Non-Relational Data Storage
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Smart Methods for Retrieving Physiological Data in Physiqual
University of Groningen Bachelor thesis Smart methods for retrieving physiological data in Physiqual Marc Babtist & Sebastian Wehkamp Supervisors: Frank Blaauw & Marco Aiello July, 2016 Contents 1 Introduction 4 1.1 Physiqual . 4 1.2 Problem description . 4 1.3 Research questions . 5 1.4 Document structure . 5 2 Related work 5 2.1 IJkdijk project . 5 2.2 MUMPS . 6 3 Background 7 3.1 Scalability . 7 3.2 CAP theorem . 7 3.3 Reliability models . 7 4 Requirements 8 4.1 Scalability . 8 4.2 Reliability . 9 4.3 Performance . 9 4.4 Open source . 9 5 General database options 9 5.1 Relational or Non-relational . 9 5.2 NoSQL categories . 10 5.2.1 Key-value Stores . 10 5.2.2 Document Stores . 11 5.2.3 Column Family Stores . 11 5.2.4 Graph Stores . 12 5.3 When to use which category . 12 5.4 Conclusion . 12 5.4.1 Key-Value . 13 5.4.2 Document stores . 13 5.4.3 Column family stores . 13 5.4.4 Graph Stores . 13 6 Specific database options 13 6.1 Key-value stores: Riak . 14 6.2 Document stores: MongoDB . 14 6.3 Column Family stores: Cassandra . 14 6.4 Performance comparison . 15 6.4.1 Sensor Data Storage Performance . 16 6.4.2 Conclusion . 16 7 Data model 17 7.1 Modeling rules . 17 7.2 Data model Design . 18 2 7.3 Summary . 18 8 Architecture 20 8.1 Basic layout . 20 8.2 Sidekiq . 21 9 Design decisions 21 9.1 Keyspaces . 21 9.2 Gap determination . -

Reliability and Security of Large Scale Data Storage in Cloud Computing C.W
This article is part of the Reliability Society 2010 Annual Technical Report Reliability and Security of Large Scale Data Storage in Cloud Computing C.W. Hsu ¹¹¹ C.W. Wang ²²² Shiuhpyng Shieh ³³³ Department of Computer Science Taiwan Information Security Center at National Chiao Tung University NCTU (TWISC@NCTU) Email: ¹[email protected] ³[email protected] ²[email protected] Abstract In this article, we will present new challenges to the large scale cloud computing, namely reliability and security. Recent progress in the research area will be briefly reviewed. It has been proved that it is impossible to satisfy consistency, availability, and partitioned-tolerance simultaneously. Tradeoff becomes crucial among these factors to choose a suitable data access model for a distributed storage system. In this article, new security issues will be addressed and potential solutions will be discussed. Introduction “Cloud Computing ”, a novel computing model for large-scale application, has attracted much attention from both academic and industry. Since 2006, Google Inc. Chief Executive Eric Schmidt introduced the term into industry, and related research had been carried out in recent years. Cloud computing provides scalable deployment and fine-grained management of services through efficient resource sharing mechanism (most of them are for hardware resources, such as VM). Convinced by the manner called “ pay-as-you-go ” [1][2], companies can lower the cost of equipment management including machine purchasing, human maintenance, data backup, etc. Many cloud services rapidly appear on the Internet, such as Amazon’s EC2, Microsoft’s Azure, Google’s Gmail, Facebook, and so on. However, the well-known definition of the term “Cloud Computing ” was first given by Prof. -

