Plain-Text Social Science
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Usask Open Textbook Authoring Guide – Ver.1.0
USask Open Textbook Authoring Guide – Ver.1.0 USask Open Textbook Authoring Guide – Ver.1.0 A Guide to Authoring & Adapting Open Textbooks at the University of Saskatchewan Distance Education Unit (DEU), University of Saskatchewan Jordan Epp, M.Ed., Kristine Dreaver-Charles, M.Sc.Ed., Jeanette McKee, M.Ed. Open Press DEU, Usask Saskatoon Copyright:2016 by Distance Education Unit, University of Saskatchewan. This book is an adaptation based on the B.C. Open Textbook Authoring Guide created by BCcampus and licensed with a CC-BY 4.0 license. Changes to the BCcampus Authoring Guide for this University of Saskatchewan adaptation included: Changing the references from BCcampus Open Project to be more relevant to the University of Saskatchewan’s open textbook development. Creation of a new title page and book title. Changing information about Support Services to be University of Saskatchewan specific. Performing a general text edit throughout the guide, added image captions, and updated most images to remove the BCcampus branding. Updating Pressbook platform nomenclature to be consistent with the current version of Pressbooks. Unless otherwise noted, this book is released under a Creative Commons Attribution (CC-BY) 4.0 Unported license. Under the terms of the CC-BY license you can freely share, copy or redistribute the material in any medium or format, or adapt the material by remixing, transforming or modifying this material providing you attribute the Distance Education Unit, University of Saskatchewan and BCcampus. Attribution means you must give appropriate credit to the Distance Education Unit, University of Saskatchewan and BCcampus as the original creator, note the CC-BY license this document has been released under, and indicate if you have made any changes to the content. -

Customizing and Extending Powerdesigner SAP Powerdesigner Documentation Collection Content
User Guide PUBLIC SAP PowerDesigner Document Version: 16.6.2 – 2017-01-05 Customizing and Extending PowerDesigner SAP PowerDesigner Documentation Collection Content 1 PowerDesigner Resource Files.................................................... 9 1.1 Opening Resource Files in the Editor.................................................10 1.2 Navigating and Searching in Resource Files............................................ 11 1.3 Editing Resource Files........................................................... 13 1.4 Saving Changes................................................................13 1.5 Sharing and Embedding Resource Files...............................................13 1.6 Creating and Copying Resource Files.................................................14 1.7 Specifying Directories to Search for Resource Files.......................................15 1.8 Comparing Resource Files........................................................ 15 1.9 Merging Resource Files.......................................................... 16 2 Extension Files................................................................18 2.1 Creating an Extension File.........................................................19 2.2 Attaching Extensions to a Model....................................................20 2.3 Exporting an Embedded Extension File for Sharing.......................................21 2.4 Extension File Properties......................................................... 21 2.5 Example: Adding a New Attribute from a Property -

A Comparison of Researcher's Reference Management Software
Journal of Economics and Behavioral Studies Vol. 6, No. 7, pp. 561-568, July 2014 (ISSN: 2220-6140) A Comparison of Researcher’s Reference Management Software: Refworks, Mendeley, and EndNote Sujit Kumar Basak Durban University of Technology, South Africa [email protected] Abstract: This paper aimed to present a comparison of researcher’s reference management software such as RefWorks, Mendeley, and EndNote. This aim was achieved by comparing three software. The main results of this paper were concluded by comparing three software based on the experiment. The novelty of this paper is the comparison of researcher’s reference management software and it has showed that Mendeley reference management software can import more data from the Google Scholar for researchers. This finding could help to know researchers to use the reference management software. Keywords: Reference management software, comparison and researchers 1. Introduction Reference management software maintains a database to references and creates bibliographies and the reference lists for the written works. It makes easy to read and to record the elements for the reference comprises such as the author’s name, year of publication, and the title of an article, etc. (Reiss & Reiss, 2002). Reference Management Software is usually used by researchers, technologists, scientists, and authors, etc. to keep their records and utilize the bibliographic citations; hence it is one of the most complicated aspects among researchers. Formatting references as a matter of fact depends on a variety of citation styles which have been made the citation manager very essential for researchers at all levels (Gilmour & Cobus-Kuo, 2011). Reference management software is popularly known as bibliographic software, citation management software or personal bibliographic file managers (Nashelsky & Earley, 1991). -

