Digital Soil Mapping Over Large Areas with Invalid Environmental Covariate Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

User Guide: Soil Parent Material 1 Kilometre Dataset
CORE Metadata, citation and similar papers at core.ac.uk Provided by NERC Open Research Archive User Guide: Soil Parent Material 1 kilometre dataset. Environmental Modelling Internal Report OR/14/025 BRITISH GEOLOGICAL SURVEY ENVIRONMENTAL Modelling INTERNAL REPORT OR/14/025 User Guide: Soil Parent Material 1 kilometre dataset. The National Grid and other Ordnance Survey data © Crown Copyright and database rights 2012. Ordnance Survey Licence R. Lawley. No. 100021290. Keywords Contributor/editor Parent Material, Soil,UKSO. B. Rawlins. National Grid Reference SW corner 999999,999999 Centre point 999999,999999 NE corner 999999,999999 Map Sheet 999, 1:99 000 scale, Map name Front cover Soil Parent Material 1km dataset. Bibliographical reference LAWLEY., R. USER GUIDE: SOIL PARENT Material 1 Kilometre dataset. 2012. User Guide: Soil Parent Material 1km dataset.. British Geological Survey Internal Report, OR/14/025. 20pp. Copyright in materials derived from the British Geological Survey’s work is owned by the Natural Environment Research Council (NERC) and/or the authority that commissioned the work. You may not copy or adapt this publication without first obtaining permission. Contact the BGS Intellectual Property Rights Section, British Geological Survey, Keyworth, email [email protected]. You may quote extracts of a reasonable length without prior permission, provided a full acknowledgement is given of the source of the extract. Maps and diagrams in this book use topography based on Ordnance Survey mapping. © NERC 2014. All rights reserved Keyworth, Nottingham British Geological Survey 2012 BRITISH GEOLOGICAL SURVEY The full range of our publications is available from BGS shops at British Geological Survey offices Nottingham, Edinburgh, London and Cardiff (Welsh publications only) see contact details below or shop online at www.geologyshop.com BGS Central Enquiries Desk Tel 0115 936 3143 Fax 0115 936 3276 The London Information Office also maintains a reference collection of BGS publications, including maps, for consultation. -
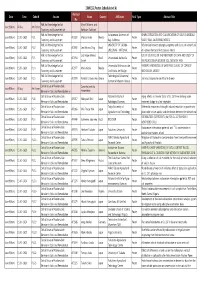
Poster Presentation Schedule
20WCSS_Poster Schedule(vol.6) Abstract Date Time Code-N Session Name Country Affiliation Final Type Abstract Title No Folk Soil Knowledge for Soil Myriel Milicevic and June 9(Mon) All day Art Poster Taxonomy and Assessment-art Ruttikorn Vuttikorn Folk Soil Knowledge for Soil Autonomous University of CHARACTERIZATION AND CLASSIFICATION OF SOILS IN MEXICALI June 9(Mon) 15:30~16:20 P1-1 AF2388 Monica Aviles Mexico Poster Taxonomy and Assessment Baja California VALLEY, BAJA CALIFORNIA, MEXICO Folk Soil Knowledge for Soil UNIVERSITY OF CUIABA - Relationship between phytophysiognomy and classes of wetland soil June 9(Mon) 15:30~16:20 P1-2 AF2892 Leo Adriano Chig Brazil Poster Taxonomy and Assessment UNIC/INAU - NATIONAL of northern Pantanal Mato Grosso - Brazil Folk Soil Knowledge for Soil Luiz Felipe Moreira USE OF SIG TOOLS IN THE TREATMENT OF DATA AND STUDY OF June 9(Mon) 15:30~16:20 P1-3 AF2934 Brazil Universidade de Brasilia Poster Taxonomy and Assessment Cassol THE RELATIONSHIP BETWEEN SOIL, GEOLOGY AND Folk Soil Knowledge for Soil Universidad Michoacana de FARMER'S KNOWLEDGE OF LAND AND CLASSES OF CORN OF June 9(Mon) 15:30~16:20 P1-4 AF2977 Maria Alcala Mexico Poster Taxonomy and Assessment San Nicolas de Hidalgo MICHOACAN, MEXICO Folk Soil Knowledge for Soil Technological Educational June 9(Mon) 15:30~16:20 P1-5 AF2979 Pantelis E. Barouchas Greece Poster Soil mass balance for an Alfisol in Greece Taxonomy and Assessment Institute of Western Greece Critical Issues of Radionuclide Center for Land Use June 9(Mon) All day Art Poster Behavior -