Amazon Dynamodb
Dynamo Amazon DynamoDB Nicolas Travers Inspiré de Advait Deo Vertigo N. Travers ESILV : Dynamo Amazon DynamoDB – What is it ? • Fully managed nosql database service on AWS • Data model in the form of tables • Data stored in the form of items (name – value attributes) • Automatic scaling ▫ Provisioned throughput ▫ Storage scaling ▫ Distributed architecture • Easy Administration • Monitoring of tables using CloudWatch • Integration with EMR (Elastic MapReduce) ▫ Analyze data and store in S3 Vertigo N. Travers ESILV : Dynamo Amazon DynamoDB – What is it ? key=value key=value key=value key=value Table Item (64KB max) Attributes • Primary key (mandatory for every table) ▫ Hash or Hash + Range • Data model in the form of tables • Data stored in the form of items (name – value attributes) • Secondary Indexes for improved performance ▫ Local secondary index ▫ Global secondary index • Scalar data type (number, string etc) or multi-valued data type (sets) Vertigo N. Travers ESILV : Dynamo DynamoDB Architecture • True distributed architecture • Data is spread across hundreds of servers called storage nodes • Hundreds of servers form a cluster in the form of a “ring” • Client application can connect using one of the two approaches ▫ Routing using a load balancer ▫ Client-library that reflects Dynamo’s partitioning scheme and can determine the storage host to connect • Advantage of load balancer – no need for dynamo specific code in client application • Advantage of client-library – saves 1 network hop to load balancer • Synchronous replication is not achievable for high availability and scalability requirement at amazon • DynamoDB is designed to be “always writable” storage solution • Allows multiple versions of data on multiple storage nodes • Conflict resolution happens while reads and NOT during writes ▫ Syntactic conflict resolution ▫ Symantec conflict resolution Vertigo N. -
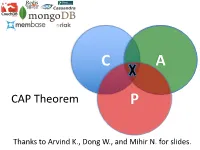
CAP Theorem P
C A CAP Theorem P Thanks to Arvind K., Dong W., and Mihir N. for slides. CAP Theorem • “It is impossible for a web service to provide these three guarantees at the same time (pick 2 of 3): • (Sequential) Consistency • Availability • Partition-tolerance” • Conjectured by Eric Brewer in ’00 • Proved by Gilbert and Lynch in ’02 • But with definitions that do not match what you’d assume (or Brewer meant) • Influenced the NoSQL mania • Highly controversial: “the CAP theorem encourages engineers to make awful decisions.” – Stonebraker • Many misinterpretations 2 CAP Theorem • Consistency: – Sequential consistency (a data item behaves as if there is one copy) • Availability: – Node failures do not prevent survivors from continuing to operate • Partition-tolerance: – The system continues to operate despite network partitions • CAP says that “A distributed system can satisfy any two of these guarantees at the same time but not all three” 3 C in CAP != C in ACID • They are different! • CAP’s C(onsistency) = sequential consistency – Similar to ACID’s A(tomicity) = Visibility to all future operations • ACID’s C(onsistency) = Does the data satisfy schema constraints 4 Sequential consistency • Makes it appear as if there is one copy of the object • Strict ordering on ops from same client • A single linear ordering across client ops – If client a executes operations {a1, a2, a3, ...}, client b executes operations {b1, b2, b3, ...} – Then, globally, clients observe some serialized version of the sequence • e.g., {a1, b1, b2, a2, ...} (or whatever) Notice -

Openldap Slides
What's New in OpenLDAP Howard Chu CTO, Symas Corp / Chief Architect OpenLDAP FOSDEM'14 OpenLDAP Project ● Open source code project ● Founded 1998 ● Three core team members ● A dozen or so contributors ● Feature releases every 12-18 months ● Maintenance releases roughly monthly A Word About Symas ● Founded 1999 ● Founders from Enterprise Software world – platinum Technology (Locus Computing) – IBM ● Howard joined OpenLDAP in 1999 – One of the Core Team members – Appointed Chief Architect January 2007 ● No debt, no VC investments Intro Howard Chu ● Founder and CTO Symas Corp. ● Developing Free/Open Source software since 1980s – GNU compiler toolchain, e.g. "gmake -j", etc. – Many other projects, check ohloh.net... ● Worked for NASA/JPL, wrote software for Space Shuttle, etc. 4 What's New ● Lightning Memory-Mapped Database (LMDB) and its knock-on effects ● Within OpenLDAP code ● Other projects ● New HyperDex clustered backend ● New Samba4/AD integration work ● Other features ● What's missing LMDB ● Introduced at LDAPCon 2011 ● Full ACID transactions ● MVCC, readers and writers don't block each other ● Ultra-compact, compiles to under 32KB ● Memory-mapped, lightning fast zero-copy reads ● Much greater CPU and memory efficiency ● Much simpler configuration LMDB Impact ● Within OpenLDAP ● Revealed other frontend bottlenecks that were hidden by BerkeleyDB-based backends ● Addressed in OpenLDAP 2.5 ● Thread pool enhanced, support multiple work queues to reduce mutex contention ● Connection manager enhanced, simplify write synchronization OpenLDAP -