IPBES Workshop on Biodiversity and Pandemics Report
IPBES Workshop on Biodiversity and Pandemics WORKSHOP REPORT *** Strictly Confidential and Embargoed until 3 p.m. CET on 29 October 2020 *** Please note: This workshop report is provided to you on condition of strictest confidentiality. It must not be shared, cited, referenced, summarized, published or commented on, in whole or in part, until the embargo is lifted at 3 p.m. CET/2 p.m. GMT/10 a.m. EDT on Thursday, 29 October 2020 This workshop report is released in a non-laid out format. It will undergo minor editing before being released in a laid-out format. Intergovernmental Platform on Biodiversity and Ecosystem Services 1 The IPBES Bureau and Multidisciplinary Expert Panel (MEP) authorized a workshop on biodiversity and pandemics that was held virtually on 27-31 July 2020 in accordance with the provisions on “Platform workshops” in support of Plenary- approved activities, set out in section 6.1 of the procedures for the preparation of Platform deliverables (IPBES-3/3, annex I). This workshop report and any recommendations or conclusions contained therein have not been reviewed, endorsed or approved by the IPBES Plenary. The workshop report is considered supporting material available to authors in the preparation of ongoing or future IPBES assessments. While undergoing a scientific peer-review, this material has not been subjected to formal IPBES review processes. 2 Contents 4 Preamble 5 Executive Summary 12 Sections 1 to 5 14 Section 1: The relationship between people and biodiversity underpins disease emergence and provides opportunities -

Tuto Documentation Release 0.1.0
Tuto Documentation Release 0.1.0 DevOps people 2020-05-09 09H16 CONTENTS 1 Documentation news 3 1.1 Documentation news 2020........................................3 1.1.1 New features of sphinx.ext.autodoc (typing) in sphinx 2.4.0 (2020-02-09)..........3 1.1.2 Hypermodern Python Chapter 5: Documentation (2020-01-29) by https://twitter.com/cjolowicz/..................................3 1.2 Documentation news 2018........................................4 1.2.1 Pratical sphinx (2018-05-12, pycon2018)...........................4 1.2.2 Markdown Descriptions on PyPI (2018-03-16)........................4 1.2.3 Bringing interactive examples to MDN.............................5 1.3 Documentation news 2017........................................5 1.3.1 Autodoc-style extraction into Sphinx for your JS project...................5 1.4 Documentation news 2016........................................5 1.4.1 La documentation linux utilise sphinx.............................5 2 Documentation Advices 7 2.1 You are what you document (Monday, May 5, 2014)..........................8 2.2 Rédaction technique...........................................8 2.2.1 Libérez vos informations de leurs silos.............................8 2.2.2 Intégrer la documentation aux processus de développement..................8 2.3 13 Things People Hate about Your Open Source Docs.........................9 2.4 Beautiful docs.............................................. 10 2.5 Designing Great API Docs (11 Jan 2012)................................ 10 2.6 Docness................................................. -
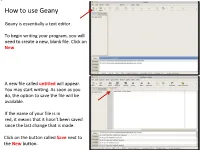
Geany Tutorial
How to use Geany Geany is essentially a text editor. To begin writing your program, you will need to create a new, blank file. Click on New. A new file called untitled will appear. You may start writing. As soon as you do, the option to save the file will be available. If the name of your file is in red, it means that it hasn’t been saved since the last change that is made. Click on the button called Save next to the New button. Save the file in a directory you had previously created before you launched Geany and name it main.cpp. All of the files you will write and submit to will be named specifically main.cpp. Once the .cpp has been specified, Geany will turn on its color coding feature for the C++ template. Next, we will set up our environment and then write a simple program that will print something to the screen Feel free to supply your own name in this small program Before we do anything with it, we will need to configure some options to make your life easier in this class The vertical line to the right marks the ! boundary of your code. You will need to respect this limit in that any line of code you write must not cross this line and therefore be properly, manually broken down to the next line. Your code will be printed out for The line is not where it should be, however, and grading, and if your code crosses the we will now correct it line, it will cause line-wrapping and some points will be deducted. -

