Applied AI and Machine Learning in Translational Medicine
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Abstracts from the Research Symposium for Medical Students and Foundation Doctors 20 November 2019
Abstracts from the Research Symposium for Medical Students and Foundation Doctors 20 November 2019 November 2019 This abstract book has been produced using author-supplied copy and no editing has been undertaken. No responsibility is assumed for any claims, instructions, methods or drug dosages included in the abstracts: it is recommended that these are verified independently. Undergraduate Prizes Best undergraduate oral presentation Socioeconomic differences in cardiovascular disease risk factor prevalence in people with type 2 diabetes in Scotland: a cross-sectional study Edward Whittaker (Supervisor: Prof. Sarah Wild) University of Edinburgh INTRODUCTION: Health inequalities exist in outcomes of diabetes in different socioeconomic groups and these are particularly marked for cardiovascular disease and its risk factors1. The aim of this study was to describe the association between socioeconomic status and prevalence of cardiovascular risk factors (smoking, body mass index, HbA1C, blood pressure and cholesterol) in people with type 2 diabetes in contemporary Scottish data. PATIENTS AND METHODS: A cross-sectional study was performed of 264,011 people with type 2 diabetes in Scotland who were alive on 30/06/16, identified from the population-based diabetes register. Socioeconomic status was defined using quintiles of the area-based SIMD with Q1 and Q5 used to identify the most and least deprived fifths of the population respectively. Logistic regression models adjusted for age, sex, health board, history of cardiovascular disease and duration of diabetes were used to estimate odds ratios (OR) (and 95% confidence intervals) for Q1 compared to Q5 for each risk factor. RESULTS: The mean (SD) age of the study population was 66.7 (12.8) years, 56.1% were men, 23.6% were in Q1 and 15.1% in Q5. -

Embedding Physical Activity in the Undergraduate Curriculum
July 2018 Embedding physical activity in the undergraduate curriculum Commissioned by Public Health England (PHE) and Sport England to embed physical activity in the undergraduate curricula in a sample of medical schools and schools of health in England during 2017 and 2018. This is part of the PHE & Sport England’s Moving Healthcare Professionals Programme Authors on behalf of Exercise Works Ltd Ann B. Gates MRPharmS BPharm (Hons) Ian K. Ritchie FRCSEd Executive Summary July 2018 movement for movement Forewords A final year medical student’s view on the lack of exercise medicine in undergraduate curricula As a medical student about to graduate, I have been left disappointed by the lack of exercise medicine I have been exposed to during my time at medical school. Despite it being a well-established way to prevent, treat and manage illness, exercise medicine does not feature significantly in medical curricula throughout the United Kingdom. As a result, there is lack of knowledge and awareness in the medical community. This issue is not limited to doctors: all allied health care professionals are in a position to influence positive lifestyle changes and all should be exposed to exercise medicine in their undergraduate curricula. We are currently missing out on a fantastic opportunity to empower the health care professionals of the future to be confident in advising patients about utilising exercise to improve their health and quality of life. This commission report demonstrates that physical activity can be successfully integrated into medical school curricula, and that students can encourage and support this being implemented. Katie Marino Final year medical student, University of Sheffield. -
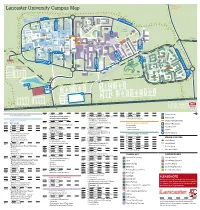
Campus Map CAMPUS
