Lighttrack: Finding Lightweight Neural Networks for Object Tracking Via One-Shot Architecture Search
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Harga Gadget 19 APRIL 2021.Xlsx
DATE : 21 APRIL 2021 SENARAI HARGA TELEFON *POTONGAN PINJAMAN TAHUNAN (RM) BIL MODEL DESKRIPSI TUNAI (RM) 1 234567 SAMSUNG 1 SAMSUNG A022 (3+32gb) AKSESORI STANDARD 399.00 46 24 17 13 11 10 8 1 SAMSUNG A025/A02S (4+64gb) AKSESORI STANDARD 529.00 58 31 21 17 14 12 11 1 SAMSUNG A125 (6+128GB) AKSESORI STANDARD 799.00 84 44 31 24 20 17 15 1 SAMSUNG A42 (8+128GB) 5G AKSESORI STANDARD 1,599.00 158 84 58 46 38 33 29 1 SAMSUNG A32 (8+128GB) 4G (NEW) AKSESORI STANDARD 1,099.00 112 59 41 32 27 23 21 1 SAMSUNG A32 (8+128GB) 5G (NEW) AKSESORI STANDARD 1,199.00 121 64 45 35 29 25 22 1 SAMSUNG A52 (8+256GB) (NEW) AKSESORI STANDARD 1,499.00 149 79 55 43 36 31 28 1 SAMSUNG A72 (8+256GB) (NEW) AKSESORI STANDARD 1,799.00 177 94 65 51 42 37 33 1 SAMSUNG A515 (8+256GB) (NEW) AKSESORI STANDARD 1,399.00 140 74 51 40 33 29 26 1 SAMSUNG A715 (8+128GB) AKSESORI STANDARD 1,699.00 168 89 62 48 40 35 31 1 SAMSUNG GALAXY FOLD 2 5G (F916b) AKSESORI STANDARD 7,999.00 758 400 279 218 182 157 140 1 SAMSUNG Z FLIP AKSESORI STANDARD 3,999.00 383 202 141 110 92 80 71 1 SAMSUNG S20 FE 5G (G781) AKSESORI STANDARD 2,999.00 290 153 107 83 69 60 53 1 SAMSUNG S21 (128GB) (NEW) AKSESORI STANDARD 3,499.00 336 178 124 97 81 70 62 1 SAMSUNG S21 (256GB) (NEW) AKSESORI STANDARD 3,699.00 355 188 131 102 85 74 66 1 SAMSUNG S21+ (128GB) (NEW) AKSESORI STANDARD 3,999.00 383 202 141 110 92 80 71 1 SAMSUNG S21+ (256GB) (NEW) AKSESORI STANDARD 4,299.00 411 217 151 118 99 85 76 1 SAMSUNG S21 ULTRA 5G (128GB) (NEW) AKSESORI STANDARD 4,999.00 477 252 175 137 114 99 88 1 SAMSUNG S21 ULTRA 5G -

Smartphone Design Win Quarterly Monitor
QUARTERLY TECHNOLOGY MONITOR Smartphone Design Win Quarterly Monitor Q1 2021 A first ever smartphone technology monitor on the latest components, packaging and silicon chip choices of the smartphone makers. This smartphone monitor utilizes data from wins (17% of total design wins) and package representative phones (65+ phones per year footprint consumption (21%). Snapdragon torn down in the System Plus Consulting processors and RF components (transceivers, Phone Teardown Track Module) and follows RFFEM) explain this. the OEM market share, which means that the Regarding die area consumption, Samsung selected phones are a good representation of leads (30% of total die area) thanks to the market. Also provided is the detailed memories and image sensors. design wins and related supply chain for the BGA and LGA packages are the main eight phones being analyzed, along with packaging platform, with 37% of package supply chain alternatives for the main devices. footprint consumption. For each device and module, you get access to U.S.-based companies account for 47% of IC Title: Smartphone the technology choices of the manufacturers. Design Win Quarterly design wins and 43% of total die area Monitor - Q1 2021 This monitor offers a clear view of the market- (Qualcomm, Qorvo, Skyworks, Texas leading semiconductor companies and a direct Instruments and Cirrus Logic have the Pages: 150 comparison between OEMs. This includes: majority). Even though Korea represents only Date: April 2021 oDesign wins for the top smartphones' OEM 6% of the IC design wins number, it represents Format: (per Mfr., nationality, type of device…) 33% in terms of the total die area. -

