The Flow Caml System Version 1.00 Documentation and User’S Manual
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bit Shifts Bit Operations, Logical Shifts, Arithmetic Shifts, Rotate Shifts
Why bit operations Assembly languages all provide ways to manipulate individual bits in multi-byte values Some of the coolest “tricks” in assembly rely on Bit Shifts bit operations With only a few instructions one can do a lot very quickly using judicious bit operations And you can do them in almost all high-level ICS312 programming languages! Let’s look at some of the common operations, Machine-Level and starting with shifts Systems Programming logical shifts arithmetic shifts Henri Casanova ([email protected]) rotate shifts Shift Operations Logical Shifts The simplest shifts: bits disappear at one end A shift moves the bits around in some data and zeros appear at the other A shift can be toward the left (i.e., toward the most significant bits), or toward the right (i.e., original byte 1 0 1 1 0 1 0 1 toward the least significant bits) left log. shift 0 1 1 0 1 0 1 0 left log. shift 1 1 0 1 0 1 0 0 left log. shift 1 0 1 0 1 0 0 0 There are two kinds of shifts: right log. shift 0 1 0 1 0 1 0 0 Logical Shifts right log. shift 0 0 1 0 1 0 1 0 Arithmetic Shifts right log. shift 0 0 0 1 0 1 0 1 Logical Shift Instructions Shifts and Numbers Two instructions: shl and shr The common use for shifts: quickly multiply and divide by powers of 2 One specifies by how many bits the data is shifted In decimal, for instance: multiplying 0013 by 10 amounts to doing one left shift to obtain 0130 Either by just passing a constant to the instruction multiplying by 100=102 amounts to doing two left shifts to obtain 1300 Or by using whatever -

Using LLVM for Optimized Lightweight Binary Re-Writing at Runtime
Using LLVM for Optimized Lightweight Binary Re-Writing at Runtime Alexis Engelke, Josef Weidendorfer Department of Informatics Technical University of Munich Munich, Germany EMail: [email protected], [email protected] Abstract—Providing new parallel programming models/ab- helpful in reducing any overhead of provided abstractions. stractions as a set of library functions has the huge advantage But with new languages, porting of existing application that it allows for an relatively easy incremental porting path for code is required, being a high burden for adoption with legacy HPC applications, in contrast to the huge effort needed when novel concepts are only provided in new programming old code bases. Therefore, to provide abstractions such as languages or language extensions. However, performance issues PGAS for legacy codes, APIs implemented as libraries are are to be expected with fine granular usage of library functions. proposed [5], [6]. Libraries have the benefit that they easily In previous work, we argued that binary rewriting can bridge can be composed and can stay small and focused. However, the gap by tightly coupling application and library functions at libraries come with the caveat that fine granular usage of runtime. We showed that runtime specialization at the binary level, starting from a compiled, generic stencil code can help library functions in inner kernels will severely limit compiler in approaching performance of manually written, statically optimizations such as vectorization and thus, may heavily compiled version. reduce performance. In this paper, we analyze the benefits of post-processing the To this end, in previous work [7], we proposed a technique re-written binary code using standard compiler optimizations for lightweight code generation by re-combining existing as provided by LLVM. -

Lisp: Final Thoughts
20 Lisp: Final Thoughts Both Lisp and Prolog are based on formal mathematical models of computation: Prolog on logic and theorem proving, Lisp on the theory of recursive functions. This sets these languages apart from more traditional languages whose architecture is just an abstraction across the architecture of the underlying computing (von Neumann) hardware. By deriving their syntax and semantics from mathematical notations, Lisp and Prolog inherit both expressive power and clarity. Although Prolog, the newer of the two languages, has remained close to its theoretical roots, Lisp has been extended until it is no longer a purely functional programming language. The primary culprit for this diaspora was the Lisp community itself. The pure lisp core of the language is primarily an assembly language for building more complex data structures and search algorithms. Thus it was natural that each group of researchers or developers would “assemble” the Lisp environment that best suited their needs. After several decades of this the various dialects of Lisp were basically incompatible. The 1980s saw the desire to replace these multiple dialects with a core Common Lisp, which also included an object system, CLOS. Common Lisp is the Lisp language used in Part III. But the primary power of Lisp is the fact, as pointed out many times in Part III, that the data and commands of this language have a uniform structure. This supports the building of what we call meta-interpreters, or similarly, the use of meta-linguistic abstraction. This, simply put, is the ability of the program designer to build interpreters within Lisp (or Prolog) to interpret other suitably designed structures in the language. -