Pedometric Mapping of Key Topsoil and Subsoil Attributes Using Proximal and Remote Sensing in Midwest Brazil
UNIVERSIDADE DE BRASÍLIA FACULDADE DE AGRONOMIA E MEDICINA VETERINÁRIA PROGRAMA DE PÓS-GRADUAÇÃO EM AGRONOMIA PEDOMETRIC MAPPING OF KEY TOPSOIL AND SUBSOIL ATTRIBUTES USING PROXIMAL AND REMOTE SENSING IN MIDWEST BRAZIL RAÚL ROBERTO POPPIEL TESE DE DOUTORADO EM AGRONOMIA BRASÍLIA/DF MARÇO/2020 UNIVERSIDADE DE BRASÍLIA FACULDADE DE AGRONOMIA E MEDICINA VETERINÁRIA PROGRAMA DE PÓS-GRADUAÇÃO EM AGRONOMIA PEDOMETRIC MAPPING OF KEY TOPSOIL AND SUBSOIL ATTRIBUTES USING PROXIMAL AND REMOTE SENSING IN MIDWEST BRAZIL RAÚL ROBERTO POPPIEL ORIENTADOR: Profa. Dra. MARILUSA PINTO COELHO LACERDA CO-ORIENTADOR: Prof. Titular JOSÉ ALEXANDRE MELO DEMATTÊ TESE DE DOUTORADO EM AGRONOMIA BRASÍLIA/DF MARÇO/2020 ii iii REFERÊNCIA BIBLIOGRÁFICA POPPIEL, R. R. Pedometric mapping of key topsoil and subsoil attributes using proximal and remote sensing in Midwest Brazil. Faculdade de Agronomia e Medicina Veterinária, Universidade de Brasília- Brasília, 2019; 105p. (Tese de Doutorado em Agronomia). CESSÃO DE DIREITOS NOME DO AUTOR: Raúl Roberto Poppiel TÍTULO DA TESE DE DOUTORADO: Pedometric mapping of key topsoil and subsoil attributes using proximal and remote sensing in Midwest Brazil. GRAU: Doutor ANO: 2020 É concedida à Universidade de Brasília permissão para reproduzir cópias desta tese de doutorado e para emprestar e vender tais cópias somente para propósitos acadêmicos e científicos. O autor reserva outros direitos de publicação e nenhuma parte desta tese de doutorado pode ser reproduzida sem autorização do autor. ________________________________________________ Raúl Roberto Poppiel CPF: 703.559.901-05 Email: [email protected] Poppiel, Raúl Roberto Pedometric mapping of key topsoil and subsoil attributes using proximal and remote sensing in Midwest Brazil/ Raúl Roberto Poppiel. -- Brasília, 2020. -

Impact of Heathland Restoration and Re-Creation Techniques on Soil Characteristics and the Historical Environment
Natural England Research Report NERR010 Impact of heathland restoration and re-creation techniques on soil characteristics and the historical environment www.naturalengland.org.uk Natural England Research Report NERR010 Impact of heathland restoration and re-creation techniques on soil characteristics and the historical environment Hawley, G.1, Anderson, P. 1, Gash, M. 1, Smith, P. 1, Higham, N. 2, Alonso, I. 3, Ede, J.3 & Holloway, J.3 1 Independent consultant, 2 University of Manchester and 3 Natural England Published on 28 March 2008 The views in this report are those of the authors and do not necessarily represent those of Natural England. You may reproduce as many individual copies of this report as you like, provided such copies stipulate that copyright remains with Natural England, 1 East Parade, Sheffield, S1 2ET ISSN 1754-1956 © Copyright Natural England 2008 Project details This report results from research commissioned by Natural England in order to provide information on the impact of heathland restoration and re-creation activities on the soils and archaeology. The work was undertaken under Natural England contract FST20-84-010 by the following team: Penny Anderson (Managing Director Penny Anderson Associates Ltd (PAA); Gerard Hawley (Senior Soil Scientist, PAA); Mark Gash (Ecologist, PAA); Phil Smith (Senior Ecologist, PAA) and Nick Higham (Professor of Early Medieval and Landscape History, University of Manchester). Isabel Alonso (Heathland Ecologist, Natural England), Joy Ede (Historic Environment Advisor, Natural England) and Julie Holloway (Senior Soil Specialist, Natural England) provided contacts, information, references and edited the report. A summary of the findings covered by this report, as well as Natural England's views on this research, can be found within Natural England Research Information Note RIN010: Impact of heathland restoration and re-creation techniques on soil characteristics and the historical environment. -

