Fast Distributed Compilation and Testing of Large C++ Projects
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Managing Projects with GNU Make, Third Edition by Robert Mecklenburg
ManagingProjects with GNU Make Other resources from O’Reilly Related titles Unix in a Nutshell sed and awk Unix Power Tools lex and yacc Essential CVS Learning the bash Shell Version Control with Subversion oreilly.com oreilly.com is more than a complete catalog of O’Reilly books. You’ll also find links to news, events, articles, weblogs, sample chapters, and code examples. oreillynet.com is the essential portal for developers interested in open and emerging technologies, including new platforms, pro- gramming languages, and operating systems. Conferences O’Reilly brings diverse innovators together to nurture the ideas that spark revolutionary industries. We specialize in document- ing the latest tools and systems, translating the innovator’s knowledge into useful skills for those in the trenches. Visit con- ferences.oreilly.com for our upcoming events. Safari Bookshelf (safari.oreilly.com) is the premier online refer- ence library for programmers and IT professionals. Conduct searches across more than 1,000 books. Subscribers can zero in on answers to time-critical questions in a matter of seconds. Read the books on your Bookshelf from cover to cover or sim- ply flip to the page you need. Try it today with a free trial. THIRD EDITION ManagingProjects with GNU Make Robert Mecklenburg Beijing • Cambridge • Farnham • Köln • Sebastopol • Tokyo Managing Projects with GNU Make, Third Edition by Robert Mecklenburg Copyright © 2005, 1991, 1986 O’Reilly Media, Inc. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. -

Red Hat Enterprise Linux 6 Developer Guide
Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Dave Brolley William Cohen Roland Grunberg Aldy Hernandez Karsten Hopp Jakub Jelinek Developer Guide Jeff Johnston Benjamin Kosnik Aleksander Kurtakov Chris Moller Phil Muldoon Andrew Overholt Charley Wang Kent Sebastian Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Edition 0 Author Dave Brolley [email protected] Author William Cohen [email protected] Author Roland Grunberg [email protected] Author Aldy Hernandez [email protected] Author Karsten Hopp [email protected] Author Jakub Jelinek [email protected] Author Jeff Johnston [email protected] Author Benjamin Kosnik [email protected] Author Aleksander Kurtakov [email protected] Author Chris Moller [email protected] Author Phil Muldoon [email protected] Author Andrew Overholt [email protected] Author Charley Wang [email protected] Author Kent Sebastian [email protected] Editor Don Domingo [email protected] Editor Jacquelynn East [email protected] Copyright © 2010 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. -

Selenium Python Bindings Release 2
Selenium Python Bindings Release 2 Baiju Muthukadan Sep 03, 2021 Contents 1 Installation 3 1.1 Introduction...............................................3 1.2 Installing Python bindings for Selenium.................................3 1.3 Instructions for Windows users.....................................3 1.4 Installing from Git sources........................................4 1.5 Drivers..................................................4 1.6 Downloading Selenium server......................................4 2 Getting Started 7 2.1 Simple Usage...............................................7 2.2 Example Explained............................................7 2.3 Using Selenium to write tests......................................8 2.4 Walkthrough of the example.......................................9 2.5 Using Selenium with remote WebDriver................................. 10 3 Navigating 13 3.1 Interacting with the page......................................... 13 3.2 Filling in forms.............................................. 14 3.3 Drag and drop.............................................. 15 3.4 Moving between windows and frames.................................. 15 3.5 Popup dialogs.............................................. 16 3.6 Navigation: history and location..................................... 16 3.7 Cookies.................................................. 16 4 Locating Elements 17 4.1 Locating by Id.............................................. 18 4.2 Locating by Name............................................ 18 4.3 -

N $NUM GPUS Python Train.Py
Neural Network concurrency Tal Ben-Nun and Torsten Hoefler, Demystifying Parallel and Distributed Deep Learning: An In-Depth Concurrency Analysis, 2018, Data Parallelism vs Model Parallelism Hardware and Libraries ● It is not only a matter of computational power: ○ CPU (MKL-DNN) ○ GPU (cuDNN) ○ FGPA ○ TPU ● Input/Output matter ○ SSD ○ Parallel file system (if you run parallel algorithm) ● Communication and interconnection too, if you are running in distributed mode ○ MPI ○ gRPC +verbs (RDMA) ○ NCCL Install TensorFlow from Source [~]$ wget https://github.com/.../bazel-0.15.2-installer-linux-x86_64.sh [~]$ ./bazel-0.15.2-installer-linux-x86_64.sh --prefix=... [~]$ wget https://github.com/tensorflow/tensorflow/archive/v1.10.0.tar.gz ... [~]$ python3 -m venv $TF_INSTALL_DIR [~]$ source $TF_INSTALL_DIR/bin/activate [~]$ pip3 install numpy wheel [~]$ ./configure ... [~]$ bazel build --config=mkl/cuda \ //tensorflow/tools/pip_package:build_pip_package [~]$ bazel-bin/tensorflow/tools/pip_package/build_pip_package $WHEELREPO [~]$ pip3 install $WHEELREPO/$WHL --ignore-installed [~]$ pip3 install keras horovod ... Input pipeline If using accelerators like GPU, pipeline tha data load exploiting the CPU with the computation on GPU The tf.data API helps to build flexible and efficient input pipelines Optimizing for CPU ● Built from source with all of the instructions supported by the target CPU and the MKL-DNN option for Intel® CPU. ● Adjust thread pools ○ intra_op_parallelism_threads: Nodes that can use multiple threads to parallelize their execution -

