Extracting Structured Data from Two Large Web Corpora
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Semantic Skin: from Flat Textual Content to Interconnected Repositories Of
Semantic Skin: from flat textual content to interconnected repositories of semantic data. Claudio Baldassarre ABSTRACT front-end web application. This application offers a faceted One approach to re-balancing the Digital Divide tends to view of the underlying \news-KB". The current blog site favor the production of informative content in flat formats, appearance is merely a stylistic choice, while a running in- which are easy to distribute and consume. At the same time stance is always backed by a SPARQL endpoint over the this approach forbids to deliver the core knowledge perti- \news-KB". The facets are typically rendered as menu ele- nent within the content; i.e. it increases the Knowledge ments5: some menus facet the entire \news-KB" (e.g., news Divide. In some international organizations1, informative Topics, or Provenance); while other menus facet only the content distribution to groups in Latin America happens by content currently visible to the users. The faceting mech- manually collecting text-based content, then disseminating anism is also applied tothe \news archive" as a time-based it via standard mailing lists, or databases copies sent out facet of the repository content. All the facets are popu- regularly. Our demo showcases the use of Semantic Skin lated with SPARQL queries over the \news-model" instances a technology that after semantifying the content submit- in the \news-KB". Each news item is then presented with ted in flat formats, provides access to the information via a its summary, title, publication date, and provenance (e.g., knowledge layer, which is, however, transparent to the end permalink). -

Hidden Meaning
FEATURES Microdata and Microformats Kit Sen Chin, 123RF.com Chin, Sen Kit Working with microformats and microdata Hidden Meaning Programs aren’t as smart as humans when it comes to interpreting the meaning of web information. If you want to maximize your search rank, you might want to dress up your HTML documents with microformats and microdata. By Andreas Möller TML lets you mark up sections formats and microdata into your own source code for the website shown in of text as headings, body text, programs. Figure 1 – an HTML5 document with a hyperlinks, and other web page business card. The Heading text block is H elements. However, these defi- Microformats marked up with the element h1. The text nitions have nothing to do with the HTML was originally designed for hu- for the business card is surrounded by meaning of the data: Does the text refer mans to read, but with the explosive the div container element, and <br/> in- to a person, an organization, a product, growth of the web, programs such as troduces a line break. or an event? Microformats [1] and their search engines also process HTML data. It is easy for a human reader to see successor, microdata [2] make the mean- What do programs that read HTML data that the data shown in Figure 1 repre- ing a bit more clear by pointing to busi- typically find? Listing 1 shows the HTML sents a business card – even if the text is ness cards, product descriptions, offers, and event data in a machine-readable LISTING 1: HTML5 Document with Business Card way. -

Le Microformat Hproduct C'est Quoi ? Pourquoi Utiliser Le Microformat
Apprendre à utiliser les microformats : hProduct 2017-02-21 23:02:01 Nicolaseo Le microformat hProduct c’est quoi ? hProduct est un microformat approprié pour publier et embarquer les données de vos produits. C’est une sorte de méta tags qui permet de structurer vos données pour permettre aux robots des moteurs de recherche de mieux référencer votre contenu. Pourquoi utiliser le microformat hProduct Le microformat hProduct est basé sur un ensemble de champs très important pour communiquer avec les robots des moteurs de recherche comme Google. Utiliser les {meta- tags|richsnippets|microformats} (et tout ce qui peut permettre aux moteurs de recherche de mieux classer votre contenu) vous apportera plus de visibilité sur internet grâce à un meilleur référencement de votre site et de son contenu. Comment utiliser le microformat hProduct Le schéma hProduct se compose de ce qui suit : hproduct brand. optionnel. texte. peut aussi utiliser hCard pour les fabricants. category. optionnel. texte. peut aussi utiliser rel-tag. ré-utilisé à partir de hCard. price. optionnel. floating point number. peut utiliser un format de devise. description. optionnel. texte. peut aussi inclure un marquage HTML valide. réutilisé à partir de hReview. fn. requis. texte. nom du produit ou titre. réutilisé de hCard. photo. optionnel. élément image ou lien. réutilisé de hCard. url. optionnel. href. peut contenir rel-tag rel=’product’. ré-utilisé de hCard. review. optionnel. hReview, ou hReview-aggregate. listing. optionnel. hListing, ou hListing-aggregate. identifier. optionnel. type. requis. – exemples : model mpn upc isbn issn ean jan sn vin sku value. requis. – l’étiquette peut être implicite. Détails des champs du microformat hProduct Les noms de classe category, fn, photo, url sont réutilisés à partir de hCard. -

