," aenz-Otero said.