ASP.NET SQL Server
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Teamcity 7.1 Documentation.Pdf
1. TeamCity Documentation . 4 1.1 What's New in TeamCity 7.1 . 5 1.2 What's New in TeamCity 7.0 . 14 1.3 Getting Started . 26 1.4 Concepts . 30 1.4.1 Agent Home Directory . 31 1.4.2 Agent Requirements . 32 1.4.3 Agent Work Directory . 32 1.4.4 Authentication Scheme . 33 1.4.5 Build Agent . 33 1.4.6 Build Artifact . 34 1.4.7 Build Chain . 35 1.4.8 Build Checkout Directory . 36 1.4.9 Build Configuration . 37 1.4.10 Build Configuration Template . 38 1.4.11 Build Grid . 39 1.4.12 Build History . 40 1.4.13 Build Log . 40 1.4.14 Build Number . 40 1.4.15 Build Queue . 40 1.4.16 Build Runner . 41 1.4.17 Build State . 41 1.4.18 Build Tag . 42 1.4.19 Build Working Directory . 43 1.4.20 Change . 43 1.4.21 Change State . 43 1.4.22 Clean Checkout . 44 1.4.23 Clean-Up . 45 1.4.24 Code Coverage . 46 1.4.25 Code Duplicates . 47 1.4.26 Code Inspection . 47 1.4.27 Continuous Integration . 47 1.4.28 Dependent Build . 47 1.4.29 Difference Viewer . 49 1.4.30 Guest User . 50 1.4.31 History Build . 51 1.4.32 Notifier . 51 1.4.33 Personal Build . 52 1.4.34 Pinned Build . 52 1.4.35 Pre-Tested (Delayed) Commit . 52 1.4.36 Project . 53 1.4.37 Remote Run . .. -

Appendixes APPENDIX A
PART 8 Appendixes APPENDIX A COM and .NET Interoperability The goal of this book was to provide you with a solid foundation in the C# language and the core services provided by the .NET platform. I suspect that when you contrast the object model provided by .NET to that of Microsoft’s previous component architecture (COM), you’ll no doubt be con- vinced that these are two entirely unique systems. Regardless of the fact that COM is now considered to be a legacy framework, you may have existing COM-based systems that you would like to inte- grate into your new .NET applications. Thankfully, the .NET platform provides various types, tools, and namespaces that make the process of COM and .NET interoperability quite straightforward. This appendix begins by examin- ing the process of .NET to COM interoperability and the related Runtime Callable Wrapper (RCW). The latter part of this appendix examines the opposite situation: a COM type communicating with a .NET type using a COM Callable Wrapper (CCW). ■Note A full examination of the .NET interoperability layer would require a book unto itself. If you require more details than presented in this appendix, check out my book COM and .NET Interoperability (Apress, 2002). The Scope of .NET Interoperability Recall that when you build assemblies using a .NET-aware compiler, you are creating managed code that can be hosted by the common language runtime (CLR). Managed code offers a number of ben- efits such as automatic memory management, a unified type system (the CTS), self-describing assemblies, and so forth. As you have also seen, .NET assemblies have a particular internal compo- sition. -

