Monte Carlo Approaches to Parameterized Poker Squares Todd W
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Daguerreian Annual 1990-2015: a Complete Index of Subjects
Daguerreian Annual 1990–2015: A Complete Index of Subjects & Daguerreotypes Illustrated Subject / Year:Page Version 75 Mark S. Johnson Editor of The Daguerreian Annual, 1997–2015 © 2018 Mark S. Johnson Mark Johnson’s contact: [email protected] This index is a work in progress, and I’m certain there are errors. Updated versions will be released so user feedback is encouraged. If you would like to suggest possible additions or corrections, send the text in the body of an email, formatted as “Subject / year:page” To Use A) Using Adobe Reader, this PDF can be quickly scrolled alphabetically by sliding the small box in the window’s vertical scroll bar. - or - B) PDF’s can also be word-searched, as shown in Figure 1. Many index citations contain keywords so trying a word search will often find other instances. Then, clicking these icons Figure 1 Type the word(s) to will take you to another in- be searched in this Adobe Reader Window stance of that word, either box. before or after. If you do not own the Daguerreian Annual this index refers you to, we may be able to help. Contact us at: [email protected] A Acuna, Patricia 2013: 281 1996: 183 Adams, Soloman; microscopic a’Beckett, Mr. Justice (judge) Adam, Hans Christian d’types 1995: 176 1995: 194 2002/2003: 287 [J. A. Whipple] Abbot, Charles G.; Sec. of Smithso- Adams & Co. Express Banking; 2015: 259 [ltr. in Boston Daily nian Institution deposit slip w/ d’type engraving Evening Transcript, 1/7/1847] 2015: 149–151 [letters re Fitz] 2014: 50–51 Adams, Zabdiel Boylston Abbott, J. -

Reality Is Broken a Why Games Make Us Better and How They Can Change the World E JANE Mcgonigal
Reality Is Broken a Why Games Make Us Better and How They Can Change the World E JANE McGONIGAL THE PENGUIN PRESS New York 2011 ADVANCE PRAISE FOR Reality Is Broken “Forget everything you know, or think you know, about online gaming. Like a blast of fresh air, Reality Is Broken blows away the tired stereotypes and reminds us that the human instinct to play can be harnessed for the greater good. With a stirring blend of energy, wisdom, and idealism, Jane McGonigal shows us how to start saving the world one game at a time.” —Carl Honoré, author of In Praise of Slowness and Under Pressure “Reality Is Broken is the most eye-opening book I read this year. With awe-inspiring ex pertise, clarity of thought, and engrossing writing style, Jane McGonigal cleanly exploded every misconception I’ve ever had about games and gaming. If you thought that games are for kids, that games are squandered time, or that games are dangerously isolating, addictive, unproductive, and escapist, you are in for a giant surprise!” —Sonja Lyubomirsky, Ph.D., professor of psychology at the University of California, Riverside, and author of The How of Happiness: A Scientific Approach to Getting the Life You Want “Reality Is Broken will both stimulate your brain and stir your soul. Once you read this remarkable book, you’ll never look at games—or yourself—quite the same way.” —Daniel H. Pink, author of Drive and A Whole New Mind “The path to becoming happier, improving your business, and saving the world might be one and the same: understanding how the world’s best games work. -

