Accelerating Personal Computations with Htcondor: Generating Large Numbers of Events with Genie
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Managing Projects with GNU Make, Third Edition by Robert Mecklenburg
ManagingProjects with GNU Make Other resources from O’Reilly Related titles Unix in a Nutshell sed and awk Unix Power Tools lex and yacc Essential CVS Learning the bash Shell Version Control with Subversion oreilly.com oreilly.com is more than a complete catalog of O’Reilly books. You’ll also find links to news, events, articles, weblogs, sample chapters, and code examples. oreillynet.com is the essential portal for developers interested in open and emerging technologies, including new platforms, pro- gramming languages, and operating systems. Conferences O’Reilly brings diverse innovators together to nurture the ideas that spark revolutionary industries. We specialize in document- ing the latest tools and systems, translating the innovator’s knowledge into useful skills for those in the trenches. Visit con- ferences.oreilly.com for our upcoming events. Safari Bookshelf (safari.oreilly.com) is the premier online refer- ence library for programmers and IT professionals. Conduct searches across more than 1,000 books. Subscribers can zero in on answers to time-critical questions in a matter of seconds. Read the books on your Bookshelf from cover to cover or sim- ply flip to the page you need. Try it today with a free trial. THIRD EDITION ManagingProjects with GNU Make Robert Mecklenburg Beijing • Cambridge • Farnham • Köln • Sebastopol • Tokyo Managing Projects with GNU Make, Third Edition by Robert Mecklenburg Copyright © 2005, 1991, 1986 O’Reilly Media, Inc. All rights reserved. Printed in the United States of America. Published by O’Reilly Media, Inc., 1005 Gravenstein Highway North, Sebastopol, CA 95472. O’Reilly books may be purchased for educational, business, or sales promotional use. -

Red Hat Enterprise Linux 6 Developer Guide
Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Dave Brolley William Cohen Roland Grunberg Aldy Hernandez Karsten Hopp Jakub Jelinek Developer Guide Jeff Johnston Benjamin Kosnik Aleksander Kurtakov Chris Moller Phil Muldoon Andrew Overholt Charley Wang Kent Sebastian Red Hat Enterprise Linux 6 Developer Guide An introduction to application development tools in Red Hat Enterprise Linux 6 Edition 0 Author Dave Brolley [email protected] Author William Cohen [email protected] Author Roland Grunberg [email protected] Author Aldy Hernandez [email protected] Author Karsten Hopp [email protected] Author Jakub Jelinek [email protected] Author Jeff Johnston [email protected] Author Benjamin Kosnik [email protected] Author Aleksander Kurtakov [email protected] Author Chris Moller [email protected] Author Phil Muldoon [email protected] Author Andrew Overholt [email protected] Author Charley Wang [email protected] Author Kent Sebastian [email protected] Editor Don Domingo [email protected] Editor Jacquelynn East [email protected] Copyright © 2010 Red Hat, Inc. and others. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/. In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. -

Kdesrc-Build Script Manual
kdesrc-build Script Manual Michael Pyne Carlos Woelz kdesrc-build Script Manual 2 Contents 1 Introduction 8 1.1 A brief introduction to kdesrc-build . .8 1.1.1 What is kdesrc-build? . .8 1.1.2 kdesrc-build operation ‘in a nutshell’ . .8 1.2 Documentation Overview . .9 2 Getting Started 10 2.1 Preparing the System to Build KDE . 10 2.1.1 Setup a new user account . 10 2.1.2 Ensure your system is ready to build KDE software . 10 2.1.3 Setup kdesrc-build . 12 2.1.3.1 Install kdesrc-build . 12 2.1.3.2 Prepare the configuration file . 12 2.1.3.2.1 Manual setup of configuration file . 12 2.2 Setting the Configuration Data . 13 2.3 Using the kdesrc-build script . 14 2.3.1 Loading project metadata . 14 2.3.2 Previewing what will happen when kdesrc-build runs . 14 2.3.3 Resolving build failures . 15 2.4 Building specific modules . 16 2.5 Setting the Environment to Run Your KDEPlasma Desktop . 17 2.5.1 Automatically installing a login driver . 18 2.5.1.1 Adding xsession support for distributions . 18 2.5.1.2 Manually adding support for xsession . 18 2.5.2 Setting up the environment manually . 19 2.6 Module Organization and selection . 19 2.6.1 KDE Software Organization . 19 2.6.2 Selecting modules to build . 19 2.6.3 Module Sets . 20 2.6.3.1 The basic module set concept . 20 2.6.3.2 Special Support for KDE module sets . -

