Drscheme: a Pedagogic Programming Environment for Scheme
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Optimized R5RS Macro Expander
An Optimized R5RS Macro Expander Sean Reque A thesis submitted to the faculty of Brigham Young University in partial fulfillment of the requirements for the degree of Master of Science Jay McCarthy, Chair Eric Mercer Quinn Snell Department of Computer Science Brigham Young University February 2013 Copyright c 2013 Sean Reque All Rights Reserved ABSTRACT An Optimized R5RS Macro Expander Sean Reque Department of Computer Science, BYU Master of Science Macro systems allow programmers abstractions over the syntax of a programming language. This gives the programmer some of the same power posessed by a programming language designer, namely, the ability to extend the programming language to fit the needs of the programmer. The value of such systems has been demonstrated by their continued adoption in more languages and platforms. However, several barriers to widespread adoption of macro systems still exist. The language Racket [6] defines a small core of primitive language constructs, including a powerful macro system, upon which all other features are built. Because of this design, many features of other programming languages can be implemented through libraries, keeping the core language simple without sacrificing power or flexibility. However, slow macro expansion remains a lingering problem in the language's primary implementation, and in fact macro expansion currently dominates compile times for Racket modules and programs. Besides the typical problems associated with slow compile times, such as slower testing feedback, increased mental disruption during the programming process, and unscalable build times for large projects, slow macro expansion carries its own unique problems, such as poorer performance for IDEs and other software analysis tools. -

The Evolution of Lisp
1 The Evolution of Lisp Guy L. Steele Jr. Richard P. Gabriel Thinking Machines Corporation Lucid, Inc. 245 First Street 707 Laurel Street Cambridge, Massachusetts 02142 Menlo Park, California 94025 Phone: (617) 234-2860 Phone: (415) 329-8400 FAX: (617) 243-4444 FAX: (415) 329-8480 E-mail: [email protected] E-mail: [email protected] Abstract Lisp is the world’s greatest programming language—or so its proponents think. The structure of Lisp makes it easy to extend the language or even to implement entirely new dialects without starting from scratch. Overall, the evolution of Lisp has been guided more by institutional rivalry, one-upsmanship, and the glee born of technical cleverness that is characteristic of the “hacker culture” than by sober assessments of technical requirements. Nevertheless this process has eventually produced both an industrial- strength programming language, messy but powerful, and a technically pure dialect, small but powerful, that is suitable for use by programming-language theoreticians. We pick up where McCarthy’s paper in the first HOPL conference left off. We trace the development chronologically from the era of the PDP-6, through the heyday of Interlisp and MacLisp, past the ascension and decline of special purpose Lisp machines, to the present era of standardization activities. We then examine the technical evolution of a few representative language features, including both some notable successes and some notable failures, that illuminate design issues that distinguish Lisp from other programming languages. We also discuss the use of Lisp as a laboratory for designing other programming languages. We conclude with some reflections on the forces that have driven the evolution of Lisp. -

Structured Foreign Types
Ftypes: Structured foreign types Andrew W. Keep R. Kent Dybvig Indiana University fakeep,[email protected] Abstract When accessing scalar elements within an ftype, the value of the High-level programming languages, like Scheme, typically repre- scalar is automatically marshaled into the equivalent Scheme rep- sent data in ways that differ from the host platform to support resentation. When setting scalar elements, the Scheme value is consistent behavior across platforms and automatic storage man- checked to ensure compatibility with the specified foreign type, and agement, i.e., garbage collection. While crucial to the program- then marshaled into the equivalent foreign representation. Ftypes ming model, differences in data representation can complicate in- are well integrated into the system, with compiler support for ef- teraction with foreign programs and libraries that employ machine- ficient access to foreign data and debugger support for convenient dependent data structures that do not readily support garbage col- inspection of foreign data. lection. To bridge this gap, many high-level languages feature for- The ftype syntax is convenient and flexible. While it is similar in eign function interfaces that include some ability to interact with some ways to foreign data declarations in other Scheme implemen- foreign data, though they often do not provide complete control tations, and language design is largely a matter of taste, we believe over the structure of foreign data, are not always fully integrated our syntax is cleaner and more intuitive than most. Our system also into the language and run-time system, and are often not as effi- has a more complete set of features, covering all C data types along cient as possible. -