Download Booklet
preMieRe Recording jonathan dove SiReNSONG CHAN 10472 siren ensemble henk guittart 81 CHAN 10472 Booklet.indd 80-81 7/4/08 09:12:19 CHAN 10472 Booklet.indd 2-3 7/4/08 09:11:49 Jonathan Dove (b. 199) Dylan Collard premiere recording SiReNSong An Opera in One Act Libretto by Nick Dear Based on the book by Gordon Honeycombe Commissioned by Almeida Opera with assistance from the London Arts Board First performed on 14 July 1994 at the Almeida Theatre Recorded live at the Grachtenfestival on 14 and 1 August 007 Davey Palmer .......................................... Brad Cooper tenor Jonathan Reed ....................................... Mattijs van de Woerd baritone Diana Reed ............................................. Amaryllis Dieltiens soprano Regulator ................................................. Mark Omvlee tenor Captain .................................................... Marijn Zwitserlood bass-baritone with Wireless Operator .................................... John Edward Serrano speaker Siren Ensemble Henk Guittart Jonathan Dove CHAN 10472 Booklet.indd 4-5 7/4/08 09:11:49 Siren Ensemble piccolo/flute Time Page Romana Goumare Scene 1 oboe 1 Davey: ‘Dear Diana, dear Diana, my name is Davey Palmer’ – 4:32 48 Christopher Bouwman Davey 2 Diana: ‘Davey… Davey…’ – :1 48 clarinet/bass clarinet Diana, Davey Michael Hesselink 3 Diana: ‘You mention you’re a sailor’ – 1:1 49 horn Diana, Davey Okke Westdorp Scene 2 violin 4 Diana: ‘i like chocolate, i like shopping’ – :52 49 Sanne Hunfeld Diana, Davey cello Scene 3 Pepijn Meeuws 5 -

The Penguin Book of Card Games
PENGUIN BOOKS The Penguin Book of Card Games A former language-teacher and technical journalist, David Parlett began freelancing in 1975 as a games inventor and author of books on games, a field in which he has built up an impressive international reputation. He is an accredited consultant on gaming terminology to the Oxford English Dictionary and regularly advises on the staging of card games in films and television productions. His many books include The Oxford History of Board Games, The Oxford History of Card Games, The Penguin Book of Word Games, The Penguin Book of Card Games and the The Penguin Book of Patience. His board game Hare and Tortoise has been in print since 1974, was the first ever winner of the prestigious German Game of the Year Award in 1979, and has recently appeared in a new edition. His website at http://www.davpar.com is a rich source of information about games and other interests. David Parlett is a native of south London, where he still resides with his wife Barbara. The Penguin Book of Card Games David Parlett PENGUIN BOOKS PENGUIN BOOKS Published by the Penguin Group Penguin Books Ltd, 80 Strand, London WC2R 0RL, England Penguin Group (USA) Inc., 375 Hudson Street, New York, New York 10014, USA Penguin Group (Canada), 90 Eglinton Avenue East, Suite 700, Toronto, Ontario, Canada M4P 2Y3 (a division of Pearson Penguin Canada Inc.) Penguin Ireland, 25 St Stephen’s Green, Dublin 2, Ireland (a division of Penguin Books Ltd) Penguin Group (Australia) Ltd, 250 Camberwell Road, Camberwell, Victoria 3124, Australia -

Catalogue of Books and Monographs