Arangodb Is Hailed As a Native Multi-Model Database by Its Developers
ArangoDB i ArangoDB About the Tutorial Apparently, the world is becoming more and more connected. And at some point in the very near future, your kitchen bar may well be able to recommend your favorite brands of whiskey! This recommended information may come from retailers, or equally likely it can be suggested from friends on Social Networks; whatever it is, you will be able to see the benefits of using graph databases, if you like the recommendations. This tutorial explains the various aspects of ArangoDB which is a major contender in the landscape of graph databases. Starting with the basics of ArangoDB which focuses on the installation and basic concepts of ArangoDB, it gradually moves on to advanced topics such as CRUD operations and AQL. The last few chapters in this tutorial will help you understand how to deploy ArangoDB as a single instance and/or using Docker. Audience This tutorial is meant for those who are interested in learning ArangoDB as a Multimodel Database. Graph databases are spreading like wildfire across the industry and are making an impact on the development of new generation applications. So anyone who is interested in learning different aspects of ArangoDB, should go through this tutorial. Prerequisites Before proceeding with this tutorial, you should have the basic knowledge of Database, SQL, Graph Theory, and JavaScript. Copyright & Disclaimer Copyright 2018 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. -
![LIST of NOSQL DATABASES [Currently 150]](https://docslib.b-cdn.net/cover/8918/list-of-nosql-databases-currently-150-418918.webp)
LIST of NOSQL DATABASES [Currently 150]
Your Ultimate Guide to the Non - Relational Universe! [the best selected nosql link Archive in the web] ...never miss a conceptual article again... News Feed covering all changes here! NoSQL DEFINITION: Next Generation Databases mostly addressing some of the points: being non-relational, distributed, open-source and horizontally scalable. The original intention has been modern web-scale databases. The movement began early 2009 and is growing rapidly. Often more characteristics apply such as: schema-free, easy replication support, simple API, eventually consistent / BASE (not ACID), a huge amount of data and more. So the misleading term "nosql" (the community now translates it mostly with "not only sql") should be seen as an alias to something like the definition above. [based on 7 sources, 14 constructive feedback emails (thanks!) and 1 disliking comment . Agree / Disagree? Tell me so! By the way: this is a strong definition and it is out there here since 2009!] LIST OF NOSQL DATABASES [currently 150] Core NoSQL Systems: [Mostly originated out of a Web 2.0 need] Wide Column Store / Column Families Hadoop / HBase API: Java / any writer, Protocol: any write call, Query Method: MapReduce Java / any exec, Replication: HDFS Replication, Written in: Java, Concurrency: ?, Misc: Links: 3 Books [1, 2, 3] Cassandra massively scalable, partitioned row store, masterless architecture, linear scale performance, no single points of failure, read/write support across multiple data centers & cloud availability zones. API / Query Method: CQL and Thrift, replication: peer-to-peer, written in: Java, Concurrency: tunable consistency, Misc: built-in data compression, MapReduce support, primary/secondary indexes, security features. -