Chez Scheme Version 5 Release Notes Copyright C 1994 Cadence Research Systems All Rights Reserved October 1994 Overview 1. Funct
Chez Scheme Version 5 Release Notes Copyright c 1994 Cadence Research Systems All Rights Reserved October 1994 Overview This document outlines the changes made to Chez Scheme for Version 5 since Version 4. New items include support for syntax-case and revised report high-level lexical macros, support for multiple values, support for guardians and weak pairs, support for generic ports, improved trace output, support for shared incremental heaps, support for passing single floats to and returning single floats from foreign procedures, support for passing structures to and returning structures from foreign procedures on MIPS-based computers, and various performance enhancements, including a dramatic improvement in the time it takes to load Scheme source and object files on DEC Ultrix MIPS-based computers. Overall performance of generated code has increased by an average of 15–50 percent over Version 4 depending upon optimize level and programming style. Programs that make extensive use of locally-defined procedures will benefit more than programs that rely heavily on globally-defined procedures, and programs compiled at higher optimize levels will improve more than programs compiled at lower optimize levels. Compile time is approximately 25 percent faster. Refer to the Chez Scheme System Manual, Revision 2.5 for detailed descriptions of the new or modified procedures and syntactic forms mentioned in these notes. Version 5 is available for the following platforms: • Sun Sparc SunOS 4.X & Solaris 2.X • DEC Alpha AXP OSF/1 V2.X • Silicon Graphics IRIX 5.X • Intel 80x86 NeXT Mach 3.2 • Motorola Delta MC88000 SVR3 & SVR4 • Decstation/Decsystem Ultrix 4.3A • Intel 80x86 BSDI BSD/386 1.1 • Intel 80x86 Linux This document contains four sections describing (1) functionality enhancements, (2) performance enhance- ments, (3) bugs fixed, and (4) compatibility issues. -

Lisp: Final Thoughts
20 Lisp: Final Thoughts Both Lisp and Prolog are based on formal mathematical models of computation: Prolog on logic and theorem proving, Lisp on the theory of recursive functions. This sets these languages apart from more traditional languages whose architecture is just an abstraction across the architecture of the underlying computing (von Neumann) hardware. By deriving their syntax and semantics from mathematical notations, Lisp and Prolog inherit both expressive power and clarity. Although Prolog, the newer of the two languages, has remained close to its theoretical roots, Lisp has been extended until it is no longer a purely functional programming language. The primary culprit for this diaspora was the Lisp community itself. The pure lisp core of the language is primarily an assembly language for building more complex data structures and search algorithms. Thus it was natural that each group of researchers or developers would “assemble” the Lisp environment that best suited their needs. After several decades of this the various dialects of Lisp were basically incompatible. The 1980s saw the desire to replace these multiple dialects with a core Common Lisp, which also included an object system, CLOS. Common Lisp is the Lisp language used in Part III. But the primary power of Lisp is the fact, as pointed out many times in Part III, that the data and commands of this language have a uniform structure. This supports the building of what we call meta-interpreters, or similarly, the use of meta-linguistic abstraction. This, simply put, is the ability of the program designer to build interpreters within Lisp (or Prolog) to interpret other suitably designed structures in the language. -