Forrest Hills SOUTH EAST Lancaster University Campus Map CAMPUS NORTH CAMPUS FURNESS AVE B TOWER AVE E C PHYSICS AVE ISO JOHN CREED AVE COUNTY AVE Bailrigg Service Station LANCASTER SQUARE AVE CTP Maintenance GEORGE FOX AVE UNDERPASS Workshops COM PHS WWB County College FYLDE AVE SOUTH CHE CAMPUS D ISS COS The PSC Orchard FAR Bonington Square Step Lancaster TRH Square FAS SBH GFX INF Physics Garden Cycle Route to NORTH DRIVE Fylde College Ellel & Galgate Great Edward SOUTH DRIVE Hall BLN BLM Roberts Court GHC Court Bowland Bowland FUR Wetland North Quad Fylde Grizedale College Quad WEL Furness College Quad Furness Alexandra College Court FYL SAT LIC Square Pendle College Welcome LEC Great Hall Centre CHC Square Reception Engineering F Square Cycle Route to PENDLE AVE ASH Bowland College City Centre BLA Students’ Union ROSSENDALE AVE LIB ENG LSE BLH A Arrival UNH Point University GRIZEDALE AVE House MAN Reception BOWLAND AVE G Graduate College HRB UNDERPASS CPC BOWLAND AVE FARRER AVE GILLOW AVE F Graduate BRH LIBRARY AVE SEC Square A GRADUATE AVE LCC CARTMEL AVE Netball Courts South West I Campus ALEXANDRA PARK DRIVE Barker NORTH WEST RUS House BHF Entrance Lancaster Court House Hotel CAMPUS H Cartmel College Rugby League Pitch PARK BOULEVARD Lacrosse Pitch ECO BARKER HOUSE AVE MED J PRE Lonsdale SOUTH WEST CAMPUS Quad LONSDALE AVE HAZELRIGG LANE Lonsdale College BFB Lake Carter Grass Playing Pitch Astro Turf Pitch L Grass Playing Pitch L Grass Playing Pitch Grass Playing Pitch Grass Playing Pitch 3rd Generation Artificial Pitch Astro Turf -

Short-Term Forecasts to Inform the Response to the Covid-19 Epidemic in the UK
medRxiv preprint doi: https://doi.org/10.1101/2020.11.11.20220962; this version posted December 4, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. It is made available under a CC-BY 4.0 International license . Short-term forecasts to inform the response to the Covid-19 epidemic in the UK 1* 1 2 3 4,5 6,7 6 1 8 Funk S , Abbott S , Atkins BD , Baguelin M , Baillie JK , Birrell P , Blake J , Bosse NI , Burton J , 7 1 6,7 2 1 1 3 Carruthers J , Davies NG , De Angelis D , Dyson L , Edmunds WJ , Eggo RM , Ferguson NM , 3 2 2 1 2 2 9 10 Gaythorpe K , Gorsich E , Guyver-Fletcher G , Hellewell J , Hill EM , Holmes A , House TA , Jewell C , 1 1 11 2 12 3 1 13 Jit M , Jombart T , Joshi I , Keeling MJ , Kendall E , Knock ES , Kucharski AJ , Lythgoe KA , Meakin 1 1 14 9 9 11 3 9,15 SR , Munday JD , Openshaw PJM , Overton CE , Pagani F , Pearson J , Perez-Guzman PN , Pellis L , 16 17,18 1 12 2 7 3,7 Scarabel F , Semple MG , Sherratt K , Tang M , Tildesley MJ , Van Leeuwen E , Whittles LK , CMMID COVID-19 Working Group, Imperial College COVID-19 Response Team, ISARIC4C Investigators 1 Centre for Mathematical Modelling of Infectious Diseases, London School of Hygiene & Tropical Medicine, Keppel St, London, WC1E 7HT, UK 2 The Zeeman Institute for Systems Biology & Infectious Disease -

LU Campus Map.Indd
Lancaster Campus E NORTH CAMPUS SOUTH EAST CAMPUS Forrest Hills 0.5 Miles B C ISO Maintenance E Workshops N S Garage & Fuel Station CTP COM PHS WWB County W College CHE ISS The PS D COS FAR Bonington C Lancaster Step Square TRH Physics FAS SBH GFX INF Garden SOUTH CAMPUS Cycle Route to North Spine Fylde Ellel & Galgate Great Edward College Hall BLN BLM Roberts Court Bowland Court Furness Fylde Grizedale North FUR GHC Bowland College Quad College Quad WEL Quad BLE Pendle Alexandra South Spine Furness FYL SAT College LIC Square College Court Great Welcome CHC Hall Centre Engineering Cycle Square Reception Bowland Square F Route to ASH College City BLA Students’ Union Centre LIB ENG Arrival LEC BLH A Point UNH LSE University House Reception Graduate College E HRB MAN V CPC A E T BRH A U D Graduate A SEC R E G Square G I AV ALEXANDRA EL South A RTM LCC CA West S Campus Entrance RU Lancaster BHF Lacrosse Pitch House Hotel PARK DRI Barker NORTH WEST RD House Cartmel H ULEVA RK BO Court College RA PA ALEXAND H CAMPUS KER O ECO VE Lonsdale BAR U S D Quad E J ME A PRE VE LO NSD Lonsdale ALE Rugby League College A Pitch BFB V Lake Carter Grass Pitch E M Astro Turf L HIO L Grass Pitches Bowling Green SOUTH WEST 3G Artificial Pitch Astro Turf SPC CAMPUS Grass Pitches Cycle K Route to City Grass Playing Pitch Centre Grass Playing Pitch Tennis Courts M6 Junction 33 e ANCE Lancas ter City Centr MAIN ENTR ANCE HEALTH INNOVATION CAMPUS ENTR SYMBOL KEY WALKS & ROUTES CAMPUS ZONES Accessible Parking co Colleges Library Shops/Refreshments Cycle Route North -

Abstracts from the Medical Research Symposium for Students and Foundation Doctors 21 November 2018