Blau Mavi Blue
4 / 2014 Quartierzeitung für das Untere Kleinbasel Mahalle Gazetesi Aşağ Küçükbasel için www.mozaikzeitung.ch Novine za cˇetvrt donji Mali Bazel Blau Mavi Blue Bilder, Stimmungen, Töned i t Resimler, Farkli sessler, d i Tonlart visions, moods, sounds e ˇ ivotu. Bazelu pricˇa21 o svom Z Foto: Jum Soon Kim Spezial:Jedna Familija u malom HOLZKOMPETENZ BACK INT NACH MASS BAL NCNNCECE Ihre Wunschvorstellung. Unser ALEXANDER-TECHNIK Handwerk. Resultat: Möbel Christina Stahlberger und Holzkonstruktionen, die dipl. Lehrerin für Alexander-Technik SVLAT M_000278 Matthäusstrasse 7, 4057 Basel Sie ein Leben lang begleiten. +41 (0)77 411 99 89 Unsere Spezialgebiete sind [email protected] I www.back-into-balance.com Haus- und Zimmertüren, Schränke, Küchen und Bade- Ed. Borer AG · Schreinerei · Wiesenstrasse 10 · 4057 Basel zimmermöbel sowie Repara- T 061 631 11 15 · F 061 631 11 26 · [email protected] turen und Restaurationen. M_000236 M_000196 Stadtteilsekretariat Kleinbasel M_000028 Darf ich hier Für Fragen, Anliegen und Probleme betreffend: • Wohnlichkeit und Zusammenleben grillieren? • Mitwirkung der Quartierbevölkerung Öffnungszeiten: Mo, Di und Do, 15 – 18.30 h Klybeckstrasse 61, 4057 Basel Tel: 061 681 84 44, Email: [email protected] www.stadtteilsekretariatebasel.ch M_000024 Wir danken unserer Kundschaft Offenburgerstrasse 41, CH-4057 Basel 061 5 54 23 33 Täglich bis 22.00 Uhr geöffnet! Täglich frische Produkte und Bio-Produkte! 365 Tage im Jahr, auch zwischen Weihnacht und Neujahr offen! Lebensmittel- und Getränkemarkt Wir bieten stets beste Qualität und freuen uns auf Ihren Besuch. Gratis-Lieferdienst für ältere Menschen M_000280 Öffnungszeiten: Montag 11.00–22.00 Uhr Dienstag–Sonntag und Feiertage: 8.00–22.00 Uhr Feldbergstrasse 32, 4057 Basel, Telefon 061 693 00 55 M_000006 M_000049 LACHENMEIER.CH SCHREINEREI konstruiert. -

Installing and Running Tensorflow
Installing and Running Tensorflow DOWNLOAD AND INSTALLATION INSTRUCTIONS TensorFlow is now distributed under an Apache v2 open source license on GitHub. STEP 1. INSTALL NVIDIA CUDA To use TensorFlow with NVIDIA GPUs, the first step is to install the CUDA Toolkit. STEP 2. INSTALL NVIDIA CUDNN Once the CUDA Toolkit is installed, download cuDNN v5.1 Library for Linux (note that you will need to register for the Accelerated Computing Developer Program). Once downloaded, uncompress the files and copy them into the CUDA Toolkit directory (assumed here to be in /usr/local/cuda/): $ sudo tar -xvf cudnn-8.0-linux-x64-v5.1-rc.tgz -C /usr/local STEP 3. INSTALL AND UPGRADE PIP TensorFlow itself can be installed using the pip package manager. First, make sure that your system has pip installed and updated: $ sudo apt-get install python-pip python-dev $ pip install --upgrade pip STEP 4. INSTALL BAZEL To build TensorFlow from source, the Bazel build system must first be installed as follows. Full details are available here. $ sudo apt-get install software-properties-common swig $ sudo add-apt-repository ppa:webupd8team/java $ sudo apt-get update $ sudo apt-get install oracle-java8-installer $ echo "deb http://storage.googleapis.com/bazel-apt stable jdk1.8" | sudo tee /etc/apt/sources.list.d/bazel.list $ curl https://storage.googleapis.com/bazel-apt/doc/apt-key.pub.gpg | sudo apt-key add - $ sudo apt-get update $ sudo apt-get install bazel STEP 5. INSTALL TENSORFLOW To obtain the best performance with TensorFlow we recommend building it from source. First, clone the TensorFlow source code repository: $ git clone https://github.com/tensorflow/tensorflow $ cd tensorflow $ git reset --hard 70de76e Then run the configure script as follows: $ ./configure Please specify the location of python. -