Huawei-Nova-7-5G-Phone Datasheet Overview
Huawei-Nova-7-5G-Phone Datasheet Get a Quote Overview Huawei Nova 7 5G Phone, Huawei 5G Cell Phone, 5G Dual-mode(SA/NSA), 6.53 inches, 1080 x 2400 pixels, Android 10.0 (AOSP + HMS); EMUI 10.1; HiSilicon Kirin 985 5G (7 nm). Quick Spec Table 1 shows the Quick Specs. Product Code Huawei Nova 7 5G Phone 5G Mode SA/NSA SIM Dual SIM (Nano-SIM, dual stand-by) OS Android 10.0 (AOSP + HMS); EMUI 10.1 Chipset HiSilicon Kirin 985 5G (7 nm) CPU Octa-core (1x2.58 GHz Cortex-A76 & 3x2.40 GHz Cortex-A76 & 4x1.84 GHz Cortex-A55) GPU Mali-G77 (8-core) Display Type OLED capacitive touchscreen, 16M colors Screen Size 6.53 inches, 102.9 cm2 (~86.3% screen-to-body ratio) Resolution 1080 x 2400 pixels, 20:9 ratio (~403 ppi density) Card slot No Product Details Fluid Aesthetics, Refined Craftsmanship Floats on air, falls into your heart Wafer-thin at 7.96 mm,2 and feather-light at around 180 grams2, the HUAWEI nova 7 is a crafted masterpiece that fits seamlessly in your palm. An iconic 3D CMF process produces a breathtaking colour show, bringing waves of shimmering splendour to the surface. Latest-Gen OLED HUAWEI Punch FullView Display3 Stunning screen, no compromise Thanks to a flawless 6.53" design3 with ultra-slim bezels, a spectacular 2400 x 1080 resolution and cinematic DCI-P3 color rendering, this new HUAWEI Punch FullView Display is always a pleasure to look at and the TÜV Rheinland certified4 eye comfort feature5 makes the fun time last longer. -
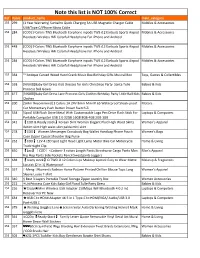
Note This List Is NOT 100% Correct
Note this list is NOT 100% Correct Ref Value product_name main_category 151 299 (1 Year Warranty) Suntaiho Quick Charging 3A USB Magnetic Charger Cable Mobiles & Accessories USB/Type C/iPhone Micro Cable 151 284 (COD) 9 Colors TWS Bluetooth Earphone inpods TWS i12 Earbuds Sports Airpod Mobiles & Accessories Headsets Wireless HiFi Colorful Headphone For iPhone and Android 151 448 (COD) 9 Colors TWS Bluetooth Earphone inpods TWS i12 Earbuds Sports Airpod Mobiles & Accessories Headsets Wireless HiFi Colorful Headphone For iPhone and Android 151 284 (COD) 9 Colors TWS Bluetooth Earphone inpods TWS i12 Earbuds Sports Airpod Mobiles & Accessories Headsets Wireless HiFi Colorful Headphone For iPhone and Android 151 364 **Antique Carved Wood Hand Crank Music Box Birthday Gifts Musical Box Toys, Games & Collectibles 151 338 [NNJXD]Baby Girl Dress Kids Dresses for Girls Christmas Party Santa Tulle Babies & Kids Princess Ball Gown 151 617 [NNJXD]Baby Girl Dress Lace Princess Girls Clothes Birthday Party Little Ball Kids Babies & Kids Clothes 151 200 [Seller Recommend] 3 Colors 1A 24V 8mm Mini IP 65 Waterproof Shock-proof Motors Car Momentary Push Button Power Switch Zi 151 534 [Spot] USB Flash Drive Metal With Customizable Logo Pen Drive Flash Stick For Laptops & Computers Portable Computer USB 2.0 32GB 16GB 8GB 4GB 2GB 1GB 151 341 【COD & Ready stock】Korean Skirt Women Elegant Plaid High Waist Skirts Women's Apparel denim skirt High waist skirt palda mini skirt 151 278 【COD】 Women Messenger Crossbody Bag Wallet Handbag Phone Pouch Women's Bags Case -