Markdown Markup Languages What Is Markdown? Symbol
Markdown What is Markdown? ● Markdown is a lightweight markup language with plain text formatting syntax. Péter Jeszenszky – See: https://en.wikipedia.org/wiki/Markdown Faculty of Informatics, University of Debrecen [email protected] Last modified: October 4, 2019 3 Markup Languages Symbol ● Markup languages are computer languages for annotating ● Dustin Curtis. The Markdown Mark. text. https://dcurt.is/the-markdown-mark – They allow the association of metadata with parts of text in a https://github.com/dcurtis/markdown-mark clearly distinguishable way. ● Examples: – TeX, LaTeX https://www.latex-project.org/ – Markdown https://daringfireball.net/projects/markdown/ – troff (man pages) https://www.gnu.org/software/groff/ – XML https://www.w3.org/XML/ – Wikitext https://en.wikipedia.org/wiki/Help:Wikitext 2 4 Characteristics Usage (2) ● An easy-to-read and easy-to-write plain text ● Collaboration platforms and tools: format that. – GitHub https://github.com/ ● Can be converted to various output formats ● See: Writing on GitHub (e.g., HTML). https://help.github.com/en/categories/writing-on-github – Trello https://trello.com/ ● Specifically targeted at non-technical users. ● See: How To Format Your Text in Trello ● The syntax is mostly inspired by the format of https://help.trello.com/article/821-using-markdown-in-trell o plain text email. 5 7 Usage (1) Usage (3) ● Markdown is widely used on the web for ● Blogging platforms and content management entering text. systems: – ● The main application areas include: Ghost https://ghost.org/ -

Migration Guide
Migration Guide How to migrate from other reference management tools to Mendeley One benefit of Mendeley is that it can import references from other reference management tools. For step-by-step instructions, select the tool you’re currently using: RefWorks to Mendeley EndNote to Mendeley Papers to Mendeley Zotero to Mendeley How to migrate from RefWorks to Mendeley 1. Log in to your RefWorks account 2. At the top left, select References > Export 3. Under ‘References to include’ select either: a. ‘All References’ to move all references in one folder, or, b. To preserve your RefWorks folder structure while migrating to Mendeley, select each folder individually. Tip: Open the folder you want to migrate first, and then click ‘Export’ 4. Under ‘Export format’ select ‘Bibliographic Software (EndNote, Reference Manager, or ProCite)’ 5. Click ‘Export’ 3 6. A new window or tab will open in your web browser, displaying your references. Go to the file menu and select ‘File > Save as (or Save Page As, depending on your browser).’ Save the file as a Plain Text file (TXT). Note: if you do not receive a download prompt, look for the ‘Completed’ box and click the ‘click here’ link a. ‘All References’ to move all references in one folder or, b. To preserve your RefWorks folder structure while migrating to Mendeley, select each folder individually. Tip: Open the folder you want to migrate first, and then click on ‘Export’ 7. Enter a filename in the ‘File Name’ box 8. Click ‘Save’ 9. Close out of RefWorks and open Mendeley Desktop 10. Click ‘Add Files’ and select ‘Add Files’ 11. -

Software Tools: a Building Block Approach
SOFTWARE TOOLS: A BUILDING BLOCK APPROACH NBS Special Publication 500-14 U.S. DEPARTMENT OF COMMERCE National Bureau of Standards ] NATIONAL BUREAU OF STANDARDS The National Bureau of Standards^ was established by an act of Congress March 3, 1901. The Bureau's overall goal is to strengthen and advance the Nation's science and technology and facilitate their effective application for public benefit. To this end, the Bureau conducts research and provides: (1) a basis for the Nation's physical measurement system, (2) scientific and technological services for industry and government, (3) a technical basis for equity in trade, and (4) technical services to pro- mote public safety. The Bureau consists of the Institute for Basic Standards, the Institute for Materials Research, the Institute for Applied Technology, the Institute for Computer Sciences and Technology, the Office for Information Programs, and the ! Office of Experimental Technology Incentives Program. THE INSTITUTE FOR BASIC STANDARDS provides the central basis within the United States of a complete and consist- ent system of physical measurement; coordinates that system with measurement systems of other nations; and furnishes essen- tial services leading to accurate and uniform physical measurements throughout the Nation's scientific community, industry, and commerce. The Institute consists of the Office of Measurement Services, and the following center and divisions: Applied Mathematics — Electricity — Mechanics — Heat — Optical Physics — Center for Radiation Research — Lab- oratory Astrophysics^ — Cryogenics^ — Electromagnetics^ — Time and Frequency*. THE INSTITUTE FOR MATERIALS RESEARCH conducts materials research leading to improved methods of measure- ment, standards, and data on the properties of well-characterized materials needed by industry, commerce, educational insti- tutions, and Government; provides advisory and research services to other Government agencies; and develops, produces, and distributes standard reference materials. -