NBN EN 12670 : Natural Stone
ICS: 01.040.73; 01.040.91;; 73.020 91.100.15 Geregistreerde NBN EN 12670 Belgische norm 1e uitg., februari 2002 Normklasse : B 17 Natuursteen - Terminologie Pierre naturelle - Terminologie Natural stone - Terminology Toelating tot publicatie : 12 februari 2002 Deze Europese norm EN 12670 : 2001 heeft de status van een Belgische norm. Deze Europese norm bestaat in drie officiële versies (Duits, Engels, Frans). Belgisch instituut voor normalisatie (BIN) , vereniging zonder winstoogmerk Brabançonnelaan 29 - 1000 BRUSSEL - telefoon: 02 738 01 12 - fax: 02 733 42 64 e-mail: [email protected] - BIN Online: www.bin.be - prk. 000-0063310-66 © BIN 2002 Prijsgroep : 21 EUROPEAN STANDARD EN 12670 NORME EUROPÉENNE EUROPÄISCHE NORM December 2001 ICS 01.040.73; 01.040.91; 73.020; 91.100.15 English version Natural stone - Terminology Pierre naturelle - Terminologie Naturstein - Terminologie This European Standard was approved by CEN on 20 October 2001. CEN members are bound to comply with the CEN/CENELEC Internal Regulations which stipulate the conditions for giving this European Standard the status of a national standard without any alteration. Up-to-date lists and bibliographical references concerning such national standards may be obtained on application to the Management Centre or to any CEN member. This European Standard exists in three official versions (English, French, German). A version in any other language made by translation under the responsibility of a CEN member into its own language and notified to the Management Centre has the same status as the official versions. CEN members are the national standards bodies of Austria, Belgium, Czech Republic, Denmark, Finland, France, Germany, Greece, Iceland, Ireland, Italy, Luxembourg, Netherlands, Norway, Portugal, Spain, Sweden, Switzerland and United Kingdom. -

Oregon Geologic Digital Compilation Rules for Lithology Merge Information Entry
State of Oregon Department of Geology and Mineral Industries Vicki S. McConnell, State Geologist OREGON GEOLOGIC DIGITAL COMPILATION RULES FOR LITHOLOGY MERGE INFORMATION ENTRY G E O L O G Y F A N O D T N M I E N M E T R R A A L P I E N D D U N S O T G R E I R E S O 1937 2006 Revisions: Feburary 2, 2005 January 1, 2006 NOTICE The Oregon Department of Geology and Mineral Industries is publishing this paper because the infor- mation furthers the mission of the Department. To facilitate timely distribution of the information, this report is published as received from the authors and has not been edited to our usual standards. Oregon Department of Geology and Mineral Industries Oregon Geologic Digital Compilation Published in conformance with ORS 516.030 For copies of this publication or other information about Oregon’s geology and natural resources, contact: Nature of the Northwest Information Center 800 NE Oregon Street #5 Portland, Oregon 97232 (971) 673-1555 http://www.naturenw.org Oregon Department of Geology and Mineral Industries - Oregon Geologic Digital Compilation i RULES FOR LITHOLOGY MERGE INFORMATION ENTRY The lithology merge unit contains 5 parts, separated by periods: Major characteristic.Lithology.Layering.Crystals/Grains.Engineering Lithology Merge Unit label (Lith_Mrg_U field in GIS polygon file): major_characteristic.LITHOLOGY.Layering.Crystals/Grains.Engineering major characteristic - lower case, places the unit into a general category .LITHOLOGY - in upper case, generally the compositional/common chemical lithologic name(s) -

Economic Valuation of Soil Functions: Phase 1
Economic Valuation of Soil Functions Phase 1: Literature Review and Method Development Prepared for: Defra Prepared by: David Harris, ADAS Boxworth, Battlegate Road, Boxworth, Cambridge, CB3 8NN Dr. Bob Crabtree, CJC Consulting, Oxford John King, ADAS Boxworth Paul Newell-Price, ADAS Gleadthorpe Date: July 2006 Copyright The proposed approach and methodology is protected by copyright and no part of this document may be copied or disclosed to any third party, either before or after the contract is awarded, without the written consent of ADAS. 0936648 Economic Valuation of Soil Functions Phase 1: Literature Review and Method Development Glossary of Terms ALC Agricultural Land Classification AONB Area of Outstanding Natural Beauty BMP Best Management Practice generally defined by being within the Codes of Good Agricultural Practice for Air, Water and Soil, COGAP (Defra) Brickfield series An imperfectly drained soil with a fine loamy texture CAP Common Agricultural Policy Clifton series An imperfectly drained, medium to coarse-textured soil with a perched water table Cu Copper CV Contingent valuation DE Direct energy used in fuel for field operations Defra Department for Environment, Food and Rural Affairs DoE Department of the Environment (now part of Defra and distinct from the Environment Agency) Dunkeswick series A poorly drained soil with a fine loamy topsoil, and a clay subsoil beginning at between 40 and 80 cm depth ELS Entry Level Scheme of Environmental Stewardship Scheme ESA Environmentally Sensitive Area FIOs Faecal indicator organisms -

