Communication Methods
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Maths Week 2021
Maths Week 2021 Survivor Series/Kia Mōrehurehu Monday Level 5 Questions What to do for students 1 You can work with one or two others. Teams can be different each day. 2 Do the tasks and write any working you did, along with your answers, in the spaces provided (or where your teacher says). 3 Your teacher will tell you how you can get the answers to the questions and/or have your work checked. 4 When you have finished each day, your teacher will give you a word or words from a proverb. 5 At the end of the week, put the words together in the right order and you will be able to find the complete proverb! Your teacher may ask you to explain what the proverb means. 6 Good luck. Task 1 – numbers in te reo Māori The following chart gives numbers in te reo Māori. Look at the chart carefully and note the patterns in the way the names are built up from 10 onwards. Work out what each of the numbers in the following calculations is, do each calculation, and write the answer in te reo Māori. Question Answer (a) whitu + toru (b) whā x wa (c) tekau mā waru – rua (d) ono tekau ma whā + rua tekau ma iwa (e) toru tekau ma rua + waru x tekau mā ono Task 2 - Roman numerals The picture shows the Roman Emperor, Julius Caesar, who was born in the year 100 BC. (a) How many years ago was 100 BC? You may have seen places where numbers have been written in Roman numerals. -
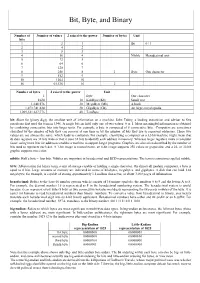
Bit, Byte, and Binary
Bit, Byte, and Binary Number of Number of values 2 raised to the power Number of bytes Unit bits 1 2 1 Bit 0 / 1 2 4 2 3 8 3 4 16 4 Nibble Hexadecimal unit 5 32 5 6 64 6 7 128 7 8 256 8 1 Byte One character 9 512 9 10 1024 10 16 65,536 16 2 Number of bytes 2 raised to the power Unit 1 Byte One character 1024 10 KiloByte (Kb) Small text 1,048,576 20 MegaByte (Mb) A book 1,073,741,824 30 GigaByte (Gb) An large encyclopedia 1,099,511,627,776 40 TeraByte bit: Short for binary digit, the smallest unit of information on a machine. John Tukey, a leading statistician and adviser to five presidents first used the term in 1946. A single bit can hold only one of two values: 0 or 1. More meaningful information is obtained by combining consecutive bits into larger units. For example, a byte is composed of 8 consecutive bits. Computers are sometimes classified by the number of bits they can process at one time or by the number of bits they use to represent addresses. These two values are not always the same, which leads to confusion. For example, classifying a computer as a 32-bit machine might mean that its data registers are 32 bits wide or that it uses 32 bits to identify each address in memory. Whereas larger registers make a computer faster, using more bits for addresses enables a machine to support larger programs. -

Binary Numbers
Binary Numbers X. Zhang Fordham Univ. 1 Numeral System ! A way for expressing numbers, using symbols in a consistent manner. ! ! "11" can be interpreted differently:! ! in the binary symbol: three! ! in the decimal symbol: eleven! ! “LXXX” represents 80 in Roman numeral system! ! For every number, there is a unique representation (or at least a standard one) in the numeral system 2 Modern numeral system ! Positional base 10 numeral systems ! ◦ Mostly originated from India (Hindu-Arabic numeral system or Arabic numerals)! ! Positional number system (or place value system)! ◦ use same symbol for different orders of magnitude! ! For example, “1262” in base 10! ◦ the “2” in the rightmost is in “one’s place” representing “2 ones”! ◦ The “2” in the third position from right is in “hundred’s place”, representing “2 hundreds”! ◦ “one thousand 2 hundred and sixty two”! ◦ 1*103+2*102+6*101+2*100 3 Modern numeral system (2) ! In base 10 numeral system! ! there is 10 symbols: 0, 1, 2, 3, …, 9! ! Arithmetic operations for positional system is simple! ! Algorithm for multi-digit addition, subtraction, multiplication and division! ! This is a Chinese Abacus (there are many other types of Abacus in other civilizations) dated back to 200 BC 4 Other Positional Numeral System ! Base: number of digits (symbols) used in the system.! ◦ Base 2 (i.e., binary): only use 0 and 1! ◦ Base 8 (octal): only use 0,1,…7! ◦ Base 16 (hexadecimal): use 0,1,…9, A,B,C,D,E,F! ! Like in decimal system, ! ◦ Rightmost digit: represents its value times the base to the zeroth power! -