Supplementary Material Forrebuilding Racket on Chez Scheme
Supplementary Material for Rebuilding Racket on Chez Scheme (Experience Report) MATTHEW FLATT, University of Utah, USA CANER DERICI, Indiana University, USA R. KENT DYBVIG, Cisco Systems, Inc., USA ANDREW W. KEEP, Cisco Systems, Inc., USA GUSTAVO E. MASSACCESI, Universidad de Buenos Aires, Argentina SARAH SPALL, Indiana University, USA SAM TOBIN-HOCHSTADT, Indiana University, USA JON ZEPPIERI, independent researcher, USA All benchmark measurements were performed on an Intel Core i7-2600 3.4GHz processor running 64-bit Linux. Except as specifically noted, we used Chez Scheme 9.5.3 commit 7df2fb2e77 at github:cicso/ChezScheme, modified as commit 6d05b70e86 at github:racket/ChezScheme, and Racket 7.3.0.3 as commit ff95f1860a at github:racket/racket. 1 TRADITIONAL SCHEME BENCHMARKS The traditional Scheme benchmarks in figure1 are based on a suite of small programs that have been widely used to compare Scheme implementations. The benchmark sources are in the "common" directory of the racket-benchmarks package in the Racket GitHub repository. The results are in two groups, where the group starting with scheme-c uses mutable pairs, so they are run in Racket as #lang r5rs programs; for Racket CS we expect overhead due to the use of a record datatype for mutable pairs, instead of Chez Scheme’s built-in pairs. The groups are sorted by the ratio of times for Chez Scheme and the current Racket imple- mentation. Note that the break-even point is near the end of the first group. The racket collatz benchmark turns out to mostly measure the performance of the built-in division operator for rational numbers, while fft and nucleic benefit from flonum unboxing. -

1. with Examples of Different Programming Languages Show How Programming Languages Are Organized Along the Given Rubrics: I
AGBOOLA ABIOLA CSC302 17/SCI01/007 COMPUTER SCIENCE ASSIGNMENT 1. With examples of different programming languages show how programming languages are organized along the given rubrics: i. Unstructured, structured, modular, object oriented, aspect oriented, activity oriented and event oriented programming requirement. ii. Based on domain requirements. iii. Based on requirements i and ii above. 2. Give brief preview of the evolution of programming languages in a chronological order. 3. Vividly distinguish between modular programming paradigm and object oriented programming paradigm. Answer 1i). UNSTRUCTURED LANGUAGE DEVELOPER DATE Assembly Language 1949 FORTRAN John Backus 1957 COBOL CODASYL, ANSI, ISO 1959 JOSS Cliff Shaw, RAND 1963 BASIC John G. Kemeny, Thomas E. Kurtz 1964 TELCOMP BBN 1965 MUMPS Neil Pappalardo 1966 FOCAL Richard Merrill, DEC 1968 STRUCTURED LANGUAGE DEVELOPER DATE ALGOL 58 Friedrich L. Bauer, and co. 1958 ALGOL 60 Backus, Bauer and co. 1960 ABC CWI 1980 Ada United States Department of Defence 1980 Accent R NIS 1980 Action! Optimized Systems Software 1983 Alef Phil Winterbottom 1992 DASL Sun Micro-systems Laboratories 1999-2003 MODULAR LANGUAGE DEVELOPER DATE ALGOL W Niklaus Wirth, Tony Hoare 1966 APL Larry Breed, Dick Lathwell and co. 1966 ALGOL 68 A. Van Wijngaarden and co. 1968 AMOS BASIC FranÇois Lionet anConstantin Stiropoulos 1990 Alice ML Saarland University 2000 Agda Ulf Norell;Catarina coquand(1.0) 2007 Arc Paul Graham, Robert Morris and co. 2008 Bosque Mark Marron 2019 OBJECT-ORIENTED LANGUAGE DEVELOPER DATE C* Thinking Machine 1987 Actor Charles Duff 1988 Aldor Thomas J. Watson Research Center 1990 Amiga E Wouter van Oortmerssen 1993 Action Script Macromedia 1998 BeanShell JCP 1999 AngelScript Andreas Jönsson 2003 Boo Rodrigo B. -