Petrology and Provenance of the Siluro-Devonian (Old Red Sandstone Facies) Sedimentary Rocks of the Midland Valley, Scotland
Petrology and provenance of the Siluro-Devonian (Old Red Sandstone facies) sedimentary rocks of the Midland Valley, Scotland Geology and Landscape Northern Britain Programme Internal Report IR/07/040 BRITISH GEOLOGICAL SURVEY GEOLOGY AND LANDSCAPE NORTHERN BRITAIN PROGRAMME INTERNAL REPORT IR/07/040 Petrology and provenance of the Siluro-Devonian (Old Red Sandstone facies) sedimentary The National Grid and other Ordnance Survey data are used with the permission of the rocks of the Midland Valley, Controller of Her Majesty’s Stationery Office. Licence No: 100017897/2005. Scotland Keywords Provenance; petrography; Emrys Phillips Silurian and Devonian sandstones; Midland Valley; Scotland. Bibliographical reference Contributors: Richard A Smith and Michael A E Browne E.R. PHILLIPS. 2007. Petrology and provenance of the Siluro- Devonian (Old Red Sandstone facies) sedimentary rocks of the Midland Valley, Scotland. British Geological Survey Internal Report, IR/07/040. 65pp. Copyright in materials derived from the British Geological Survey’s work is owned by the Natural Environment Research Council (NERC) and/or the authority that commissioned the work. You may not copy or adapt this publication without first obtaining permission. Contact the BGS Intellectual Property Rights Section, British Geological Survey, Keyworth, e-mail [email protected]. You may quote extracts of a reasonable length without prior permission, provided a full acknowledgement is given of the source of the extract. Maps and diagrams in this book use topography based on Ordnance Survey mapping. © NERC 2007. All rights reserved Keyworth, Nottingham British Geological Survey 2007 BRITISH GEOLOGICAL SURVEY The full range of Survey publications is available from the BGS British Geological Survey offices Sales Desks at Nottingham, Edinburgh and London; see contact details below or shop online at www.geologyshop.com Keyworth, Nottingham NG12 5GG The London Information Office also maintains a reference 0115-936 3241 Fax 0115-936 3488 collection of BGS publications including maps for consultation. -

Classification of Metamorphosed Clastic Sedimentary Rocks: a Proposal
B. Contributed Papers - Northern Saskatchewan Geological Survey 87 88 Summary of Investigations 1999, Volume l Classification of Metamorphosed Clastic Sedimentary Rocks: A Proposal Ralf 0. Maxeiner. Chris F. Gilboy. and Gary M Yeo Maxeiner. R.0. Gilboy, C.f., and Yeo. G.M. ( 1999): Classification.of m.etamorp~osed elastic sc?iment~I)' rocks: A proposal; in Summary of Invt:stigations J 999. Volume I. Saskatchewan Geological Survey, Sask. Energy Mmes, Misc. Rep. 99-4. 1. l . Introduction classification diagrams is the rock fragment content, which is unlikely to be preserved at higher As pointed out by Gilboy ( 1982), lack of conformity in metamorphic grades. At such grades, composition naming metamorphic rocks derived from elastic alone provides no guide to the original rock fragment sediments commonly causes problems with clear content. Consequently, at medium to high communication of geological facts and hinders metamorphic grades, an arkose as defined by Pettijohn attempts at lithologic correlation. et al. ( 1973) is indistinguishable from an 'arkosic arenite' or a 'lithic' arenite. Similarly, a Most geologists working in unmetamorphosed metamorphosed 'arkosic wacke' cannot be sedimentary basins use elastic sedimentary rock distinguished from a ' lithic greywacke'. classification systems that are based on a combination of grain size, rock fragment content, and mineral The problem of classifying metamorphosed composition (e.g. Dott, 1964; Young, 1967; Folk, sedimentary rocks is not new. Tyrell ( 1921) used the 1968; Pettijohn et al.. 1973). Recrystallization during term pelite as the metamorphic derivative of fine metamorphism changes these parameters, especially grained sedimentary rock such as siltstone or grain size and rock fragment content, and therefore mudstone, and psammite as the metamorphic renders such classification diagrams of limited use for derivative of a sandstone. -

