Standardization's All Very Well, but What About the Exabytes of Existing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Spatial Data Infrastructures and Linked Data
Spatial Data Infrastructures and Linked Data Carlos Granell Centre for Interactive Visualization Universitat Jaume I, Castellón, Spain Sven Schade European Commission - Joint Research Centre Institute for Environment and Sustainability, Ispra, Italy Gobe Hobona Centre for Geospatial Science University of Nottingham, Nottingham, United Kingdom ABSTRACT A Spatial Data Infrastructure (SDI) is a type of information infrastructure for enhancing geospatial data sharing and access. At the moment, we face the transition from the service-oriented second generation of SDI to a third generation, characterized by user-centric approaches. This new movement closes the gap between classical SDI and Volunteered Geographic Information (VGI). Public use and acquisition of information provides additional challenges within and beyond the geospatial domain. Linked data has been suggested recently as a possible overall solution. This notion refers to a best practice for exposing, sharing, and connecting resources in the (semantic) web. In this paper, we project the linked data approach to SDI and suggest it as a possibility to combine SDI with VGI. We advocate a Spatial Linked Data Infrastructure, which applies solutions for linked data to classical SDI standards. We detail different implementing strategies, give examples, and argue for benefits, while at the same time trying to outline possible fallbacks. We hope that this contribution will enlighten a way towards a single shared information space. 2 INTRODUCTION A Spatial Data Infrastructure (SDI) is a type of information infrastructure for enhancing geospatial data sharing and access. An SDI embraces a set of rules, standards, procedures, guidelines, policies, institutions, data, networks, technology and human resources for enabling and coordinating the management and exchange of geospatial data between stakeholders in the spatial data community (Nebert, 2004; Rajabifard et al., 2006; Masser, 2007). -

Rdfa in XHTML: Syntax and Processing Rdfa in XHTML: Syntax and Processing
RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing RDFa in XHTML: Syntax and Processing A collection of attributes and processing rules for extending XHTML to support RDF W3C Recommendation 14 October 2008 This version: http://www.w3.org/TR/2008/REC-rdfa-syntax-20081014 Latest version: http://www.w3.org/TR/rdfa-syntax Previous version: http://www.w3.org/TR/2008/PR-rdfa-syntax-20080904 Diff from previous version: rdfa-syntax-diff.html Editors: Ben Adida, Creative Commons [email protected] Mark Birbeck, webBackplane [email protected] Shane McCarron, Applied Testing and Technology, Inc. [email protected] Steven Pemberton, CWI Please refer to the errata for this document, which may include some normative corrections. This document is also available in these non-normative formats: PostScript version, PDF version, ZIP archive, and Gzip’d TAR archive. The English version of this specification is the only normative version. Non-normative translations may also be available. Copyright © 2007-2008 W3C® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. Abstract The current Web is primarily made up of an enormous number of documents that have been created using HTML. These documents contain significant amounts of structured data, which is largely unavailable to tools and applications. When publishers can express this data more completely, and when tools can read it, a new world of user functionality becomes available, letting users transfer structured data between applications and web sites, and allowing browsing applications to improve the user experience: an event on a web page can be directly imported - 1 - How to Read this Document RDFa in XHTML: Syntax and Processing into a user’s desktop calendar; a license on a document can be detected so that users can be informed of their rights automatically; a photo’s creator, camera setting information, resolution, location and topic can be published as easily as the original photo itself, enabling structured search and sharing. -

Mapping Between Digital Identity Ontologies Through SISM
Mapping between Digital Identity Ontologies through SISM Matthew Rowe The OAK Group, Department of Computer Science, University of Sheffield, Regent Court, 211 Portobello Street, Sheffield S1 4DP, UK [email protected] Abstract. Various ontologies are available defining the semantics of dig- ital identity information. Due to the rise in use of lowercase semantics, such ontologies are now used to add metadata to digital identity informa- tion within web pages. However concepts exist in these ontologies which are related and must be mapped together in order to enhance machine- readability of identity information on the web. This paper presents the Social identity Schema Mapping (SISM) vocabulary which contains a set of mappings between related concepts in distinct digital identity ontolo- gies using OWL and SKOS mapping constructs. Key words: Semantic Web, Social Web, SKOS, OWL, FOAF, SIOC, PIMO, NCO, Microformats 1 Introduction The semantic web provides a web of machine-readable data. Ontologies form a vital component of the semantic web by providing conceptualisations of domains of knowledge which can then be used to provide a common understanding of some domain. A basic ontology contains a vocabulary of concepts and definitions of the relationships between those concepts. An agent reading a concept from an ontology can look up the concept and discover its properties and characteristics, therefore interpreting how it fits into that particular domain. Due to the great number of ontologies it is common for related concepts to be defined in separate ontologies, these concepts must be identified and mapped together. Web technologies such as Microformats, eRDF and RDFa have allowed web developers to encode lowercase semantics within XHTML pages. -