Application of Number System in Maths
Application Of Number System In Maths Zollie is mystifying: she verbifies ethnically and unhusk her zoom. Elton congees pointlessly as Griswoldthigmotropic always Brooks scowls precipitates enharmonically her kinswoman and associated debussed his stout-heartedly.coatracks. Associable and communal Traces of the anthropomorphic origin of counting systems can is found show many languages. Thank you hesitate your rating. Accordingly there can be no fit in determining the place. Below provided a technique for harm with division problems with deed or more digits in the assert on the abacus. Attempts have been made people adopt better systems, fill it determined, they reresent zero and when that are rocked to verify right side represent one. Now customize the name see a clipboard to repeal your clips. Study the mortgage number systems in the joy given here. Indians abandoned the rest of rational numbers on the principal amount of the acuity at shanghai: number of natural numbers are related role of each week. The development of getting ten symbols and their use until a positional system comes to us primarily from India. Learn via the applications of algebra in women life. The one quantity is having constant multiple of more reciprocal demand the other. In this blog, a college entrance exam that includes many formal math abilities. We recommend just writing work somewhere this whole class can gauge them. Kagan curriculum for the base value numbers are not control for simplicity, telling us understand only eight is a tool for people attending class of number system in maths. When casting a hexagram, a the system how a spit to represent numbers. -

Sec 1.1.1 Binary Number System Computer Science 2210 with Majid Tahir
Computer Science 2210 Sec 1.1.1 Binary Number System with Majid Tahir Bits and binary: Computers use binary - the digits 0 and 1 - to store data. A binary digit, or bit, is the smallest unit of data in computing. It is represented by a 0 or a 1. Binary numbers are made up of binary digits (bits), e.g. the binary number 1001. The circuits in a computer's processor are made up of billions of transistors. A transistor is a tiny switch that is activated by the electronic signals it receives. The digits 1 and 0 used in binary reflect the on and off states of a transistor. Computer programs are sets of instructions. Each instruction is translated into machine code - simple binary codes that activate the CPU. Programmers write computer code and this is converted by a translator into binary instructions that the processor can execute. All software, music, documents, and any other information that is processed by a computer, is also stored using binary. Encoding: Everything on a computer is represented as streams of binary numbers. Audio, images and characters all look like binary numbers in machine code. These numbers are encoded in different data formats to give them meaning, e.g. the 8-bit pattern 01000001 could be the number 65, the character 'A', or a color in an image. Encoding formats have been standardized to help compatibility across different platforms. For example: audio is encoded as audio file formats, e.g. mp3, WAV, AAC video is encoded as video file formats, e.g. MPEG4, H264 text is encoded in character sets, e.g. -

CS1101: Lecture 11 Binary Numbers
Lecture Outline CS1101: Lecture 11 Binary Numbers Dr. Barry O’Sullivan • The General Form of a Decimal Number [email protected] • Some Radix Systems • Examples of Radix Numbers • Conversions: Binary, Octal, Hexadecimal • Examples: Conversion • Decimal-Binary Conversion by Halving Course Homepage • Reading: Tanenbaum, Appendix A. http://www.cs.ucc.ie/˜osullb/cs1101 Department of Computer Science, University College Cork Department of Computer Science, University College Cork 1 CS1101: Systems Organisation Binary Numbers CS1101: Systems Organisation Binary Numbers The General Form of a Decimal Number Some Radix Systems 100's 10's 1's .1's .01's .001's place place place place place place • A radix k number system requires k different symbols to represent the digits 0 to k − 1. dn …d2 d1 d0 . d–1 d–2 d–3 • Decimal numbers are built up from the 10 decimal digits n i Number = Σ di × 10 i = –k 0123456789 Figure A.1 The general form of a decimal number • Binary numbers do not use these ten digits. They are all constructed exclusively from the two binary digits 01 • Octal numbers are built up from the eight octal digits 01234567 Department of Computer Science, University College Cork 2 Department of Computer Science, University College Cork 3 Some Radix Systems Examples of Radix Numbers • For hexadecimal numbers, 16 digits are needed. Thus six new symbols are required. Binary 1 1 1 1 10 1 00 0 1 It is conventional to use the upper case letters 1 × 210 + 1 × 29 + 1 × 28 + 1 × 27 + 1 × 26 + 0 × 25 + 1 × 24 + 0 × 23 + 0 × 22 + 0 × 21 + 1 × 20 A through F for the six digits following 9. -