![Acoylco an Emarketplace Platform in Singapore [Demo] Huawei Nova 7](https://docslib.b-cdn.net/cover/6683/acoylco-an-emarketplace-platform-in-singapore-demo-huawei-nova-7-3176683.webp)
Acoylco an Emarketplace Platform in Singapore [Demo] Huawei Nova 7
Acoylco [Demo] Huawei Nova 7 SE 5G An eMarketPlace Platform in Singapore https://acoylco.com/product/demo-huawei-nova-7-se-5g/ [DEMO] HUAWEI NOVA 7 SE 5G $528.00 Huawei Nova 7 SE 5G Youth has been launched as the latest smartphone offering from the company. The phone is powered by the MediaTek Dimensity 800U SoC and packs a 4,000mAh battery. It is a slightly watered-down model of the Huawei Nova 7 SE 5G that was launched in April this year. Apart from the processor, there is little else that is different between the two smartphones. Other phones in this series include Huawei Nova 7 5G and Huawei Nova 7 5G Pro, both of which are comparatively premium models. SKU: N/A Categories: Huawei, IT & Electronics, Phones Tags: 5G, Handphone, Huawei, Nova 7 SE 5G Page: 1 Acoylco [Demo] Huawei Nova 7 SE 5G An eMarketPlace Platform in Singapore https://acoylco.com/product/demo-huawei-nova-7-se-5g/ All-Powerful Kirin 820 5G SoC NEXT-LEVEL MOBILE PROCESSING, REIMAGINED The HUAWEI nova 7SE features the new and improved 7nm Kirin 820, a balanced chipset that incorporates an advanced 8-core CPU, 6-core GPU and proprietary NPU, harnessing next-level intelligence to achieve a new realm of performance. The Kirin ISP 5.0 works to ensure that image processing and photo/video denoising are top-notch across the board. Page: 2 Acoylco [Demo] Huawei Nova 7 SE 5G An eMarketPlace Platform in Singapore https://acoylco.com/product/demo-huawei-nova-7-se-5g/ 64 MP AI QUAD-CAMERA SYSTEM Capture Beauty on Every Level Capture sweeping landscapes with crystal clarity, crawling critters from up close, or enchanting portraits all on a staggering 64 MP camera. -

Schools Are Safe, No Reason to Fear Or Worry
QatarTribune Qatar_Tribune TUESDAY QatarTribuneChannel qatar_tribune SEPTEMBER 8, 2020 MUHARRAM 20, 1442 VOL.14 NO. 5046 QR 2 Fajr: 3:59 am Dhuhr: 11:32 am Asr: 3:00 pm Maghrib: 5:47 pm Isha: 7:17 pm Business 9 Sports 13 MoCI, QC sign MoU Djokovic says ‘so sorry’ FINE to issue Arab but feels shouldn’t have HIGH : 42°C e-certificate of origin been disqualified LOW : 30°C COVID-19 recoveries surpass 117,000 Schools are safe, TRIBUNE NEWS NETWORK DOHA no reason to fear QATAR on Monday reported 253 corona- virus (COVID-19) cases -- 233 from com- munity and 20 from travellers returning from abroad, the Ministry of Public Health (MoPH) said in its daily report. or worry: Official Also, 243 people recovered from the virus in the past 24 hours, bringing the total number of recoveries in Qatar to 85% attendance 117,241. Sadly, two more people – aged 71 and 76 – succumbed to the virus, tak- in most schools ing the death toll in the country to 205. TRIBUNE NEWS NETWORK The MoPH said all the new cases DOHA have been introduced to isolation and are receiving necessary healthcare ac- THE number of coronavirus cases re- cording to their health status. ported in schools is very few and there is no reason to fear or worry, a senior ministry official has said. The schools are safe for children, he added. “Among more than 340,000 stu- dents and 30,000 teachers in schools, Continuous coordination between the QRCS PROVIDES HUMANITARIAN AID the number of cases that have been Ministry of Education and Higher Educa- confirmed to have coronavirus is very tion and the Ministry of Public Health to TO HELP SUDAN FIGHT COVID-19 few,” Mohamed Al Bishri, an advi- ensure safety in schools. -