Where Is the Semantic Web? – an Overview of the Use of Embeddable Semantics in Austria
Where Is The Semantic Web? – An Overview of the Use of Embeddable Semantics in Austria Wilhelm Loibl Institute for Service Marketing and Tourism Vienna University of Economics and Business, Austria [email protected] Abstract Improving the results of search engines and enabling new online applications are two of the main aims of the Semantic Web. For a machine to be able to read and interpret semantic information, this content has to be offered online first. With several technologies available the question arises which one to use. Those who want to build the software necessary to interpret the offered data have to know what information is available and in which format. In order to answer these questions, the author analysed the business websites of different Austrian industry sectors as to what semantic information is embedded. Preliminary results show that, although overall usage numbers are still small, certain differences between individual sectors exist. Keywords: semantic web, RDFa, microformats, Austria, industry sectors 1 Introduction As tourism is a very information-intense industry (Werthner & Klein, 1999), especially novel users resort to well-known generic search engines like Google to find travel related information (Mitsche, 2005). Often, these machines do not provide satisfactory search results as their algorithms match a user’s query against the (weighted) terms found in online documents (Berry and Browne, 1999). One solution to this problem lies in “Semantic Searches” (Maedche & Staab, 2002). In order for them to work, web resources must first be annotated with additional metadata describing the content (Davies, Studer & Warren., 2006). Therefore, anyone who wants to provide data online must decide on which technology to use. -

Appendix a the Ten Commandments for Websites
Appendix A The Ten Commandments for Websites Welcome to the appendixes! At this stage in your learning, you should have all the basic skills you require to build a high-quality website with insightful consideration given to aspects such as accessibility, search engine optimization, usability, and all the other concepts that web designers and developers think about on a daily basis. Hopefully with all the different elements covered in this book, you now have a solid understanding as to what goes into building a website (much more than code!). The main thing you should take from this book is that you don’t need to be an expert at everything but ensuring that you take the time to notice what’s out there and deciding what will best help your site are among the most important elements of the process. As you leave this book and go on to updating your website over time and perhaps learning new skills, always remember to be brave, take risks (through trial and error), and never feel that things are getting too hard. If you choose to learn skills that were only briefly mentioned in this book, like scripting, or to get involved in using content management systems and web software, go at a pace that you feel comfortable with. With that in mind, let’s go over the 10 most important messages I would personally recommend. After that, I’ll give you some useful resources like important websites for people learning to create for the Internet and handy software. Advice is something many professional designers and developers give out in spades after learning some harsh lessons from what their own bitter experiences. -

Microformats the Next (Small) Thing on the Semantic Web?
Standards Editor: Jim Whitehead • [email protected] Microformats The Next (Small) Thing on the Semantic Web? Rohit Khare • CommerceNet “Designed for humans first and machines second, microformats are a set of simple, open data formats built upon existing and widely adopted standards.” — Microformats.org hen we speak of the “evolution of the is precisely encoding the great variety of person- Web,” it might actually be more appropri- al, professional, and genealogical relationships W ate to speak of “intelligent design” — we between people and organizations. By contrast, can actually point to a living, breathing, and an accidental challenge is that any blogger with actively involved Creator of the Web. We can even some knowledge of HTML can add microformat consult Tim Berners-Lee’s stated goals for the markup to a text-input form, but uploading an “promised land,” dubbed the Semantic Web. Few external file dedicated to machine-readable use presume we could reach those objectives by ran- remains forbiddingly complex with most blog- domly hacking existing Web standards and hop- ging tools. ing that “natural selection” by authors, software So, although any intelligent designer ought to developers, and readers would ensure powerful be able to rely on the long-established facility of enough abstractions for it. file transfer to publish the “right” model of a social Indeed, the elegant and painstakingly inter- network, the path of least resistance might favor locked edifice of technologies, including RDF, adding one of a handful of fixed tags to an exist- XML, and query languages is now growing pow- ing indirect form — the “blogroll” of hyperlinks to erful enough to attack massive information chal- other people’s sites. -
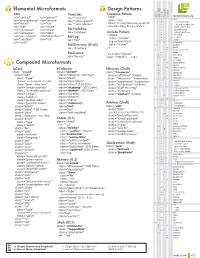
Microformats Cheat Sheet
Elemental Microformats Design Patterns tom eview Datetime Pattern esume XFN VoteLinks microformats.org hR hR hCard hCalendar rel="contact" rel="parent" rev="vote-for" <abbr hA rel="acquaintance" rel="spouse" class="foo" • adr rev="vote-against" + country-name title="YYYY-MM-DDTHH:MM:SS+ZZ:ZZ" rel="friend" rel="kin" rev="vote-abstain" • extended-address rel="met" rel="muse" >Human Date Time</abbr> + post-office-box rel="co-worker" rel="crush" Rel-Nofollow + postal-code rel="colleague" rel="date" rel="nofollow" Include Pattern • street-address + locality rel="co-resident" rel="sweetheart" <object Rel-Tag class="include" + region rel="neighbor" rel="me" rel="tag" • type rel="child" type="text/html" • affiliation Rel-Directory (Draft) data="#idref" ¤ author rel="directory" /> + best × + bookmark (rel) Rel-License + bday <a class="include" • • category rel="license" href="#idref">...</a> + + class × contact Compound Microformats + description + dtend + dtreviewed hCard hCalendar hResume (Draft) × dtstart class="vcard" class="vevent" class="hresume" × dtstamp class="adr" class="category" rel="tag" class="affiliation" (hcard) duration class="type" class="class" class="education" (hcalendar) • education [work|home|pref|postal|dom|intl] class="description" • email class="experience" (hcalendar) • type class="post-office-box" class="dtend" (ISO Date) class="publication" (citation) • value class="street-address" class="dtstamp" (ISO Date) class="skill" rel="tag" × entry-content class="extended-address" class="dtstart" (ISO Date) class="summary" • entry-summary -