Catalogue of Books and Monographs (last updated Nov 2006) The Archaeological Sites and Monuments of Scotland. Edinburgh, RCAHMS. Doon Hill: 3 diagrams of structures: 1) two structures, 2) area (with pencil marks) 3) halls A and B. Dumbarton Publication Drawings: 1) Description of illustrations 2) 16 diagrams and maps (4 maps of Scotland, rest diagrams (some cross-section). Kinnelhead and Drannandow: Maps of Kinnelhead sites (1-4, 6) and Drannandow (5, 7), with natural features, structures. Paper, some sellotaped together and fragile. North of Scotland Archaeological Services. Round House & Compass Circles: 2 diagrams 1) on left has concentric circles, probably done with compass, with numbers 2) on right plan of Round house (?) P2 with numbers and word 'Deu . ' (1923). A guide to the Anglo-Saxon and foreign teutonic antiquities in the Department of British and Mediaeval Antiquities. London, British Museum. (1925). A guide to antiquities of the early Iron Age in the Department of British and Medieval Antiquities. Oxford, Oxford University Press for the British Museum. (1926). A guide to antiquities of the Stone Age in the Department of British and Mediaeval Antiquities. Oxford, Oxford University Press for the British Museum. (1927). London and the Vikings. London. (1936). Proceedings of the Warrington Literary and Philosophical Society 1933-1936. Warrington, John Walker & Co. Ltd. (1937). The Archeological Journal. London, Royal Archaeological Institute of Great Britain and Ireland. 94 (XCIV). (1940). Medieval catalogue. London, The London Museum. (1947). Field Archaeology. Some Notes for Beginners issued by the Ordnance Survey. London, HMSO. (1947). The Sutton Hoo Ship-Burial. A Provisional Guide. London, Trustees of the British Museum. -

Journal of Research in Innovative Teaching
Journal of Research in Innovative Teaching Volume 6, Issue 1, March 2013 Publication of National University La Jolla, CA USA Editorial Board Dr. Jerry Lee, Executive Editor Dr. Peter Serdyukov, Editor-in-Chief Dr. Eileen Heveron, Member Dr. Robyn Hill, Member Dr. David Smith, Member Dr. Carl Boggs, Member Dr. Igor Subbotin, Member Dr. Mohammad Amin, Member Dr. C. Kalani Beyer, Pacific Oaks College, California, Member Dr. Hermann Maurer, University of Graz, Austria, Member Dr. Piet Kommers, University of Twente, The Netherlands, Member Review Board Dr. Patrick Papin, San Diego State University, California Dr. Dale Glaser, San Diego State University, California Dr. Eduardo Jesús Arismendi-Pardi, Obelus Educational Services, LLC, California Dr. Darrel J. Mitry, Norwich University, Vermont Dr. M. A. Alim, A & M University, Alabama Dr. Richard P. Long, Columbus State University, Ohio Dr. Sharon Bratt, Simon Fraser University, Canada Dr. Marcos Turqueti, Creative Electron, California Dr. Jacquline Spacek, District Superintendent (retired), California Dr. Susan Jindra, California State University, San Bernardino, California Dr. Cynthia Schubert-Irastorza, National University Dr. Dee Fabry, National University Dr. Ron Germaine, National University Dr. Jodi Reeves, National University Dr. Charles Tatum, National University Dr. Wayne Padover, National University and all members of the Editorial Board Copyright © 2013 National University All rights reserved. No part of this publication may be reproduced or distributed in any form or by any means, or stored in a database or retrieval system, without the prior written permission of the publisher, except as permitted under the United States Copyright Act of 1976. ISSN 1947-1017 When referring to this publication, please use the following: Name, (2013), title. -

