ARPEGE Cloud Cover Forecast Postprocessing with Convolutional Neural Network
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
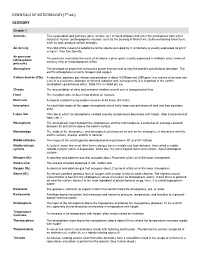
ESSENTIALS of METEOROLOGY (7Th Ed.) GLOSSARY
ESSENTIALS OF METEOROLOGY (7th ed.) GLOSSARY Chapter 1 Aerosols Tiny suspended solid particles (dust, smoke, etc.) or liquid droplets that enter the atmosphere from either natural or human (anthropogenic) sources, such as the burning of fossil fuels. Sulfur-containing fossil fuels, such as coal, produce sulfate aerosols. Air density The ratio of the mass of a substance to the volume occupied by it. Air density is usually expressed as g/cm3 or kg/m3. Also See Density. Air pressure The pressure exerted by the mass of air above a given point, usually expressed in millibars (mb), inches of (atmospheric mercury (Hg) or in hectopascals (hPa). pressure) Atmosphere The envelope of gases that surround a planet and are held to it by the planet's gravitational attraction. The earth's atmosphere is mainly nitrogen and oxygen. Carbon dioxide (CO2) A colorless, odorless gas whose concentration is about 0.039 percent (390 ppm) in a volume of air near sea level. It is a selective absorber of infrared radiation and, consequently, it is important in the earth's atmospheric greenhouse effect. Solid CO2 is called dry ice. Climate The accumulation of daily and seasonal weather events over a long period of time. Front The transition zone between two distinct air masses. Hurricane A tropical cyclone having winds in excess of 64 knots (74 mi/hr). Ionosphere An electrified region of the upper atmosphere where fairly large concentrations of ions and free electrons exist. Lapse rate The rate at which an atmospheric variable (usually temperature) decreases with height. (See Environmental lapse rate.) Mesosphere The atmospheric layer between the stratosphere and the thermosphere. -

Cloud and Precipitation Radars
Sponsored by the U.S. Department of Energy Office of Science, the Atmospheric Radiation Measurement (ARM) Climate Research Facility maintains heavily ARM Radar Data instrumented fixed and mobile field sites that measure clouds, aerosols, Radar data is inherently complex. ARM radars are developed, operated, and overseen by engineers, scientists, radiation, and precipitation. data analysts, and technicians to ensure common goals of quality, characterization, calibration, data Data from these sites are used by availability, and utility of radars. scientists to improve the computer models that simulate Earth’s climate system. Storage Process Data Post- Data Cloud and Management processing Products Precipitation Radars Mentors Mentors Cloud systems vary with climatic regimes, and observational DQO Translators Data capabilities must account for these differences. Radars are DMF Developers archive Site scientist DMF the only means to obtain both quantitative and qualitative observations of clouds over a large area. At each ARM fixed and mobile site, millimeter and centimeter wavelength radars are used to obtain observations Calibration Configuration of the horizontal and vertical distributions of clouds, as well Scan strategy as the retrieval of geophysical variables to characterize cloud Site operations properties. This unprecedented assortment of 32 radars Radar End provides a unique capability for high-resolution delineation Mentors science users of cloud evolution, morphology, and characteristics. One-of-a-Kind Radar Network Advanced Data Products and Tools All ARM radars, with the exception of three, are equipped with dual- Reectivity (dBz) • Active Remotely Sensed Cloud Locations (ARSCL) – combines data from active remote sensors with polarization technology. Combined -60 -40 -20 0 20 40 50 60 radar observations to produce an objective determination of hydrometeor height distributions and retrieval with multiple frequencies, this 1 μm 10 μm 100 μm 1 mm 1 cm 10 cm 10-3 10-2 10-1 100 101 102 of cloud properties. -