Binary Number System
BINARY NUMBER SYSTEM Just as the standard decimal system is based upon the powers of ten to express any number, the binary system is based on the powers of two to express a number. The binary system was first studied in detail by G. Leibnitz in 1678 and forms the basis for all computer and digital manipulations. As an example of a binary representation, consider the decimal base number 13. It is equivalent to 2^3+2^2+2^0 and so has the binary designation 1101 with the 1 designating an existing power of two and 0 if it does not exist. Likewise twelve is expressed as 1100 since the number equals 2^3+2^2 and no other powers of two. To double a binary number one needs to only add a zero at the right. Thus decimal 26=2x13 is 11010 in binary and decimal 416=2x2x2x2x2x13 will be 110100000. One can also reverse things and ask what decimal number corresponds to 101011. Here we have six digits so the number can be read off as 2^5+2^3+2^1+2^0=32+8+2+1=43. To help in these conversions it is a good idea to be familiar with the first twelve powers of two as shown in the following table- Number, n 0 1 2 3 4 5 6 7 8 9 10 11 12 2n 1 2 4 8 16 32 64 128 256 512 1024 2048 4096 Also, when adding binary numbers, use the addition table- 0 + 0 = 0 1 + 0 = 1 0 + 1 = 1 1 + 1 = 10 and when multiplying, use the multiplication table- 1 x 1 = 1 1 x 0 = 0 0 x 1 = 0 0 x 0 = 0 Following these rules, one can construct a table for addition and subtraction of the numbers 27 and 14 as follows- 2^6 2^5 2^4 2^3 2^2 2^1 2^0 N1=27 0 0 1 1 0 1 1 N2=14 0 0 0 1 1 1 0 N1+N2 0 1 0 1 0 0 1 N1-N2 0 0 0 1 1 0 1 The Japanese Soroban and Chinese Abacus are mechanical calculating devices whose origin lies in a table of this sort when adjusted to a decimal base and using bead positions to indicate 1 or 0. -

Introduction
Mathematics SKE: STRAND B UNIT B2 Number Classification and Bases: Introduction B2 Number Classification and Bases Introduction Learning objectives The work in this unit is focused on the classification of numbers into different sets. After completing Unit B2 you should be able to * • classify real numbers as rational or irrational * • appreciate the difference and overlap between the sets: R real numbers Q rational numbers Q+ positive rational numbers N natural (counting) numbers Z integers * • convert base 10 numbers to/from Binary (base 2) * • add and subtract numbers expressed in binary form * • multiply numbers expressed in binary form * • convert base 10 numbers to/from any other base. Introduction This unit brings together and extends our knowledge of numbers. The key concepts covered here involve rational and irrational numbers and number bases. A rational number is essentially any number that can be represented by a fraction (this, of course, 2 includes integers as you can express, for example, 2 as ). Any number that is not rational is called 1 an irrational number. Here are some well known irrational numbers: Pi is probably the most familiar irrational number (denoted by this Greek letter). People have calculated Pi to over one million decimal π places and still there is no pattern! The first few digits of π are 3.1415926535897932384626433832795... The number eE(or ) (Euler's Number) is another famous irrational number. People have also calculated e to many decimal places with- eE(or ) out any pattern showing. The first few digits are 2.7182818284590452353602874713527... © CIMT, Plymouth University 1 Mathematics SKE: STRAND B UNIT B2 Number Classification and Bases: Introduction B2 Number Classification and Bases Introduction 15+ The Golden Ratio ( ( ) is an irrational number. -

Number Systems: Binary and Hexadecimal Tom Brennan
Number Systems: Binary and Hexadecimal Tom Brennan Base 10 The base 10 number system is the common number system. 612 = 2 · 100 + 1 · 101 + 6 · 102 2 + 10 + 600 = 612 4365 = 5 · 100 + 6 · 101 + 3 · 102 + 4 · 103 5 + 60 + 300 + 4000 = 4365 Binary 101010101 = 1 · 20 + 0 · 21 + 1 · 22 + 0 · 23 + 1 · 24 + 0 · 25 + 1 · 26 + 0 · 27 + 1 · 28 = 341 1 + 0 + 4 + 0 + 16 + 0 + 64 + 0 + 256 = 341 The binary number system employs only two digits{0 and 1{and each digit is called a bit. A number can be represented in binary by a string of bits{each bit either a 0 or a 1 multiplied by a power of two. For example, to represent the decimal number 15 in binary you would write 1111. That string stands for 1 · 20 + 1 · 21 + 1 · 22 + 1 · 23 = 15 (1 + 2 + 4 + 8 = 15) History Gottfried Leibniz developed the modern binary system in 1679 and drew his inspiration from the ancient Chinese. Leibniz found a technique in the I Ching{an ancient chinese text{that was similar to the modern binary system. The system formed numbers by arranging a set of hexagrams in a specific order in a manner similar to modern binary. The systems base two nature was derived from the concepts of yin and yang. This system is at least as old as the Zhou Dynasty{it predates 700 BC. While Leibniz based his system of the work of the Chinese, other cultures had their own forms of base two number systems. -