Semantic Skin: from Flat Textual Content to Interconnected Repositories Of
Semantic Skin: from flat textual content to interconnected repositories of semantic data. Claudio Baldassarre ABSTRACT front-end web application. This application offers a faceted One approach to re-balancing the Digital Divide tends to view of the underlying \news-KB". The current blog site favor the production of informative content in flat formats, appearance is merely a stylistic choice, while a running in- which are easy to distribute and consume. At the same time stance is always backed by a SPARQL endpoint over the this approach forbids to deliver the core knowledge perti- \news-KB". The facets are typically rendered as menu ele- nent within the content; i.e. it increases the Knowledge ments5: some menus facet the entire \news-KB" (e.g., news Divide. In some international organizations1, informative Topics, or Provenance); while other menus facet only the content distribution to groups in Latin America happens by content currently visible to the users. The faceting mech- manually collecting text-based content, then disseminating anism is also applied tothe \news archive" as a time-based it via standard mailing lists, or databases copies sent out facet of the repository content. All the facets are popu- regularly. Our demo showcases the use of Semantic Skin lated with SPARQL queries over the \news-model" instances a technology that after semantifying the content submit- in the \news-KB". Each news item is then presented with ted in flat formats, provides access to the information via a its summary, title, publication date, and provenance (e.g., knowledge layer, which is, however, transparent to the end permalink). -

Where Is the Semantic Web? – an Overview of the Use of Embeddable Semantics in Austria
Where Is The Semantic Web? – An Overview of the Use of Embeddable Semantics in Austria Wilhelm Loibl Institute for Service Marketing and Tourism Vienna University of Economics and Business, Austria [email protected] Abstract Improving the results of search engines and enabling new online applications are two of the main aims of the Semantic Web. For a machine to be able to read and interpret semantic information, this content has to be offered online first. With several technologies available the question arises which one to use. Those who want to build the software necessary to interpret the offered data have to know what information is available and in which format. In order to answer these questions, the author analysed the business websites of different Austrian industry sectors as to what semantic information is embedded. Preliminary results show that, although overall usage numbers are still small, certain differences between individual sectors exist. Keywords: semantic web, RDFa, microformats, Austria, industry sectors 1 Introduction As tourism is a very information-intense industry (Werthner & Klein, 1999), especially novel users resort to well-known generic search engines like Google to find travel related information (Mitsche, 2005). Often, these machines do not provide satisfactory search results as their algorithms match a user’s query against the (weighted) terms found in online documents (Berry and Browne, 1999). One solution to this problem lies in “Semantic Searches” (Maedche & Staab, 2002). In order for them to work, web resources must first be annotated with additional metadata describing the content (Davies, Studer & Warren., 2006). Therefore, anyone who wants to provide data online must decide on which technology to use. -

Linked Data Schemata: Fixing Unsound Foundations
Linked data schemata: fixing unsound foundations. Kevin Feeney, Gavin Mendel Gleason, Rob Brennan Knowledge and Data Engineering Group & ADAPT Centre, School of Computer Science & Statistics, Trinity College Dublin, Ireland Abstract. This paper describes an analysis, and the tools and methods used to produce it, of the practical and logical implications of unifying common linked data vocabularies into a single logical model. In order to support any type of reasoning or even just simple type-checking, the vocabularies that are referenced by linked data statements need to be unified into a complete model wherever they reference or reuse terms that have been defined in other linked data vocabularies. Strong interdependencies between vocabularies are common and a large number of logical and practical problems make this unification inconsistent and messy. However, the situation is far from hopeless. We identify a minimal set of necessary fixes that can be carried out to make a large number of widely-deployed vocabularies mutually compatible, and a set of wider-ranging recommendations for linked data ontology design best practice to help alleviate the problem in future. Finally we make some suggestions for improving OWL’s support for distributed authoring and ontology reuse in the wild. Keywords: Linked Data, Reasoning, Data Quality 1. Introduction One of the central tenets of the Linked Data movement is the reuse of terms from existing well- known vocabularies [Bizer09] when developing new schemata or datasets. The semantic web infrastructure, and the RDF, RDFS and OWL languages, support this with their inherently distributed and modular nature. In practice, through vocabulary reuse, linked data schemata adopt knowledge models that are based on multiple, independently devised ontologies that often exhibit varying definitional semantics [Hogan12]. -