Relational Representation of the LLVM Intermediate Language
NATIONAL AND KAPODISTRIAN UNIVERSITY OF ATHENS SCHOOL OF SCIENCE DEPARTMENT OF INFORMATICS AND TELECOMMUNICATIONS UNDERGRADUATE STUDIES UNDERGRADUATE THESIS Relational Representation of the LLVM Intermediate Language Eirini I. Psallida Supervisors: Yannis Smaragdakis, Associate Professor NKUA Georgios Balatsouras, PhD Student NKUA ATHENS JANUARY 2014 ΕΘΝΙΚΟ ΚΑΙ ΚΑΠΟΔΙΣΤΡΙΑΚΟ ΠΑΝΕΠΙΣΤΗΜΙΟ ΑΘΗΝΩΝ ΣΧΟΛΗ ΘΕΤΙΚΩΝ ΕΠΙΣΤΗΜΩΝ ΤΜΗΜΑ ΠΛΗΡΟΦΟΡΙΚΗΣ ΚΑΙ ΤΗΛΕΠΙΚΟΙΝΩΝΙΩΝ ΠΡΟΠΤΥΧΙΑΚΕΣ ΣΠΟΥΔΕΣ ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ Σχεσιακή Αναπαράσταση της Ενδιάμεσης Γλώσσας του LLVM Ειρήνη Ι. Ψαλλίδα Επιβλέποντες: Γιάννης Σμαραγδάκης, Αναπληρωτής Καθηγητής ΕΚΠΑ Γεώργιος Μπαλατσούρας, Διδακτορικός φοιτητής ΕΚΠΑ ΑΘΗΝΑ ΙΑΝΟΥΑΡΙΟΣ 2014 UNDERGRADUATE THESIS Relational Representation of the LLVM Intermediate Language Eirini I. Psallida R.N.: 1115200700272 Supervisor: Yannis Smaragdakis, Associate Professor NKUA Georgios Balatsouras, PhD Student NKUA ΠΤΥΧΙΑΚΗ ΕΡΓΑΣΙΑ Σχεσιακή Αναπαράσταση της ενδιάμεσης γλώσσας του LLVM Ειρήνη Ι. Ψαλλίδα Α.Μ.: 1115200700272 Επιβλέπων: Γιάννης Σμαραγδάκης, Αναπληρωτής Καθηγητής ΕΚΠΑ Γεώργιος Μπαλατσούρας, Διδακτορικός φοιτητής ΕΚΠΑ ΠΕΡΙΛΗΨΗ Περιγράφουμε τη σχεσιακή αναπαράσταση της ενδιάμεσης γλώσσας του LLVM, γνωστή ως LLVM IR. Η υλοποίηση μας παράγει σχέσεις από ένα πρόγραμμα εισόδου σε ενδιάμεση μορφή LLVM. Κάθε σχέση αποθηκεύεται σαν πίνακας βάσης δεδομένων σε ένα περιβάλλον εργασίας Datalog. Αναπαριστούμε το σύστημα τύπων καθώς και το σύνολο εντολών της γλώσσας του LLVM. Υποστηρίζουμε επίσης τους περιορισμούς της γλώσσας προσδιορίζοντάς τους με χρήση της προγραμματιστικής γλώσσας Datalog. ΘΕΜΑΤΙΚΗ ΠΕΡΙΟΧΗ: Μεταγλωτιστές, Γλώσσες Προγραμματισμού ΛΕΞΕΙΣ ΚΛΕΙΔΙΑ: σχεσιακή αναπαράσταση, ενδιάμεση αναπαράσταση, σύστημα τύπων, σύνολο εντολών, LLVM, Datalog ABSTRACT We describe the relational representation of the LLVM intermediate language, known as the LLVM IR. Our implementation produces the relation contents of an input program in the LLVM intermediate form. Each relation is stored as a database table into a Datalog workspace. -