A Survey of Monte Carlo Tree Search Methods
IEEE TRANSACTIONS ON COMPUTATIONAL INTELLIGENCE AND AI IN GAMES, VOL. 4, NO. 1, MARCH 2012 1 A Survey of Monte Carlo Tree Search Methods Cameron Browne, Member, IEEE, Edward Powley, Member, IEEE, Daniel Whitehouse, Member, IEEE, Simon Lucas, Senior Member, IEEE, Peter I. Cowling, Member, IEEE, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis and Simon Colton Abstract—Monte Carlo Tree Search (MCTS) is a recently proposed search method that combines the precision of tree search with the generality of random sampling. It has received considerable interest due to its spectacular success in the difficult problem of computer Go, but has also proved beneficial in a range of other domains. This paper is a survey of the literature to date, intended to provide a snapshot of the state of the art after the first five years of MCTS research. We outline the core algorithm’s derivation, impart some structure on the many variations and enhancements that have been proposed, and summarise the results from the key game and non-game domains to which MCTS methods have been applied. A number of open research questions indicate that the field is ripe for future work. Index Terms—Monte Carlo Tree Search (MCTS), Upper Confidence Bounds (UCB), Upper Confidence Bounds for Trees (UCT), Bandit-based methods, Artificial Intelligence (AI), Game search, Computer Go. F 1 INTRODUCTION ONTE Carlo Tree Search (MCTS) is a method for M finding optimal decisions in a given domain by taking random samples in the decision space and build- ing a search tree according to the results. It has already had a profound impact on Artificial Intelligence (AI) approaches for domains that can be represented as trees of sequential decisions, particularly games and planning problems. -

JAM-BOX Retro PACK 16GB AMSTRAD
JAM-BOX retro PACK 16GB BMX Simulator (UK) (1987).zip BMX Simulator 2 (UK) (19xx).zip Baby Jo Going Home (UK) (1991).zip Bad Dudes Vs Dragon Ninja (UK) (1988).zip Barbarian 1 (UK) (1987).zip Barbarian 2 (UK) (1989).zip Bards Tale (UK) (1988) (Disk 1 of 2).zip Barry McGuigans Boxing (UK) (1985).zip Batman (UK) (1986).zip Batman - The Movie (UK) (1989).zip Beachhead (UK) (1985).zip Bedlam (UK) (1988).zip Beyond the Ice Palace (UK) (1988).zip Blagger (UK) (1985).zip Blasteroids (UK) (1989).zip Bloodwych (UK) (1990).zip Bomb Jack (UK) (1986).zip Bomb Jack 2 (UK) (1987).zip AMSTRAD CPC Bonanza Bros (UK) (1991).zip 180 Darts (UK) (1986).zip Booty (UK) (1986).zip 1942 (UK) (1986).zip Bravestarr (UK) (1987).zip 1943 (UK) (1988).zip Breakthru (UK) (1986).zip 3D Boxing (UK) (1985).zip Bride of Frankenstein (UK) (1987).zip 3D Grand Prix (UK) (1985).zip Bruce Lee (UK) (1984).zip 3D Star Fighter (UK) (1987).zip Bubble Bobble (UK) (1987).zip 3D Stunt Rider (UK) (1985).zip Buffalo Bills Wild West Show (UK) (1989).zip Ace (UK) (1987).zip Buggy Boy (UK) (1987).zip Ace 2 (UK) (1987).zip Cabal (UK) (1989).zip Ace of Aces (UK) (1985).zip Carlos Sainz (S) (1990).zip Advanced OCP Art Studio V2.4 (UK) (1986).zip Cauldron (UK) (1985).zip Advanced Pinball Simulator (UK) (1988).zip Cauldron 2 (S) (1986).zip Advanced Tactical Fighter (UK) (1986).zip Championship Sprint (UK) (1986).zip After the War (S) (1989).zip Chase HQ (UK) (1989).zip Afterburner (UK) (1988).zip Chessmaster 2000 (UK) (1990).zip Airwolf (UK) (1985).zip Chevy Chase (UK) (1991).zip Airwolf 2 (UK) -
