Implementing a Container-Based Build Environment: a Case Study
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Version Control Systems, Build Automation and Continuous Integration Integration and Verification Techniques
Version Control Systems, Build Automation and Continuous Integration Integration and Verification Techniques Systematic methods and automation can highly enhance the teamwork on software projects. During this laboratory we will learn the basics of the following techniques: • Version control systems to support efficient teamwork. • Build automation to ensure stable and consistent builds. • Continuous Integration to provide automatic and systematic build, test execution and also deployments. 1 Version Control Systems Version control systems allow to keep all the historical versions of your software for easy tracking. Using version control also benefits team collaboration and improves the efficiency of the development team. In addition, it can be used as a central repository for the data, making build automation and continuous integration possible. There are historically two different approaches for managing the repositories: • Centralized model (CVS and Subversion/SVN): there is one server that contains “the repository” and everyone else checks code into and out of that repository. An important feature of these systems is that only the repository has the full history of all changes made. A checkout from this central repository will place a “working copy” on the user’s machine. This is a snapshot from a certain version of the project on his/her disk. • Distributed model (Git): In a distributed version control system, instead of a checkout, a user will clone a repository from a remote server. In return, he/she receives a full-fledged repository, not just a working copy. The user then has his/her own repository on the local machine – including all of the project’s history. -

Managing Projects with GNU Make, Third Edition by Robert Mecklenburg
ManagingProjects with GNU Make Other resources from O’Reilly Related titles Unix in a Nutshell sed and awk Unix Power Tools lex and yacc Essential CVS Learning the bash Shell Version Control with Subversion oreilly.com oreilly.com is more than a complete catalog of O’Reilly books. You’ll also find links to news, events, articles, weblogs, sample chapters, and code examples. oreillynet.com is the essential portal for developers interested in open and emerging technologies, including new platforms, pro- gramming languages, and operating systems. Conferences O’Reilly brings diverse innovators together to nurture the ideas that spark revolutionary industries. We specialize in document- ing the latest tools and systems, translating the innovator’s knowledge into useful skills for those in the trenches. Visit con- ferences.oreilly.com for our upcoming events. Safari Bookshelf (safari.oreilly.com) is the premier online refer- ence library for programmers and IT professionals. Conduct searches across more than 1,000 books. Subscribers can zero in on answers to time-critical questions in a matter of seconds. Read the books on your Bookshelf from cover to cover or sim- ply flip to the page you need. Try it today with a free trial. THIRD EDITION ManagingProjects with GNU Make Robert Mecklenburg Beijing • Cambridge • Farnham • Köln • Sebastopol • Tokyo Managing Projects with GNU Make, Third Edition by Robert Mecklenburg Copyright © 2005, 1991, 1986 O’Reilly Media, Inc. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. -

Red Hat Enterprise Linux 6 Developer Guide
Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Dave Brolley William Cohen Roland Grunberg Aldy Hernandez Karsten Hopp Jakub Jelinek Developer Guide Jeff Johnston Benjamin Kosnik Aleksander Kurtakov Chris Moller Phil Muldoon Andrew Overholt Charley Wang Kent Sebastian Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Edition 0 Author Dave Brolley [email protected] Author William Cohen [email protected] Author Roland Grunberg [email protected] Author Aldy Hernandez [email protected] Author Karsten Hopp [email protected] Author Jakub Jelinek [email protected] Author Jeff Johnston [email protected] Author Benjamin Kosnik [email protected] Author Aleksander Kurtakov [email protected] Author Chris Moller [email protected] Author Phil Muldoon [email protected] Author Andrew Overholt [email protected] Author Charley Wang [email protected] Author Kent Sebastian [email protected] Editor Don Domingo [email protected] Editor Jacquelynn East [email protected] Copyright © 2010 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. -

Devops Point of View an Enterprise Architecture Perspective
DevOps Point of View An Enterprise Architecture perspective Amsterdam, 2020 Management summary “It is not the strongest of the species that survive, nor the most intelligent, but the one most responsive to change.”1 Setting the scene Goal of this Point of View In the current world of IT and the development of This point of view aims to create awareness around the IT-related products or services, companies from transformation towards the DevOps way of working, to enterprise level to smaller sizes are starting to help gain understanding what DevOps is, why you need it use the DevOps processes and methods as a part and what is needed to implement DevOps. of their day-to-day organization process. The goal is to reduce the time involved in all the An Enterprise Architecture perspective software development phases, to achieve greater Even though it is DevOps from an Enterprise Architecture application stability and faster development service line perspective, this material has been gathered cycles. from our experiences with customers, combined with However not only on the technical side of the knowledge from subject matter experts and theory from organization is DevOps changing the playing within and outside Deloitte. field, also an organizational change that involves merging development and operations teams is Targeted audience required with an hint of cultural changes. And last but not least the skillset of all people It is specifically for the people within Deloitte that want to involved is changing. use this as an accelerator for conversations and proposals & to get in contact with the people who have performed these type of projects. -