Kdesrc-Build Script Manual
kdesrc-build Script Manual Michael Pyne Carlos Woelz kdesrc-build Script Manual 2 Contents 1 Introduction 8 1.1 A brief introduction to kdesrc-build . .8 1.1.1 What is kdesrc-build? . .8 1.1.2 kdesrc-build operation ‘in a nutshell’ . .8 1.2 Documentation Overview . .9 2 Getting Started 10 2.1 Preparing the System to Build KDE . 10 2.1.1 Setup a new user account . 10 2.1.2 Ensure your system is ready to build KDE software . 10 2.1.3 Setup kdesrc-build . 12 2.1.3.1 Install kdesrc-build . 12 2.1.3.2 Prepare the configuration file . 12 2.1.3.2.1 Manual setup of configuration file . 12 2.2 Setting the Configuration Data . 13 2.3 Using the kdesrc-build script . 14 2.3.1 Loading project metadata . 14 2.3.2 Previewing what will happen when kdesrc-build runs . 14 2.3.3 Resolving build failures . 15 2.4 Building specific modules . 16 2.5 Setting the Environment to Run Your KDEPlasma Desktop . 17 2.5.1 Automatically installing a login driver . 18 2.5.1.1 Adding xsession support for distributions . 18 2.5.1.2 Manually adding support for xsession . 18 2.5.2 Setting up the environment manually . 19 2.6 Module Organization and selection . 19 2.6.1 KDE Software Organization . 19 2.6.2 Selecting modules to build . 19 2.6.3 Module Sets . 20 2.6.3.1 The basic module set concept . 20 2.6.3.2 Special Support for KDE module sets . -

Installing the Klocwork Server Package
Installation and Upgrade Klocwork Insight 10.0 SR6 Document version 1.6 Klocwork Installation and Upgrade Version 10.0 PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Tue, 12 Aug 2014 15:19:51 EST Contents Articles Before you install 1 System requirements 1 Release Notes 11 About the Klocwork packages and components 24 Upgrading from a previous version 26 Upgrading from a previous version 26 Import your existing projects into a new projects root 27 Migrate your projects root directory 31 Installing the Klocwork Server package on Windows -- Upgrade only 36 Installing the Klocwork Server package on Unix -- Upgrade only 37 Installing the Klocwork Server package on Mac -- Upgrade only 40 Get a license 42 Getting a license 42 Installing the Server package 45 Installing Klocwork Insight 45 Installing the Klocwork Server package on Windows 46 Installing the Klocwork Server package on Unix 49 Installing the Klocwork Server package on Mac 52 Viewing and changing Klocwork server settings 54 Downloading and deploying the desktop analysis plug-ins 56 kwupdate 57 Installing a desktop analysis plug-in or command line utility 59 Installing a desktop analysis plug-in 59 Installing the Klocwork plug-in from the Eclipse update site 62 Running a custom installation for new or upgraded IDEs 63 Installing the Distributed Analysis package 64 Installing the Distributed Analysis package 64 Configuring and starting the Klocwork servers 67 Viewing and changing Klocwork server settings 67 -
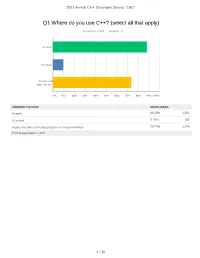
Q1 Where Do You Use C++? (Select All That Apply)
2021 Annual C++ Developer Survey "Lite" Q1 Where do you use C++? (select all that apply) Answered: 1,870 Skipped: 3 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 88.29% 1,651 At school 9.79% 183 In personal time, for hobby projects or to try new things 73.74% 1,379 Total Respondents: 1,870 1 / 35 2021 Annual C++ Developer Survey "Lite" Q2 How many years of programming experience do you have in C++ specifically? Answered: 1,869 Skipped: 4 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 7.60% 142 3-5 years 20.60% 385 6-10 years 20.71% 387 10-20 years 30.02% 561 >20 years 21.08% 394 TOTAL 1,869 2 / 35 2021 Annual C++ Developer Survey "Lite" Q3 How many years of programming experience do you have overall (all languages)? Answered: 1,865 Skipped: 8 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 1.02% 19 3-5 years 12.17% 227 6-10 years 22.68% 423 10-20 years 29.71% 554 >20 years 34.42% 642 TOTAL 1,865 3 / 35 2021 Annual C++ Developer Survey "Lite" Q4 What types of projects do you work on? (select all that apply) Answered: 1,861 Skipped: 12 Gaming (e.g., console and.. -

