Applications of Existing Biodiversity Information: Capacity to Support Decision-Making
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
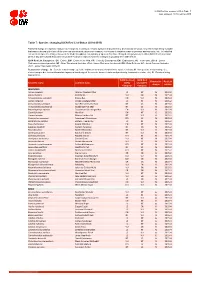
Table 7: Species Changing IUCN Red List Status (2014-2015)
IUCN Red List version 2015.4: Table 7 Last Updated: 19 November 2015 Table 7: Species changing IUCN Red List Status (2014-2015) Published listings of a species' status may change for a variety of reasons (genuine improvement or deterioration in status; new information being available that was not known at the time of the previous assessment; taxonomic changes; corrections to mistakes made in previous assessments, etc. To help Red List users interpret the changes between the Red List updates, a summary of species that have changed category between 2014 (IUCN Red List version 2014.3) and 2015 (IUCN Red List version 2015-4) and the reasons for these changes is provided in the table below. IUCN Red List Categories: EX - Extinct, EW - Extinct in the Wild, CR - Critically Endangered, EN - Endangered, VU - Vulnerable, LR/cd - Lower Risk/conservation dependent, NT - Near Threatened (includes LR/nt - Lower Risk/near threatened), DD - Data Deficient, LC - Least Concern (includes LR/lc - Lower Risk, least concern). Reasons for change: G - Genuine status change (genuine improvement or deterioration in the species' status); N - Non-genuine status change (i.e., status changes due to new information, improved knowledge of the criteria, incorrect data used previously, taxonomic revision, etc.); E - Previous listing was an Error. IUCN Red List IUCN Red Reason for Red List Scientific name Common name (2014) List (2015) change version Category Category MAMMALS Aonyx capensis African Clawless Otter LC NT N 2015-2 Ailurus fulgens Red Panda VU EN N 2015-4 -

Species List
Mozambique: Species List Birds Specie Seen Location Common Quail Harlequin Quail Blue Quail Helmeted Guineafowl Crested Guineafowl Fulvous Whistling-Duck White-faced Whistling-Duck White-backed Duck Egyptian Goose Spur-winged Goose Comb Duck African Pygmy-Goose Cape Teal African Black Duck Yellow-billed Duck Cape Shoveler Red-billed Duck Northern Pintail Hottentot Teal Southern Pochard Small Buttonquail Black-rumped Buttonquail Scaly-throated Honeyguide Greater Honeyguide Lesser Honeyguide Pallid Honeyguide Green-backed Honeyguide Wahlberg's Honeyguide Rufous-necked Wryneck Bennett's Woodpecker Reichenow's Woodpecker Golden-tailed Woodpecker Green-backed Woodpecker Cardinal Woodpecker Stierling's Woodpecker Bearded Woodpecker Olive Woodpecker White-eared Barbet Whyte's Barbet Green Barbet Green Tinkerbird Yellow-rumped Tinkerbird Yellow-fronted Tinkerbird Red-fronted Tinkerbird Pied Barbet Black-collared Barbet Brown-breasted Barbet Crested Barbet Red-billed Hornbill Southern Yellow-billed Hornbill Crowned Hornbill African Grey Hornbill Pale-billed Hornbill Trumpeter Hornbill Silvery-cheeked Hornbill Southern Ground-Hornbill Eurasian Hoopoe African Hoopoe Green Woodhoopoe Violet Woodhoopoe Common Scimitar-bill Narina Trogon Bar-tailed Trogon European Roller Lilac-breasted Roller Racket-tailed Roller Rufous-crowned Roller Broad-billed Roller Half-collared Kingfisher Malachite Kingfisher African Pygmy-Kingfisher Grey-headed Kingfisher Woodland Kingfisher Mangrove Kingfisher Brown-hooded Kingfisher Striped Kingfisher Giant Kingfisher Pied -