Drscheme: a Pedagogic Programming Environment for Scheme
DrScheme A Pedagogic Programming Environment for Scheme Rob ert Bruce Findler Cormac Flanagan Matthew Flatt Shriram Krishnamurthi and Matthias Felleisen Department of Computer Science Rice University Houston Texas Abstract Teaching intro ductory computing courses with Scheme el evates the intellectual level of the course and thus makes the sub ject more app ealing to students with scientic interests Unfortunatelythe p o or quality of the available programming environments negates many of the p edagogic advantages Toovercome this problem wehavedevel op ed DrScheme a comprehensive programming environmentforScheme It fully integrates a graphicsenriched editor a multilingua l parser that can pro cess a hierarchyofsyntactically restrictivevariants of Scheme a functional readevalprint lo op and an algebraical ly sensible printer The environment catches the typical syntactic mistakes of b eginners and pinp oints the exact source lo cation of runtime exceptions DrScheme also provides an algebraic stepp er a syntax checker and a static debugger The rst reduces Scheme programs including programs with assignment and control eects to values and eects The to ol is useful for explainin g the semantics of linguistic facilities and for studying the b ehavior of small programs The syntax c hecker annotates programs with fontandcolorchanges based on the syntactic structure of the pro gram It also draws arrows on demand that p oint from b ound to binding o ccurrences of identiers The static debugger roughly sp eaking pro vides a typ e inference system -

1. with Examples of Different Programming Languages Show How Programming Languages Are Organized Along the Given Rubrics: I
AGBOOLA ABIOLA CSC302 17/SCI01/007 COMPUTER SCIENCE ASSIGNMENT 1. With examples of different programming languages show how programming languages are organized along the given rubrics: i. Unstructured, structured, modular, object oriented, aspect oriented, activity oriented and event oriented programming requirement. ii. Based on domain requirements. iii. Based on requirements i and ii above. 2. Give brief preview of the evolution of programming languages in a chronological order. 3. Vividly distinguish between modular programming paradigm and object oriented programming paradigm. Answer 1i). UNSTRUCTURED LANGUAGE DEVELOPER DATE Assembly Language 1949 FORTRAN John Backus 1957 COBOL CODASYL, ANSI, ISO 1959 JOSS Cliff Shaw, RAND 1963 BASIC John G. Kemeny, Thomas E. Kurtz 1964 TELCOMP BBN 1965 MUMPS Neil Pappalardo 1966 FOCAL Richard Merrill, DEC 1968 STRUCTURED LANGUAGE DEVELOPER DATE ALGOL 58 Friedrich L. Bauer, and co. 1958 ALGOL 60 Backus, Bauer and co. 1960 ABC CWI 1980 Ada United States Department of Defence 1980 Accent R NIS 1980 Action! Optimized Systems Software 1983 Alef Phil Winterbottom 1992 DASL Sun Micro-systems Laboratories 1999-2003 MODULAR LANGUAGE DEVELOPER DATE ALGOL W Niklaus Wirth, Tony Hoare 1966 APL Larry Breed, Dick Lathwell and co. 1966 ALGOL 68 A. Van Wijngaarden and co. 1968 AMOS BASIC FranÇois Lionet anConstantin Stiropoulos 1990 Alice ML Saarland University 2000 Agda Ulf Norell;Catarina coquand(1.0) 2007 Arc Paul Graham, Robert Morris and co. 2008 Bosque Mark Marron 2019 OBJECT-ORIENTED LANGUAGE DEVELOPER DATE C* Thinking Machine 1987 Actor Charles Duff 1988 Aldor Thomas J. Watson Research Center 1990 Amiga E Wouter van Oortmerssen 1993 Action Script Macromedia 1998 BeanShell JCP 1999 AngelScript Andreas Jönsson 2003 Boo Rodrigo B. -

Moscow ML Library Documentation
Moscow ML Library Documentation Version 2.00 of June 2000 Sergei Romanenko, Russian Academy of Sciences, Moscow, Russia Claudio Russo, Cambridge University, Cambridge, United Kingdom Peter Sestoft, Royal Veterinary and Agricultural University, Copenhagen, Denmark This document This manual describes the Moscow ML library, which includes parts of the SML Basis Library and several extensions. The manual has been generated automatically from the commented signature files. Alternative formats of this document Hypertext on the World-Wide Web The manual is available at http://www.dina.kvl.dk/~sestoft/mosmllib/ for online browsing. Hypertext in the Moscow ML distribution The manual is available for offline browsing at mosml/doc/mosmllib/index.html in the distribution. On-line help in the Moscow ML interactive system The manual is available also in interactive mosml sessions. Type help "lib"; for an overview of built-in function libraries. Type help "fromstring"; for help on a particular identifier, such as fromString. This will produce a menu of all library structures which contain the identifier fromstring (disregarding the lowercase/uppercase distinction): -------------------------------- | 1 | val Bool.fromString | | 2 | val Char.fromString | | 3 | val Date.fromString | | 4 | val Int.fromString | | 5 | val Path.fromString | | 6 | val Real.fromString | | 7 | val String.fromString | | 8 | val Time.fromString | | 9 | val Word.fromString | | 10 | val Word8.fromString | -------------------------------- Choosing a number from this menu will invoke the -