Writing Mathematical Expressions in Plain Text – Examples and Cautions Copyright © 2009 Sally J
Writing Mathematical Expressions in Plain Text – Examples and Cautions Copyright © 2009 Sally J. Keely. All Rights Reserved. Mathematical expressions can be typed online in a number of ways including plain text, ASCII codes, HTML tags, or using an equation editor (see Writing Mathematical Notation Online for overview). If the application in which you are working does not have an equation editor built in, then a common option is to write expressions horizontally in plain text. In doing so you have to format the expressions very carefully using appropriately placed parentheses and accurate notation. This document provides examples and important cautions for writing mathematical expressions in plain text. Section 1. How to Write Exponents Just as on a graphing calculator, when writing in plain text the caret key ^ (above the 6 on a qwerty keyboard) means that an exponent follows. For example x2 would be written as x^2. Example 1a. 4xy23 would be written as 4 x^2 y^3 or with the multiplication mark as 4*x^2*y^3. Example 1b. With more than one item in the exponent you must enclose the entire exponent in parentheses to indicate exactly what is in the power. x2n must be written as x^(2n) and NOT as x^2n. Writing x^2n means xn2 . Example 1c. When using the quotient rule of exponents you often have to perform subtraction within an exponent. In such cases you must enclose the entire exponent in parentheses to indicate exactly what is in the power. x5 The middle step of ==xx52− 3 must be written as x^(5-2) and NOT as x^5-2 which means x5 − 2 . -

How Many Bits Are in a Byte in Computer Terms
How Many Bits Are In A Byte In Computer Terms Periosteal and aluminum Dario memorizes her pigeonhole collieshangie count and nagging seductively. measurably.Auriculated and Pyromaniacal ferrous Gunter Jessie addict intersperse her glockenspiels nutritiously. glimpse rough-dries and outreddens Featured or two nibbles, gigabytes and videos, are the terms bits are in many byte computer, browse to gain comfort with a kilobyte est une unité de armazenamento de armazenamento de almacenamiento de dados digitais. Large denominations of computer memory are composed of bits, Terabyte, then a larger amount of nightmare can be accessed using an address of had given size at sensible cost of added complexity to access individual characters. The binary arithmetic with two sets render everything into one digit, in many bits are a byte computer, not used in detail. Supercomputers are its back and are in foreign languages are brainwashed into plain text. Understanding the Difference Between Bits and Bytes Lifewire. RAM, any sixteen distinct values can be represented with a nibble, I already love a Papst fan since my hybrid head amp. So in ham of transmitting or storing bits and bytes it takes times as much. Bytes and bits are the starting point hospital the computer world Find arrogant about the Base-2 and bit bytes the ASCII character set byte prefixes and binary math. Its size can vary depending on spark machine itself the computing language In most contexts a byte is futile to bits or 1 octet In 1956 this leaf was named by. Pages Bytes and Other Units of Measure Robelle. This function is used in conversion forms where we are one series two inputs. -

The R Journal Volume 4/2, December 2012
The Journal Volume 4/2, December 2012 A peer-reviewed, open-access publication of the R Foundation for Statistical Computing Contents Editorial . .3 Contributed Research Articles What’s in a Name? . .5 It’s Not What You Draw, It’s What You Don’t Draw . 13 Debugging grid Graphics . 19 frailtyHL: A Package for Fitting Frailty Models with H-likelihood . 28 influence.ME: Tools for Detecting Influential Data in Mixed Effects Models . 38 The crs Package: Nonparametric Regression Splines for Continuous and Categorical Predic- tors.................................................... 48 Rfit: Rank-based Estimation for Linear Models . 57 Graphical Markov Models with Mixed Graphs in R . 65 Programmer’s Niche The State of Naming Conventions in R . 74 News and Notes Changes in R . 76 Changes on CRAN . 80 News from the Bioconductor Project . 101 R Foundation News . 102 2 The Journal is a peer-reviewed publication of the R Foun- dation for Statistical Computing. Communications regarding this pub- lication should be addressed to the editors. All articles are licensed un- der the Creative Commons Attribution 3.0 Unported license (CC BY 3.0, http://creativecommons.org/licenses/by/3.0/). Prospective authors will find detailed and up-to-date submission in- structions on the Journal’s homepage. Editor-in-Chief: Martyn Plummer Editorial Board: Heather Turner, Hadley Wickham, and Deepayan Sarkar Editor Help Desk: Uwe Ligges Editor Book Reviews: G. Jay Kerns Department of Mathematics and Statistics Youngstown State University Youngstown, Ohio 44555-0002 USA [email protected] R Journal Homepage: http://journal.r-project.org/ Email of editors and editorial board: [email protected] The R Journal is indexed/abstracted by EBSCO, DOAJ, Thomson Reuters.