Our Atmosphere Greece Sicily Athens
National Aeronautics and Space Administration Sardinia Italy Turkey Our Atmosphere Greece Sicily Athens he atmosphere is a life-giving blanket of air that surrounds our Crete T Tunisia Earth; it is composed of gases that protect us from the Sun’s intense ultraviolet Gulf of Gables radiation, allowing life to flourish. Greenhouse gases like carbon dioxide, Mediterranean Sea ozone, and methane are steadily increasing from year to year. These gases trap infrared radiation (heat) emitted from Earth’s surface and atmosphere, Gulf of causing the atmosphere to warm. Conversely, clouds as well as many tiny Sidra suspended liquid or solid particles in the air such as dust, smoke, and Egypt Libya pollution—called aerosols—reflect the Sun’s radiative energy, which leads N to cooling. This delicate balance of incoming and reflected solar radiation 200 km and emitted infrared energy is critical in maintaining the Earth’s climate Turkey Greece and sustaining life. Research using computer models and satellite data from NASA’s Earth Sicily Observing System enhances our understanding of the physical processes Athens affecting trends in temperature, humidity, clouds, and aerosols and helps us assess the impact of a changing atmosphere on the global climate. Crete Tunisia Gulf of Gables Mediterranean Sea September 17, 1979 Gulf of Sidra October 6, 1986 September 20, 1993 Egypt Libya September 10, 2000 Aerosol Index low high September 24, 2006 On August 26, 2007, wildfires in southern Greece stretched along the southwest coast of the Peloponnese producing Total Ozone (Dobson Units) plumes of smoke that drifted across the Mediterranean Sea as far as Libya along Africa’s north coast. -

The Cloud Cycle and Acid Rain
gX^\[`i\Zk\em`ifed\ekXc`dgXZkjf]d`e`e^Xkc`_`i_`^_jZ_ffcYffbc\k(+ ( K_\Zcfl[ZpZc\Xe[XZ`[iX`e m the mine ke fro smo uld rain on Lihir? Co e acid caus /P 5IJTCPPLMFUXJMM FYQMBJOXIZ K_\i\Xjfe]fik_`jYffbc\k K_\i\`jefXZ`[iX`efeC`_`i% `jk_Xkk_\i\_XjY\\ejfd\ K_`jYffbc\k\ogcX`ejk_\jZ`\eZ\ d`jle[\ijkXe[`e^XYflkk_\ Xe[Z_\d`jkipY\_`e[XZ`[iX`e% \o`jk\eZ\f]XZ`[iX`efeC`_`i% I\X[fekfÔe[flkn_pk_\i\`jef XZ`[iX`efeC`_`i55 page Normal rain cycle and acid rain To understand why there is no acid rain on Lihir we will look at: 1 How normal rain is formed 2 2 How humidity effects rain formation 3 3 What causes acid rain? 4 4 How much smoke pollution makes acid rain? 5 5 Comparing pollution on Lihir with Sydney and China 6 6 Where acid rain does occur 8–9 7 Could acid rain fall on Lihir? 10–11 8 The effect of acid rain on the environment 12 9 Time to check what you’ve learnt 13 Glossary back page Read the smaller text in the blue bar at the bottom of each page if you want to understand the detailed scientific explanations. > > gX^\) ( ?fnefidXciX`e`j]fid\[ K_\eXkliXcnXk\iZpZc\ :cfl[jXi\]fid\[n_\e_\Xk]ifdk_\jleZXlj\jk_\nXk\i`e k_\fZ\Xekf\mXgfiXk\Xe[Y\Zfd\Xe`em`j`Yc\^Xj% K_`j^Xji`j\j_`^_`ekfk_\X`in_\i\Zffc\ik\dg\iXkli\jZXlj\ `kkfZfe[\ej\Xe[Y\Zfd\k`epnXk\i[ifgc\kj%N_\edXepf] k_\j\nXk\i[ifgc\kjZfcc`[\kf^\k_\ik_\pdXb\Y`^^\inXk\i [ifgj#n_`Z_Xi\kff_\XmpkfÕfXkXifle[`ek_\X`iXe[jfk_\p ]Xcc[fneXjiX`e%K_`jgifZ\jj`jZXcc\[gi\Z`g`kXk`fe% K_\eXkliXcnXk\iZpZc\ _\Xk]ifd k_\jle nXk\imXgflijZfe[\ej\ kfZi\Xk\Zcfl[j gi\Z`g`kXk`fe \mXgfiXk`fe K_\jZ`\eZ\Y\_`e[iX`e K_\_\Xk]ifdk_\jleZXlj\jnXk\i`ek_\ -