Installing the Klocwork Server Package
Installation and Upgrade Klocwork Insight 10.0 SR6 Document version 1.6 Klocwork Installation and Upgrade Version 10.0 PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Tue, 12 Aug 2014 15:19:51 EST Contents Articles Before you install 1 System requirements 1 Release Notes 11 About the Klocwork packages and components 24 Upgrading from a previous version 26 Upgrading from a previous version 26 Import your existing projects into a new projects root 27 Migrate your projects root directory 31 Installing the Klocwork Server package on Windows -- Upgrade only 36 Installing the Klocwork Server package on Unix -- Upgrade only 37 Installing the Klocwork Server package on Mac -- Upgrade only 40 Get a license 42 Getting a license 42 Installing the Server package 45 Installing Klocwork Insight 45 Installing the Klocwork Server package on Windows 46 Installing the Klocwork Server package on Unix 49 Installing the Klocwork Server package on Mac 52 Viewing and changing Klocwork server settings 54 Downloading and deploying the desktop analysis plug-ins 56 kwupdate 57 Installing a desktop analysis plug-in or command line utility 59 Installing a desktop analysis plug-in 59 Installing the Klocwork plug-in from the Eclipse update site 62 Running a custom installation for new or upgraded IDEs 63 Installing the Distributed Analysis package 64 Installing the Distributed Analysis package 64 Configuring and starting the Klocwork servers 67 Viewing and changing Klocwork server settings 67 -
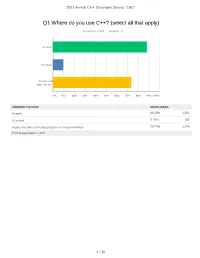
Q1 Where Do You Use C++? (Select All That Apply)
2021 Annual C++ Developer Survey "Lite" Q1 Where do you use C++? (select all that apply) Answered: 1,870 Skipped: 3 At work At school In personal time, for ho... 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES At work 88.29% 1,651 At school 9.79% 183 In personal time, for hobby projects or to try new things 73.74% 1,379 Total Respondents: 1,870 1 / 35 2021 Annual C++ Developer Survey "Lite" Q2 How many years of programming experience do you have in C++ specifically? Answered: 1,869 Skipped: 4 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 7.60% 142 3-5 years 20.60% 385 6-10 years 20.71% 387 10-20 years 30.02% 561 >20 years 21.08% 394 TOTAL 1,869 2 / 35 2021 Annual C++ Developer Survey "Lite" Q3 How many years of programming experience do you have overall (all languages)? Answered: 1,865 Skipped: 8 1-2 years 3-5 years 6-10 years 10-20 years >20 years 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% ANSWER CHOICES RESPONSES 1-2 years 1.02% 19 3-5 years 12.17% 227 6-10 years 22.68% 423 10-20 years 29.71% 554 >20 years 34.42% 642 TOTAL 1,865 3 / 35 2021 Annual C++ Developer Survey "Lite" Q4 What types of projects do you work on? (select all that apply) Answered: 1,861 Skipped: 12 Gaming (e.g., console and.. -
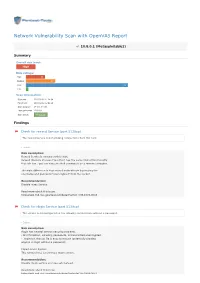
Network Vulnerability Scan with Openvas Report
Network Vulnerability Scan with OpenVAS Report 10.8.0.1 (Metasploitable2) Summary Overall risk level: High Risk ratings: High: 13 Medium: 20 Low: 69 Info: 1 Scan information: Start time: 2018-03-02 11:24:54 Finish time: 2018-03-02 12:02:48 Scan duration: 37 min, 54 sec Tests performed: 103/103 Scan status: Finished Findings Check for rexecd Service (port 512/tcp) The rexecd Service is not allowing connections from this host. Details Risk description: Rexecd Service is running at this Host. Rexecd (Remote Process Execution) has the same kind of functionality that rsh has : you can execute shell commands on a remote computer. The main difference is that rexecd authenticate by reading the username and password *unencrypted* from the socket. Recommendation: Disable rexec Service. Read more about this issue: https//web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-1999-0618 Check for rlogin Service (port 513/tcp) The service is misconfigured so it is allowing conntections without a password. Details Risk description: rlogin has several serious security problems, - All information, including passwords, is transmitted unencrypted. - .rlogin (or .rhosts) file is easy to misuse (potentially allowing anyone to login without a password) Impact Level: System This remote host is running a rlogin service. Recommendation: Disable rlogin service and use ssh instead. Read more about this issue: https//web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-1999-0651 https//web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-1999-0651 http//en.wikipedia.org/wiki/Rlogin http//www.ietf.org/rfc/rfc1282.txt DistCC Detection (port 3632/tcp) No evidence Details Risk description: DistCC is a program to distribute builds of C, C++, Objective C or Objective C++ code across several machines on a network. -