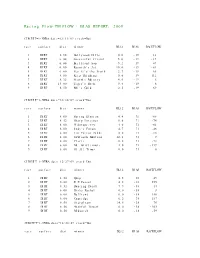
Racing Flow-TM FLOW + BIAS REPORT: 2009
Racing Flow-TM FLOW + BIAS REPORT: 2009 CIRCUIT=1-NYRA date=12/31/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 5.50 Hollywood Hills 0.0 -19 13 2 DIRT 6.00 Successful friend 5.0 -19 -19 3 DIRT 6.00 Brilliant Son 5.2 -19 47 4 DIRT 6.00 Raynick's Jet 10.6 -19 -61 5 DIRT 6.00 Yes It's the Truth 2.7 -19 65 6 DIRT 8.00 Keep Thinking 0.0 -19 -112 7 DIRT 8.32 Storm's Majesty 4.0 -19 6 8 DIRT 13.00 Tiger's Rock 9.4 -19 6 9 DIRT 8.50 Mel's Gold 2.5 -19 69 CIRCUIT=1-NYRA date=12/30/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 8.00 Spring Elusion 4.4 71 -68 2 DIRT 8.32 Sharp Instinct 0.0 71 -74 3 DIRT 6.00 O'Sotopretty 4.0 71 -61 4 DIRT 6.00 Indy's Forum 4.7 71 -46 5 DIRT 6.00 Ten Carrot Nikki 0.0 71 -18 6 DIRT 8.00 Sawtooth Moutain 12.1 71 9 7 DIRT 6.00 Cleric 0.6 71 -73 8 DIRT 6.00 Mt. Glittermore 4.0 71 -119 9 DIRT 6.00 Of All Times 0.0 71 0 CIRCUIT=1-NYRA date=12/27/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 8.50 Quip 4.5 -38 49 2 DIRT 6.00 E Z Passer 4.2 -38 255 3 DIRT 8.32 Dancing Daisy 7.9 -38 14 4 DIRT 6.00 Risky Rachel 0.0 -38 8 5 DIRT 6.00 Kaffiend 0.0 -38 150 6 DIRT 6.00 Capridge 6.2 -38 187 7 DIRT 8.50 Stargleam 14.5 -38 76 8 DIRT 8.50 Wishful Tomcat 0.0 -38 -203 9 DIRT 8.50 Midwatch 0.0 -38 -59 CIRCUIT=1-NYRA date=12/26/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 6.00 Papaleo 7.0 108 129 2 DIRT 6.00 Overcommunication 1.0 108 -72 3 DIRT 6.00 Digger 0.0 108 -211 4 DIRT 6.00 Bryan Kicks 0.0 108 136 5 DIRT 6.00 We Get It 16.8 108 129 6 DIRT 6.00 Yawanna Trust 4.5 108 -21 7 DIRT 6.00 Smarty Karakorum 6.5 108 83 8 DIRT 8.32 Almighty Silver 18.7 108 133 9 DIRT 8.32 Offlee Cool 0.0 108 -60 CIRCUIT=1-NYRA date=12/13/09 track=Dot race surface dist winner BL12 BIAS RACEFLOW 1 DIRT 8.32 Crafty Bear 3.0 -158 -139 2 DIRT 6.00 Cheers Darling 0.5 -158 61 3 DIRT 6.00 Iberian Gate 3.0 -158 154 4 DIRT 6.00 Pewter 0.5 -158 8 5 DIRT 6.00 Wolfson 6.2 -158 86 6 DIRT 6.00 Mr. -

THE POLITICAL PHILOSOPHY of JEAN-JACQUES ROUSSEAU the Impossibilityof Reason
qvortrup.cov 2/9/03 12:29 pm Page 1 Was Rousseau – the great theorist of the French Revolution – really a Conservative? THE POLITICAL PHILOSOPHY OF JEAN-JACQUES ROUSSEAU This original study argues that the author of The Social Contract was a constitutionalist much closer to Madison, Montesquieu and Locke than to revolutionaries. Outlining his profound opposition to Godless materialism and revolutionary change, this book finds parallels between Rousseau and Burke, as well as showing that Rousseau developed the first modern theory of nationalism. The book presents an inte- grated political analysis of Rousseau’s educational, ethical, religious and political writings. The book will be essential readings for students of politics, philosophy and the history of ideas. ‘No society can survive without mutuality. Dr Qvortrup’s book shows that rights and responsibilities go hand in hand. It is an excellent primer for any- one wishing to understand how renewal of democracy hinges on a strong civil society’ The Rt. Hon. David Blunkett, MP ‘Rousseau has often been singled out as a precursor of totalitarian thought. Dr Qvortrup argues persuasively that Rousseau was nothing of the sort. Through an array of chapters the book gives an insightful account of Rousseau’s contribution to modern philosophy, and how he inspired individuals as diverse as Mozart, Tolstoi, Goethe, and Kant’ John Grey, Professor of European Political Thought,LSE ‘Qvortrup has written a highly readable and original book on Rousseau. He approaches the subject of Rousseau’s social and political philosophy with an attractively broad vision of Rousseau’s thought in the context of the development of modernity, including our contemporary concerns. -