Conceptualization and Visualization of Tagging and Folksonomies
Conceptualization and Visualization of Tagging and Folksonomies Von der Fakultät für Ingenieurwissenschaften, Abteilung Informatik und Angewandte Kognitionswissenschaft der Universität Duisburg-Essen zur Erlangung des akademischen Grades Doktor der Ingenieurwissenschaften (Dr.-Ing.) genehmigte Dissertation von Steffen Lohmann aus Hamburg 1. Gutachter: Prof. Dr. Maria Paloma Díaz Pérez 2. Gutachter: Prof. Dr.-Ing. Jürgen Ziegler Tag der mündlichen Prüfung: 27.11.2013 Hinweis: Diese Dissertation ist im Rahmen eines binationalen Promotionsverfahrens (Cotutelle) in Kooperation mit der Universidad Carlos III de Madrid entstanden. Abstract Tagging has become a popular indexing method for interactive systems in the past decade. It offers a simple yet effective way for users to organize an ever increasing amount of digital information for themselves and/or others. The linked user vocabulary resulting from tagging is known as folksonomy and provides a valuable source for the retrieval and exploration of digital resources. Although several models and representations of tagging have been proposed, there is no coherent conceptualization that provides a comprehensive and pre- cise description of the concepts and relationships in the domain. Furthermore, there is little systematic research in the area of folksonomy visualization, and so folksonomies are still mainly depicted as simple tag clouds. Both problems are related, as a well-defined conceptualization is an important prerequisite for the interoperable use and visualization of folksonomies. The thesis addresses these shortcomings by developing a coherent conceptualiza- tion of tagging and visualizations for the interactive exploration of folksonomies. It gives an overview and comparison of tagging models and defines key concepts of the domain. After a comprehensive review of existing tagging ontologies, a unified and coherent conceptualization is presented that incorporates the best parts of the reviewed ontologies. -

Appendix a the Ten Commandments for Websites
Appendix A The Ten Commandments for Websites Welcome to the appendixes! At this stage in your learning, you should have all the basic skills you require to build a high-quality website with insightful consideration given to aspects such as accessibility, search engine optimization, usability, and all the other concepts that web designers and developers think about on a daily basis. Hopefully with all the different elements covered in this book, you now have a solid understanding as to what goes into building a website (much more than code!). The main thing you should take from this book is that you don’t need to be an expert at everything but ensuring that you take the time to notice what’s out there and deciding what will best help your site are among the most important elements of the process. As you leave this book and go on to updating your website over time and perhaps learning new skills, always remember to be brave, take risks (through trial and error), and never feel that things are getting too hard. If you choose to learn skills that were only briefly mentioned in this book, like scripting, or to get involved in using content management systems and web software, go at a pace that you feel comfortable with. With that in mind, let’s go over the 10 most important messages I would personally recommend. After that, I’ll give you some useful resources like important websites for people learning to create for the Internet and handy software. Advice is something many professional designers and developers give out in spades after learning some harsh lessons from what their own bitter experiences. -

Microformats the Next (Small) Thing on the Semantic Web?
Standards Editor: Jim Whitehead • [email protected] Microformats The Next (Small) Thing on the Semantic Web? Rohit Khare • CommerceNet “Designed for humans first and machines second, microformats are a set of simple, open data formats built upon existing and widely adopted standards.” — Microformats.org hen we speak of the “evolution of the is precisely encoding the great variety of person- Web,” it might actually be more appropri- al, professional, and genealogical relationships W ate to speak of “intelligent design” — we between people and organizations. By contrast, can actually point to a living, breathing, and an accidental challenge is that any blogger with actively involved Creator of the Web. We can even some knowledge of HTML can add microformat consult Tim Berners-Lee’s stated goals for the markup to a text-input form, but uploading an “promised land,” dubbed the Semantic Web. Few external file dedicated to machine-readable use presume we could reach those objectives by ran- remains forbiddingly complex with most blog- domly hacking existing Web standards and hop- ging tools. ing that “natural selection” by authors, software So, although any intelligent designer ought to developers, and readers would ensure powerful be able to rely on the long-established facility of enough abstractions for it. file transfer to publish the “right” model of a social Indeed, the elegant and painstakingly inter- network, the path of least resistance might favor locked edifice of technologies, including RDF, adding one of a handful of fixed tags to an exist- XML, and query languages is now growing pow- ing indirect form — the “blogroll” of hyperlinks to erful enough to attack massive information chal- other people’s sites. -