Introduction to Soils and Pedology
Introduction to Soils and Pedology • Coined in mid 19th Century by French scientist • DidDerived from Gree k: pedon=ground, log ia = discour se • “The study, in situ, of the biogeochemical processes that form and dbdistribute soil”ls” • An observational, vs. an experimental, science - nature is the laboratory • Origins attributed to two centers: Russia (Dokuchaev) and Berkeley (Hilgard) Definition of Soils • Many definitions •Soil is part of a continuum of materials at earth’ surface –Soil vs. non-soil at bottom and top –Different soils laterally •Need to divide continuum into systems, or discrete seggyments, for study •Hans Jenny (1930’s) conceptualized soils as physical systems amenable and susceptible to physical variables (STATE FACTORS) ElEcological functions of soil • Supports plant growth • Recycles nutrients and waste • Controls the flow and purity of water • Provid es habit a t for soil organisms • Functions as a building material/base Role of Pedology in Scientific and Societal Problems •Carbon and nitrogen cycles •Are soils part of an unidentified sink for CO2? •What is the effect of agricultural on soil C (and atm CO2)? •Will soils store excess N from human activity? •Chemi st ry of natural waters •How do soils release elements with time and space? •Earth history •‘Paleosols’ and evolution of land plants, atmospheric CO2 records, human evolution •Soils and archaeology •Biodiversity •Is soil diversity analogous to, and complementary to, biodiversity •Microorganisms in soil represent unknown biodiversity resources Soils as a -

Chapter 3 Sedimentary Rocks
Chapter 3 Sedimentary Rocks Rivers that flow into the Gulf of Mexico through Alabama and other Gulf Coast states are typically brown, yellow-orange or red in color due to the presence of fine particulate material suspended within the water column. This particulate material is called sediment, and it was produced through the erosion and weathering of rocks exposed far inland from the coast (including the Appalachian Mountains). Sediment transported by rivers eventually finds its way into a standing body of water. Sometimes this is a lake or an inland sea, but for those of us that reside in southern Alabama, it is almost always the Gulf of Mexico. When rivers enter standing bodies of water (e.g., the Gulf), the sediment load that they are carrying is dropped and deposition occurs. Usually deposition forms more or less parallel layers called strata. Given time, and the processes of compaction and cementation, the sediment may be lithified into sedimentary rock. It is important to note that deposition of sediment is not restricted to river mouths. It also occurs on floodplains surrounding rivers, on tidal flats, adjacent to mountains in alluvial fans, and in the deepest portions of the oceans. Sedimentation occurs everywhere and this is one of the reasons why your humble author finds sedimentary geology so fascinating. Sedimentary rocks comprise approximately 30% of all of the rocks exposed at the Earth's surface. Those that are composed of broken rock fragments formed during erosion of bedrock are termed siliciclastic sedimentary rocks (or clastic for short). Sedimentary rocks can also be produced through chemical and biochemical deposition. -

Soils As Pacemakers and Limiters of Global Silicate Weathering
Originally published as: Dixon, J. L., von Blanckenburg, F. (2012): Soils as pacemakers and limiters of global silicate weathering. ‐ Comptes Rendus Geoscience, 344, 11 ‐ 12, 597‐609 DOI: 10.1016/j.crte.2012.10.012 Soils as pacemakers and limiters of global silicate weathering Jean L. Dixon1,2 and Friedhelm von Blanckenburg1 1 Helmholtz Centre Potsdam, GFZ German Centre for Geosciences, Telegraphenberg, 14473 Potsdam, Germany 2 Department of Geography, University of California, Santa Barbara, CA 93106, USA Keywords: chemical weathering, soil production, speed limits, erosion, regolith, river fluxes Comptes rendus – Geosciences 344, 597-609, 2012 Abstract The weathering and erosion processes that produce and destroy regolith are widely recognized to be positively correlated across diverse landscapes. However, conceptual and numerical models predict some limits to this relationship that remain largely untested. Using new global data compilations of soil production and weathering rates from cosmogenic nuclides and silicate weathering fluxes from global rivers, we show that the weathering- erosion relationship is capped by certain ‘speed limits’. We estimate a soil production speed limit of between 320 to 450 t km-2 y-1 and the associated weathering rate speed limit of roughly 150 t km-2 y-1. These limits appear to be valid for a range of lithologies, and also extend to mountain belts, where soil cover is not continuous and erosion rates outpace soil production. We argue that the presence of soil and regolith is a requirement for high weathering fluxes from a landscape, and that rapidly eroding, active mountain belts are not the most efficient sites for weathering.