Your Build in a Datacenter Remote Caching and Execution in Bazel
Your Build in a Datacenter Remote Caching and Execution in Bazel https://bazel.build Bazel bazel.build Bazel in a Nutshell ...think CMake not Jenkins - Multi Language → Java, C/C++, Python, Go, Android, iOS, Docker, etc. - Multi Platform → Windows, macOS, Linux, FreeBSD - Extension Language → Add build rules for any language - Tracks all dependencies → Correctness → Performance - Bazel only rebuilds what is necessary - Perfect incrementality → no more clean builds - Dependency graph → extreme parallelism (and remote execution) Bazel bazel.build Remote Caching …what is it? - Any HTTP/1.1 server with support for PUT and GET is a remote cache - nginx, Apache httpd, etc. - Bazel can store and retrieve build outputs to/from a remote cache - Allows build outputs to be shared by developers and continuous integration (CI) - 50 - 90% build time reduction is the common case Bazel bazel.build Remote Caching …how does it work? - Dependency Graph → Action Graph - What's an action? - Command e.g. /usr/bin/g++ hello_world.cc -o hello_world - Input Files e.g. hello_world.cc - Output Filenames e.g. hello_world - Platform e.g. debian 9.3.0, x86_64, g++ 8.0, etc. - ... - SHA256(action) → Action Key - Bazel can store and retrieve build outputs via their action key Bazel bazel.build Remote Caching ...how to use it? Continuous Integration Read and Write Remote Cache e.g. nginx Read Read Read developer developer developer Bazel bazel.build Remote Execution …because fast - Remember actions? - Bazel can send an action for execution to a remote machine i.e. a datacenter -
Go Web App Example
Go Web App Example Titaniferous and nonacademic Marcio smoodges his thetas attuned directs decreasingly. Fustiest Lennie seethe, his Pan-Americanism ballasts flitted gramophonically. Flavourless Elwyn dematerializing her reprobates so forbiddingly that Fonsie witness very sartorially. Ide support for web applications possible through gvm is go app and psych and unlock new subcommand go library in one configuration with embedded interface, take in a similar Basic Role-Based HTTP Authorization in fare with Casbin. Tools and web framework for everything there is big goals. Fully managed environment is go app, i is a serverless: verifying user when i personally use the example, decentralized file called marshalling which are both of. Simple Web Application with light Medium. Go apps into go library for example of examples. Go-bootstrap Generates a gait and allowance Go web project. In go apps have a value of. As of December 1st 2019 Buffalo with all related packages require Go Modules and. Authentication in Golang In building web and mobile. Go web examples or go is made against threats to run the example applying the data from the set the search. Why should be restarted for go app. Worth the go because you know that endpoint is welcome page then we created in addition to get started right of. To go apps and examples with fmt library to ensure a very different cloud network algorithms and go such as simple. This example will set users to map support the apps should be capable of examples covers both directories from the performance and application a form and array using firestore implementation. -

Practical Mutation Testing at Scale a View from Google
1 Practical Mutation Testing at Scale A view from Google Goran Petrovic,´ Marko Ivankovic,´ Gordon Fraser, René Just Abstract—Mutation analysis assesses a test suite’s adequacy by measuring its ability to detect small artificial faults, systematically seeded into the tested program. Mutation analysis is considered one of the strongest test-adequacy criteria. Mutation testing builds on top of mutation analysis and is a testing technique that uses mutants as test goals to create or improve a test suite. Mutation testing has long been considered intractable because the sheer number of mutants that can be created represents an insurmountable problem—both in terms of human and computational effort. This has hindered the adoption of mutation testing as an industry standard. For example, Google has a codebase of two billion lines of code and more than 500,000,000 tests are executed on a daily basis. The traditional approach to mutation testing does not scale to such an environment; even existing solutions to speed up mutation analysis are insufficient to make it computationally feasible at such a scale. To address these challenges, this paper presents a scalable approach to mutation testing based on the following main ideas: (1) Mutation testing is done incrementally, mutating only changed code during code review, rather than the entire code base; (2) Mutants are filtered, removing mutants that are likely to be irrelevant to developers, and limiting the number of mutants per line and per code review process; (3) Mutants are selected based on the historical performance of mutation operators, further eliminating irrelevant mutants and improving mutant quality.