Cold Season Cloud Seeding
Weather Modification UNDERSTANDING Cloud seeding—a form of weather modification— ALBERTA CANADA COLD SEASON is a safe, scientific, time-tested, and proven set of Cloud Seeding technologies used to enhance rain and snow, re- ND duce hail damage, and alleviate fog. The benefits ID of cloud seeding can be measured in additional WY water for cities and agriculture, as well as the re- NV UT duction of damage from severe weather. CA CO KS TX Target area—Cold-season cloud-seeding Target area—Warm-season cloud-seeding A ground-based generator is used to burn a silver iodide solution to release microscopic silver-iodide particles which can create additional ice crystals, then snow, in winter clouds. Research has shown that placing equipment at high elevations increases cloud seeding effectiveness. NAWMC Members Cold Season Seeding California Department of Water Resources When moist air flows over the mountains, water vapor Colorado Water Conservation Board condenses and forms clouds composed of water droplets. These droplets become “super cooled” and have the unique Desert Research Institute quality to remain liquid even at temperatures below freez- North Dakota Atmospheric Resource Board ing. Given enough time and mixing with surrounding air, many of the droplets will evaporate, but under the correct Texas Department of Licensing and Regulation conditions some will eventually become ice crystals, grow Utah Division of Water Resources into snowflakes and precipitate to the ground. Cloud seed- Wyoming Water Development Office ing provides an opportunity to increase the number of ice crystals that can become snowflakes. NAWMC Associate Members Who Conducts Cloud Seeding? Central Arizona Water Conservation District In North America, cloud-seeding programs are conducted in Metropolitan Water District of Southern California California, Colorado, Idaho, Nevada, Utah, Wyoming, Kansas, Santa Barbara County Water Agency North Dakota, and Texas, as well as Alberta, Canada. -

Lecture 7A: Cloud Development and Forms
Lecture 7a: Cloud Development and Forms (from “The Blue Planet”) Why Clouds Form Cloud Types ESS55 Prof. Jin-Yi Yu Why Clouds Form? Clouds form when air rises and becomes saturated in response to adiabatic cooling. ESS55 Prof. Jin-Yi Yu Four Ways to Lift Air Upward (1) Localized Convection cold front (2) Convergence (4) Frontal Lifting Lifting warm front (3) Orographic Lifting ESS55 (from “The Blue Planet”) Prof. Jin-Yi Yu Orographic Lifting ESS55 Prof. Jin-Yi Yu Frontal Lifting When boundaries between air of unlike temperatures (fronts) migrate, warmer air is pushed aloft. This results in adiabatic cooling and cloud formation. Cold fronts occur when warm air is displaced by cooler air. Warm fronts occur when warm air rises over and displaces cold air. ESS55 Prof. Jin-Yi Yu Cloud Type Based On Properties Four basic cloud categories: Cirrus --- thin, wispy cloud of ice. Stratus --- layered cloud Cumulus --- clouds having vertical development. Nimbus --- rain-producing cloud These basic cloud types can be combined to generate ten different cloud types, such as cirrostratus clouds that have the characteristics of cirrus clouds and stratus clouds. ESS55 Prof. Jin-Yi Yu Cloud Types ESS55 Prof. Jin-Yi Yu Cloud Types Based On Height If based on cloud base height, the ten principal cloud types can then grouped into four cloud types: High clouds -- cirrus, cirrostratus, cirroscumulus. Middle clouds – altostratus and altocumulus Low clouds – stratus, stratocumulus, and nimbostartus Clouds with extensive vertical development – cumulus and cumulonimbus. (from “The Blue Planet”) ESS55 Prof. Jin-Yi Yu Cloud Classifications (from “The Blue Planet”) ESS55 Prof. -

Prediction of Short-Time Cloud Motion Using a Deep-Learning Model
atmosphere Article Prediction of Short-Time Cloud Motion Using a Deep-Learning Model Xinyue Su 1,*, Tiejian Li 1,2 , Chenge An 1 and Guangqian Wang 1 1 State Key Laboratory of Hydroscience and Engineering, Tsinghua University, Beijing 100084, China; [email protected] (T.L.); [email protected] (C.A.); [email protected] (G.W.) 2 State Key Laboratory of Plateau Ecology and Agriculture, Qinghai University, Xining 810016, China * Correspondence: [email protected] Received: 24 August 2020; Accepted: 22 October 2020; Published: 26 October 2020 Abstract: A cloud image can provide significant information, such as precipitation and solar irradiation. Predicting short-time cloud motion from images is the primary means of making intra-hour irradiation forecasts for solar-energy production and is also important for precipitation forecasts. However, it is very challenging to predict cloud motion (especially nonlinear motion) accurately. Traditional methods of cloud-motion prediction are based on block matching and the linear extrapolation of cloud features; they largely ignore nonstationary processes, such as inversion and deformation, and the boundary conditions of the prediction region. In this paper, the prediction of cloud motion is regarded as a spatiotemporal sequence-forecasting problem, for which an end-to-end deep-learning model is established; both the input and output are spatiotemporal sequences. The model is based on gated recurrent unit (GRU)- recurrent convolutional network (RCN), a variant of the gated recurrent unit (GRU), which has convolutional structures to deal with spatiotemporal features. We further introduce surrounding context into the prediction task. We apply our proposed Multi-GRU-RCN model to FengYun-2G satellite infrared data and compare the results to those of the state-of-the-art method of cloud-motion prediction, the variational optical flow (VOF) method, and two well-known deep-learning models, namely, the convolutional long short-term memory (ConvLSTM) and GRU. -