Special Characters Numbers
Index ■Special Characters AddServiceEndpoint( ) member, ServiceHost type, #define, preprocessor directive, 317–319 1032 #elif, preprocessor directive, 317–318 ADO.NET #else, preprocessor directive, 317–318 additional namespaces, 763–764 #endif, preprocessor directive, 317–318 vs. ADO classic, 759–760 #endregion, preprocessor directive, 317 application configuration files, 769–770 #if, preprocessor directive, 317–318 asynchronous data access, 792–793 #region, preprocessor directive, 317 autogenerated data components, 824–825 #undef, preprocessor directive, 317–319 autogenerating SQL commands, 816–817 % modulo operator, C#, 1097 autoincrementing, 797 & operator, pointer types, 312–313 binding DataTables to user interfaces, 804, 806 * operator, pointer types, 312–313 Command object, 781–782 ?? operator, 133 connected layer, 778 += operator, 610 connected vs. disconnected layer, 760 <%@Page%> directive attribute, ASP.NET, 846 connecting to database, Visual Studio 2005, 776 <%Import%> directive, ASP.NET, 846–847 connection objects, 779–780 => token, 1098 ConnectionStringBuilder object, 780–781 ? suffix, nullable types, 131 connectionStrings element, application configuration, 774–775 ■Numbers data access libraries, 1130 data adapter objects, 811–812 3D graphics graphical service, WPF, 1012 data providers, 760, 762 3D rendered animation, 970 data wizards, 822–825 100% code approach, 1048 DataColumn objects, 796, 798 ■ DataRelation objects, 817–820 A DataRow objects, 798–799, 801 A# programming language, 8 DataRow.RowState property, 799–800 Abort( -
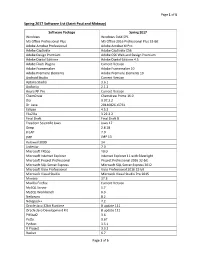
Spring 2017 Software List (Saint Paul and Midway)
Page 1 of 5 Spring 2017 Software List (Saint Paul and Midway) Software Package Spring 2017 Windows Windows 7x64 SP1 MS Office Professional Plus MS Office 2016 Professional Plus 32-Bit Adobe Acrobat Professional Adobe Acrobat XI Pro Adobe Captivate Adobe Captivate CS6 Adobe Design Premium Adobe CS6 Web and Design Premium Adobe Digital Editions Adobe Digital Editions 4.5 Adobe Flash Plugins Current Version Adobe Framemaker Adobe Framemaker 10 Adobe Premiere Elements Adobe Premiere Elements 10 Android Studio Current Version Aptana Studio 3.6.1 Audacity 2.1.2 Axure RP Pro Current Version ChemDraw Chemdraw Prime 16.0 Dia 0.97.2.2 Dr. Java 20140826-r5761 Eclipse 4.5.2 FileZilla 3.22.2.2 Final Draft Final Draft 8 Freedom Scientific Jaws Jaws 17 Gimp 2.8.18 JFLAP 7.0 JMP JMP 13 Kurzweil 3000 14 Lodestar 7.0 Microsoft FXCop 10.0 Microsoft Internet Explorer Internet Explorer 11 with Silverlight Microsoft Project Professional Project Professional 2016 32-bit Microsoft SQL Server Express Microsoft SQL Server Express 2012 Microsoft Visio Professional Visio Professional 2016 32-bit Microsoft Visual Studio Microsoft Visual Studio Pro 2015 Minitab 17.3 Mozilla Firefox Current Version MySQL Server 5.7 MySQL Workbench 6.3 Netbeans 8.2 Notepad++ 7.2 Oracle Java 32bit Runtime 8 update 111 Oracle Java Development Kit 8 update 111 PHStat2 3.6 Putty 0.67 Python 3.5.1 R Project 3.3.2 Racket 6.7 Page 1 of 5 Page 2 of 5 Software Package Spring 2017 Raptor Current Version SAP Client SAP Client 7.4.9 SAP Lumira 1.31.1 SAP Crystal Reports Current Version SPSS SPSS -

20 Le Regular Expression Seconda Parte
������������������������������������������������������������� ��������������������������������������� ������������������������������������������������������������ ����������������������������� ���������������������������������� ��������������������������������������������������� ������������������������������������������������������������������������������������������������������������������������������������� 400X302 Computer programming.ind1 1 20-03-2007 10:29:34 ������������������������������������������������������������� ��������������������������������������� ������������������������������������������������������������ ����������������������������� ���������������������������������� ��������������������������������������������������� ������������������������������������������������������������������������������������������������������������������������������������� 400X302 Computer programming.ind1 1 20-03-2007 10:29:34 I N V E T R I N A V B J 7 5 Doing Objects Object-Oriented Programming Access Data in Visual Basic 2005 Languages: Interpretation Analysis Cookbook di D. Kurata di Craig - I. D. di K.Bluttman - W.S. Freeze Addison Wesley Springer O’ Reilly 552 pp - 46,95 Euro 256 pp - 36,70 Euro 366 pp - 47,20 Euro ISBN 9780321320490 ISBN 9781846287732 ISBN 9780596101220 Scrivi a [email protected] specificando nell’oggetto della e-mail: IN VETRINA VBJ n. 75 oppure inviaci il coupon al numero di fax 0587/732232 Potrai acquistare i libri qui riportati con uno SCONTO ECCEZIONALE del 10% anche se acquisti solo un libro oppure del 20% -

