Introduction to Formal Languages and Automata
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

COMPSCI 501: Formal Language Theory Insights on Computability Turing Machines Are a Model of Computation Two (No Longer) Surpris
Insights on Computability Turing machines are a model of computation COMPSCI 501: Formal Language Theory Lecture 11: Turing Machines Two (no longer) surprising facts: Marius Minea Although simple, can describe everything [email protected] a (real) computer can do. University of Massachusetts Amherst Although computers are powerful, not everything is computable! Plus: “play” / program with Turing machines! 13 February 2019 Why should we formally define computation? Must indeed an algorithm exist? Back to 1900: David Hilbert’s 23 open problems Increasingly a realization that sometimes this may not be the case. Tenth problem: “Occasionally it happens that we seek the solution under insufficient Given a Diophantine equation with any number of un- hypotheses or in an incorrect sense, and for this reason do not succeed. known quantities and with rational integral numerical The problem then arises: to show the impossibility of the solution under coefficients: To devise a process according to which the given hypotheses or in the sense contemplated.” it can be determined in a finite number of operations Hilbert, 1900 whether the equation is solvable in rational integers. This asks, in effect, for an algorithm. Hilbert’s Entscheidungsproblem (1928): Is there an algorithm that And “to devise” suggests there should be one. decides whether a statement in first-order logic is valid? Church and Turing A Turing machine, informally Church and Turing both showed in 1936 that a solution to the Entscheidungsproblem is impossible for the theory of arithmetic. control To make and prove such a statement, one needs to define computability. In a recent paper Alonzo Church has introduced an idea of “effective calculability”, read/write head which is equivalent to my “computability”, but is very differently defined. -

Use Formal and Informal Language in Persuasive Text
Author’S Craft Use Formal and Informal Language in Persuasive Text 1. Focus Objectives Explain Using Formal and Informal Language In this mini-lesson, students will: Say: When I write a persuasive letter, I want people to see things my way. I use • Learn to use both formal and different kinds of language to gain support. To connect with my readers, I use informal language in persuasive informal language. Informal language is conversational; it sounds a lot like the text. way we speak to one another. Then, to make sure that people believe me, I also use formal language. When I use formal language, I don’t use slang words, and • Practice using formal and informal I am more objective—I focus on facts over opinions. Today I’m going to show language in persuasive text. you ways to use both types of language in persuasive letters. • Discuss how they can apply this strategy to their independent writing. Model How Writers Use Formal and Informal Language Preparation Display the modeling text on chart paper or using the interactive whiteboard resources. Materials Needed • Chart paper and markers 1. As the parent of a seventh grader, let me assure you this town needs a new • Interactive whiteboard resources middle school more than it needs Old Oak. If selling the land gets us a new school, I’m all for it. Advanced Preparation 2. Last month, my daughter opened her locker and found a mouse. She was traumatized by this experience. She has not used her locker since. If you will not be using the interactive whiteboard resources, copy the Modeling Text modeling text and practice text onto chart paper prior to the mini-lesson. -

Midterm Study Sheet for CS3719 Regular Languages and Finite
Midterm study sheet for CS3719 Regular languages and finite automata: • An alphabet is a finite set of symbols. Set of all finite strings over an alphabet Σ is denoted Σ∗.A language is a subset of Σ∗. Empty string is called (epsilon). • Regular expressions are built recursively starting from ∅, and symbols from Σ and closing under ∗ Union (R1 ∪ R2), Concatenation (R1 ◦ R2) and Kleene Star (R denoting 0 or more repetitions of R) operations. These three operations are called regular operations. • A Deterministic Finite Automaton (DFA) D is a 5-tuple (Q, Σ, δ, q0,F ), where Q is a finite set of states, Σ is the alphabet, δ : Q × Σ → Q is the transition function, q0 is the start state, and F is the set of accept states. A DFA accepts a string if there exists a sequence of states starting with r0 = q0 and ending with rn ∈ F such that ∀i, 0 ≤ i < n, δ(ri, wi) = ri+1. The language of a DFA, denoted L(D) is the set of all and only strings that D accepts. • Deterministic finite automata are used in string matching algorithms such as Knuth-Morris-Pratt algorithm. • A language is called regular if it is recognized by some DFA. • ‘Theorem: The class of regular languages is closed under union, concatenation and Kleene star operations. • A non-deterministic finite automaton (NFA) is a 5-tuple (Q, Σ, δ, q0,F ), where Q, Σ, q0 and F are as in the case of DFA, but the transition function δ is δ : Q × (Σ ∪ {}) → P(Q). -