Arthropod Parasites in Domestic Animals
ARTHROPOD PARASITES IN DOMESTIC ANIMALS Abbreviations KINGDOM PHYLUM CLASS ORDER CODE Metazoa Arthropoda Insecta Siphonaptera INS:Sip Mallophaga INS:Mal Anoplura INS:Ano Diptera INS:Dip Arachnida Ixodida ARA:Ixo Mesostigmata ARA:Mes Prostigmata ARA:Pro Astigmata ARA:Ast Crustacea Pentastomata CRU:Pen References Ashford, R.W. & Crewe, W. 2003. The parasites of Homo sapiens: an annotated checklist of the protozoa, helminths and arthropods for which we are home. Taylor & Francis. Taylor, M.A., Coop, R.L. & Wall, R.L. 2007. Veterinary Parasitology. 3rd edition, Blackwell Pub. HOST-PARASITE CHECKLIST Class: MAMMALIA [mammals] Subclass: EUTHERIA [placental mammals] Order: PRIMATES [prosimians and simians] Suborder: SIMIAE [monkeys, apes, man] Family: HOMINIDAE [man] Homo sapiens Linnaeus, 1758 [man] ARA:Ast Sarcoptes bovis, ectoparasite (‘milker’s itch’)(mange mite) ARA:Ast Sarcoptes equi, ectoparasite (‘cavalryman’s itch’)(mange mite) ARA:Ast Sarcoptes scabiei, skin (mange mite) ARA:Ixo Ixodes cornuatus, ectoparasite (scrub tick) ARA:Ixo Ixodes holocyclus, ectoparasite (scrub tick, paralysis tick) ARA:Ixo Ornithodoros gurneyi, ectoparasite (kangaroo tick) ARA:Pro Cheyletiella blakei, ectoparasite (mite) ARA:Pro Cheyletiella parasitivorax, ectoparasite (rabbit fur mite) ARA:Pro Demodex brevis, sebacceous glands (mange mite) ARA:Pro Demodex folliculorum, hair follicles (mange mite) ARA:Pro Trombicula sarcina, ectoparasite (black soil itch mite) INS:Ano Pediculus capitis, ectoparasite (head louse) INS:Ano Pediculus humanus, ectoparasite (body -

The Status and Distribution of Freshwater Fish Endemic to the Mediterranean Basin
IUCN – The Species Survival Commission The Status and Distribution of The Species Survival Commission (SSC) is the largest of IUCN’s six volunteer commissions with a global membership of 8,000 experts. SSC advises IUCN and its members on the wide range of technical and scientific aspects of species conservation Freshwater Fish Endemic to the and is dedicated to securing a future for biodiversity. SSC has significant input into the international agreements dealing with biodiversity conservation. Mediterranean Basin www.iucn.org/themes/ssc Compiled and edited by Kevin G. Smith and William R.T. Darwall IUCN – Freshwater Biodiversity Programme The IUCN Freshwater Biodiversity Assessment Programme was set up in 2001 in response to the rapidly declining status of freshwater habitats and their species. Its mission is to provide information for the conservation and sustainable management of freshwater biodiversity. www.iucn.org/themes/ssc/programs/freshwater IUCN – Centre for Mediterranean Cooperation The Centre was opened in October 2001 and is located in the offices of the Parque Tecnologico de Andalucia near Malaga. IUCN has over 172 members in the Mediterranean region, including 15 governments. Its mission is to influence, encourage and assist Mediterranean societies to conserve and use sustainably the natural resources of the region and work with IUCN members and cooperate with all other agencies that share the objectives of the IUCN. www.iucn.org/places/medoffice Rue Mauverney 28 1196 Gland Switzerland Tel +41 22 999 0000 Fax +41 22 999 0002 E-mail: [email protected] www.iucn.org IUCN Red List of Threatened SpeciesTM – Mediterranean Regional Assessment No. -

First Finding of Species Alburnus Arborella (Bonaparte, 1841) Syn
Journal of Survey in Fisheries Sciences 6(2) 79-92 2020 First finding of species Alburnus arborella (Bonaparte, 1841) syn. Alburnus alborella (De Filippi, 1844)(Actinoptery GII: Cyprinidae, Alburninae) in Buško Lake Ţujo Zekić D.1*; Riđanović S.1; Spasojević P.1 Received: May 2019 Accepted: December2019 Abstract In this paper we present data about first findings of species Alburnus arborella(Bonaparte, 1841) syn. Alburnus alborella (De Filippi, 1844) (Actinoptery GII: Cyprinidae, Alburninae) in Buško Lake (Municipality Livno).In this report twenty – four specimens were cought during research period in two seasons in 2018. More specifically, trips to the catchment areas were made in spring-summer season from 12.06.2018 to 18.07.2018. and 22.11.2018.Determination of individuals was made on the basis of analysis of individual morphometric and meristic characterswith the exact length and weight of the individuals.This is the first finding of this species probably brought and introduced by fishermen.The findings of this species in Bosnia and Herzegovina have so far been confirmed in the Neretva watercourse and in the Ričica river in the Republic of Croatia. Keywords:Alburnus arborella, First finding, Busko lakeBosnia and Herzegovina, Meristic characters Downloaded from sifisheriessciences.com at 16:50 +0330 on Tuesday September 28th 2021 [ DOI: 10.18331/SFS2020.6.2.9 ] 1-Department of Biology,Faculty of Education, University of Dţemal Bijedićin Mostar, Sjeverni logor b.b., 88.104 Mostar, Bosna i Hercegovina *Corresponding author's Email: [email protected] 80 Ţujo Zekić et al., First finding of species Alburnus arborella (Bonaparte, 1841) syn. Alburnus… Introduction 1968,1977; Aganovic et al. -

