Managing Projects with GNU Make, Third Edition by Robert Mecklenburg
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Red Hat Enterprise Linux 6 Developer Guide
Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Dave Brolley William Cohen Roland Grunberg Aldy Hernandez Karsten Hopp Jakub Jelinek Developer Guide Jeff Johnston Benjamin Kosnik Aleksander Kurtakov Chris Moller Phil Muldoon Andrew Overholt Charley Wang Kent Sebastian Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Edition 0 Author Dave Brolley [email protected] Author William Cohen [email protected] Author Roland Grunberg [email protected] Author Aldy Hernandez [email protected] Author Karsten Hopp [email protected] Author Jakub Jelinek [email protected] Author Jeff Johnston [email protected] Author Benjamin Kosnik [email protected] Author Aleksander Kurtakov [email protected] Author Chris Moller [email protected] Author Phil Muldoon [email protected] Author Andrew Overholt [email protected] Author Charley Wang [email protected] Author Kent Sebastian [email protected] Editor Don Domingo [email protected] Editor Jacquelynn East [email protected] Copyright © 2010 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. -

Functional C
Functional C Pieter Hartel Henk Muller January 3, 1999 i Functional C Pieter Hartel Henk Muller University of Southampton University of Bristol Revision: 6.7 ii To Marijke Pieter To my family and other sources of inspiration Henk Revision: 6.7 c 1995,1996 Pieter Hartel & Henk Muller, all rights reserved. Preface The Computer Science Departments of many universities teach a functional lan- guage as the first programming language. Using a functional language with its high level of abstraction helps to emphasize the principles of programming. Func- tional programming is only one of the paradigms with which a student should be acquainted. Imperative, Concurrent, Object-Oriented, and Logic programming are also important. Depending on the problem to be solved, one of the paradigms will be chosen as the most natural paradigm for that problem. This book is the course material to teach a second paradigm: imperative pro- gramming, using C as the programming language. The book has been written so that it builds on the knowledge that the students have acquired during their first course on functional programming, using SML. The prerequisite of this book is that the principles of programming are already understood; this book does not specifically aim to teach `problem solving' or `programming'. This book aims to: ¡ Familiarise the reader with imperative programming as another way of imple- menting programs. The aim is to preserve the programming style, that is, the programmer thinks functionally while implementing an imperative pro- gram. ¡ Provide understanding of the differences between functional and imperative pro- gramming. Functional programming is a high level activity. -

X Window System Version 6.4.2 Release Notes
X Window System Version 6.4.2 Release Notes October 2000 0890298-6.4.2 READREAD MEME BEFOREBEFORE INSTALLINGINSTALLING THISTHIS PRODUCTPRODUCT Copyright Copyright 2000 by Concurrent Computer Corporation. All rights reserved. This publication or any part thereof is intended for use with Concurrent Computer Corporation products by Concurrent Computer Corporation personnel, customers, and end–users. It may not be reproduced in any form without the written permission of the publisher. Disclaimer The information contained in this document is subject to change without notice. Concurrent Computer Corporation has taken efforts to remove errors from this document, however, Concurrent Computer Corporation’s only liability regarding errors that may still exist is to correct said errors upon their being made known to Concurrent Computer Corporation. Concurrent Computer Corporation assumes no responsibility for the use or reliability of software if used on equipment that is not supplied by Concurrent Computer Corporation. License The software described in this document is furnished under a license, and it can be used or copied only in a manner permitted by that license. Any copy of the described software must include any copyright notice, trademarks or other legends or credits of Concurrent Computer Corporation and/or its suppliers. Title to and ownership of the described software and any copies thereof shall remain in Concurrent Computer Corporation and/or its suppliers. The licensed software described herein may contain certain encryptions or other devices which may prevent or detect unauthorized use of the Licensed Software. Temporary use permitted by the terms of the License Agreement may require assistance from Concurrent Computer Corporation. -