Abstracts from the Medical Research Symposium for Students and Foundation Doctors 21 November 2018 November 2018 This abstract book has been produced using author-supplied copy and no editing has been undertaken. No responsibility is assumed for any claims, instructions, methods or drug dosages included in the abstracts: it is recommended that these are verified independently. Undergraduate Prizes Best undergraduate oral presentation Comparing Outcomes of Stent Retriever Thrombectomy versus Direct Aspiration for the Endovascular Treatment of Acute Anterior Circulation Stroke SE Thompson, R Jones, K Nader Birmingham Medical School Introduction Endovascular therapy with a stent retriever has been shown to be superior to standard medical therapy in the treatment of acute ischaemic stroke and is recommended by the American Stroke Association. Direct aspiration thrombectomy is another commonly used method increasing in popularity with advances in catheter technology. Few studies have directly compared the efficacy of the two methods, with current evidence equivocal. This study compares the stent retriever and direct aspiration methods. Patients and methods 101 patients presenting to the Queen Elizabeth Hospital Birmingham between January 2013-November 2017 with anterior circulation ischaemic stroke, fulfilling the criteria for endovascular therapy, were retrospectively analysed. 45 patients underwent first-line stent retriever thrombectomy and in 56 patients, direct aspiration was the primary method. The primary outcome was successful revascularization (TICI 2b/3) and secondary outcomes included procedural and clinical measures. Results Successful revascularization was achieved more frequently when direct aspiration was the primary chosen method (91.1% vs. 57.8%, p=0.000) and was significantly more likely to be successful with a single pass (p=0.005). -

Lancaster University Annual Report and Accounts 2011
LAncAsteR UniveRsity AnnUAL RepoRt And AccoUnts 2011 Lancaster University 1 1 Lancaster 0 2 LA1 4YW s t United Kingdom n u o c T: +44(0)1524 65201 c A www.lancs.ac.uk d n a ISBN 978-1-86220-290-0 t r o p e R y t i s r e v i n U r e t s a c n a L Lancaster University has been awarded the Carbon Trust Standard after taking action on climate change by reducing carbon emissions. The University has made an overall reduction of 245 tonnes of carbon or 0.9% averaged over the past three years. Lancaster University 1 Contents Vice-Chancellor’s review 2 Pro-Chancellor’s review 4 High notes of the year 6 A global university 12 Awards and distinctions 18 Advancing knowledge through research 30 Key facts and figures 42 Financial Statements 46 Operating and Financial Review for the year ended 31 July 2011 48 Statement of Corporate Governance 56 Independent Auditors’ Report to the Council of Lancaster University 61 Statement of Accounting Policies 62 Consolidated Income and Expenditure Account 64 Statement of Consolidated Historical Cost Surpluses and Deficits 65 Balance Sheets as at 31 July 20 11 66 Consolidated Cash Flow Statement 67 Reconciliation of Net Cash Flow to movement in Net Debt 68 Consolidated Statement of Total Recognised Gains and Losses 69 Notes to the Financial Statements 70 Chancellor’s Guild roll of honour 92 Chancellor’s Guild corporate donors and legacy pledges 93 Trusts, foundations and charities 94 Organisational chart 95 Lancaster University Report and Accounts 2011 3 ViCe-ChanCellor’s reView The growing reputation of Lancaster was marked this year by top ten placings in each of the UK’s major university been strengthened with a formal respond to this feedback to make sure The Government’s White Paper “Students collaboration with the Chinese Academy every department is outstanding. -

Dr Faraz Ahmed Senior Research Associate, Division of Health Research