Coverity Static Analysis
Coverity Static Analysis Quickly find and fix Overview critical security and Coverity® gives you the speed, ease of use, accuracy, industry standards compliance, and quality issues as you scalability that you need to develop high-quality, secure applications. Coverity identifies code critical software quality defects and security vulnerabilities in code as it’s written, early in the development process when it’s least costly and easiest to fix. Precise actionable remediation advice and context-specific eLearning help your developers understand how to fix their prioritized issues quickly, without having to become security experts. Coverity Benefits seamlessly integrates automated security testing into your CI/CD pipelines and supports your existing development tools and workflows. Choose where and how to do your • Get improved visibility into development: on-premises or in the cloud with the Polaris Software Integrity Platform™ security risk. Cross-product (SaaS), a highly scalable, cloud-based application security platform. Coverity supports 22 reporting provides a holistic, more languages and over 70 frameworks and templates. complete view of a project’s risk using best-in-class AppSec tools. Coverity includes Rapid Scan, a fast, lightweight static analysis engine optimized • Deployment flexibility. You for cloud-native applications and Infrastructure-as-Code (IaC). Rapid Scan runs decide which set of projects to do automatically, without additional configuration, with every Coverity scan and can also AppSec testing for: on-premises be run as part of full CI builds with conventional scan completion times. Rapid Scan can or in the cloud. also be deployed as a standalone scan engine in Code Sight™ or via the command line • Shift security testing left. -

Kdesrc-Build Script Manual
kdesrc-build Script Manual Michael Pyne Carlos Woelz kdesrc-build Script Manual 2 Contents 1 Introduction 8 1.1 A brief introduction to kdesrc-build . .8 1.1.1 What is kdesrc-build? . .8 1.1.2 kdesrc-build operation ‘in a nutshell’ . .8 1.2 Documentation Overview . .9 2 Getting Started 10 2.1 Preparing the System to Build KDE . 10 2.1.1 Setup a new user account . 10 2.1.2 Ensure your system is ready to build KDE software . 10 2.1.3 Setup kdesrc-build . 12 2.1.3.1 Install kdesrc-build . 12 2.1.3.2 Prepare the configuration file . 12 2.1.3.2.1 Manual setup of configuration file . 12 2.2 Setting the Configuration Data . 13 2.3 Using the kdesrc-build script . 14 2.3.1 Loading project metadata . 14 2.3.2 Previewing what will happen when kdesrc-build runs . 14 2.3.3 Resolving build failures . 15 2.4 Building specific modules . 16 2.5 Setting the Environment to Run Your KDEPlasma Desktop . 17 2.5.1 Automatically installing a login driver . 18 2.5.1.1 Adding xsession support for distributions . 18 2.5.1.2 Manually adding support for xsession . 18 2.5.2 Setting up the environment manually . 19 2.6 Module Organization and selection . 19 2.6.1 KDE Software Organization . 19 2.6.2 Selecting modules to build . 19 2.6.3 Module Sets . 20 2.6.3.1 The basic module set concept . 20 2.6.3.2 Special Support for KDE module sets . -