Programming Language Use in US Academia and Industry
Informatics in Education, 2015, Vol. 14, No. 2, 143–160 143 © 2015 Vilnius University DOI: 10.15388/infedu.2015.09 Programming Language Use in US Academia and Industry Latifa BEN ARFA RABAI1, Barry COHEN2, Ali MILI2 1 Institut Superieur de Gestion, Bardo, 2000, Tunisia 2 CCS, NJIT, Newark NJ 07102-1982 USA e-mail: [email protected], [email protected], [email protected] Received: July 2014 Abstract. In the same way that natural languages influence and shape the way we think, program- ming languages have a profound impact on the way a programmer analyzes a problem and formu- lates its solution in the form of a program. To the extent that a first programming course is likely to determine the student’s approach to program design, program analysis, and programming meth- odology, the choice of the programming language used in the first programming course is likely to be very important. In this paper, we report on a recent survey we conducted on programming language use in US academic institutions, and discuss the significance of our data by comparison with programming language use in industry. Keywords: programming language use, academic institution, academic trends, programming lan- guage evolution, programming language adoption. 1. Introduction: Programming Language Adoption The process by which organizations and individuals adopt technology trends is complex, as it involves many diverse factors; it is also paradoxical and counter-intuitive, hence difficult to model (Clements, 2006; Warren, 2006; John C, 2006; Leo and Rabkin, 2013; Geoffrey, 2002; Geoffrey, 2002a; Yi, Li and Mili, 2007; Stephen, 2006). This general observation applies to programming languages in particular, where many carefully de- signed languages that have superior technical attributes fail to be widely adopted, while languages that start with modest ambitions and limited scope go on to be widely used in industry and in academia. -
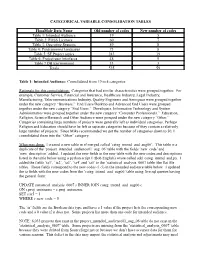
Categorical Variable Consolidation Tables
CATEGORICAL VARIABLE CONSOLIDATION TABLES FlossMole Data Name Old number of codes New number of codes Table 1: Intended Audience 19 5 Table 2: FOSS Licenses 60 7 Table 3: Operating Systems 59 8 Table 4: Programming languages 73 8 Table 5: SF Project topics 243 19 Table 6: Project user interfaces 48 9 Table 7 DB Environment 33 3 Totals 535 59 Table 1: Intended Audience: Consolidated from 19 to 4 categories Rationale for this consolidation: Categories that had similar characteristics were grouped together. For example, Customer Service, Financial and Insurance, Healthcare Industry, Legal Industry, Manufacturing, Telecommunications Industry, Quality Engineers and Aerospace were grouped together under the new category “Business.” End Users/Desktop and Advanced End Users were grouped together under the new category “End Users.” Developers, Information Technology and System Administrators were grouped together under the new category “Computer Professionals.” Education, Religion, Science/Research and Other Audience were grouped under the new category “Other.” Categories containing large numbers of projects were generally left as individual categories. Perhaps Religion and Education should have be left as separate categories because of they contain a relatively large number of projects. Since Mike recommended we get the number of categories down to 50, I consolidated them into the “Other” category. What was done: I created a new table in sf merged called ‘categ_intend_aud_aug06’. This table is a duplicate of the ‘project_intended_audience01_aug_06’ table with the fields ‘new_code’ and ‘new_description’ added. I updated the new fields in the new table with the new codes and descriptions listed in the table below using a python script I (Bob English) wrote called add_categ_intend_aud.py. -