Kdesrc-Build Script Manual
kdesrc-build Script Manual Michael Pyne Carlos Woelz kdesrc-build Script Manual 2 Contents 1 Introduction 8 1.1 A brief introduction to kdesrc-build . .8 1.1.1 What is kdesrc-build? . .8 1.1.2 kdesrc-build operation ‘in a nutshell’ . .8 1.2 Documentation Overview . .9 2 Getting Started 10 2.1 Preparing the System to Build KDE . 10 2.1.1 Setup a new user account . 10 2.1.2 Ensure your system is ready to build KDE software . 10 2.1.3 Setup kdesrc-build . 12 2.1.3.1 Install kdesrc-build . 12 2.1.3.2 Prepare the configuration file . 12 2.1.3.2.1 Manual setup of configuration file . 12 2.2 Setting the Configuration Data . 13 2.3 Using the kdesrc-build script . 14 2.3.1 Loading project metadata . 14 2.3.2 Previewing what will happen when kdesrc-build runs . 14 2.3.3 Resolving build failures . 15 2.4 Building specific modules . 16 2.5 Setting the Environment to Run Your KDEPlasma Desktop . 17 2.5.1 Automatically installing a login driver . 18 2.5.1.1 Adding xsession support for distributions . 18 2.5.1.2 Manually adding support for xsession . 18 2.5.2 Setting up the environment manually . 19 2.6 Module Organization and selection . 19 2.6.1 KDE Software Organization . 19 2.6.2 Selecting modules to build . 19 2.6.3 Module Sets . 20 2.6.3.1 The basic module set concept . 20 2.6.3.2 Special Support for KDE module sets . -

Installing the Klocwork Server Package
Installation and Upgrade Klocwork Insight 10.0 SR6 Document version 1.6 Klocwork Installation and Upgrade Version 10.0 PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Tue, 12 Aug 2014 15:19:51 EST Contents Articles Before you install 1 System requirements 1 Release Notes 11 About the Klocwork packages and components 24 Upgrading from a previous version 26 Upgrading from a previous version 26 Import your existing projects into a new projects root 27 Migrate your projects root directory 31 Installing the Klocwork Server package on Windows -- Upgrade only 36 Installing the Klocwork Server package on Unix -- Upgrade only 37 Installing the Klocwork Server package on Mac -- Upgrade only 40 Get a license 42 Getting a license 42 Installing the Server package 45 Installing Klocwork Insight 45 Installing the Klocwork Server package on Windows 46 Installing the Klocwork Server package on Unix 49 Installing the Klocwork Server package on Mac 52 Viewing and changing Klocwork server settings 54 Downloading and deploying the desktop analysis plug-ins 56 kwupdate 57 Installing a desktop analysis plug-in or command line utility 59 Installing a desktop analysis plug-in 59 Installing the Klocwork plug-in from the Eclipse update site 62 Running a custom installation for new or upgraded IDEs 63 Installing the Distributed Analysis package 64 Installing the Distributed Analysis package 64 Configuring and starting the Klocwork servers 67 Viewing and changing Klocwork server settings 67 -
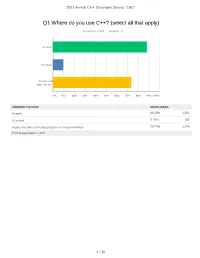
Q1 Where Do You Use C++? (Select All That Apply)
2021 Annual C++ Developer Survey "Lite" Q1 Where do you use C++? (select all that apply) Answered: 1,870 Skipped: 3 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 88.29% 1,651 At school 9.79% 183 In personal time, for hobby projects or to try new things 73.74% 1,379 Total Respondents: 1,870 1 / 35 2021 Annual C++ Developer Survey "Lite" Q2 How many years of programming experience do you have in C++ specifically? Answered: 1,869 Skipped: 4 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 7.60% 142 3-5 years 20.60% 385 6-10 years 20.71% 387 10-20 years 30.02% 561 >20 years 21.08% 394 TOTAL 1,869 2 / 35 2021 Annual C++ Developer Survey "Lite" Q3 How many years of programming experience do you have overall (all languages)? Answered: 1,865 Skipped: 8 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 1.02% 19 3-5 years 12.17% 227 6-10 years 22.68% 423 10-20 years 29.71% 554 >20 years 34.42% 642 TOTAL 1,865 3 / 35 2021 Annual C++ Developer Survey "Lite" Q4 What types of projects do you work on? (select all that apply) Answered: 1,861 Skipped: 12 Gaming (e.g., console and.. -