Biography of Sismondi
1 BIOGRAPHY OF SISMONDI HELMUT O. PAPPE I. Jean Charles Léonard Simonde was born on the 9th May 1773 into a Genevan family. In later life he changed his family to de Sismondi after an old Pisan aristocratic family from which he believed the Simondis to be descended. Charles’s parents were the pasteur Gèdèon François Simonde and his wife Henriette Ester Gabriele Girodz; a sister, Sara, called Serina by the family and her friends, saw the light of day two years later. The families of both parents were du haut the Simondes being on the borderline between nobility and upper bourgeoisie, the Girodz being members of the well-to-do upper bourgeoisie. Both the Simondes and the Girodz had come to Geneva as members of the second éimgration after the revocation of the Edict of Nantes in 1685, that is, both families were Protestant fugitives from religious persecution in France. The Girodz had come to Geneva from Chàlons-sur-Saône in 1689. Henriette’s father, Pierre Girodz, became a successful and highly respected businessman engaged in various commercial enterprises connected with the watchmaking trade. He owned a substantial town house close to the cathedral in the Bourg-de-Four and an imposing country seat ‘Tourant’ at Chênes, both to be the residences of Sismondi after his return from exile in Italy. On the occasion of the marriage of his daughter on the 12th January 1770 Pierre Girodz was able to give her a dowry his town house worth 30,000 Livres as well as 10,000 Livres in cash and 2,000 Livres worth of jewellery. -

\0-9\0 and X ... \0-9\0 Grad Nord ... \0-9\0013 ... \0-9\007 Car Chase ... \0-9\1 X 1 Kampf ... \0-9\1, 2, 3
... \0-9\0 and X ... \0-9\0 Grad Nord ... \0-9\0013 ... \0-9\007 Car Chase ... \0-9\1 x 1 Kampf ... \0-9\1, 2, 3 ... \0-9\1,000,000 ... \0-9\10 Pin ... \0-9\10... Knockout! ... \0-9\100 Meter Dash ... \0-9\100 Mile Race ... \0-9\100,000 Pyramid, The ... \0-9\1000 Miglia Volume I - 1927-1933 ... \0-9\1000 Miler ... \0-9\1000 Miler v2.0 ... \0-9\1000 Miles ... \0-9\10000 Meters ... \0-9\10-Pin Bowling ... \0-9\10th Frame_001 ... \0-9\10th Frame_002 ... \0-9\1-3-5-7 ... \0-9\14-15 Puzzle, The ... \0-9\15 Pietnastka ... \0-9\15 Solitaire ... \0-9\15-Puzzle, The ... \0-9\17 und 04 ... \0-9\17 und 4 ... \0-9\17+4_001 ... \0-9\17+4_002 ... \0-9\17+4_003 ... \0-9\17+4_004 ... \0-9\1789 ... \0-9\18 Uhren ... \0-9\180 ... \0-9\19 Part One - Boot Camp ... \0-9\1942_001 ... \0-9\1942_002 ... \0-9\1942_003 ... \0-9\1943 - One Year After ... \0-9\1943 - The Battle of Midway ... \0-9\1944 ... \0-9\1948 ... \0-9\1985 ... \0-9\1985 - The Day After ... \0-9\1991 World Cup Knockout, The ... \0-9\1994 - Ten Years After ... \0-9\1st Division Manager ... \0-9\2 Worms War ... \0-9\20 Tons ... \0-9\20.000 Meilen unter dem Meer ... \0-9\2001 ... \0-9\2010 ... \0-9\21 ... \0-9\2112 - The Battle for Planet Earth ... \0-9\221B Baker Street ... \0-9\23 Matches ..