978-3-642-23300-5 6 Chapter.Pd
The Problem of Conceptual Incompatibility Simon Mcginnes To cite this version: Simon Mcginnes. The Problem of Conceptual Incompatibility. 1st Availability, Reliability and Security (CD-ARES), Aug 2011, Vienna, Austria. pp.69-81, 10.1007/978-3-642-23300-5_6. hal-01590394 HAL Id: hal-01590394 https://hal.inria.fr/hal-01590394 Submitted on 19 Sep 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution| 4.0 International License The Problem of Conceptual Incompatibility Exploring the Potential of Conceptual Data Independence to Ease Data Integration Simon McGinnes Trinity College Dublin, Dublin 2, Ireland [email protected] Abstract. Application interoperability and data exchange are desirable goals, but conventional system design practices make these goals difficult to achieve, since they create heterogeneous, incompatible conceptual structures. This conceptual incompatibility increases system development, maintenance and integration workloads unacceptably. Conceptual data independence (CDI) is proposed as a way of overcoming these problems. Under CDI, data is stored and exchanged in a form which is invariant with respect to conceptual structures; data corresponding to multiple schemas can co-exist within the same application without loss of integrity. -

Microformats: Empowering Your Markup for Web 2.0
Microformats: Empowering Your Markup for Web 2.0 John Allsopp Microformats: Empowering Your Markup for Web 2.0 Copyright © 2007 by John Allsopp All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage or retrieval system, without the prior written permission of the copyright owner and the publisher. ISBN-13 (pbk): 978-1-59059814-6 ISBN-10 (pbk): 1-59059-814-8 Printed and bound in the United States of America 9 8 7 6 5 4 3 2 1 Trademarked names may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, we use the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. Distributed to the book trade worldwide by Springer-Verlag New York, Inc., 233 Spring Street, 6th Floor, New York, NY 10013. Phone 1-800-SPRINGER, fax 201-348-4505, e-mail [email protected],or visit www.springeronline.com. For information on translations, please contact Apress directly at 2560 Ninth Street, Suite 219, Berkeley, CA 94710. Phone 510-549-5930, fax 510-549-5939, e-mail [email protected], or visit www.apress.com. The information in this book is distributed on an “as is” basis, without warranty. Although every precaution has been taken in the preparation of this work, neither the author(s) nor Apress shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the information contained in this work. -