Nosql Databases: Yearning for Disambiguation
NOSQL DATABASES: YEARNING FOR DISAMBIGUATION Chaimae Asaad Alqualsadi, Rabat IT Center, ENSIAS, University Mohammed V in Rabat and TicLab, International University of Rabat, Morocco [email protected] Karim Baïna Alqualsadi, Rabat IT Center, ENSIAS, University Mohammed V in Rabat, Morocco [email protected] Mounir Ghogho TicLab, International University of Rabat Morocco [email protected] March 17, 2020 ABSTRACT The demanding requirements of the new Big Data intensive era raised the need for flexible storage systems capable of handling huge volumes of unstructured data and of tackling the challenges that arXiv:2003.04074v2 [cs.DB] 16 Mar 2020 traditional databases were facing. NoSQL Databases, in their heterogeneity, are a powerful and diverse set of databases tailored to specific industrial and business needs. However, the lack of the- oretical background creates a lack of consensus even among experts about many NoSQL concepts, leading to ambiguity and confusion. In this paper, we present a survey of NoSQL databases and their classification by data model type. We also conduct a benchmark in order to compare different NoSQL databases and distinguish their characteristics. Additionally, we present the major areas of ambiguity and confusion around NoSQL databases and their related concepts, and attempt to disambiguate them. Keywords NoSQL Databases · NoSQL data models · NoSQL characteristics · NoSQL Classification A PREPRINT -MARCH 17, 2020 1 Introduction The proliferation of data sources ranging from social media and Internet of Things (IoT) to industrially generated data (e.g. transactions) has led to a growing demand for data intensive cloud based applications and has created new challenges for big-data-era databases. -

IBM Cloudant: Database As a Service Fundamentals
Front cover IBM Cloudant: Database as a Service Fundamentals Understand the basics of NoSQL document data stores Access and work with the Cloudant API Work programmatically with Cloudant data Christopher Bienko Marina Greenstein Stephen E Holt Richard T Phillips ibm.com/redbooks Redpaper Contents Notices . 5 Trademarks . 6 Preface . 7 Authors. 7 Now you can become a published author, too! . 8 Comments welcome. 8 Stay connected to IBM Redbooks . 9 Chapter 1. Survey of the database landscape . 1 1.1 The fundamentals and evolution of relational databases . 2 1.1.1 The relational model . 2 1.1.2 The CAP Theorem . 4 1.2 The NoSQL paradigm . 5 1.2.1 ACID versus BASE systems . 7 1.2.2 What is NoSQL? . 8 1.2.3 NoSQL database landscape . 9 1.2.4 JSON and schema-less model . 11 Chapter 2. Build more, grow more, and sleep more with IBM Cloudant . 13 2.1 Business value . 15 2.2 Solution overview . 16 2.3 Solution architecture . 18 2.4 Usage scenarios . 20 2.5 Intuitively interact with data using Cloudant Dashboard . 21 2.5.1 Editing JSON documents using Cloudant Dashboard . 22 2.5.2 Configuring access permissions and replication jobs within Cloudant Dashboard. 24 2.6 A continuum of services working together on cloud . 25 2.6.1 Provisioning an analytics warehouse with IBM dashDB . 26 2.6.2 Data refinement services on-premises. 30 2.6.3 Data refinement services on the cloud. 30 2.6.4 Hybrid clouds: Data refinement across on/off–premises. 31 Chapter 3. -

The Complete Guide to Social Media from the Social Media Guys
The Complete Guide to Social Media From The Social Media Guys PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Mon, 08 Nov 2010 19:01:07 UTC Contents Articles Social media 1 Social web 6 Social media measurement 8 Social media marketing 9 Social media optimization 11 Social network service 12 Digg 24 Facebook 33 LinkedIn 48 MySpace 52 Newsvine 70 Reddit 74 StumbleUpon 80 Twitter 84 YouTube 98 XING 112 References Article Sources and Contributors 115 Image Sources, Licenses and Contributors 123 Article Licenses License 125 Social media 1 Social media Social media are media for social interaction, using highly accessible and scalable publishing techniques. Social media uses web-based technologies to turn communication into interactive dialogues. Andreas Kaplan and Michael Haenlein define social media as "a group of Internet-based applications that build on the ideological and technological foundations of Web 2.0, which allows the creation and exchange of user-generated content."[1] Businesses also refer to social media as consumer-generated media (CGM). Social media utilization is believed to be a driving force in defining the current time period as the Attention Age. A common thread running through all definitions of social media is a blending of technology and social interaction for the co-creation of value. Distinction from industrial media People gain information, education, news, etc., by electronic media and print media. Social media are distinct from industrial or traditional media, such as newspapers, television, and film. They are relatively inexpensive and accessible to enable anyone (even private individuals) to publish or access information, compared to industrial media, which generally require significant resources to publish information. -