Final Readme Xcode 4.2 for Lion
Xcode 4.2 Includes SDKs for Mac OS X 10.7 Lion and iOS 5 Contents Introduction About SDKs Installation Deprecation Notice Introduction Xcode is the complete developer toolset for creating applications for Mac, iPhone, and iPad. This package installs the Xcode IDE, the Instruments analysis tool, iOS Simulator, and OS framework bundles in the form of Mac OS X SDKs and iOS SDKs. What’s New in Xcode 4.2 for Lion • Support for Mac OS X 10.7 Lion and iOS SDK 5 • Apple LLVM compiler 3.0 with Automatic Reference Counting (ARC) • Storyboarding support in Interface Builder to design multi-view workflows for iOS • OpenGL ES graphical debugger within the main Xcode debugging interface • LLVM compiler support for C++’0x features using the new LLVM libc++ standard library • Additional bug fixes, stability, and performance improvements What’s New in Xcode 4 • Xcode 4 has a brand new, single window interface for all major workflows • Interface Builder is now integrated within the main Xcode IDE • Assistant shows a paired editor with complementary files, e.g.: header or UI controller • Live Issues display coding errors as you type, and Fix-it can correct the mistake for you Compatibility: Xcode 4 requires an Intel-based Mac running Mac OS X 10.7.0 Lion or later, and includes Mac OS X SDK 10.7 and 10.6, and iOS SDK 5. To develop apps targeting prior versions of Mac OS X or iOS, see the section titled About SDKs and the iOS Simulator below. Developer Resources: The Mac and iOS Developer Programs provide access to the App Store, additional support and documentation, as well as provisioning resources to enable testing and deployment on an iPhone, iPod touch, or iPad device. -

Fast Distributed Compilation and Testing of Large C++ Projects
EPJ Web of Conferences 245, 05001 (2020) https://doi.org/10.1051/epjconf/202024505001 CHEP 2019 Fast distributed compilation and testing of large C++ projects Rosen Matev1;∗ 1CERN Abstract. High energy physics experiments traditionally have large software codebases primarily written in C++ and the LHCb physics software stack is no exception. Compiling from scratch can easily take 5 hours or more for the full stack even on an 8-core VM. In a development workflow, incremental builds often do not significantly speed up compilation because even just a change of the modification time of a widely used header leads to many compiler and linker invokations. Using powerful shared servers is not practical as users have no control and maintenance is an issue. Even though support for building partial checkouts on top of published project versions exists, by far the most practical development workflow involves full project checkouts because of off-the-shelf tool support (git, intellisense, etc.) This paper details a deployment of distcc, a distributed compilation server, on opportunistic resources such as development machines. The best performance operation mode is achieved when preprocessing remotely and profiting from the shared CernVM File System. A 10 (30) fold speedup of elapsed (real) time is achieved when compiling Gaudi, the base of the LHCb stack, when comparing local compilation on a 4 core VM to remote compilation on 80 cores, where the bottleneck becomes non-distributed work such as linking. Compilation results are cached locally using ccache, allowing for even faster rebuilding. A recent distributed memcached-based shared cache is tested as well as a more modern distributed system by Mozilla, sccache, backed by S3 storage. -

Pdf/Acyclic.1.Pdf
tldr pages Simplified and community-driven man pages Generated on Sun Sep 26 15:57:34 2021 Android am Android activity manager. More information: https://developer.android.com/studio/command-line/adb#am. • Start a specific activity: am start -n {{com.android.settings/.Settings}} • Start an activity and pass data to it: am start -a {{android.intent.action.VIEW}} -d {{tel:123}} • Start an activity matching a specific action and category: am start -a {{android.intent.action.MAIN}} -c {{android.intent.category.HOME}} • Convert an intent to a URI: am to-uri -a {{android.intent.action.VIEW}} -d {{tel:123}} bugreport Show an Android bug report. This command can only be used through adb shell. More information: https://android.googlesource.com/platform/frameworks/native/+/ master/cmds/bugreport/. • Show a complete bug report of an Android device: bugreport bugreportz Generate a zipped Android bug report. This command can only be used through adb shell. More information: https://android.googlesource.com/platform/frameworks/native/+/ master/cmds/bugreportz/. • Generate a complete zipped bug report of an Android device: bugreportz • Show the progress of a running bugreportz operation: bugreportz -p • Show the version of bugreportz: bugreportz -v • Display help: bugreportz -h cmd Android service manager. More information: https://cs.android.com/android/platform/superproject/+/ master:frameworks/native/cmds/cmd/. • List every running service: cmd -l • Call a specific service: cmd {{alarm}} • Call a service with arguments: cmd {{vibrator}} {{vibrate 300}} dalvikvm Android Java virtual machine. More information: https://source.android.com/devices/tech/dalvik. • Start a Java program: dalvikvm -classpath {{path/to/file.jar}} {{classname}} dumpsys Provide information about Android system services. -