Chapter 6 Formal Language Theory
Chapter 6 Formal Language Theory In this chapter, we introduce formal language theory, the computational theories of languages and grammars. The models are actually inspired by formal logic, enriched with insights from the theory of computation. We begin with the definition of a language and then proceed to a rough characterization of the basic Chomsky hierarchy. We then turn to a more de- tailed consideration of the types of languages in the hierarchy and automata theory. 6.1 Languages What is a language? Formally, a language L is defined as as set (possibly infinite) of strings over some finite alphabet. Definition 7 (Language) A language L is a possibly infinite set of strings over a finite alphabet Σ. We define Σ∗ as the set of all possible strings over some alphabet Σ. Thus L ⊆ Σ∗. The set of all possible languages over some alphabet Σ is the set of ∗ all possible subsets of Σ∗, i.e. 2Σ or ℘(Σ∗). This may seem rather simple, but is actually perfectly adequate for our purposes. 6.2 Grammars A grammar is a way to characterize a language L, a way to list out which strings of Σ∗ are in L and which are not. If L is finite, we could simply list 94 CHAPTER 6. FORMAL LANGUAGE THEORY 95 the strings, but languages by definition need not be finite. In fact, all of the languages we are interested in are infinite. This is, as we showed in chapter 2, also true of human language. Relating the material of this chapter to that of the preceding two, we can view a grammar as a logical system by which we can prove things. -
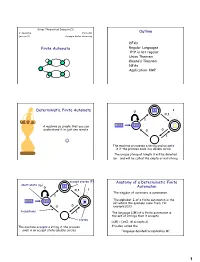
Deterministic Finite Automata 0 0,1 1
Great Theoretical Ideas in CS V. Adamchik CS 15-251 Outline Lecture 21 Carnegie Mellon University DFAs Finite Automata Regular Languages 0n1n is not regular Union Theorem Kleene’s Theorem NFAs Application: KMP 11 1 Deterministic Finite Automata 0 0,1 1 A machine so simple that you can 0111 111 1 ϵ understand it in just one minute 0 0 1 The machine processes a string and accepts it if the process ends in a double circle The unique string of length 0 will be denoted by ε and will be called the empty or null string accept states (F) Anatomy of a Deterministic Finite start state (q0) 11 0 Automaton 0,1 1 The singular of automata is automaton. 1 The alphabet Σ of a finite automaton is the 0111 111 1 ϵ set where the symbols come from, for 0 0 example {0,1} transitions 1 The language L(M) of a finite automaton is the set of strings that it accepts states L(M) = {x∈Σ: M accepts x} The machine accepts a string if the process It’s also called the ends in an accept state (double circle) “language decided/accepted by M”. 1 The Language L(M) of Machine M The Language L(M) of Machine M 0 0 0 0,1 1 q 0 q1 q0 1 1 What language does this DFA decide/accept? L(M) = All strings of 0s and 1s The language of a finite automaton is the set of strings that it accepts L(M) = { w | w has an even number of 1s} M = (Q, Σ, , q0, F) Q = {q0, q1, q2, q3} Formal definition of DFAs where Σ = {0,1} A finite automaton is a 5-tuple M = (Q, Σ, , q0, F) q0 Q is start state Q is the finite set of states F = {q1, q2} Q accept states : Q Σ → Q transition function Σ is the alphabet : Q Σ → Q is the transition function q 1 0 1 0 1 0,1 q0 Q is the start state q0 q0 q1 1 q q1 q2 q2 F Q is the set of accept states 0 M q2 0 0 q2 q3 q2 q q q 1 3 0 2 L(M) = the language of machine M q3 = set of all strings machine M accepts EXAMPLE Determine the language An automaton that accepts all recognized by and only those strings that contain 001 1 0,1 0,1 0 1 0 0 0 1 {0} {00} {001} 1 L(M)={1,11,111, …} 2 Membership problem Determine the language decided by Determine whether some word belongs to the language. -