Dr Faraz Ahmed Senior Research Associate, Division of Health Research Faraz is currently a Research Associate at Lancaster University, following his Medical Research Council PhD studentship at the Institute of Public Health (University of Cambridge). Faraz's current work at Lancaster University is within the national Neighbourhoods and Dementia Programme(http://www.neighbourhoodsanddementia.org/), which aims to develop the evidence base for dementia training in NHS hospitals (a mixed method study). Viewing the acute hospital as a neighbourhood space increasingly occupied by people living with dementia, his research will examine the impact of dementia training on staff skills, knowledge, confidence and satisfaction, and improved outcomes for patients living with dementia in the acute hospital settings. Faraz is a Public Health researcher, with extensive experience in international health and working with minority ethnic communities in the UK. Prior to starting his research at the Institute of Public Health (University of Cambridge), he was working as a Research Fellow at the University of York. He holds an MSc in International Health from the University of Leeds and has a strong interest in addressing inequalities in health. His previous experience includes public-private partnerships in increasing TB case-detection among poor and disadvantaged groups, health systems evaluation, and developing and evaluating health promotion programmes for minority ethnic groups. Research Overview/Interests Brief summary of current area of work: Neighbourhoods and Dementia Programme (N&D) (PI Dr Siobhan Reilly) The Improving Dementia Care Lancaster University research team are currently conducting two studies within the Neighbourhoods and Dementia Programme (2014-2019) funded by the NIHR/ESRC My research interests focus on patient experience, dementia, equity and health services research. -

Analysis of Research and Education Indicators to Support Designation of Academic Health Science Centres in England
CHILDREN AND FAMILIES The RAND Corporation is a nonprofit institution that helps improve policy and EDUCATION AND THE ARTS decisionmaking through research and analysis. ENERGY AND ENVIRONMENT HEALTH AND HEALTH CARE This electronic document was made available from www.rand.org as a public INFRASTRUCTURE AND service of the RAND Corporation. TRANSPORTATION INTERNATIONAL AFFAIRS LAW AND BUSINESS NATIONAL SECURITY Skip all front matter: Jump to Page 16 POPULATION AND AGING PUBLIC SAFETY SCIENCE AND TECHNOLOGY Support RAND TERRORISM AND Browse Reports & Bookstore HOMELAND SECURITY Make a charitable contribution For More Information Visit RAND at www.rand.org Explore RAND Europe View document details Limited Electronic Distribution Rights This document and trademark(s) contained herein are protected by law as indicated in a notice appearing later in this work. This electronic representation of RAND intellectual property is provided for non-commercial use only. Unauthorized posting of RAND electronic documents to a non-RAND Web site is prohibited. RAND electronic documents are protected under copyright law. Permission is required from RAND to reproduce, or reuse in another form, any of our research documents for commercial use. For information on reprint and linking permissions, please see RAND Permissions. This report is part of the RAND Corporation research report series. RAND reports present research findings and objective analysis that address the challenges facing the public and private sectors. All RAND reports undergo rigorous peer review to ensure high standards for research quality and objectivity. EUROPE Analysis of research and education indicators to support designation of Academic Health Science Centres in England Salil Gunashekar, Petal Jean Hackett, Sophie Castle-Clarke, Ros Rouse, Jonathan Grant Prepared for the Department of Health (England) The research described in this document was prepared for the Department of Health (England). -
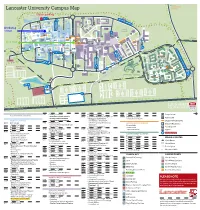
Lancaster University Campus Map CAMPUS
Forrest Hills SOUTH EAST Lancaster University Campus Map CAMPUS NORTH CAMPUSVisitor parking FURNESS AVE B TOWER AVE E C PHYSICS AVE ISO JOHN CREED AVE COUNTY AVE Bailrigg Service Station LANCASTER SQUARE AVE CTP GEORGE FOX AVE Maintenance UNDERPASS Workshops COM PHS WWB Workshop FYLDE AVE County College SOUTH CHE CAMPUS venue D ISS COS The PSC Orchard FAR Bonington Square Step Lancaster TRH Square FAS SBH GFX INF Physics Garden Cycle Route to NORTH DRIVE Fylde College Ellel & Galgate Great Edward SOUTH DRIVE Hall BLN BLM Roberts Court GHC Court Bowland Bowland FUR Wetland North Quad Fylde Grizedale College Bus stop Quad WEL Furness College Quad Furness Alexandra College Court FYL SAT LIC Square LEC Pendle College