Leakage Reduction Techniques
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ray Tracing on the Cell Processor
Ray Tracing on the Cell Processor Carsten Benthin† Ingo Wald Michael Scherbaum† Heiko Friedrich‡ †inTrace Realtime Ray Tracing GmbH SCI Institute, University of Utah ‡Saarland University {benthin, scherbaum}@intrace.com, [email protected], [email protected] Abstract band”) architectures1 to hide memory latencies, at exposing par- Over the last three decades, higher CPU performance has been allelism through SIMD units, and at multi-core architectures. At achieved almost exclusively by raising the CPU’s clock rate. Today, least for specialized tasks such as triangle rasterization, these con- the resulting power consumption and heat dissipation threaten to cepts have been proven as very powerful, and have made modern end this trend, and CPU designers are looking for alternative ways GPUs as fast as they are; for example, a Nvidia 7800 GTX offers of providing more compute power. In particular, they are looking 313 GFlops [16], 35 times more than a 2.2 GHz AMD Opteron towards three concepts: a streaming compute model, vector-like CPU. Today, there seems to be a convergence between CPUs and SIMD units, and multi-core architectures. One particular example GPUs, with GPUs—already using the streaming compute model, of such an architecture is the Cell Broadband Engine Architecture SIMD, and multi-core—become increasingly programmable, and (CBEA), a multi-core processor that offers a raw compute power CPUs are getting equipped with more and more cores and stream- of up to 200 GFlops per 3.2 GHz chip. The Cell bears a huge po- ing functionalities. Most commodity CPUs already offer 2–8 tential for compute-intensive applications like ray tracing, but also cores [1, 9, 10, 25], and desktop PCs with more cores can be built requires addressing the challenges caused by this processor’s un- by stacking and interconnecting smaller multi-core systems (mostly conventional architecture. -

IBM System P5 Quad-Core Module Based on POWER5+ Technology: Technical Overview and Introduction
Giuliano Anselmi Redpaper Bernard Filhol SahngShin Kim Gregor Linzmeier Ondrej Plachy Scott Vetter IBM System p5 Quad-Core Module Based on POWER5+ Technology: Technical Overview and Introduction The quad-core module (QCM) is based on the well-known POWER5™ dual-core module (DCM) technology. The dual-core POWER5 processor and the dual-core POWER5+™ processor are packaged with the L3 cache chip into a cost-effective DCM package. The QCM is a package that enables entry-level or midrange IBM® System p5™ servers to achieve additional processing density without increasing the footprint. Figure 1 shows the DCM and QCM physical views and the basic internal architecture. to I/O to I/O Core Core 1.5 GHz 1.5 GHz Enhanced Enhanced 1.9 MB MB 1.9 1.9 MB MB 1.9 L2 cache L2 L2 cache switch distributed switch distributed switch 1.9 GHz POWER5 Core Core core or CPU or core 1.5 GHz L3 Mem 1.5 GHz L3 Mem L2 cache L2 ctrl ctrl ctrl ctrl Enhanced distributed Enhanced 1.9 MB Shared Shared MB 1.9 Ctrl 1.9 GHz L3 Mem Ctrl POWER5 core or CPU or core 36 MB 36 MB 36 L3 cache L3 cache L3 DCM 36 MB QCM L3 cache L3 to memory to memory DIMMs DIMMs POWER5+ Dual-Core Module POWER5+ Quad-Core Module One Dual-Core-chip Two Dual-Core-chips plus two L3-cache-chips plus one L3-cache-chip Figure 1 DCM and QCM physical views and basic internal architecture © Copyright IBM Corp. 2006. -
Local, Compressed
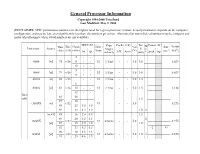
General Processor Information Copyright 1994-2000 Tom Burd Last Modified: May 2, 2000 (DISCLAIMER: SPEC performance numbers are the highest rated for a given processor version. Actual performance depends on the computer configuration, and may be less, even significantly less than, the numbers given here. Also note that non-italicized numbers may be company esti- mates of perforamnce when actual numbers are not available) SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ 5 - - 8086 [vi] 78 v/16 8 - - 1/1 1/1/na - - 5.0 3.0 0.029 10 - - 5 - - 8088 [vi] 79 v/16 1/1 1/1/na - - 5.0 3.0 0.029 8 - - 80186 [vi] 82 v/16 - - 1/1 1/1/na - - 5.0 1.5 6 - - 80286 [vi] 82 v/16 10 - - 1/1 1/1/na - - 5.0 1.5 0.134 12 - - Intel 85 16 x86 1.5 87 20 i386DX [vi] v/32 1/1 - - 5.0 0.275 88 25 6.5 1.9 89 33 8.4 3.0 1.0 2 [vi,41] 88 16 2.4 0.9 1.5 89 20 3.5 1.3 2 i386SX v/32 1/1 4/na/na - - 5.0 0.275 [vi] 89 25 4.6 1.9 1.0 92 33 6.2 3.3 ~2 43 90 20 3.5 1.3 i386SL [vi] v/32 1/1 4/na/na - - 5.0 1.0 2 0.855 91 25 4.6 1.9 SPEC-92 Pipe Cache (i/d) Tec Power (W) Date Bits Clock Units / Vdd M Size Xsistor Processor Source Stages h e (ship) (i/d) (MHz) Issue (V) (mm2) (106) int fp int/ldst/fp kB Assoc (um) t peak typ [vi] 89 25 14.2 6.7 1.0 2 i486DX [vi,45] 90 v/32 33 18.6 8.5 2/1 5/na/5? 8 u. -