Glossary of Severe Weather Terms
Glossary of Severe Weather Terms -A- Anvil The flat, spreading top of a cloud, often shaped like an anvil. Thunderstorm anvils may spread hundreds of miles downwind from the thunderstorm itself, and sometimes may spread upwind. Anvil Dome A large overshooting top or penetrating top. -B- Back-building Thunderstorm A thunderstorm in which new development takes place on the upwind side (usually the west or southwest side), such that the storm seems to remain stationary or propagate in a backward direction. Back-sheared Anvil [Slang], a thunderstorm anvil which spreads upwind, against the flow aloft. A back-sheared anvil often implies a very strong updraft and a high severe weather potential. Beaver ('s) Tail [Slang], a particular type of inflow band with a relatively broad, flat appearance suggestive of a beaver's tail. It is attached to a supercell's general updraft and is oriented roughly parallel to the pseudo-warm front, i.e., usually east to west or southeast to northwest. As with any inflow band, cloud elements move toward the updraft, i.e., toward the west or northwest. Its size and shape change as the strength of the inflow changes. Spotters should note the distinction between a beaver tail and a tail cloud. A "true" tail cloud typically is attached to the wall cloud and has a cloud base at about the same level as the wall cloud itself. A beaver tail, on the other hand, is not attached to the wall cloud and has a cloud base at about the same height as the updraft base (which by definition is higher than the wall cloud). -

Name That Cloud!
Period _____ Name ___________________________ Name That Cloud! What’s the weather going to be like today? We’re always asking that. We need to know. The weather affects what we wear, what we need to take with us, and what we do. Will we need to wear shorts, or a sweater and warm pants? Will we need to take an umbrella or a heavy coat? Can we play outside after school? You can learn to predict the weather. You don’t need a lot of equipment or fancy stuff – just use your eyes! Go outside and look at the clouds. Clouds come in different shapes, sizes, and colors. You can use what you know about clouds to find out what the weather will bring. Okay, here’s what you need to know about clouds. Clouds are named by the way they look. We use Latin root words to name them. Clouds come in different sizes and shapes. They are formed and drift along at different heights in the sky. All of these things help us name them and know what kind of weather they may bring. There are three main types of clouds: cumulus, cirrus, and stratus. When the weather is fair, we see cumulus clouds. Fair weather is fine, sunny weather with no chance of rain, snow, or any other precipitation. Cumulus clouds are white, puffy clouds that may look like cauliflower. In Latin, cumulus means “heap.” You may see heaps and heaps of these white, fluffy, cotton-ball-looking clouds. Usually there are large spaces of clear blue sky in between them. -

CLOUDSCLOUDS and the Earth’S Radiant Energy System
Educational Product Educators Grades 5–8 Investigating the Climate System CLOUDSCLOUDS And the Earth’s Radiant Energy System PROBLEM-BASED CLASSROOM MODULES Responding to National Education Standards in: English Language Arts ◆ Geography ◆ Mathematics Science ◆ Social Studies Investigating the Climate System CLOUDSCLOUDS And the Earth’s Radiant Energy System Authored by: CONTENTS Sallie M. Smith, Howard B. Owens Science Center, Greenbelt, Maryland Scenario; Grade Levels; Time Required; Objectives; Prepared by: Disciplines Encompassed; Key Terms & Concepts; Stacey Rudolph, Senior Science Prerequisite Knowledge . 2 Education Specialist, Institute for Global Environmental Strategies Student Weather Intern Training Activities . 4 (IGES), Arlington, Virginia Activity One; Activity Two. 4 John Theon, Former Program Activity Three. 5 Scientist for NASA TRMM Activity Four. 6 Editorial Assistance, Dan Stillman, Science Communications Specialist, Activity Five . 9 Institute for Global Environmental Activity Six . 11 Strategies (IGES), Arlington, Virginia Appendix A: Resources . 12 Graphic Design by: Susie Duckworth Graphic Design & Appendix B: Assessment Rubrics & Answer Keys. 13 Illustration, Falls Church, Virginia Funded by: Appendix C: National Education Standards. 18 NASA TRMM Grant #NAG5-9641 Give us your feedback: Appendix D: Problem-Based Learning . 20 To provide feedback on the modules online, go to: Appendix E: TRMM Introduction/Instruments . 22 https://ehb2.gsfc.nasa.gov/edcats/ educational_product Appendix F: Online Resources . 24 and click on “Investigating the Climate System.” Appendix G: Glossary . 29 NOTE: This module was developed as part of the series “Investigating the Climate System.”The series includes five modules: Clouds, Energy, Precipitation, Weather, and Winds. While these materials were developed under one series title, they were designed so that each module could be used independently. -