Axiomatic Set Teory P.D.Welch
Axiomatic Set Teory P.D.Welch. August 16, 2020 Contents Page 1 Axioms and Formal Systems 1 1.1 Introduction 1 1.2 Preliminaries: axioms and formal systems. 3 1.2.1 The formal language of ZF set theory; terms 4 1.2.2 The Zermelo-Fraenkel Axioms 7 1.3 Transfinite Recursion 9 1.4 Relativisation of terms and formulae 11 2 Initial segments of the Universe 17 2.1 Singular ordinals: cofinality 17 2.1.1 Cofinality 17 2.1.2 Normal Functions and closed and unbounded classes 19 2.1.3 Stationary Sets 22 2.2 Some further cardinal arithmetic 24 2.3 Transitive Models 25 2.4 The H sets 27 2.4.1 H - the hereditarily finite sets 28 2.4.2 H - the hereditarily countable sets 29 2.5 The Montague-Levy Reflection theorem 30 2.5.1 Absoluteness 30 2.5.2 Reflection Theorems 32 2.6 Inaccessible Cardinals 34 2.6.1 Inaccessible cardinals 35 2.6.2 A menagerie of other large cardinals 36 3 Formalising semantics within ZF 39 3.1 Definite terms and formulae 39 3.1.1 The non-finite axiomatisability of ZF 44 3.2 Formalising syntax 45 3.3 Formalising the satisfaction relation 46 3.4 Formalising definability: the function Def. 47 3.5 More on correctness and consistency 48 ii iii 3.5.1 Incompleteness and Consistency Arguments 50 4 The Constructible Hierarchy 53 4.1 The L -hierarchy 53 4.2 The Axiom of Choice in L 56 4.3 The Axiom of Constructibility 57 4.4 The Generalised Continuum Hypothesis in L. -
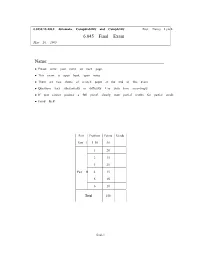
6.045 Final Exam Name
6.045J/18.400J: Automata, Computability and Complexity Prof. Nancy Lynch 6.045 Final Exam May 20, 2005 Name: • Please write your name on each page. • This exam is open book, open notes. • There are two sheets of scratch paper at the end of this exam. • Questions vary substantially in difficulty. Use your time accordingly. • If you cannot produce a full proof, clearly state partial results for partial credit. • Good luck! Part Problem Points Grade Part I 1–10 50 1 20 2 15 3 25 Part II 4 15 5 15 6 10 Total 150 final-1 Name: Part I Multiple Choice Questions. (50 points, 5 points for each question) For each question, any number of the listed answersClearly may place be correct. an “X” in the box next to each of the answers that you are selecting. Problem 1: Which of the following are true statements about regular and nonregular languages? (All lan guages are over the alphabet{0, 1}) IfL1 ⊆ L2 andL2 is regular, thenL1 must be regular. IfL1 andL2 are nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is nonregular, then the complementL 1 must of also be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is regular, thenL1 ∪ L2 must be nonregular. Problem 2: Which of the following are guaranteed to be regular languages ? ∗ L2 = {ww : w ∈{0, 1}}. L2 = {ww : w ∈ L1}, whereL1 is a regular language. L2 = {w : ww ∈ L1}, whereL1 is a regular language. L2 = {w : for somex,| w| = |x| andwx ∈ L1}, whereL1 is a regular language. -