Implementing Powerpc Linux on System I Platform
Front cover Implementing POWER Linux on IBM System i Platform Planning and configuring Linux servers on IBM System i platform Linux distribution on IBM System i Platform installation guide Tips to run Linux servers on IBM System i platform Yessong Johng Erwin Earley Rico Franke Vlatko Kosturjak ibm.com/redbooks International Technical Support Organization Implementing POWER Linux on IBM System i Platform February 2007 SG24-6388-01 Note: Before using this information and the product it supports, read the information in “Notices” on page vii. Second Edition (February 2007) This edition applies to i5/OS V5R4, SLES10 and RHEL4. © Copyright International Business Machines Corporation 2005, 2007. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . vii Trademarks . viii Preface . ix The team that wrote this redbook. ix Become a published author . xi Comments welcome. xi Chapter 1. Introduction to Linux on System i platform . 1 1.1 Concepts and terminology . 2 1.1.1 System i platform . 2 1.1.2 Hardware management console . 4 1.1.3 Virtual Partition Manager (VPM) . 10 1.2 Brief introduction to Linux and Linux on System i platform . 12 1.2.1 Linux on System i platform . 12 1.3 Differences between existing Power5-based System i and previous System i models 13 1.3.1 Linux enhancements on Power5 / Power5+ . 14 1.4 Where to go for more information . 15 Chapter 2. Configuration planning . 17 2.1 Concepts and terminology . 18 2.1.1 Processor concepts . -

From Blue Gene to Cell Power.Org Moscow, JSCC Technical Day November 30, 2005
IBM eServer pSeries™ From Blue Gene to Cell Power.org Moscow, JSCC Technical Day November 30, 2005 Dr. Luigi Brochard IBM Distinguished Engineer Deep Computing Architect [email protected] © 2004 IBM Corporation IBM eServer pSeries™ Technology Trends As frequency increase is limited due to power limitation Dual core is a way to : 2 x Peak Performance per chip (and per cycle) But at the expense of frequency (around 20% down) Another way is to increase Flop/cycle © 2004 IBM Corporation IBM eServer pSeries™ IBM innovations POWER : FMA in 1990 with POWER: 2 Flop/cycle/chip Double FMA in 1992 with POWER2 : 4 Flop/cycle/chip Dual core in 2001 with POWER4: 8 Flop/cycle/chip Quadruple core modules in Oct 2005 with POWER5: 16 Flop/cycle/module PowerPC: VMX in 2003 with ppc970FX : 8 Flops/cycle/core, 32bit only Dual VMX+ FMA with pp970MP in 1Q06 Blue Gene: Low frequency , system on a chip, tight integration of thousands of cpus Cell : 8 SIMD units and a ppc970 core on a chip : 64 Flop/cycle/chip © 2004 IBM Corporation IBM eServer pSeries™ Technology Trends As needs diversify, systems are heterogeneous and distributed GRID technologies are an essential part to create cooperative environments based on standards © 2004 IBM Corporation IBM eServer pSeries™ IBM innovations IBM is : a sponsor of Globus Alliances contributing to Globus Tool Kit open souce a founding member of Globus Consortium IBM is extending its products Global file systems : – Multi platform and multi cluster GPFS Meta schedulers : – Multi platform -