Build a GCC-Based Cross Compiler for Linux
Build a GCC-based cross compiler for Linux Presented by developerWorks, your source for great tutorials ibm.com/developerWorks Table of contents If you're viewing this document online, you can click any of the topics below to link directly to that section. 1. Before you start ..................................................................................... 2 2. Cross-compiling..................................................................................... 4 3. Preparation............................................................................................ 7 4. Configuration and building................................................................... 10 5. Install and use your cross-compiler..................................................... 14 6. Summary and resources ..................................................................... 16 Build a GCC-based cross compiler for Linux Page 1 of 17 ibm.com/developerWorks Presented by developerWorks, your source for great tutorials Section 1. Before you start About this tutorial There are times when the platform you're developing on and the computer you're developing for don't match. For example, you might want to build a PowerPC/Linux application from your x86/Linux laptop. Using the gcc, gas, and ld tools from the GNU toolkits, you can specify and build a cross-compiler that will enable you to build for other targets on your machine. With a bit more work, you can even set up an environment that will build an application for a variety of different targets. In this tutorial, I describe the process required to build a cross-compiler on your system. I also discuss building a complete environment for a range of targets, show you how to integrate with the distcc and ccache tools, and describe the methods required to keep up-to-date with the latest revisions and updates on your new development platform. To build a cross-compiler, you need a basic knowledge of the build process of a typical UNIX open source project, some basic shell skills, and a lot of patience. -

History and Features of a Developer Tool in Ios: XCODE Miss Priyanka V
Volume 4, No. 6, May 2013 (Special Issue) International Journal of Advanced Research in Computer Science CASE STUDY AND REPORT Available Online at www.ijarcs.info History and Features of a developer tool in iOS: XCODE Miss Priyanka V. Kanoi Miss Payal N. ingole 2nd yr Information and Technology 3rd yr Computer sc and Engineering JDIET , Yavatmal JDIET, Yavatmal [email protected] [email protected] Abstract: The powerful developer tool Xcode developed by apple.inc provides everything for creating great apps in mac, iphone and ipad. XCODE is integrated tightly with the Cocoa and Cocoa Touch frameworks. XCODE creates powerful and easy to use development environment, which is powerful enough to be used by OS X and iOS. Xcode toolset includes Xcode IDE, with the Interface Builder design tool and fully integrated LLVM compiler. Dozens of other supporting developer tools are also included in XCODE along with Instruments analysis tool. Keywords: XCODE, XCODE IDE, LLVM compiler, Simulators, LLDB Debugger. I. INTRODUCTION B. X 2 series: Xcode is an Integrated Development Environment (IDE) Xcode 2.0 was released with Mac OS X v10.4 "Tiger". It containing a suite of software development tools developed included the Quartz Composer visual programming language, by Apple for developing software for OS X and iOS. First better Code Sense indexing for Java, and Ant support. It released in 2003, the latest stable release is version 4.6. also included the Apple Reference Library tool. Xcode 2.1 Registered developers can download preview releases and could create universal binaries. It supported previous versions of the suite through the Apple Developer Shared Precompiled Headers, unit testing targets, conditional website.[1] breakpoints, and watchpoints. -

Distcc, a Fast Free Distributed Compiler
distcc, a fast free distributed compiler Date: December 2003 Author: Martin Pool <[email protected]> Presented at: linux.conf.au, Adelaide, 2004 Licence: Verbatim reproduction of this paper is permitted. 1 Abstract distcc is a program to distribute compilation of C, C++, Objective C and Objective C++ code between several machines on a network. distcc is easy to set up, and can build software projects several times faster than local compilation. It is distributed under the GNU General Public License. distcc does not require all machines to share a filesystem, have synchronised clocks, or to have the same libraries or header files installed. They can even have different processors or operating systems, if cross-compilers are installed. This paper begins with some background information on compilation and prior distributed compilers, then describes the design of distcc, presents the outcomes and some applications, and some lessons learned that may be useful to other small free software projects. 2 Background It is common for a software developer to have access to more than one computer. Perhaps they have a laptop and also a desktop machine, or perhaps they work in a group where each member has a workstation. It would be nice if the spare computing power could be used to speed up software builds. distcc offers a straightforward solution. The distccd server runs on all the machines, with a low priority and a cap on the number of processes. Any client can distribute compilation jobs onto other machines. distcc can be installed by any user, without needing root access or system-wide changes.