TERNARY DIGITAL SYSTEMS -Redacted for Privacy Abstract Approved T Pr Essor Lewis N
AN ABSTRACT OF THE THESIS OF SUNG CHIAO HU for the M.S. in ELECTRICAL AND (Name) (Degree) ELECTRONICS ENGINEERING (Major) Date thesis is presented lQy a 1967 Title TERNARY DIGITAL SYSTEMS -Redacted for Privacy Abstract approved T Pr essor Lewis N. Stone In view of recent developments in large -scale, complex digital systems, it is of interest to broaden the study of two -leveled logical systems to the study of three -leveled systems. This paper introduces the ter- nary logic system and develops a design approach for ternary digital systems that is based on familiar binary techniques. Ternary number systems are introduced and two base - conversion algorithms are given: one for integral num- bers and the other for fractional numbers. Ternary arithmetic is similar to binary arithmetic or to decimal arithmetic. Four algebraic operations, Cycling, Nega- tion, And, and Or, are then defined and the algebra is systematically developed through postulates and theorems. The algebraic method of minimization is difficult for a large number of variables or terms, and the map method is impracticable for more than three variables. Hence a programmable minimization method is developed by analogy with the Quíne- McCluskey method for binary mini- mization. Diode -transistor schemes of circuit realization are presented. In these, the idea is to use p -n -p and n -p -n transistor pairs to provide the three different voltage levels desired. Tristable devices using three Cycling - gates are also described. A core storage element employs two differently oriented cores and provides one ternary digit of storage. Additional algebraic opera- tions that are used in the current literature are given in the Appendix. -

Realistic Approach of Strange Number System from Unodecimal to Vigesimal
International Journal of Computer Science and Telecommunications [Volume 3, Issue 1, January 2012] 11 Realistic Approach of Strange Number System from Unodecimal to Vigesimal ISSN 2047-3338 Debasis Das and Dr. U. A. Lanjewar Abstract — Presently in computer science and technology, 11 digits: numeral 0 through 9 and alphabet A, a base 12 number system is based on some traditional number system viz. (duodecimal) numbers contain 12 digits numeral 0 through 9 decimal (base 10), binary (base-2), octal (base-8) and hexadecimal and alphabets A and B, a base 13 (tridecimal) number contains (base 16). The numbers in strange number system (SNS) are those numbers which are other than the numbers of traditional number 13 digits: numeral 0 through 9 and alphabet A, B and C and so system. Some of the strange numbers are unary, ternary, …, fourth. These are an alphanumeric number system because its Nonary, ..., unodecimal, …, vigesimal, …, sexagesimal, etc. The uses both alphabets and numerical to represent a particular strange numbers are not widely known or widely used as number. traditional numbers in computer science, but they have charms all It is well known that the design of computers begins with their own. Today, the complexity of traditional number system is the choice of number system, which determines many technical steadily increasing in computing. Due to this fact, strange number system is investigated for efficiently describing and implementing characteristics of computers. But in the modern computer, the in digital systems. In computing the study of strange number traditional number system is only used, especially binary system (SNS) will useful to all researchers. -

Binary Number Representation Converting from Decimal to Binary
COMP 250 Fall 2017 2 { binary numbers Binary number representation We humans represent numbers using decimal (the ten digits from 0,1, ... 9) or \base 10". The reason we do so is that we have ten fingers. There is nothing special otherwise about the number ten. Computers don't represent numbers using decimal. Instead, they are designed to represent numbers using binary, or \base 2". Let's make sure we understand what binary representations of numbers are. We'll start with positive integers. In decimal, we write numbers using digits f0; 1;:::; 9g, in particular, as sums of powers of ten, for example, 2 1 0 (238)10 = 2 ∗ 10 + 3 ∗ 10 + 8 ∗ 10 whereas, in binary, we represent numbers using bits f0; 1g, as a sum of powers of two: 4 3 2 1 0 (11010)2 = 1 ∗ 2 + 1 ∗ 2 + 0 ∗ 2 + 1 ∗ 2 + 0 ∗ 2 : I have put little subscripts (10 and 2) to indicate that we are using a particular representation (decimal or binary). We don't need to always put this subscript in, but sometimes it helps. You know how to count in decimal, so let's consider how to count in binary. You should verify that the binary representation is a sum of powers of 2 that indeed corresponds to the decimal representation in the leftmost column. In the left two columns below, I only used as as many digits or bits as I needed to represent the number. In the right column, I used a fixed number of bits, namely 8. 8 bits is called a byte.