From Krivine's Machine to the Caml Implementations
From Krivine's machine to the Caml implementations Xavier Leroy INRIA Rocquencourt 1 In this talk An illustration of the strengths and limitations of abstract machines for the purpose of e±cient execution of strict functional languages (Caml). 1. A retrospective on the ZAM, a call-by-value variant of Krivine's machine. 2. From abstract machines to e±cient P.L. implementations: the example of Caml Light and Objective Caml. 3. Beyond abstract machines: push-enter models vs. eval-apply models. 2 Why are abstract machines interesting? On the theory side (λ-calculus, semantics): Abstract machines expose concepts lacking or implicit in the λ-calculus: • Reduction strategy, evaluation order. • Data representations, esp. closures and environments. On the implementation side: Compilation to abstract machine code o®ers much better performance than interpreters. Abstract machine code as an intermediate language for machine-code generation. Abstract machine code as an architecture-independent low-level format for distributing compiled programs (JVM, .Net). 3 There are better ways In every area where abstract machines help, there are arguably better alternatives: • Exposing reduction order: CPS transformation, structured operational semantics, reduction contexts. • Closures and environments: explicit substitutions. • E±cient execution: optimizing compilation to real machine code. • Intermediate languages: RTL, SSA, CPS, A-normal forms, etc. • Code distribution: ANDF (?). Abstract machines do many things well but none very well. This we will illustrate in the case of e±cient execution of Caml. 4 A retrospective on the ZAM 5 The starting point The Caml language and implementation circa 1989: • Core ML (CBV λ-calculus) with primitives, data types and pattern-matching. -

23 Things I Know About Modules for Scheme
23 things I know about modules for Scheme Christian Queinnec Université Paris 6 — Pierre et Marie Curie LIP6, 4 place Jussieu, 75252 Paris Cedex — France [email protected] ABSTRACT difficult to deliver (or even rebuild) stand-alone systems. The benefits of modularization are well known. However, Interfaces as collection of names — If modules are about shar- modules are not standard in Scheme. This paper accompanies ing, what should be shared ? Values, locations (that is an invited talk at the Scheme Workshop 2002 on the current variables), types, classes (and their cortege` of accessors, state of modules for Scheme. Implementation is not addressed, constructors and predicates) ? only linguistic features are covered. Cave lector, this paper only reflects my own and instanta- The usual answer in Scheme is to share locations with neous biases! (quite often) two additional properties: (i) these loca- tions can only be mutated from the body of their defin- ing modules (this favors block compilation), (ii) they 1. MODULES should hold functions (and this should be statically (and The benefits of modularization within conventional languages easily) discoverable). This restricts linking with other are well known. Modules dissociate interfaces and implemen- (foreign) languages that may export locations holding tations; they allow separate compilation (or at least indepen- non-functional data (the errno location for instance). dent compilation a` la C). Modules tend to favor re-usability, This is not a big restriction since modern interfaces (Corba common libraries and cross language linkage. for example) tend to exclusively use functions (or meth- Modules discipline name spaces with explicit names expo- ods). -

Programming Languages As Operating Systems
Programming Languages as Op erating Systems (or Revenge of the Son of the Lisp Machine) Matthew Flatt Rob ert Bruce Findler Shriram Krishnamurthi Matthias Felleisen Department of Computer Science Rice University Houston, Texas 77005-1892 reclaim the program's resources|even though the program Abstract and DrScheme share a single virtual machine. The MrEd virtual machine serves b oth as the implementa- To address this problem, MrEd provides a small set of tion platform for the DrScheme programming environment, new language constructs. These constructs allow a program- and as the underlying Scheme engine for executing expres- running program, suchasDrScheme, to run nested programs sions and programs entered into DrScheme's read-eval-print directly on the MrEd virtual machine without sacri cing lo op. We describ e the key elements of the MrEd virtual control over the nested programs. As a result, DrScheme machine for building a programming environment, and we can execute a copyofDrScheme that is executing its own step through the implementation of a miniature version of copy of DrScheme (see Figure 1). The inner and middle DrScheme in MrEd. More generally,weshowhow MrEd de- DrSchemes cannot interfere with the op eration of the outer nes a high-level op erating system for graphical programs. DrScheme, and the middle DrScheme cannot interfere with the outer DrScheme's control over the inner DrScheme. In this pap er, we describ e the key elements of the MrEd 1 MrEd: A Scheme Machine virtual machine, and we step through the implementation of a miniature version of DrScheme in MrEd. More gen- The DrScheme programming environment [10] provides stu- erally,weshowhow MrEd de nes a high-level op erating dents and programmers with a user-friendly environment system (OS) for graphical programs.