Huawei Pay Frequently Asked Questions (“Faqs”)
Huawei Pay Frequently Asked Questions (“FAQs”) 1. What is Huawei Pay? Huawei Pay is a mobile payment service launched by Huawei. Huawei Pay allows on-the-go payments with phones capable of Near Field Communication (NFC), instead of using your physical ICBC cards. With Huawei Pay, you can make secured and convenient payments, simply by tapping your NFC-capable phone against a contactless payment terminal or card reader. To use Huawei Pay, simply download Huawei Wallet Application (“Wallet”) from Huawei AppGallery (“AppGallery”) and complete the registration process. 2. Does my phone support Huawei Pay or Access card? Among phones purchased outside of the Chinese mainland, the following models support Huawei Pay or Access card: HUAWEI Mate Xs, Mate X, Mate 40 Pro, Mate 30, Mate 30 Pro, PORSCHE DESIGN Mate 30 RS, Mate 20 X (5G), Mate 20, Mate 20 Pro, PORSCHE DESIGN Mate 20 RS, PORSCHE DESIGN Mate RS, Mate 10, Mate 10 Pro, PORSCHE DESIGN Mate 10, Mate 9, Mate 9 Pro, PORSCHE DESIGN Mate 9 HUAWEI P40, P40 Pro, P40 Pro+, P30, P30 Pro, P20, P20 Pro, P10, P10 Plus HUAWEI nova 7 5G HONOR 30 Pro+, HONOR 30, HONOR View30 Pro, HONOR 10, HONOR View10, HONOR 9, HONOR 8 Pro Among phones purchased in the Chinese mainland, the following models support Huawei Pay or Access card: HUAWEI Mate Xs, Mate X, Mate 40 Pro, Mate 30, Mate 30 Pro, PORSCHE DESIGN Mate 30 RS, Mate 20, Mate 20 Pro, PORSCHE DESIGN Mate 20 RS HUAWEI P40, P40 Pro, P40 Pro+, P30, P30 Pro Before using Huawei Pay or Access card, ensure that you have updated your phone and Wallet to the latest version. -

Varsity Brands
TikTok to challenge Trump crackdown in court PAGE 10 MONDAY, AUGUST 24, 2020 27,930.33 9,809.05 38,434.72 1,940.47 +190.60 PTS +41.87 PTS +214.33 PTS GOLD -0.35% South Africa retailers feel pain from DOW QE SENSEX coronavirus pandemic PAGE 11 PRICE PERCENTAGE PRICE PERCENTAGE 26.88 BRENT 44.35 -1.22% WTI 42.34 -1.12% SILVER -1.55% Industries Qatar acquires QP’s 25% stake in QAFCO owner of the world’s largest single In addition, and as part of the The $1 billion deal reaffirms Industries Qatar’s site urea producer and expanding same transaction, IQ’s board of its footprints in a well-established directors also approved QAFCO’s position and value proposition in industrial sector fertiliser business, with a proven acquisition of Qatar Petroleum’s track record of operational excel- 40 percent stake in QMC, effective TRIBUNE NEWS NETWORK the shareholders’ approval of the lence and market positioning, along from July 1, 2020. DOHA transaction. with resilient cash flow generation Being the sole shareholder of The effective date of the trans- capabilities, spurred by synergistic QAFCO, IQ will now have full con- INDUSTRIES Qatar (IQ), one of action would be January 1, 2020, opportunities. trol of QAFCO, which would provide the region’s industrial giants, on until expiry of the new Gas Sale As part of the transaction, IQ the ability to appoint all mem- Sunday announced that the com- and Purchase Agreement (GSPA), QAFCO has entered into a new bers of QAFCO’s board of directors, pany has approved the proposed for a proposed purchase considera- GSPA with Qatar Petroleum with and make investing, financing and purchase of Qatar Petroleum’s 25 tion of $1 billion. -