Linux on IBM Zseries and S/390: Application Development
Front cover Linux on IBM zSeries and S/390: Application Development Tools and techniques for Linux application development Using the Eclipse IDE and Jakarta Project tools Sample code to illustrate programming techniques Gregory Geiselhart Andrea Grahn Frans Handoko Jörg Hundertmark Albert Krzymowski Eliuth Pomar ibm.com/redbooks International Technical Support Organization Linux on IBM ^ zSeries and S/390: Application Development July 2002 SG24-6807-00 Note: Before using this information and the product it supports, read the information in “Notices” on page xiii. First Edition (July 2002) This edition applies to zVM 4.2 (ESP) and many different Linux distributions. SuSE Linux Enterprise Server 7.0 was used. © Copyright International Business Machines Corporation 2002. All rights reserved. Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Notices . xiii Trademarks . xiv Preface . xv The team that wrote this redbook. xvi Become a published author . xvii Comments welcome. xvii Part 1. Programming tools . 1 Chapter 1. The basic tools you need. 3 1.1 Where you can look for information. 4 1.1.1 Man pages . 4 1.1.2 Info - the help system . 5 1.2 Compiling C/C++ source code . 6 1.2.1 Starting gcc . 6 1.2.2 Source files . 6 1.2.3 Directory search . 7 1.2.4 Compilation stages . 7 1.2.5 Macros . 8 1.2.6 Warnings . 8 1.2.7 Extra information for debuggers . 8 1.2.8 Code optimization . 9 1.2.9 Configuring gcc as a cross-compiler . -

Building the Package
5 Building the package Nowwehav e configured our package and we’re ready to build. This is the Big Moment: at the end of the build process we should have a complete, functioning software product in our source tree. In this chapter,we’ll look at the surprises that make can have instore for you. Youcan find the corresponding theoretical material in Chapter 19, Make. Preparation If you’re unlucky, a port can go seriously wrong. The first time that error messages appear thick and fast and scroll offthe screen before you can read them, you could get the impression that the packages were built this way deliberately to annoyyou. Alittle bit of preparation can go a long way towards keeping you in control of what’sgoing on. Here are some suggestions: Makesure you have enough space One of the most frequent reasons of failure of a build is that the file system fills up. If possi- ble, ensure that you have enough space before you start. The trouble is, howmuch is enough? Hardly anypackage will tell you howmuch space you need, and if it does it will probably be wrong, since the size depends greatly on the platform. If you are short on space, consider compiling without debugging symbols (which takeupalot of space). If you do run out of space in the middle of a build, you might be able to save the day by stripping the objects with strip,inother words removing the symbols from the file. Use a windowing system The sheer size of a complicated port can be a problem. -
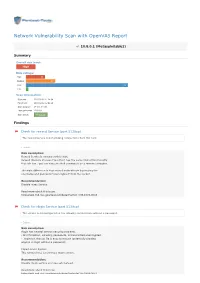
Network Vulnerability Scan with Openvas Report
Network Vulnerability Scan with OpenVAS Report 10.8.0.1 (Metasploitable2) Summary Overall risk level: High Risk ratings: High: 13 Medium: 20 Low: 69 Info: 1 Scan information: Start time: 2018-03-02 11:24:54 Finish time: 2018-03-02 12:02:48 Scan duration: 37 min, 54 sec Tests performed: 103/103 Scan status: Finished Findings Check for rexecd Service (port 512/tcp) The rexecd Service is not allowing connections from this host. Details Risk description: Rexecd Service is running at this Host. Rexecd (Remote Process Execution) has the same kind of functionality that rsh has : you can execute shell commands on a remote computer. The main difference is that rexecd authenticate by reading the username and password *unencrypted* from the socket. Recommendation: Disable rexec Service. Read more about this issue: https//web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-1999-0618 Check for rlogin Service (port 513/tcp) The service is misconfigured so it is allowing conntections without a password. Details Risk description: rlogin has several serious security problems, - All information, including passwords, is transmitted unencrypted. - .rlogin (or .rhosts) file is easy to misuse (potentially allowing anyone to login without a password) Impact Level: System This remote host is running a rlogin service. Recommendation: Disable rlogin service and use ssh instead. Read more about this issue: https//web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-1999-0651 https//web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-1999-0651 http//en.wikipedia.org/wiki/Rlogin http//www.ietf.org/rfc/rfc1282.txt DistCC Detection (port 3632/tcp) No evidence Details Risk description: DistCC is a program to distribute builds of C, C++, Objective C or Objective C++ code across several machines on a network. -