IBM Powerpc 970 (A.K.A. G5)
IBM PowerPC 970 (a.k.a. G5) Ref 1 David Benham and Yu-Chung Chen UIC – Department of Computer Science CS 466 PPC 970FX overview ● 64-bit RISC ● 58 million transistors ● 512 KB of L2 cache and 96KB of L1 cache ● 90um process with a die size of 65 sq. mm ● Native 32 bit compatibility ● Maximum clock speed of 2.7 Ghz ● SIMD instruction set (Altivec) ● 42 watts @ 1.8 Ghz (1.3 volts) ● Peak data bandwidth of 6.4 GB per second A picture is worth a 2^10 words (approx.) Ref 2 A little history ● PowerPC processor line is a product of the AIM alliance formed in 1991. (Apple, IBM, and Motorola) ● PPC 601 (G1) - 1993 ● PPC 603 (G2) - 1995 ● PPC 750 (G3) - 1997 ● PPC 7400 (G4) - 1999 ● PPC 970 (G5) - 2002 ● AIM alliance dissolved in 2005 Processor Ref 3 Ref 3 Core details ● 16(int)-25(vector) stage pipeline ● Large number of 'in flight' instructions (various stages of execution) - theoretical limit of 215 instructions ● 512 KB L2 cache ● 96 KB L1 cache – 64 KB I-Cache – 32 KB D-Cache Core details continued ● 10 execution units – 2 load/store operations – 2 fixed-point register-register operations – 2 floating-point operations – 1 branch operation – 1 condition register operation – 1 vector permute operation – 1 vector ALU operation ● 32 64 bit general purpose registers, 32 64 bit floating point registers, 32 128 vector registers Pipeline Ref 4 Benchmarks ● SPEC2000 ● BLAST – Bioinformatics ● Amber / jac - Structure biology ● CFD lab code SPEC CPU2000 ● IBM eServer BladeCenter JS20 ● PPC 970 2.2Ghz ● SPECint2000 ● Base: 986 Peak: 1040 ● SPECfp2000 ● Base: 1178 Peak: 1241 ● Dell PowerEdge 1750 Xeon 3.06Ghz ● SPECint2000 ● Base: 1031 Peak: 1067 Apple’s SPEC Results*2 ● SPECfp2000 ● Base: 1030 Peak: 1044 BLAST Ref. -

Microprocessor Training
Microprocessors and Microcontrollers © 1999 Altera Corporation 1 Altera Confidential Agenda New Products - MicroController products (1 hour) n Microprocessor Systems n The Embedded Microprocessor Market n Altera Solutions n System Design Considerations n Uncovering Sales Opportunities © 2000 Altera Corporation 2 Altera Confidential Embedding microprocessors inside programmable logic opens the door to a multi-billion dollar market. Altera has solutions for this market today. © 2000 Altera Corporation 3 Altera Confidential Microprocessor Systems © 1999 Altera Corporation 4 Altera Confidential Processor Terminology n Microprocessor: The implementation of a computer’s central processor unit functions on a single LSI device. n Microcontroller: A self-contained system with a microprocessor, memory and peripherals on a single chip. “Just add software.” © 2000 Altera Corporation 5 Altera Confidential Examples Microprocessor: Motorola PowerPC 600 Microcontroller: Motorola 68HC16 © 2000 Altera Corporation 6 Altera Confidential Two Types of Processors Computational Embedded n Programmable by the end-user to n Performs a fixed set of functions that accomplish a wide range of define the product. User may applications configure but not reprogram. n Runs an operating system n May or may not use an operating system n Program exists on mass storage n Program usually exists in ROM or or network Flash n Tend to be: n Tend to be: – Microprocessors – Microcontrollers – More expensive (ASP $193) – Less expensive (ASP $12) n Examples n Examples – Work Station -

IBM Power Systems Performance Report Apr 13, 2021
IBM Power Performance Report Power7 to Power10 September 8, 2021 Table of Contents 3 Introduction to Performance of IBM UNIX, IBM i, and Linux Operating System Servers 4 Section 1 – SPEC® CPU Benchmark Performance 4 Section 1a – Linux Multi-user SPEC® CPU2017 Performance (Power10) 4 Section 1b – Linux Multi-user SPEC® CPU2017 Performance (Power9) 4 Section 1c – AIX Multi-user SPEC® CPU2006 Performance (Power7, Power7+, Power8) 5 Section 1d – Linux Multi-user SPEC® CPU2006 Performance (Power7, Power7+, Power8) 6 Section 2 – AIX Multi-user Performance (rPerf) 6 Section 2a – AIX Multi-user Performance (Power8, Power9 and Power10) 9 Section 2b – AIX Multi-user Performance (Power9) in Non-default Processor Power Mode Setting 9 Section 2c – AIX Multi-user Performance (Power7 and Power7+) 13 Section 2d – AIX Capacity Upgrade on Demand Relative Performance Guidelines (Power8) 15 Section 2e – AIX Capacity Upgrade on Demand Relative Performance Guidelines (Power7 and Power7+) 20 Section 3 – CPW Benchmark Performance 19 Section 3a – CPW Benchmark Performance (Power8, Power9 and Power10) 22 Section 3b – CPW Benchmark Performance (Power7 and Power7+) 25 Section 4 – SPECjbb®2015 Benchmark Performance 25 Section 4a – SPECjbb®2015 Benchmark Performance (Power9) 25 Section 4b – SPECjbb®2015 Benchmark Performance (Power8) 25 Section 5 – AIX SAP® Standard Application Benchmark Performance 25 Section 5a – SAP® Sales and Distribution (SD) 2-Tier – AIX (Power7 to Power8) 26 Section 5b – SAP® Sales and Distribution (SD) 2-Tier – Linux on Power (Power7 to Power7+) -