An Introduction to Formal Language Theory That Integrates Experimentation and Proof
An Introduction to Formal Language Theory that Integrates Experimentation and Proof Allen Stoughton Kansas State University Draft of Fall 2004 Copyright °c 2003{2004 Allen Stoughton Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sec- tions, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled \GNU Free Documentation License". The LATEX source of this book and associated lecture slides, and the distribution of the Forlan toolset are available on the WWW at http: //www.cis.ksu.edu/~allen/forlan/. Contents Preface v 1 Mathematical Background 1 1.1 Basic Set Theory . 1 1.2 Induction Principles for the Natural Numbers . 11 1.3 Trees and Inductive De¯nitions . 16 2 Formal Languages 21 2.1 Symbols, Strings, Alphabets and (Formal) Languages . 21 2.2 String Induction Principles . 26 2.3 Introduction to Forlan . 34 3 Regular Languages 44 3.1 Regular Expressions and Languages . 44 3.2 Equivalence and Simpli¯cation of Regular Expressions . 54 3.3 Finite Automata and Labeled Paths . 78 3.4 Isomorphism of Finite Automata . 86 3.5 Algorithms for Checking Acceptance and Finding Accepting Paths . 94 3.6 Simpli¯cation of Finite Automata . 99 3.7 Proving the Correctness of Finite Automata . 103 3.8 Empty-string Finite Automata . 114 3.9 Nondeterministic Finite Automata . 120 3.10 Deterministic Finite Automata . 129 3.11 Closure Properties of Regular Languages . -

Regular Expressions with a Brief Intro to FSM
Regular Expressions with a brief intro to FSM 15-123 Systems Skills in C and Unix Case for regular expressions • Many web applications require pattern matching – look for <a href> tag for links – Token search • A regular expression – A pattern that defines a class of strings – Special syntax used to represent the class • Eg; *.c - any pattern that ends with .c Formal Languages • Formal language consists of – An alphabet – Formal grammar • Formal grammar defines – Strings that belong to language • Formal languages with formal semantics generates rules for semantic specifications of programming languages Automaton • An automaton ( or automata in plural) is a machine that can recognize valid strings generated by a formal language . • A finite automata is a mathematical model of a finite state machine (FSM), an abstract model under which all modern computers are built. Automaton • A FSM is a machine that consists of a set of finite states and a transition table. • The FSM can be in any one of the states and can transit from one state to another based on a series of rules given by a transition function. Example What does this machine represents? Describe the kind of strings it will accept. Exercise • Draw a FSM that accepts any string with even number of A’s. Assume the alphabet is {A,B} Build a FSM • Stream: “I love cats and more cats and big cats ” • Pattern: “cat” Regular Expressions Regex versus FSM • A regular expressions and FSM’s are equivalent concepts. • Regular expression is a pattern that can be recognized by a FSM. • Regex is an example of how good theory leads to good programs Regular Expression • regex defines a class of patterns – Patterns that ends with a “*” • Regex utilities in unix – grep , awk , sed • Applications – Pattern matching (DNA) – Web searches Regex Engine • A software that can process a string to find regex matches. -

Theory of Computation
Theory of Computation Alexandre Duret-Lutz [email protected] September 10, 2010 ADL Theory of Computation 1 / 121 References Introduction to the Theory of Computation (Michael Sipser, 2005). Lecture notes from Pierre Wolper's course at http://www.montefiore.ulg.ac.be/~pw/cours/calc.html (The page is in French, but the lecture notes labelled chapitre 1 to chapitre 8 are in English). Elements of Automata Theory (Jacques Sakarovitch, 2009). Compilers: Principles, Techniques, and Tools (A. Aho, R. Sethi, J. Ullman, 2006). ADL Theory of Computation 2 / 121 Introduction What would be your reaction if someone came at you to explain he has invented a perpetual motion machine (i.e. a device that can sustain continuous motion without losing energy or matter)? You would probably laugh. Without looking at the machine, you know outright that such the device cannot sustain perpetual motion. Indeed the laws of thermodynamics demonstrate that perpetual motion devices cannot be created. We know beforehand, from scientic knowledge, that building such a machine is impossible. The ultimate goal of this course is to develop similar knowledge for computer programs. ADL Theory of Computation 3 / 121 Theory of Computation Theory of computation studies whether and how eciently problems can be solved using a program on a model of computation (abstractions of a computer). Computability theory deals with the whether, i.e., is a problem solvable for a given model. For instance a strong result we will learn is that the halting problem is not solvable by a Turing machine. Complexity theory deals with the how eciently. -