Surviving C#-Codereviews
Rainer Stropek | time cockpit Surviving C#-Codereviews Your Host Rainer Stropek Developer, Entrepreneur Azure MVP, MS Regional Director Trainer at IT-Visions Contact software architects gmbh [email protected] Twitter: @rstropek Agenda Es ist nicht unüblich, dass externe oder interne Kunden Experten beauftragen, die C#- Codebasis eines Projekts zu begutachten. Rainer Stropek, langjähriger MVP und MS Regional Director, macht solche Projekte regelmäßig. In dieser Session erklärt er, worauf er dabei Wert legt. • Welche Tools setzt er ein, um Verbesserungspotenziale zu suchen? • Wie findet er in großen Codebasen rasch die kritischen Bereiche? • Welche Best und Worst Practices kontrolliert er? • Wie würde er ein C#-Projekt aufsetzen, das jeden Codereview glänzend bestehen soll? Auf solche Fragen wird Rainer in der Session eingehen. Sie erhalten eine konkrete Checkliste von Punkten, die Sie bei Ihren Projekten beachten können, um die Qualität Ihres gelieferten C#- Codes noch weiter zu verbessern. Agenda Introduction Reviewing the process Why Code Review Projects? Automation My Rules for Review Projects Source code handling Reviewing the code State of the art? Development process Basics Team management Coding guidelines Code structure Summary Documentation Recommendations Testing Performance Security Why Code Review Projects? Why Code Review Projects? M&A Buy company or source of a product New management team Customer-vendor relationship Tip: Make code review criteria part of contract Large customers buys software strategic for their business Frequently: Large customer, small vendor Team wants/needs external advice Reviewer is a kind of external coach Accompanying Reviews Security review Legal reviews Who owns the source code? License terms of dependencies? Compliance to policies (internal/external) Standard certifications E.g. -

Detailed Resume
[email protected] https://laptev.co/ Nickolay Laptev Education 2005-2010 Mary State Technical University, Russia, Master of Computer Science Summary of qualifications General skills: - Languages: Java, C#, Go, JavaScript, Groovy, Perl, VB.NET, Lisp, F#, Assembler, C, C++, PHP, Ruby. - Web frameworks: Spring MVC, AngularJS, ASP.NET MVC, Apache Struts. - IDE: Eclipse, IntelliJ Idea, NetBeans, MS Visual Studio 2003/2005/2008/2010/2012, Vim. - Version control: Git, Mercurial, Subversion, Rational Team Concert, Team Foundation Server, Vault, Visual SourceSafe. - DBMS: MS SQL Server 2000/2005/2008/2012, Oracle, DB2, Postgresql, MariaDB, MongoDB, Apache Jena, DynamoDB, Redshift, InfluxDB. - DB tools: Spring Data, JPA, Hibernate, MyBatis, pgbench, sysbench. - Messaging: Apache Kafka, JMS, IBM Websphere MQ, Apache ActiveMQ, RabbitMQ. - Transactions: JTA, JBossTS (Narayana). - Web services: RPC, SOAP, REST. - Application servers: Apache Tomcat, JBoss, Websphere Liberty. - Design platforms: OSGi, Eclipse Rich Client Platform, Eclipse Equinox, Netbeans platform. - Unit-testing frameworks: JUnit, NUnit, JMockit, PITest, Arquillian. - Logging frameworks: Graylog, Log4j, Logback. - GUI: GDI/ GDI+, DirectX, OpenGL. - DevOps/MLOps tools: Jenkins, Ansible, CloudFormation, Team City, ElectricFlow, Bitbucket Pipe- lines, Azure Pipelines, TravisCI, Bamboo, Rational Team Concert, Sagemaker. - Monitoring tools: New Relic, Zenoss, Grafana, Graphite, DataDog. - Source code static analysers: FxCop, StyleCop, Klocwork, Sonar, FindBugs. - Build and dependency -