IBM's POWER5 Micro Processor Design and Methodology
IBM's POWER5 Micro Processor Design and Methodology Ron Kalla IBM Systems Group © 2003 IBM Corporation IBM’s POWER5 Micro Processor Design and Methodology Outline POWER5 Overview Design Process Power UT CS352 , April 2005 © 2003 IBM Corporation IBM’s POWER5 Micro Processor Design and Methodology POWER Server Roadmap 2001 2002-3 2004* 2005* 2006* POWER4 POWER4+ POWER5 POWER5+ POWER6 90 nm 65 nm 130 nm 130 nm Ultra high 180 nm >> GHz >> GHz frequency cores Core Core 1.7 GHz 1.7 GHz > GHz > GHz L2 caches Core Core Core Core 1.3 GHz 1.3 GHz Shared L2 Advanced System Features Core Core Distributed Switch Shared L2 Shared L2 Distributed Switch Distributed Switch Shared L2 Simultaneous multi-threading Distributed Switch Sub-processor partitioning Reduced size Dynamic firmware updates Enhanced scalability, parallelism Chip Multi Processing Lower power High throughput performance - Distributed Switch Larger L2 Enhanced memory subsystem - Shared L2 More LPARs (32) Dynamic LPARs (16) Autonomic Computing Enhancements *Planned to be offered by IBM. All statements about IBM’s future direction and intent are* subject to change or withdrawal without notice and represent goals and objectives only. UT CS352 , April 2005 © 2003 IBM Corporation IBM’s POWER5 Micro Processor Design and Methodology POWER5 Technology: 130nm lithography, Cu, SOI 389mm2 276M Transistors Dual processor core 8-way superscalar Simultaneous multithreaded (SMT) core Up to 2 virtual processors per real processor UT CS352 , April 2005 © 2003 IBM Corporation IBM’s POWER5 Micro -

SEWIP Program Leverages COTS P 36 P 28 an Interview with Deon Viergutz, Vice President of Cyber Solutions at Lockheed Martin Information Systems & Global Solutions
@military_cots John McHale Obsolescence trends 8 Special Report Shipboard displays 44 Mil Tech Trends Predictive analytics 52 Industry Spotlight Aging avionics software 56 MIL-EMBEDDED.COM September 2015 | Volume 11 | Number 6 RESOURCE GUIDE 2015 P 62 Navy SEWIP program leverages COTS P 36 P 28 An interview with Deon Viergutz, Vice President of Cyber Solutions at Lockheed Martin Information Systems & Global Solutions Military electronics market overview P 14 Volume 11 Number 6 www.mil-embedded.com September 2015 COLUMNS BONUS – MARKET OVERVIEW Editor’s Perspective 14 C4ISR funding a bright spot in military 8 Tech mergers & military electronics electronics market obsolescence By John McHale, Editorial Director By John McHale Q&A EXECUTIVE OUTLOOK Field Intelligence 10 Metadata: When target video 28 Defending DoD from cyberattacks, getting to data is not enough the left of the boom By Charlotte Adams 14 An interview with Deon Viergutz, Vice President of Cyber Solutions at Lockheed Martin Information Mil Tech Insider Systems & Global Solutions 12 Broadwell chip boosts GPU performance for COTS SBCs 32 RF and microwave innovation drives military By Aaron Frank radar and electronic warfare applications An interview with Bryan Goldstein, DEPARTMENTS General Manager of the Aerospace and Defense, Analog Devices 22 Defense Tech Wire By Mariana Iriarte SPECIAL REPORT 60 Editor’s Choice Products Shipboard Electronics 112 University Update 36 U.S. Navy’s electronic warfare modernization On DARPA’s cybersecurity radar: 36 effort centers on COTS Algorithmic and side-channel attacks By Sally Cole, Senior Editor By Sally Cole 114 Connecting with Mil Embedded 44 Key to military display technologies: Blog – The fascinating world of System integration By Tom Whinfrey, IEE Inc. -