Installing the Klocwork Server Package
Installation and Upgrade Klocwork Insight 10.0 SR6 Document version 1.6 Klocwork Installation and Upgrade Version 10.0 PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Tue, 12 Aug 2014 15:19:51 EST Contents Articles Before you install 1 System requirements 1 Release Notes 11 About the Klocwork packages and components 24 Upgrading from a previous version 26 Upgrading from a previous version 26 Import your existing projects into a new projects root 27 Migrate your projects root directory 31 Installing the Klocwork Server package on Windows -- Upgrade only 36 Installing the Klocwork Server package on Unix -- Upgrade only 37 Installing the Klocwork Server package on Mac -- Upgrade only 40 Get a license 42 Getting a license 42 Installing the Server package 45 Installing Klocwork Insight 45 Installing the Klocwork Server package on Windows 46 Installing the Klocwork Server package on Unix 49 Installing the Klocwork Server package on Mac 52 Viewing and changing Klocwork server settings 54 Downloading and deploying the desktop analysis plug-ins 56 kwupdate 57 Installing a desktop analysis plug-in or command line utility 59 Installing a desktop analysis plug-in 59 Installing the Klocwork plug-in from the Eclipse update site 62 Running a custom installation for new or upgraded IDEs 63 Installing the Distributed Analysis package 64 Installing the Distributed Analysis package 64 Configuring and starting the Klocwork servers 67 Viewing and changing Klocwork server settings 67 -
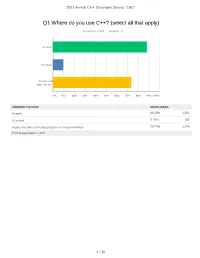
Q1 Where Do You Use C++? (Select All That Apply)
2021 Annual C++ Developer Survey "Lite" Q1 Where do you use C++? (select all that apply) Answered: 1,870 Skipped: 3 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 88.29% 1,651 At school 9.79% 183 In personal time, for hobby projects or to try new things 73.74% 1,379 Total Respondents: 1,870 1 / 35 2021 Annual C++ Developer Survey "Lite" Q2 How many years of programming experience do you have in C++ specifically? Answered: 1,869 Skipped: 4 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 7.60% 142 3-5 years 20.60% 385 6-10 years 20.71% 387 10-20 years 30.02% 561 >20 years 21.08% 394 TOTAL 1,869 2 / 35 2021 Annual C++ Developer Survey "Lite" Q3 How many years of programming experience do you have overall (all languages)? Answered: 1,865 Skipped: 8 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 1.02% 19 3-5 years 12.17% 227 6-10 years 22.68% 423 10-20 years 29.71% 554 >20 years 34.42% 642 TOTAL 1,865 3 / 35 2021 Annual C++ Developer Survey "Lite" Q4 What types of projects do you work on? (select all that apply) Answered: 1,861 Skipped: 12 Gaming (e.g., console and.. -

Security Automation Best Practices
SECURITY AUTOMATION BEST PRACTICES A Guide to Making Your Security Team Successful with Automation TABLE OF CONTENTS Introduction 3 What Is Security Automation? 3 Security Automation: A Tough Nut to Crack 4 Prepare Your Security Organization for Success 6 Make a Choice: Build or buy? 8 Add Automation When the Time Is Right 10 Know Which Tasks Are Ideal for Automation 12 Testing Automation’s Capabilities 14 Implementing Security Automation 15 About Rapid7 16 Appendix 17 | Rapid7.com Security Automation Best Practices - 2 INTRODUCTION The best security postures are those that are built on efficiency and time-to-response. While processes make it possible to get a job done faster, creating ones that solve practical problems and result in measurable efficiency gains can be a time-consuming task, and without the expertise required to create and build them, they simply don’t get done. This is where security automation comes in. WHAT IS SECURITY AUTOMATION? Security automation streamlines a series of repetitive, manual tasks into cohesive and automated workflows. By plugging a set of tasks into an automated system (such as those involved in phishing investigations), security processes become: • More efficient • Less prone to human error With increased efficiency, better and faster decisions can be made, which in turn can improve your organization’s entire security posture. Even better, with repetitive and manual tasks taken care of by automation, security personnel can instead focus on more strategic work, which boosts their job satisfaction and ensures you’re retaining good talent. | Rapid7.com Security Automation Best Practices - 3 SECURITY AUTOMATION: A TOUGH NUT TO CRACK Historically, security automation has been difficult to implement, which is why many companies have yet to take advantage of it. -