Programming Language Use in US Academia and Industry
Informatics in Education, 2015, Vol. 14, No. 2, 143–160 143 © 2015 Vilnius University DOI: 10.15388/infedu.2015.09 Programming Language Use in US Academia and Industry Latifa BEN ARFA RABAI1, Barry COHEN2, Ali MILI2 1 Institut Superieur de Gestion, Bardo, 2000, Tunisia 2 CCS, NJIT, Newark NJ 07102-1982 USA e-mail: [email protected], [email protected], [email protected] Received: July 2014 Abstract. In the same way that natural languages influence and shape the way we think, program- ming languages have a profound impact on the way a programmer analyzes a problem and formu- lates its solution in the form of a program. To the extent that a first programming course is likely to determine the student’s approach to program design, program analysis, and programming meth- odology, the choice of the programming language used in the first programming course is likely to be very important. In this paper, we report on a recent survey we conducted on programming language use in US academic institutions, and discuss the significance of our data by comparison with programming language use in industry. Keywords: programming language use, academic institution, academic trends, programming lan- guage evolution, programming language adoption. 1. Introduction: Programming Language Adoption The process by which organizations and individuals adopt technology trends is complex, as it involves many diverse factors; it is also paradoxical and counter-intuitive, hence difficult to model (Clements, 2006; Warren, 2006; John C, 2006; Leo and Rabkin, 2013; Geoffrey, 2002; Geoffrey, 2002a; Yi, Li and Mili, 2007; Stephen, 2006). This general observation applies to programming languages in particular, where many carefully de- signed languages that have superior technical attributes fail to be widely adopted, while languages that start with modest ambitions and limited scope go on to be widely used in industry and in academia. -
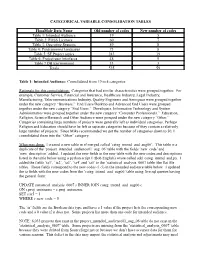
Categorical Variable Consolidation Tables
CATEGORICAL VARIABLE CONSOLIDATION TABLES FlossMole Data Name Old number of codes New number of codes Table 1: Intended Audience 19 5 Table 2: FOSS Licenses 60 7 Table 3: Operating Systems 59 8 Table 4: Programming languages 73 8 Table 5: SF Project topics 243 19 Table 6: Project user interfaces 48 9 Table 7 DB Environment 33 3 Totals 535 59 Table 1: Intended Audience: Consolidated from 19 to 4 categories Rationale for this consolidation: Categories that had similar characteristics were grouped together. For example, Customer Service, Financial and Insurance, Healthcare Industry, Legal Industry, Manufacturing, Telecommunications Industry, Quality Engineers and Aerospace were grouped together under the new category “Business.” End Users/Desktop and Advanced End Users were grouped together under the new category “End Users.” Developers, Information Technology and System Administrators were grouped together under the new category “Computer Professionals.” Education, Religion, Science/Research and Other Audience were grouped under the new category “Other.” Categories containing large numbers of projects were generally left as individual categories. Perhaps Religion and Education should have be left as separate categories because of they contain a relatively large number of projects. Since Mike recommended we get the number of categories down to 50, I consolidated them into the “Other” category. What was done: I created a new table in sf merged called ‘categ_intend_aud_aug06’. This table is a duplicate of the ‘project_intended_audience01_aug_06’ table with the fields ‘new_code’ and ‘new_description’ added. I updated the new fields in the new table with the new codes and descriptions listed in the table below using a python script I (Bob English) wrote called add_categ_intend_aud.py. -