A Dissertation Entitled Evolution, Systematics
A Dissertation Entitled Evolution, systematics, and phylogeography of Ponto-Caspian gobies (Benthophilinae: Gobiidae: Teleostei) By Matthew E. Neilson Submitted as partial fulfillment of the requirements for The Doctor of Philosophy Degree in Biology (Ecology) ____________________________________ Adviser: Dr. Carol A. Stepien ____________________________________ Committee Member: Dr. Christine M. Mayer ____________________________________ Committee Member: Dr. Elliot J. Tramer ____________________________________ Committee Member: Dr. David J. Jude ____________________________________ Committee Member: Dr. Juan L. Bouzat ____________________________________ College of Graduate Studies The University of Toledo December 2009 Copyright © 2009 This document is copyrighted material. Under copyright law, no parts of this document may be reproduced without the expressed permission of the author. _______________________________________________________________________ An Abstract of Evolution, systematics, and phylogeography of Ponto-Caspian gobies (Benthophilinae: Gobiidae: Teleostei) Matthew E. Neilson Submitted as partial fulfillment of the requirements for The Doctor of Philosophy Degree in Biology (Ecology) The University of Toledo December 2009 The study of biodiversity, at multiple hierarchical levels, provides insight into the evolutionary history of taxa and provides a framework for understanding patterns in ecology. This is especially poignant in invasion biology, where the prevalence of invasiveness in certain taxonomic groups could -

The Haematophagous Arthropods (Animalia: Arthropoda) of the Cape Verde Islands: a Review
Zoologia Caboverdiana 4 (2): 31-42 Available at www.scvz.org © 2013 Sociedade Caboverdiana de Zoologia The haematophagous arthropods (Animalia: Arthropoda) of the Cape Verde Islands: a review Elves Heleno Duarte1 Keywords: Arthropods, arthropod-borne diseases, bloodsucking, hematophagy, Cape Verde Islands ABSTRACT Arthropoda is the most diverse phylum of the animal kingdom. The majority of bloodsucking arthropods of public health concern are found in two classes, Arachnida and Insecta. Mosquitoes, ticks, cattle flies, horseflies and biting midges are the main hematophagous groups occurring in the Cape Verde Islands and whose role in infectious disease transmission has been established. In this literature review, the main morphological and biological characters and their role in the cycle of disease transmission are summarized. RESUMO Os artrópodes constituem o mais diverso entre todos os filos do reino animal. É na classe Arachnida e na classe Insecta que encontramos a maioria dos artrópodes com importância na saúde pública. Os mosquitos, os carrapatos, as moscas do gado, os tabanídeos e os mosquitos pólvora são os principais grupos hematófagos que ocorrem em Cabo Verde e possuem clara associação com a transmissão de agentes infecciosos. Nesta revisão da literatura apresentamos os principais caracteres morfológicos e biologicos e o seu papel no ciclo de transmissão de doenças. 1 Direcção Nacional da Saúde, Ministério da Saúde, Avenida Cidade de Lisboa, C.P. 47, Praia, Republic of Cape Verde; [email protected] Duarte 32 Haematophagous arthropods INTRODUCTION With over a million described species, which ca. 500 are strongly associated with the Arthropoda is the most diverse and species rich transmission of infectious agents (Grimaldi & clade of the animal kingdom. -