Technical Report
Technical Report Department of Computer Science University of Minnesota 4-192 EECS Building 200 Union Street SE Minneapolis, MN 55455-0159 USA TR 97-030 Hardware and Compiler-Directed Cache Coherence in Large-Scale Multiprocessors by: Lynn Choi and Pen-Chung Yew Hardware and Compiler-Directed Cache Coherence 1n Large-Scale Multiprocessors: Design Considerations and Performance Study1 Lynn Choi Center for Supercomputing Research and Development University of Illinois at Urbana-Champaign 1308 West Main Street Urbana, IL 61801 Email: lchoi@csrd. uiuc. edu Pen-Chung Yew 4-192 EE/CS Building Department of Computer Science University of Minnesota 200 Union Street, SE Minneapolis, MN 55455-0159 Email: [email protected] Abstract In this paper, we study a hardware-supported, compiler-directed (HSCD) cache coherence scheme, which can be implemented on a large-scale multiprocessor using off-the-shelf micro processors, such as the Cray T3D. The scheme can be adapted to various cache organizations, including multi-word cache lines and byte-addressable architectures. Several system related issues, including critical sections, inter-thread communication, and task migration have also been addressed. The cost of the required hardware support is minimal and proportional to the cache size. The necessary compiler algorithms, including intra- and interprocedural array data flow analysis, have been implemented on the Polaris parallelizing compiler [33]. From our simulation study using the Perfect Club benchmarks [5], we found that in spite of the conservative analysis made by the compiler, the performance of the proposed HSCD scheme can be comparable to that of a full-map hardware directory scheme. Given its compa rable performance and reduced hardware cost, the proposed scheme can be a viable alternative for large-scale multiprocessors such as the Cray T3D, which rely on users to maintain data coherence. -

A Bibliography of Publications in IEEE Micro
A Bibliography of Publications in IEEE Micro Nelson H. F. Beebe University of Utah Department of Mathematics, 110 LCB 155 S 1400 E RM 233 Salt Lake City, UT 84112-0090 USA Tel: +1 801 581 5254 FAX: +1 801 581 4148 E-mail: [email protected], [email protected], [email protected] (Internet) WWW URL: http://www.math.utah.edu/~beebe/ 16 September 2021 Version 2.108 Title word cross-reference -Core [MAT+18]. -Cubes [YW94]. -D [ASX19, BWMS19, DDG+19, Joh19c, PZB+19, ZSS+19]. -nm [ABG+16, KBN16, TKI+14]. #1 [Kah93i]. 0.18-Micron [HBd+99]. 0.9-micron + [Ano02d]. 000-fps [KII09]. 000-Processor $1 [Ano17-58, Ano17-59]. 12 [MAT 18]. 16 + + [ABG+16]. 2 [DTH+95]. 21=2 [Ste00a]. 28 [BSP 17]. 024-Core [JJK 11]. [KBN16]. 3 [ASX19, Alt14e, Ano96o, + AOYS95, BWMS19, CMAS11, DDG+19, 1 [Ano98s, BH15, Bre10, PFC 02a, Ste02a, + + Ste14a]. 1-GHz [Ano98s]. 1-terabits DFG 13, Joh19c, LXB07, LX10, MKT 13, + MAS+07, PMM15, PZB+19, SYW+14, [MIM 97]. 10 [Loc03]. 10-Gigabit SCSR93, VPV12, WLF+08, ZSS+19]. 60 [Gad07, HcF04]. 100 [TKI+14]. < [BMM15]. > [BMM15]. 2 [Kir84a, Pat84, PSW91, YSMH91, ZACM14]. [WHCK18]. 3 [KBW95]. II [BAH+05]. ∆ 100-Mops [PSW91]. 1000 [ES84]. 11- + [Lyl04]. 11/780 [Abr83]. 115 [JBF94]. [MKG 20]. k [Eng00j]. µ + [AT93, Dia95c, TS95]. N [YW94]. x 11FO4 [ASD 05]. 12 [And82a]. [DTB01, Dur96, SS05]. 12-DSP [Dur96]. 1284 [Dia94b]. 1284-1994 [Dia94b]. 13 * [CCD+82]. [KW02]. 1394 [SB00]. 1394-1955 [Dia96d]. 1 2 14 [WD03]. 15 [FD04]. 15-Billion-Dollar [KR19a].