MEMOIRE DE FIN D'etudes En Vue De L'obtention Du DIPLOME De Licence Ès Sciences Techniques DEVELOPPEMENT D'un LOGICIEL DE
N° d’ordre : 07/L3/TCO Année Universitaire : 2010 / 2011 UNIVERSITE D’ANTANANARIVO ---------------------- ECOLE SUPERIEURE POLYTECHNIQUE ----------------------- DEPARTEMENT TELECOMMUNICATION MEMOIRE DE FIN D’ETUDES en vue de l’obtention du DIPLOME de Licence ès sciences techniques Spécialité : Télécommunication par : RADIASON Tsiry Andriamampianina DEVELOPPEMENT D’UN LOGICIEL DE MESSAGERIE INSTANTANEE AVEC UN MODULE DE CRYPTAGE DE MESSAGE Soutenu le 20 Juillet 2012 Président : M. RAKOTOMALALA Mamy Alain Examinateurs : M. RAKOTONDRAINA Tahina Ezéchiel Mme. ANDRIANTSILAVO Haja Samiarivonjy Mme. RAMAFIARISONA Malalatiana Directeur de mémoire : Monsieur RAVONIMANANTSOA Ndaohialy Manda-Vy TABLE DES MATIERES TABLE DES MATIERES .................................................................................................................... i LISTE DES FIGURES........................................................................................................................ iv TABLE DES ABREVIATIONS ......................................................................................................... vi REMERCIEMENT ............................................................................................................................. x INTRODUCTION GENERALE ........................................................................................................ 1 CHAPITRE 1 GENERALITE ............................................................................................................ 3 1. Presentation du protocole SIP ................................................................................................ -

< Day Day up > Visual Studio Hacks by James Avery
< Day Day Up > Visual Studio Hacks By James Avery ............................................... Publisher: O'Reilly Pub Date: March 2005 ISBN: 0-596-00847-3 Pages: 500 Table of Contents | Index | Examples | Errata This hands-on guide is designed for developers who want to go far beyond the obvious features of Visual Studio--the most powerful, feature-rich Integrated Development Environment (IDE) on the market today. It takes the reader on a detailed tour through code editor hacks, all manners of customization, even external tools such as PowerToys. Full of valuable tips, tools, and tricks. < Day Day Up > < Day Day Up > Visual Studio Hacks By James Avery ............................................... Publisher: O'Reilly Pub Date: March 2005 ISBN: 0-596-00847-3 Pages: 500 Table of Contents | Index | Examples | Errata Copyright credits Credits About the Author Contributors Acknowledgments Preface Preface Why Visual Studio Hacks? How to Use This Book An Important Note About Keyboard Shortcuts How This Book Is Organized Conventions Using Code Examples Safari Enabled How to Contact Us Got a Hack? Chapter 1. Master Projects and Solutions Section 1.1. Hacks 1-5 Hack 1. Manage Projects and Solutions Hack 2. Master Assembly and Project References Hack 3. Organize Projects and Solutions Hack 4. Hack the Project and Solution Files Hack 5. Remove SourceSafe Bindings Chapter 2. Master the Editor Section 2.1. Hacks 6-15 Hack 6. Master the Clipboard Hack 7. Make Pasting into Visual Studio Easier Hack 8. Master IntelliSense Hack 9. Master Regions Hack 10. Add Guidelines to the Text Editor Hack 11. Select the Best Editor Hack 12. Customize Syntax Coloring Hack 13. -