From Krivine's Machine to the Caml Implementations
From Krivine's machine to the Caml implementations Xavier Leroy INRIA Rocquencourt 1 In this talk An illustration of the strengths and limitations of abstract machines for the purpose of e±cient execution of strict functional languages (Caml). 1. A retrospective on the ZAM, a call-by-value variant of Krivine's machine. 2. From abstract machines to e±cient P.L. implementations: the example of Caml Light and Objective Caml. 3. Beyond abstract machines: push-enter models vs. eval-apply models. 2 Why are abstract machines interesting? On the theory side (λ-calculus, semantics): Abstract machines expose concepts lacking or implicit in the λ-calculus: • Reduction strategy, evaluation order. • Data representations, esp. closures and environments. On the implementation side: Compilation to abstract machine code o®ers much better performance than interpreters. Abstract machine code as an intermediate language for machine-code generation. Abstract machine code as an architecture-independent low-level format for distributing compiled programs (JVM, .Net). 3 There are better ways In every area where abstract machines help, there are arguably better alternatives: • Exposing reduction order: CPS transformation, structured operational semantics, reduction contexts. • Closures and environments: explicit substitutions. • E±cient execution: optimizing compilation to real machine code. • Intermediate languages: RTL, SSA, CPS, A-normal forms, etc. • Code distribution: ANDF (?). Abstract machines do many things well but none very well. This we will illustrate in the case of e±cient execution of Caml. 4 A retrospective on the ZAM 5 The starting point The Caml language and implementation circa 1989: • Core ML (CBV λ-calculus) with primitives, data types and pattern-matching. -

The Definition of Standard ML, Revised
The Definition of Standard ML The Definition of Standard ML (Revised) Robin Milner, Mads Tofte, Robert Harper and David MacQueen The MIT Press Cambridge, Massachusetts London, England c 1997 Robin Milner All rights reserved. No part of this book may be reproduced in any form by any electronic or mechanical means (including photocopying, recording, or information storage and retrieval) without permission in writing from the publisher. Printed and bound in the United States of America. Library of Congress Cataloging-in-Publication Data The definition of standard ML: revised / Robin Milner ::: et al. p. cm. Includes bibliographical references and index. ISBN 0-262-63181-4 (alk. paper) 1. ML (Computer program language) I. Milner, R. (Robin), 1934- QA76.73.M6D44 1997 005:1303|dc21 97-59 CIP Contents 1 Introduction 1 2 Syntax of the Core 3 2.1 Reserved Words . 3 2.2 Special constants . 3 2.3 Comments . 4 2.4 Identifiers . 5 2.5 Lexical analysis . 6 2.6 Infixed operators . 6 2.7 Derived Forms . 7 2.8 Grammar . 7 2.9 Syntactic Restrictions . 9 3 Syntax of Modules 12 3.1 Reserved Words . 12 3.2 Identifiers . 12 3.3 Infixed operators . 12 3.4 Grammar for Modules . 13 3.5 Syntactic Restrictions . 13 4 Static Semantics for the Core 16 4.1 Simple Objects . 16 4.2 Compound Objects . 17 4.3 Projection, Injection and Modification . 17 4.4 Types and Type functions . 19 4.5 Type Schemes . 19 4.6 Scope of Explicit Type Variables . 20 4.7 Non-expansive Expressions . 21 4.8 Closure . -

Bitwise Instructions
Bitwise Instructions CSE 30: Computer Organization and Systems Programming Dept. of Computer Science and Engineering University of California, San Diego Overview vBitwise Instructions vShifts and Rotates vARM Arithmetic Datapath Logical Operators vBasic logical operators: vAND: outputs 1 only if both inputs are 1 vOR: outputs 1 if at least one input is 1 vXOR: outputs 1 if exactly one input is 1 vIn general, can define them to accept >2 inputs, but in the case of ARM assembly, both of these accept exactly 2 inputs and produce 1 output vAgain, rigid syntax, simpler hardware Logical Operators vTruth Table: standard table listing all possible combinations of inputs and resultant output for each vTruth Table for AND, OR and XOR A B A AND B A OR B A XOR B A BIC B 0 0 0 0 0 0 0 1 0 1 1 0 1 0 0 1 1 1 1 1 1 1 0 0 Uses for Logical Operators vNote that ANDing a bit with 0 produces a 0 at the output while ANDing a bit with 1 produces the original bit. vThis can be used to create a mask. vExample: 1011 0110 1010 0100 0011 1101 1001 1010 mask: 0000 0000 0000 0000 0000 1111 1111 1111 vThe result of ANDing these: 0000 0000 0000 0000 0000 1101 1001 1010 mask last 12 bits Uses for Logical Operators vSimilarly, note that ORing a bit with 1 produces a 1 at the output while ORing a bit with 0 produces the original bit. vThis can be used to force certain bits of a string to 1s.