The 2008 IUCN Red Listings of the World's Small Carnivores
The 2008 IUCN red listings of the world’s small carnivores Jan SCHIPPER¹*, Michael HOFFMANN¹, J. W. DUCKWORTH² and James CONROY³ Abstract The global conservation status of all the world’s mammals was assessed for the 2008 IUCN Red List. Of the 165 species of small carni- vores recognised during the process, two are Extinct (EX), one is Critically Endangered (CR), ten are Endangered (EN), 22 Vulnerable (VU), ten Near Threatened (NT), 15 Data Deficient (DD) and 105 Least Concern. Thus, 22% of the species for which a category was assigned other than DD were assessed as threatened (i.e. CR, EN or VU), as against 25% for mammals as a whole. Among otters, seven (58%) of the 12 species for which a category was assigned were identified as threatened. This reflects their attachment to rivers and other waterbodies, and heavy trade-driven hunting. The IUCN Red List species accounts are living documents to be updated annually, and further information to refine listings is welcome. Keywords: conservation status, Critically Endangered, Data Deficient, Endangered, Extinct, global threat listing, Least Concern, Near Threatened, Vulnerable Introduction dae (skunks and stink-badgers; 12), Mustelidae (weasels, martens, otters, badgers and allies; 59), Nandiniidae (African Palm-civet The IUCN Red List of Threatened Species is the most authorita- Nandinia binotata; one), Prionodontidae ([Asian] linsangs; two), tive resource currently available on the conservation status of the Procyonidae (raccoons, coatis and allies; 14), and Viverridae (civ- world’s biodiversity. In recent years, the overall number of spe- ets, including oyans [= ‘African linsangs’]; 33). The data reported cies included on the IUCN Red List has grown rapidly, largely as on herein are freely and publicly available via the 2008 IUCN Red a result of ongoing global assessment initiatives that have helped List website (www.iucnredlist.org/mammals). -

Supplementary Material
Adaptation of mammalian myosin II sequences to body mass Mark N Wass*1, Sarah T Jeanfavre*1,2, Michael P Coghlan*1, Martin Ridout#, Anthony J Baines*3 and Michael A Geeves*3 School of Biosciences*, and School of Mathematics#, Statistics and Actuarial Science, University of Kent, Canterbury, UK 1. Equal contribution 2. Current address: Broad Institute, 415 Main Street, 7029-K, Cambridge MA 02142 3. Joint corresponding authors Key words: selection, muscle contraction, mammalian physiology, heart rate Address for correspondence: Prof M.A.Geeves School of Biosciences, University of Kent, Canterbury CT1 7NJ UK [email protected] tel 44 1227827597 Dr A J Baines School of Biosciences, University of Kent, Canterbury CT1 7NJ UK [email protected] tel 44 1227 823462 SUPPLEMENTARY MATERIAL Supplementary Table 1. Source of Myosin sequences and the mass of each species used in the analysis of Fig 1 & 2 Species Isoform Mass Skeletal Skeletal Embryonic Skeletal α- β-cardiac Perinatal Non- Non- Smooth Extraocular Slow (kg) 2d/x 2a 2b cardiac muscle A muscle B Muscle Tonic Human P12882 Q9UKX2 251757455 Q9Y623 P13533 P12883 P13535 P35579 219841954 13432177 110624781 599045671 68a Bonobo 675746236 397494570 675746242 675746226 397473260 397473262 675746209 675764569 675746138 675746206 675798456 45.5a Macaque 544497116 544497114 544497126 109113269 544446347 544446351 544497122 383408157 384940798 387541766 544497107 544465262 6.55b Tarsier 640786419 640786435 640786417 640818214 640818212 640786413 640796733 640805785 640786411 640822915 0.1315c -

3. Aonyx Congicus Red List 2020
Aonyx congicus - Lönnberg, 1910 ANIMALIA - CHORDATA - MAMMALIA - CARNIVORA - MUSTELIDAE - Aonyx - congicus Common Names: Congo Clawless Otter (English), Cameroon Clawless Otter (English), Kleinkrallen- Fingerotter (German), Kongo-Fingerotter (German), Loutre à joues blanches du Cameroun (French), Loutre à joues blanches du Congo (French), Nutria Inerme de Camerún (Spanish; Castilian), Paraonyx tacheté (French), Small-clawed Otter (English), Small-toothed Clawless Otter (English), Zaire Clawless Otter (English) Synonyms: No Synonyms Taxonomic Note: Allen (1924) and Davis (1978) treated A. capensis and A. congicus as being conspecific, arguing that they represent clinal variations of the same species. However, mainly based on tooth size and skin differences, Rosevear (1974), Van Zyll de Jong (1987), Wozencraft (1993), and Larivière (2001) considered A. capensis and A. congicus as separate species, but this remains debated, and Wozencraft (2005) did not retain A. congicus as a valid species, contrary to the opinion of the IUCN SSC Otter Specialist Group (www.otterspecialistgroup.org) (Jacques et al. 2009). The name Aonyx congica is often found in the literature but A. congicus is the correct spelling as Aonyx, from the Greek ‘onux’, is masculine (Van Bree et al. 1999). Red List Status NT, A3cde (IUCN version 3.1) Red List Assessment Assessment Information Date of Assessment: 31/01/2020 Reviewed: 27/02/2020 Assessor(s): Jacques, H., Reed-Smith, J., Davenport, L. & Somers, M.J. Reviewer(s): Hussain, S.A., Duplaix, N. Contributor(s): Hoffmann, M. Facilitators/Compilers: NA Assessment Rationale All of Africa's otter species are threatened by alteration and/or degradation of freshwater habitats and riparian vegetation which are the preferred settlements of human population. -