Towards Left Duff S Mdbg Holt Winters Gai Incl Tax Drupal Fapi Icici
jimportneoneo_clienterrorentitynotfoundrelatedtonoeneo_j_sdn neo_j_traversalcyperneo_jclientpy_neo_neo_jneo_jphpgraphesrelsjshelltraverserwritebatchtransactioneventhandlerbatchinsertereverymangraphenedbgraphdatabaseserviceneo_j_communityjconfigurationjserverstartnodenotintransactionexceptionrest_graphdbneographytransactionfailureexceptionrelationshipentityneo_j_ogmsdnwrappingneoserverbootstrappergraphrepositoryneo_j_graphdbnodeentityembeddedgraphdatabaseneo_jtemplate neo_j_spatialcypher_neo_jneo_j_cyphercypher_querynoe_jcypherneo_jrestclientpy_neoallshortestpathscypher_querieslinkuriousneoclipseexecutionresultbatch_importerwebadmingraphdatabasetimetreegraphawarerelatedtoviacypherqueryrecorelationshiptypespringrestgraphdatabaseflockdbneomodelneo_j_rbshortpathpersistable withindistancegraphdbneo_jneo_j_webadminmiddle_ground_betweenanormcypher materialised handaling hinted finds_nothingbulbsbulbflowrexprorexster cayleygremlintitandborient_dbaurelius tinkerpoptitan_cassandratitan_graph_dbtitan_graphorientdbtitan rexter enough_ram arangotinkerpop_gremlinpyorientlinkset arangodb_graphfoxxodocumentarangodborientjssails_orientdborientgraphexectedbaasbox spark_javarddrddsunpersist asigned aql fetchplanoriento bsonobjectpyspark_rddrddmatrixfactorizationmodelresultiterablemlibpushdownlineage transforamtionspark_rddpairrddreducebykeymappartitionstakeorderedrowmatrixpair_rddblockmanagerlinearregressionwithsgddstreamsencouter fieldtypes spark_dataframejavarddgroupbykeyorg_apache_spark_rddlabeledpointdatabricksaggregatebykeyjavasparkcontextsaveastextfilejavapairdstreamcombinebykeysparkcontext_textfilejavadstreammappartitionswithindexupdatestatebykeyreducebykeyandwindowrepartitioning -

Procedurally Generated Landscape As a Visualization of C# Code
Masaryk University Faculty of Informatics Procedurally Generated Landscape as a Visualization of C# Code Bachelor’s Thesis Adam Štěpánek Brno, Spring 2020 This is where a copy of the official signed thesis assignment and a copy ofthe Statement of an Author is located in the printed version of the document. Declaration Hereby I declare that this paper is my original authorial work, which I have worked out on my own. All sources, references, and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Adam Štěpánek Advisor: Mgr. David Kuťák i Acknowledgements I thank my advisor, Mgr. David Kuťák, for patience and invaluable feedback. I also thank my colleagues at Riganti for their input and for letting me use their hardware to deploy Helveg. Last but not least, I thank my D&D group for their encouragement, and everyone who supported me, while working on this project, in any way. ii Abstract Software visualization helps programmers better understand code through visual means. This thesis presents a software visualization tool, named Helveg, that maps the structure of C# code, along with compiler diagnostics, onto a procedurally generated landscape. This is achieved in three stages (code analysis, landscape genera- tion, and rendering), which the thesis describes in detail. Presented are also case studies involving open-source codebases. Results of these case studies show that Helveg can be used to visualize the structure of a C# codebase in a visually appealing way. Also, analysis of these outputs helps to pinpoint the drawbacks of the current visualization thus providing ideas for future work. -

Coverity 2018.09 Command Reference Reference for Coverity Analysis, Coverity Platform, and Coverity Desktop
Coverity 2018.09 Command Reference Reference for Coverity Analysis, Coverity Platform, and Coverity Desktop. Copyright 2018, Synopsys, Inc. All rights reserved worldwide. Table of Contents I. Coverity Analysis Commands ........................................................................................................ 1 cov-analyze .............................................................................................................................. 2 cov-blame .............................................................................................................................. 45 cov-build, cov-build-sbox ......................................................................................................... 50 cov-collect-models .................................................................................................................. 80 cov-commit-defects ................................................................................................................. 82 cov-configure, cov-configure-sbox ........................................................................................... 94 cov-copy-overrun-triage (Deprecated) .................................................................................... 109 cov-count-lines ..................................................................................................................... 111 cov-dotnet-aot ...................................................................................................................... 114 cov-emit ..............................................................................................................................