Great Hall Welcome CHC Square Centre Reception Engineering F Square Cycle Route to PENDLE AVE ASH Bowland College City Centre BLA Students’ Union ROSSENDALE AVE LIB ENG LSE BLH A Arrival UNH Point GRIZEDALE AVE University House MAN Reception BOWLAND AVE G Graduate College HRB UNDERPASS CPC BOWLAND AVE FARRER AVE GILLOW AVE Graduate BRH LIBRARY AVE SEC Square A GRADUATE AVE LCC CARTMEL AVE Netball Courts South West I Campus ALEXANDRA PARK DRIVE Barker NORTH WEST RUS House BHF Entrance Lancaster Court House Hotel CAMPUS H Cartmel College Rugby League Pitch PARK BOULEVARD Lacrosse Pitch ECO BARKER HOUSE AVE MED J PRE Lonsdale SOUTH WEST CAMPUS Quad LONSDALE AVE HAZELRIGG LANE Lonsdale College BFB Lake Carter Grass Playing Pitch Astro Turf Pitch L Grass Playing Pitch L Grass Playing Pitch Grass Playing Pitch Grass Playing Pitch 3rd -

SEC/2016/2/1349 LANCASTER UNIVERSITY Estates Committee A
SEC/2016/2/1349 LANCASTER UNIVERSITY Estates Committee A meeting of the Committee was held on Friday 4 November 2016 at which the following persons were present: Mr Simon Reynolds (in the Chair) Vice-Chancellor Professor Andrew Atherton Mr Roderick Burgess Professor Amanda Chetwynd Professor John Garside Ms Rhiannon Jones Lord Roger Liddle Professor Ella Ritchie (via conference call) Ms Nicola Owen The following persons were in attendance: Mr Alistair Burg-Broquere Ms Claire Geddes Dr Hazel Hardie (Secretary) Mr Ian Jenkinson, CRBE (for item EST.16/35) Mrs Sarah Randall-Paley EST.16/30 Declaration of Interest There were no declarations of interest. EST.16/31 Minutes of the meeting held on 7 July 2016 Documents: SEC/2016/2/1317; SEC/2016/2/0931 The minutes of the meeting held on 7 July 2016 were confirmed as an accurate record. EST.16/32 Matters Arising There were no matters arising. EST.16/33 Committee Terms of Reference Document: SEC/2016/2/1318 The Committee reviewed its terms of reference and agreed to make minor amendments, which would be reported to the Council for approval. Action: Secretary EST.16/34 Lancaster University Campus Masterplan and 10 Year Capital Programme The Committee received a progress update on the Campus Masterplan, which was being refined to reflect the projected growth in student numbers across different departments. It was noted that the Masterplan would be brought to the January meeting, along with the 10 Year Capital Programme. EST.16/35 Residential Accommodation Strategy (Commercial in Confidence) Document: SEC/2016/2/1319 [MINUTE COMMERCIAL IN CONFIDENCE] EST.16/36 Health Innovation Campus Document: SEC/2016/2/1320 The Director of Estates provided an update on the development of the Health Innovation Campus project. -
Entry Requirements for UK Medical Schools
Entry requirements for UK medical schools 2021 entry “Around the UK there are students who would make brilliant doctors but who feel in the dark about what they need in order to apply. Some of these students may never have considered their talent for medicine, while others have had encouragement from family or teachers. “Medical schools want to find the best candidates and believe they can come from any background. With a resource like this, we hope that a major part of the process – admissions criteria – can become clearer for everyone.” Paul Garrud Honorary Associate Professor, University of Nottingham Chair, Medical Schools Council Selection Alliance Contents Click on a title to go to the page Welcome 6 Course types 7 Admissions tests 8 About Access courses 9 Understanding the course tables 10 Standard Entry Medicine University of Aberdeen 12 Anglia Ruskin University 13 Aston University 14 University of Birmingham 15 Brighton and Sussex Medical School 16 University of Bristol 17 University of Buckingham 18 University of Cambridge 19 Cardiff University 20 University of Dundee 21 Edge Hill University 22 University of East Anglia 23 University of Edinburgh 24 University of Exeter 25 University of Glasgow 26 Hull York Medical School 27 Imperial College London 28 Entry requirements for UK medical schools: 2021 entry www.medschools.ac.uk 2 Keele University 29 Kent and Medway Medical School 30 King’s College London 31 Lancaster University 32 University of Leeds 33 University of Leicester 34 Lincoln Medical School 35 University of Liverpool