Pachychilon Pictum Region: 1 Taxonomic Authority: (Heckel & Kner, 1858) Synonyms: Common Names
Pachychilon pictum Region: 1 Taxonomic Authority: (Heckel & Kner, 1858) Synonyms: Common Names: Order: Cypriniformes Family: Cyprinidae Notes on taxonomy: General Information Biome Terrestrial Freshwater Marine Geographic Range of species: Habitat and Ecology Information: It is restricted to the Lake Skadar basin (Serbia-Montenegro) and to the It is a small cyprinid living in rivers as well as in lakes. Drin river basin including Lake Ohrid (Albania and FYROM). It is also recorded in the Aoos river bain in western Greece. In Italy was introduced in Serchio River and was found also in Lake Massaciuccoli were it is quite common, but still reported in this lake as Rutilus rubilio (P.G.Bianco pers. observ.). The species has commercial value in Lake Skadar, and is very frequent in the basin of Moraca River and in River Vijose in Albany which originate in Greece as River Aoos. It has also been introduced France. Conservation Measures: Threats: It is listed in the Appendix III of the Bern Convention. Habitat destruction (dams), water pollution. Species population information: Quite abundant (Freyhof, J. pers comm). Native - Native - Presence Presence Extinct Reintroduced Introduced Vagrant Country Distribution Confirmed Possible Country:Albania Country:France Country:Greece Country:Italy Country:Macedonia, the former Yugoslav Republ Country:Serbia and Montenegro Upper Level Habitat Preferences Score Lower Level Habitat Preferences Score 5.1 Wetlands (inland) - Permanent Rivers/Streams/Creeks 1 (includes waterfalls) 5.5 Wetlands (inland) - Permanent -

Atypicat Molecular Evolution of Afrotherian and Xenarthran B-Globin
Atypicat molecular evolution of afrotherian and xenarthran B-globin cluster genes with insights into the B-globin cluster gene organization of stem eutherians. By ANGELA M. SLOAN A thesis submitted to the Faculty of Graduate Studies in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE Department of Zoology University of Manitoba Winnipeg, Manitoba, Canada @ Angela M. Sloan, July 2005 TIIE I]MVERSITY OF' MANITOBA FACULTY OF GRADUATE STT]DIES ***** - COPYRIGHTPERMISSION ] . Atypical molecular evolution of afrotherian and xenarthran fslobin cluster genes with insights into thefglobin cluster gene organization òf stem eutherians. BY Angela M. Sloan A ThesislPracticum submitted to the Faculty of Graduate Studies of The University of Manitoba in partial fulfill¡nent of the requirement of the degree of Master of Science Angela M. Sloan @ 2005 Permission has been granted to the Library of the University of Manitoba to lend or sell copies of this thesis/practicum, to the National Library of Canada to microfilm this thesis and to lend or sell copies of the fiIm, and to University Microfïlms Inc. to publish an abstract of this thesis/practicum. This reproduction or copy of this thesis has been made available by authority of the copyright owner solely for the purpose of private study and research, and may only be reproduced and copied as permitted by copyright laws or with express written authorization from the copyright ownér. ABSTRACT Our understanding of p-globin gene cluster evolutionlwithin eutherian mammals .is based solely upon data collected from species in the two most derived eutherian superorders, Laurasiatheria and Euarchontoglires. Ifence, nothing is known regarding_the gene composition and evolution of this cluster within afrotherian (elephants, sea cows, hyraxes, aardvarks, elephant shrews, tenrecs and golden moles) and xenarthran (sloths, anteaters and armadillos) mammals.