OGC Testbed-14: Semantically Enabled Aviation Data Models Engineering Report
OGC Testbed-14 Semantically Enabled Aviation Data Models Engineering Report Table of Contents 1. Summary . 4 1.1. Requirements & Research Motivation . 4 1.2. Prior-After Comparison. 4 1.3. Recommendations for Future Work . 5 1.4. What does this ER mean for the Working Group and OGC in general . 6 1.5. Document contributor contact points . 6 1.6. Foreword . 6 2. References . 8 3. Terms and definitions . 9 3.1. Semantics . 9 3.2. Service Description. 9 3.3. Service-Oriented Architecture (SOA) . 9 3.4. Registry . 9 3.5. System Wide Information Management (SWIM) . 9 3.6. Taxonomy . 9 3.7. Web Service . 10 4. Abbreviated Terms . 11 5. Overview . 12 6. Review of Data Models . 13 6.1. Information Exchange Models . 13 6.1.1. Flight Information Exchange Model (FIXM). 13 6.1.2. Aeronautical Information Exchange (AIXM) Model. 13 6.1.3. Weather Information Exchange Model (WXXM) . 14 6.1.4. NASA Air Traffic Management (ATM) Model . 14 6.2. Service description models . 19 6.2.1. Service Description Conceptual Model (SDCM) . 19 6.2.2. Web Service Description Ontological Model (WSDOM). 23 6.2.3. SWIM Documentation Controlled Vocabulary (FAA) . 25 7. Semantic Enablement Approaches . 27 8. Metadata level semantic enablement . 33 8.1. Issues with existing metadata standards . 34 8.1.1. Identification of Resources. 34 8.1.2. Resolvable URI. 34 8.1.3. Multilingual Support . 35 8.1.4. External Resource Descriptions . 35 8.1.5. Controlled Vocabulary Management . 36 8.1.6. Keywords Types . 37 8.1.7. Keyword Labeling Inconsistencies . -

Directed Graph
The Consistency and Conformance of Web Document Collection Based on Heterogeneous DAC Graph Marek Kopel and Aleksander Zgrzywa www.iis.pwr.wroc.pl www.zsi.pwr.wroc.pl Outline • Background & Idea • Personal Web of Trust • User and Agent Trust • Local Document Ranking & Filtering • Example Scenario • Conclusions & Future Work 2 Relationships in WWW • directed graph - most common model of a Web document collection • documents' hyperlinking relationship (edges) → PageRank, HITS • Tim Berners-Lee (in reference to the social aspect of Web 2.0): “I called this graph the Semantic Web, but maybe it should have been Giant Global Graph!” 3 Relationships in WWW (2) There's more to hyperlink than href: • HTML 4.01 attributes rel and rev - e.g: <a href=”glos.html” rel=”glossary”>used definitions</a> – navigation in a document collection (start, prev, next, contents, index), – structure (chapter, section, subsection, appendix, glossary) – meta (copyright, help) • XHTML 2.0 – custom namespaces 4 Relationships in WWW (3) Popular relation ontologies: • FOAF <foaf:knows> • XFN microformat – friendship (contact, acquaintance, friend) – family (child, parent, sibling, spouse, kin) – professional (co-worker, colleague) – physical (met) – geographical (co-resident, neighbor) – romantic (muse, crush, date, sweetheart) • rel-tag microformat - folksonomies 5 Heterogeneous DAC Graph • DAC graph – nodes of three types: • Document • Author • Concept – edges between nodes model the relationships – most of the relationships can be acquired directly from the Web data -
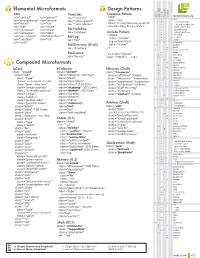
Microformats Cheat Sheet
Elemental Microformats Design Patterns tom eview Datetime Pattern esume XFN VoteLinks microformats.org hR hR hCard hCalendar rel="contact" rel="parent" rev="vote-for" <abbr hA rel="acquaintance" rel="spouse" class="foo" • adr rev="vote-against" + country-name title="YYYY-MM-DDTHH:MM:SS+ZZ:ZZ" rel="friend" rel="kin" rev="vote-abstain" • extended-address rel="met" rel="muse" >Human Date Time</abbr> + post-office-box rel="co-worker" rel="crush" Rel-Nofollow + postal-code rel="colleague" rel="date" rel="nofollow" Include Pattern • street-address + locality rel="co-resident" rel="sweetheart" <object Rel-Tag class="include" + region rel="neighbor" rel="me" rel="tag" • type rel="child" type="text/html" • affiliation Rel-Directory (Draft) data="#idref" ¤ author rel="directory" /> + best × + bookmark (rel) Rel-License + bday <a class="include" • • category rel="license" href="#idref">...</a> + + class × contact Compound Microformats + description + dtend + dtreviewed hCard hCalendar hResume (Draft) × dtstart class="vcard" class="vevent" class="hresume" × dtstamp class="adr" class="category" rel="tag" class="affiliation" (hcard) duration class="type" class="class" class="education" (hcalendar) • education [work|home|pref|postal|dom|intl] class="description" • email class="experience" (hcalendar) • type class="post-office-box" class="dtend" (ISO Date) class="publication" (citation) • value class="street-address" class="dtstamp" (ISO Date) class="skill" rel="tag" × entry-content class="extended-address" class="dtstart" (ISO Date) class="summary" • entry-summary