Huawei-Nova-7-Pro-5G-Phone Datasheet Overview
Huawei-Nova-7-Pro-5G-Phone Datasheet Get a Quote Overview Huawei Nova 7 Pro 5G Phone, Huawei 5G Cell Phone, 5G Dual-mode(SA/NSA); 6.57 inches, 1080 x 2340 pixels, Android 10.0 (AOSP + HMS); EMUI 10.1; HiSilicon Kirin 985 5G (7 nm). Quick Spec Table 1 shows the Quick Specs. Product Code Huawei Nova 7 Pro 5G Phone 5G Mode SA/NSA SIM Dual SIM (Nano-SIM, dual stand-by) OS OS: Android 10.0 (AOSP + HMS); EMUI 10.1 Chipset HiSilicon Kirin 985 5G (7 nm) CPU Octa-core (1x2.58 GHz Cortex-A76 & 3x2.40 GHz Cortex-A76 & 4x1.84 GHz Cortex-A55) GPU Mali-G77 (8-core) Display Type OLED capacitive touchscreen, 16M colors Screen Size 6.57 inches, 106.0 cm2 (~89.6% screen-to-body ratio) Resolution 1080 x 2340 pixels, 19.5:9 ratio (~392 ppi density) Card slot No Product Details Compare to Similar Items Table 2 shows the comparison. Model HUAWEI nova 7 5G Phone HUAWEI nova 7 Pro 5G Phone HUAWEI nova 7 SE 5G Phone Dimensions Width: 74.33 mm Width: 73.74mm Width: 75.0 mm Height: 160.64 mm Height: 160.36mm Height: 162.31 mm Depth: 7.96 mm Depth: 8.28 mm Depth:8.58 mm Size 6.53 inches 6.57 inches 6.5 inches Colour 16.7 million colours, Wide Color 16.7 million colours, Wide Color 16.7 million colours, Wide Color Gamut (DCI-P3) Gamut (DCI-P3) Gamut (NTSC): 96%(Typical Value) Resolution 2400 x 1080 Pixels 1080 x 2340 pixels 2400 x 1080 pixels Chipest HUAWEI Kirin 985 HUAWEI Kirin 985 HUAWEI Kirin 820 CPU Octa-core Processor Octa-core Processor Octa-core Processor Operating System EMUI 10.1 (Based on Android 10) EMUI 10.1 (Based on Android 10) EMUI 10.1 (Based on Android -

Campaign? This “Huawei Beyond A
Frequent Ask Questions 1. What is the “Huawei Beyond a TV” campaign? This “Huawei Beyond a TV” campaign (“Campaign”) is a Huawei campaign that rewards Huawei customers who purchase selected Huawei device model from the participating HUAWEI Brand Stores, HUAWEI Operator Stores or HUAWEI Online Store (https://shop.huawei.com/my/) from 27th April 2021, 12:00AM (GMT+8) to 16th May 2021, 11:59PM (GMT+8) (“Campaign Period”). This Campaign comprises of three (3) Events: Lucky Draw, 1 to 1 Give Away Free Gift and Additional Give Away. Please refer to the terms and conditions for further details of each event. 2. Who can participate in this “Huawei Beyond a TV” campaign? This Campaign is open to all individuals who are residents of Malaysia, and aged 18 years old and above as of 27th April 2021 (“Customer(s)”). Employees of Huawei, their immediate families, Huawei’s dealers, partners, advertising, creative and public relations agencies, program organizer, their employees and immediate families is not eligible to participate in this Campaign. 3. How to participate in the Lucky Draw Event of this Campaign? You must within the Campaign Period, purchase the selected Huawei Product below from a participating HUAWEI Brand Stores, HUAWEI Operator Stores or HUAWEI Online Store (https://shop.huawei.com/my/) to be entitled to submit an entry for the Lucky Draw Event:- a) Huawei Mate 40 Pro b) Huawei P40 c) Huawei P40 Pro d) Huawei P40 Pro + e) Huawei Mate 30 f) Huawei Mate 30 Pro g) Huawei Mate 30 Pro (5G) h) Huawei Matebook X Pro (i5) i) Huawei Matebook -