Rdfa Versus Microformats: Exploring the Potential for Semantic Interoperability of Mash-Up Personal Learning Environments
RDFa versus Microformats: Exploring the Potential for Semantic Interoperability of Mash-up Personal Learning Environments Vladimir Tomberg, Mart Laanpere Tallinn University, Narva mnt. 25, 10120 Tallinn, Estonia [email protected], [email protected] Abstract. This paper addresses the possibilities for increasing semantic interoperability of mash-up learning environments through the use of automatically processed metadata associated with both learning resources and learning process. We analyze and compare potential of two competing technologies for this purpose: microformats and RDFa. 1 Introduction Mash-up Personal Learning Environments have become a fast developing trend in the world of technology-enhanced learning, partly because of their flexibility and lightweight integration features. Although it is quite easy to aggregate the RSS feeds from the blogs of learners, it is more difficult to get an overview of course and its learning activities. A course is not just a syllabus, it also involves various dynamic processes that can be described in many aspects. The course always has certain learning goals, a schedule that consists learning activities (assignments, discussions), registered participants like teachers and students, and different types of resources. It would be useful, if we would be able to extract such information also from mash-up personal learning environments (just like it can be done in traditional Learning Management Systems) and allow exchanging it between the course participants. Today for semantic tagging of Web content in general and learning content as special case various technologies are used. But there are no tools and ways exist for semantic annotation of learning process that takes place in a distributed network of mash-up personal learning environments. -

Standardization's All Very Well, but What About the Exabytes of Existing
Standardization’s all very well, but what about the Exabytes of Existing Content and Learner Contributions? Felix Mödritscher 1), Victor Manuel García-Barrios 2) 1) Institute for Information Systems and New Media, Vienna University of Economics and Business Administration, Augasse 2-6, 1090 Vienna, Austria [email protected] 2) Institute for Information Systems and Computer Media, Graz University of Technology, Inffeldgasse 16c, 8010 Graz, Austria [email protected] 1. Problem Definition Standardization in the field of technology-enhanced learning focuses on structuring and aggregating assets to interoperable educational entities, like a course package. However, available standards and specifications in this area do not include an approach for addressing semantics embedded in existing content. This consideration might be useful for user-centered concepts, like learners tagging or commenting existing material, as well as for automated mechanism, like extracting relations or other meta-information automatically from the resources. In the upcoming section we indicate application areas and explain why available standards and specifications do not support these scenarios. Thereafter, we present a XML- based description language for semantics embedded in web-based content, which might be a solution for these use cases. Finally, we summarize and discuss some experiences on in- content semantics from former projects, particularly AdeLE (Adaptive e-Learning with Eye- tracking, http://adele.fh-joanneum.at) and iCamp (http://icamp.eu), and give an outlook on future work. 2. Application Areas and Shortcomings of Standards In 2004 we came in the situation that we had to cope with semantic enrichment of existing learning content, precisely to enable facilitators to tag web-based resources. -

Tantek Çelik HTML5 Now a Step-By-Step Tutorial for Getting Started Today Tantek Çelik
<!DOCTYPE html> <meta charset= "utf-8"><title>HTML5 Now</title> <hgroup> <h1> HTML5 </h1> N <h2> OW A STEP-BY-STEP TUtoRIAL FOR GETTING STARTED TODAY </h2> </hgroup> <div class= "vcard"> <a href= "http://tantek.com" class= "url fn"> TANTEK ÇELIK </a> <div> EXTENDED REFERENCE GUIDE HTML5 NOW A STEP-BY-STEP TUtoRIAL FOR GETTING STARTED TODAY TANTEK ÇELIK HTML5 Now A Step-by-Step Tutorial for Getting Started Today Tantek Çelik New Riders 1249 Eighth Street Berkeley, CA 94710 510/524-2178 Fax: 510/524-2221 Find us on the web at www.newriders.com To report errors, please send a note to [email protected] New Riders is an imprint of Peachpit, a division of Pearson Education Copyright © 2011 by Pearson Education, Inc. Senior Editor: Karyn Johnson Production Editor: Hilal Sala Copy Editor: Kelly Anton Technical Editor: Ben Ward Interior Design and Composition: Andreas deDanaan Presentation Graphics and Design: Coley Wopperer Author Photo: Matt Nuzzaco Cover Design: Mimi Heft Cover Production: Andreas deDanaan Video Production and Direction: Mary Sweeney Notice of Rights All rights reserved. No part of this book may be reproduced or transmitted in any form by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the publisher. For information on getting permission for reprints and excerpts, contact [email protected]. Notice of Liability The information in this book is distributed on an “As Is” basis without warranty. While every precaution has been taken in the preparation of the book, neither the author nor Peachpit shall have any liability to any person or entity with respect to any loss or damage caused or alleged to be caused directly or indirectly by the instructions contained in this book or by the computer software and hardware products described in it.