XL C/C++ Compiler and Runtime Migration Guide for the Application Programmer
z/OS Version 2 Release 3 XL C/C++ Compiler and Runtime Migration Guide for the Application Programmer IBM GC14-7306-30 Note Before using this information and the product it supports, read the information in “Notices” on page 129. This edition applies to Version 2 Release 3 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2019-02-15 © Copyright International Business Machines Corporation 1996, 2017. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document.............................................................................................xi z/OS XL C/C++ on the World Wide Web.................................................................................................... xix Where to find more information...........................................................................................................xix Technical support...................................................................................................................................... xix How to send your comments to IBM.........................................................................................................xix If you have a technical problem........................................................................................................... xx Part 1. Introduction.............................................................................................. -

Accelerating Personal Computations with Htcondor: Generating Large Numbers of Events with Genie
Proceedings of the 27th International Symposium Nuclear Electronics and Computing (NEC’2019) Budva, Becici, Montenegro, September 30 – October 4, 2019 ACCELERATING PERSONAL COMPUTATIONS WITH HTCONDOR: GENERATING LARGE NUMBERS OF EVENTS WITH GENIE N. Balashov1,a , I. Kakorin2, V. Naumov2 1 Laboratory of Information Technologies, Joint Institute for Nuclear Research, 6 Jolio-Curie st., Dubna, 141980, Russia 2 Bogoliubov Laboratory of Theoretical Physics, Joint Institute for Nuclear Research, 6 Jolio-Curie st., Dubna, 141980, Russia E-mail: a [email protected] GENIE is one of the most popular MC neutrino event generators, widely used in many modern neutrino experiments (e.g. NOvA, MINERvA, MicroBooNE, KM3NeT, IceCube). The tasks related to the development and optimization of the generator itself require creating a large number of events in the shortest possible time in order to reduce the overall development time. The usage of large-scale distributed computing infrastructures, such as Grid, does not guarantee the minimal execution time due to possibly long queue times. At the same time, the power of a modern PC is not capable of performing such computations in a reasonable amount of time. In this work we give an example of a hybrid approach: accelerating computations by using a personal computing device in conjunction with a general-purpose batch system based on HTCondor. Keywords: distributed computing, HTCondor, GENIE Nikita Balashov, Igor Kakorin, Vadim Naumov Copyright © 2019 for this paper by its authors. Use permitted under Creative Commons License Attribution 4.0 International (CC BY 4.0). 135 Proceedings of the 27th International Symposium Nuclear Electronics and Computing (NEC’2019) Budva, Becici, Montenegro, September 30 – October 4, 2019 1. -

Solaris X Window System Reference Manual
Solaris X Window System Reference Manual Sun Microsystems, Inc. 2550 Garcia Avenue Mountain View, CA 94043 U.S.A. 1995 Sun Microsystems, Inc., 2550 Garcia Avenue, Mountain View, California 94043-1100 USA. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Portions of this product may be derived from the UNIX system, licensed from UNIX System Laboratories, Inc., a wholly owned subsidiary of Novell, Inc., and from the Berkeley 4.3 BSD system, licensed from the University of California. Third- party software, including font technology in this product, is protected by copyright and licensed from Sun's Suppliers. RESTRICTED RIGHTS LEGEND: Use, duplication, or disclosure by the government is subject to restrictions as set forth in subparagraph (c)(1)(ii) of the Rights in Technical Data and Computer Software clause at DFARS 252.227-7013 and FAR 52.227-19. The product described in this manual may be protected by one or more U.S. patents, foreign patents, or pending applications. TRADEMARKS Sun, Sun Microsystems, the Sun logo, SunSoft, the SunSoft logo, Solaris, SunOS, OpenWindows, DeskSet, ONC, ONC+, and NFS are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries. UNIX is a registered trademark in the United States and other countries, exclusively licensed through X/Open Company, Ltd. OPEN LOOK is a registered trademark of Novell, Inc.