Tropical Cyclone Temperature Profiles and Cloud Macro-/Micro-Physical Properties Based on AIRS Data
atmosphere Article Tropical Cyclone Temperature Profiles and Cloud Macro-/Micro-Physical Properties Based on AIRS Data 1,2, 1, 3 3, 1, 1 Qiong Liu y, Hailin Wang y, Xiaoqin Lu , Bingke Zhao *, Yonghang Chen *, Wenze Jiang and Haijiang Zhou 1 1 College of Environmental Science and Engineering, Donghua University, Shanghai 201620, China; [email protected] (Q.L.); [email protected] (H.W.); [email protected] (W.J.); [email protected] (H.Z.) 2 State Key Laboratory of Severe Weather, Chinese Academy of Meteorological Sciences, Beijing 100081, China 3 Shanghai Typhoon Institute, China Meteorological Administration, Shanghai 200030, China; [email protected] * Correspondence: [email protected] (B.Z.); [email protected] (Y.C.) The authors have the same contribution. y Received: 9 October 2020; Accepted: 29 October 2020; Published: 2 November 2020 Abstract: We used the observations from Atmospheric Infrared Sounder (AIRS) onboard Aqua over the northwest Pacific Ocean from 2006–2015 to study the relationships between (i) tropical cyclone (TC) temperature structure and intensity and (ii) cloud macro-/micro-physical properties and TC intensity. TC intensity had a positive correlation with warm-core strength (correlation coefficient of 0.8556). The warm-core strength increased gradually from 1 K for tropical depression (TD) to >15 K for super typhoon (Super TY). The vertical areas affected by the warm core expanded as TC intensity increased. The positive correlation between TC intensity and warm-core height was slightly weaker. The warm-core heights for TD, tropical storm (TS), and severe tropical storm (STS) were concentrated between 300 and 500 hPa, while those for typhoon (TY), severe typhoon (STY), and Super TY varied from 200 to 350 hPa. -

Tropical Cyclone Cloud and Intensity Relationships by Charles P. Arnold Department of Atmospheric Science Colorado State Univers
Tropical Cyclone Cloud and Intensity Relationships by Charles P. Arnold Department of Atmospheric Science Colorado State University Fort Collins, Colorado u.s. Army Grant No. DAEA 18-77-C-0039 NHEML Brant No. 04-6-022-44036 TROPICAL CYCLONE CLOUD AND INTENSITY RELATIONSHIPS by Charles P. Arnold Preparation of this report has been financially supported by United States Army Electronics, White Sands Missile Range Grant No. DAEA 18-77-C-0039 and NOAA _. National Hurricane and Experimental Meteorology Laboratory Grant No. 04-6-022-44036 Department of Atmospheric Science Colorado State University Fort Collins, Colorado November, 1977 Atmospheric Science Paper 277 ABSTRACT This paper describes an observational study of tropical cyclones based on high resolution visual and infrared Defense Meteorological Satellite Program (DMSP) pictures of western North Pa~ific storms. It ~lso utilizes composited rawinsonde data about storms in the same geo graphical region. It discusses the physical characteristics, cloud characteristics and wind and thermodynamic characteristics associated with each of four stages of tropical cyclone development (developing cluster, tropical depression, tropical storm, and typhoons). Among the physical characteristics discussed are typical storm sizes, types of banding most often observed, location and type of circulation center, intensification rates, and eye dimensions. Cloud characteristics in clude the percent of storm area covered by cirrus and convective cloud types and the distribution and characteristics of the basic convective element found in DMSP data. Among the wind and thermodynamic parameters investigated were vertical motion, vorticity, tangential wind, moisture and temperature. RE!SultS of this study reveal a substantial variability exists in the cloudiness of tropical cyclones.