How to Get the Most out of Your Ci/Cd Workflow Using Automated Testing
WHITE PAPER HOW TO GET THE MOST OUT OF YOUR CI/CD WORKFLOW USING AUTOMATED TESTING This paper is aimed at Test and QA Executives as well as Project Managers who are considering adopting automated testing, but are unsure of how to get started. It highlights the benefits of automated testing, the recommended technical approach to take, and suggests tools that enable teams to successfully adopt automated testing as part of a healthy continuous integration and delivery process. It also examines which tests to automate and which to continue to do manually. TABLE OF CONTENTS 3 Executive Summary 10 Mobile Testing 3 Automated Testing as Part of the Broader 11 Which Tests to Continue Manually CI/CD Pipeline 11 Usability Tests 4 The Kubernetes Effect 12 One-off Tests 5 GitOps = Fully-automated CI/CD 12 Selecting the Right Test Automation Solution 5 Reality Check - The Majority of Testing is 12 The Crucial Decision - In-house, Open Still Manual Source, or Commercial 6 What is Test Automation? 13 Selenium - The Leading Test Automation Tool 7 Manual Testing vs Automated Testing - for Web Apps Weighing the Benefits 13 Appium - The Leading Test Automation Tool 7 Obstacles to Adopting Automated Testing for Mobile Apps 8 The Right Approach to Test Automation 14 Open Source Tools Require Expertise to Run In-House 9 Unit and Component Testing 14 The Ideal Solution Should Combine the Best of 9 Headless Testing Both Worlds - Selenium & Appium 9 API or Web Services Testing 15 Conclusion 9 UI Testing 15 About Sauce Labs 10 Regression Testing 15 Appendix 10 Functional Testing EXECUTIVE SUMMARY In today’s hyper-competitive cloud economy, it’s important to be first to market to gain a competitive edge. -

Continuous Integration (CI) Needs and Wishes for Developers of Proprietary Code
Continuous Integration (CI) Needs and Wishes for Developers of Proprietary Code Michael Hilton, Nicholas Nelson, Danny Dig Timothy Tunnell, Darko Marinov School of EECS, Oregon State University CS Department, University of Illinois {hiltonm,nelsonni,digd}@oregonstate.edu {tunnell2,marinov}@illinois.edu Abstract—Continuous integration (CI) systems automate the Open-source projects are often considered fundamentally dif- compilation, building, and testing of software. Despite CI being ferent from proprietary-code projects [6]. Differences between one of the most widely used processes in software engineering, open-source and proprietary-code projects include that open- we do not know what motivates developers to use CI, and what barriers and unmet needs they face. Without such knowledge source projects foster more creativity [7], have fewer defects [7], developers make easily avoidable errors, managers reduce the and assign work differently [8]. However, similarities have also productivity of developers by making misinformed decisions, tool been found, including how GitHub is used [9], overall project builders invest in the wrong direction, and researchers miss many complexity [7], and amount of modularity [7]. opportunities for improving the software engineering practice. There are still many gaps in our knowledge about why Given the large fraction of proprietary code development, un- derstanding how proprietary developers are using CI is vital to developers use CI, and what barriers they face, especially for improving it. projects of proprietary code. What motivates developers to use We present the first study of how CI is used in the proprietary CI? What are the barriers that developers face when using development of software. We conduct 16 semi-structured inter- CI? What needs do developers have that are unmet by their views with developers from different industries and development current CI system(s)? Do proprietary developers have the same scale. -
Network Vulnerability Scan with Openvas Report
Network Vulnerability Scan with OpenVAS Report 10.8.0.1 (Metasploitable2) Summary Overall risk level: High Risk ratings: High: 13 Medium: 20 Low: 69 Info: 1 Scan information: Start time: 2018-03-02 11:24:54 Finish time: 2018-03-02 12:02:48 Scan duration: 37 min, 54 sec Tests performed: 103/103 Scan status: Finished Findings Check for rexecd Service (port 512/tcp) The rexecd Service is not allowing connections from this host. Details Risk description: Rexecd Service is running at this Host. Rexecd (Remote Process Execution) has the same kind of functionality that rsh has : you can execute shell commands on a remote computer. The main difference is that rexecd authenticate by reading the username and password *unencrypted* from the socket. Recommendation: Disable rexec Service. Read more about this issue: https//web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-1999-0618 Check for rlogin Service (port 513/tcp) The service is misconfigured so it is allowing conntections without a password. Details Risk description: rlogin has several serious security problems, - All information, including passwords, is transmitted unencrypted. - .rlogin (or .rhosts) file is easy to misuse (potentially allowing anyone to login without a password) Impact Level: System This remote host is running a rlogin service. Recommendation: Disable rlogin service and use ssh instead. Read more about this issue: https//web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-1999-0651 https//web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-1999-0651 http//en.wikipedia.org/wiki/Rlogin http//www.ietf.org/rfc/rfc1282.txt DistCC Detection (port 3632/tcp) No evidence Details Risk description: DistCC is a program to distribute builds of C, C++, Objective C or Objective C++ code across several machines on a network.