5G NOW Market Trial Terms and Conditions
5G NOW Market Trial Terms and Conditions The three-month trial will extend free 5G connectivity and an additional 10GB of local data to 20,000 early adopters for three months. This includes 10,000 existing Singtel Combo and XO customers with compatible 5G handset who will be progressively provisioned with 3 free months of seamless 5G connectivity and additional 10GB of local data. The next 10,000 eligible customers who sign up/recontract on Singtel Combo and XO plans; and purchase compatible handset will also get to trial 3 free months of 5G connectivity and additional 10GB of local data. Subsequently, customers who are keen on 5G can also enjoy our 5G NOW market trial by adding on Singtel 5G NOW 10GB Add-on at a promotional price of S$10 per month1 (12-month term) when they sign up/recontract on Singtel Combo and XO mobile plans with compatible 5G handsets. Customers who sign up/recontract on Singtel Combo and XO mobile plans with 5G handsets that are not yet software ready2 can also add on Singtel 5G NOW 10GB Add-on at a promotional price of S$10 per month (12-month term) before 9 January 2021. 5G access will be turned on once these devices rollout software updates to be compatible with our 5G network. From 9 January 2021, customers who sign up/recontract on Combo or XO with 5G mobile plans on a 5G handset will be able to enjoy an additional 10GB of data (12-month term) and free 5G NOW market trial access at $15/month. -

Huawei-Nova-7-SE-5G-Phone Datasheet Overview
Huawei-Nova-7-SE-5G-Phone Datasheet Get a Quote Overview HUAWEI Nova 7 SE 5G Phone, Huawei 5G Cell Phone, 5G Dual-mode(SA/NSA), 6.5 inches, 1080 x 2400 pixels, Android 10.0 (AOSP + HMS); EMUI 10.1; HiSilicon Kirin 820 5G (7 nm). Quick Spec Table 1 shows the Quick Specs. Product Code Huawei Nova 7 SE 5G Phone 5G Mode SA/NSA SIM Dual SIM (Nano-SIM, dual stand-by) OS Android 10.0 (AOSP + HMS); EMUI 10.1 Chipset HiSilicon Kirin 820 5G (7nm) CPU Octa-core (1x2.36 GHz Cortex-A76 & 3x2.22 GHz Cortex-A76 & 4x1.84 GHz Cortex-A55) GPU Mali-G57 (6-core) Display Type LTPS IPS LCD capacitive touchscreen, 16M colors Screen Size 6.5 inches, 102.0 cm2 (~83.8% screen-to-body ratio) Resolution 1080 x 2400 pixels, 20:9 ratio (~405 ppi density) Card slot NM (Nano Memory), up to 256GB (uses shared SIM slot) Product Details A New Spin on Craftsmanship A Stunning Design that Appeals to All Watch light dance across the beautifully textured 3D glass surface as you turn it slowly in your hand. The phone has been crafted to be as amazing to hold as it is to look at with functions such as the side-mounted power button unlocking the screen within a quarter of a second3, providing hassle-free use. Blistering-Fast 5G Internet Keep up with Your Fast-paced Life Pure 5G4, or Dual SIM 5G+4G — your best connection is always on hand! It's your chance to experience the game-changing 5G era ahead of the crowd.