A Big Data Roadmap for the DB2 Professional
A Big Data Roadmap For the DB2 Professional Sponsored by: align http://www.datavail.com Craig S. Mullins Mullins Consulting, Inc. http://www.MullinsConsulting.com © 2014 Mullins Consulting, Inc. Author This presentation was prepared by: Craig S. Mullins President & Principal Consultant Mullins Consulting, Inc. 15 Coventry Ct Sugar Land, TX 77479 Tel: 281-494-6153 Fax: 281.491.0637 Skype: cs.mullins E-mail: [email protected] http://www.mullinsconsultinginc.com This document is protected under the copyright laws of the United States and other countries as an unpublished work. This document contains information that is proprietary and confidential to Mullins Consulting, Inc., which shall not be disclosed outside or duplicated, used, or disclosed in whole or in part for any purpose other than as approved by Mullins Consulting, Inc. Any use or disclosure in whole or in part of this information without the express written permission of Mullins Consulting, Inc. is prohibited. © 2014 Craig S. Mullins and Mullins Consulting, Inc. (Unpublished). All rights reserved. © 2014 Mullins Consulting, Inc. 2 Agenda Uncover the roadmap to Big Data… the terminology and technology used, use cases, and trends. • Gain a working knowledge and definition of Big Data (beyond the simple three V's definition) • Break down and understand the often confusing terminology within the realm of Big Data (e.g. polyglot persistence) • Examine the four predominant NoSQL database systems used in Big Data implementations (graph, key/value, column, and document) • Learn some of the major differences between Big Data/NoSQL implementations vis-a-vis traditional transaction processing • Discover the primary use cases for Big Data and NoSQL versus relational databases © 2014 Mullins Consulting, Inc. -

Storing Metagraph Model in Relational, Document- Oriented, and Graph Databases
Storing Metagraph Model in Relational, Document- Oriented, and Graph Databases © Valeriy M. Chernenkiy © Yuriy E. Gapanyuk © Yuriy T. Kaganov © Ivan V. Dunin © Maxim A. Lyaskovsky © Vadim S. Larionov Bauman Moscow State Technical University, Moscow, Russia [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] Abstract. This paper proposes an approach for metagraph model storage in databases with different data models. The formal definition of the metagraph data model is given. The approaches for mapping the metagraph model to the flat graph, document-oriented, and relational data models are proposed. The limitations of the RDF model in comparison with the metagraph model are considered. It is shown that the metagraph model addresses RDF limitations in a natural way without emergence loss. The experiments result for storing the metagraph model in different databases are given. Keywords: metagraph, metavertex, flat graph, graph database, document-oriented database, relational database. adapted for information systems description by the 1 Introduction present authors [2]. According to [2]: = , , , At present, on the one hand, the domains are becoming where – metagraph; – set of metagraph more and more complex. Therefore, models based on vertices; – set of〈 metagraph metavertices; 〉 – complex graphs are increasingly used in various fields of set of metagraph edges. science from mathematics and computer science to A metagraph vertex is described by the set of biology and sociology. attributes: = { }, , where – metagraph On the other hand, there are currently only graph vertex; – attribute. databases based on flat graph or hypergraph models that A metagraph edge is described∈ by the set of attributes, are not capable enough of being suitable repositories for the source and destination vertices and edge direction complex relations in the domains.