Generating Context-Free Grammars Using Classical Planning
Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17) Generating Context-Free Grammars using Classical Planning Javier Segovia-Aguas1, Sergio Jimenez´ 2, Anders Jonsson 1 1 Universitat Pompeu Fabra, Barcelona, Spain 2 University of Melbourne, Parkville, Australia [email protected], [email protected], [email protected] Abstract S ! aSa S This paper presents a novel approach for generating S ! bSb /|\ Context-Free Grammars (CFGs) from small sets of S ! a S a /|\ input strings (a single input string in some cases). a S a Our approach is to compile this task into a classical /|\ planning problem whose solutions are sequences b S b of actions that build and validate a CFG compli- | ant with the input strings. In addition, we show that our compilation is suitable for implementing the two canonical tasks for CFGs, string produc- (a) (b) tion and string recognition. Figure 1: (a) Example of a context-free grammar; (b) the corre- sponding parse tree for the string aabbaa. 1 Introduction A formal grammar is a set of symbols and rules that describe symbols in the grammar and (2), a bounded maximum size of how to form the strings of certain formal language. Usually the rules in the grammar (i.e. a maximum number of symbols two tasks are defined over formal grammars: in the right-hand side of the grammar rules). Our approach is compiling this inductive learning task into • Production : Given a formal grammar, generate strings a classical planning task whose solutions are sequences of ac- that belong to the language represented by the grammar. -

Formal Grammar Specifications of User Interface Processes
FORMAL GRAMMAR SPECIFICATIONS OF USER INTERFACE PROCESSES by MICHAEL WAYNE BATES ~ Bachelor of Science in Arts and Sciences Oklahoma State University Stillwater, Oklahoma 1982 Submitted to the Faculty of the Graduate College of the Oklahoma State University iri partial fulfillment of the requirements for the Degree of MASTER OF SCIENCE July, 1984 I TheSIS \<-)~~I R 32c-lf CO'f· FORMAL GRAMMAR SPECIFICATIONS USER INTER,FACE PROCESSES Thesis Approved: 'Dean of the Gra uate College ii tta9zJ1 1' PREFACE The benefits and drawbacks of using a formal grammar model to specify a user interface has been the primary focus of this study. In particular, the regular grammar and context-free grammar models have been examined for their relative strengths and weaknesses. The earliest motivation for this study was provided by Dr. James R. VanDoren at TMS Inc. This thesis grew out of a discussion about the difficulties of designing an interface that TMS was working on. I would like to express my gratitude to my major ad visor, Dr. Mike Folk for his guidance and invaluable help during this study. I would also like to thank Dr. G. E. Hedrick and Dr. J. P. Chandler for serving on my graduate committee. A special thanks goes to my wife, Susan, for her pa tience and understanding throughout my graduate studies. iii TABLE OF CONTENTS Chapter Page I. INTRODUCTION . II. AN OVERVIEW OF FORMAL LANGUAGE THEORY 6 Introduction 6 Grammars . • . • • r • • 7 Recognizers . 1 1 Summary . • • . 1 6 III. USING FOR~AL GRAMMARS TO SPECIFY USER INTER- FACES . • . • • . 18 Introduction . 18 Definition of a User Interface 1 9 Benefits of a Formal Model 21 Drawbacks of a Formal Model .