Proceedings of the Workshop on Configuration at ECAI 2012
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computer Lab Software
# of Department Room AppName Computers All lab and classroom computers are loaded with a base set of software, exceptions are noted under each lab if applicable; Last Updated Jan 6/20 Microsoft Office 2019 - Access, Excel, One Note, Power Point, Windows 10 Base Publisher and Word, no Outlook Adobe Acrobat Reader DC (2019.012.20040) Adobe Flash & Shockwave Browser plugins Audacity 2.2.2 Aver A+ Docu Camera Suite (Classrooms and Lab Instructor Stations) Google Chrome Enterprise 75.0.3770.142 Java (OpenJDK 11.0.3.7-1) Mendeley Desktop 1.19.4 Microsoft Edge Microsoft Internet Explorer 11 Microsoft Silverlight (5.1.50918.0) Mozilla FireFox 68.0ESR .Net 4.72 NetSupport Notify R 3.65.1 Rstudio 1.2.1335 Skype VLC Media Player 3.0.7.1 Windows DVD Maker Windows Media Player Zip Software (Native Windows) # of Department Room AppName Computers Mac OS 10 Base Adobe Acrobat Pro DC Adobe Flash Player Audacity 2.1.3 Fetch Google Chrome Google Earth Microsoft Office 2011 Mozilla FireFox NetSupport Notify Network Connect Skype VLC Media Player # of Department Room AppName Computers RLLC (Library) Library (Commons) EL1411 Windows 10 Base/Mac Base 99 FPI (Financial Performance Indicators) 2011 Google Earth Pro 7.3.2 Kinovea 0.87 MegaStats 10.2.1 PSPP 1.2 Read & Write 11.5.7 Zotero Connector (Chrome Extension) Library Loaner Laptops Library Service Desk EL1230 Windows 10 Base 98 Business) Google Earth Pro 7.3.2 Kinovea 0.87 MegaStats 10.2.1 Mendeley Desktop MirrorOp Sender PSPP 1.2 Read & Write 11.5.7 RStudio # of Department Room AppName Computers Library -

Debian Java Insights and Challenges
Debian Java Insights and challenges Markus Koschany FOSDEM 19 Brussels / Belgium February, 3rd 2019 Markus Koschany Debian Java: Insights and challenges FOSDEM 19 1/7 The importance of Java Source / binary packages maintained by the Java team: 1033 / 1644 (+10,84 % since Debian 9) Source lines of code (Rank 3) : 90,744,884 Popcon value OpenJDK-8 (installed): 78104 / 199604 Popular libraries: apache-commons-*, javamail, xerces2, bouncycastle Popular applications: libreoffice, netbeans, pdfsam, sweethome3d, freeplane, freecol Frequently used for scientific research, medical care and bioinformatics. Markus Koschany Debian Java: Insights and challenges FOSDEM 19 2/7 What is new in Buster? OpenJDK 11 transition completed. (required more than 400! package updates) Build tools: Ant and Maven are up-to-date. Gradle is stuck at the last pre-Kotlin version. SBT is still being worked on. JVM languages: Groovy 2.14, Scala 2.11.12 (2.12 requires SBT), Clojure 1.9, Jython 1.7.1, JRuby 9.1.13 (?), Kotlin is wanted but hard to bootstrap. IDE: Eclipse is gone (lack of maintainers) but there is Netbeans 10 now. Server: Jetty 9.4 and Tomcat 9 fully up-to-date with systemd integration. Reproducibility rate is at 85% (was 75%) https://reproducible-builds.org Markus Koschany Debian Java: Insights and challenges FOSDEM 19 3/7 Packaging challenges “None of the packages in the main archive area require software outside of that area to function” Internet downloads at build time are not allowed No prebuilt jar or class files! Java is version-centric. Every developer has to update every dependency themself in this model. -

Manual De Freeplane
Manual de Freeplane – Luis Javier González Caballero [email protected] 31 de enero de 2019 Acerca del autor Luis Javier González Caballero es un Técnico en Informática con amplia experiencia en soporte a usuarios. Ha realizado algu- nos trabajos de programación, fundamentalmente en Python. Es Ingeniero Técnico Industrial por la Universidad de León e Inge- niero en Informática por la Universidad de Educación Nacional a Distancia. Es una persona activa con una gran capacidad de aprendizaje, lo que le permite ponerse al día rápidamente en los proyectos en los que se involucra. Aparte de su carrera profesional colabora con numerosas orga- nizaciones sin ánimo de lucro y proyectos libres y es amante de los animales. Vive en León, una pequeña ciudad en el noroeste de España con su familia. [email protected] 1 Índice general I Freeplane básico8 1. Mapas mentales 9 1.1. Introducción............................................9 1.2. La sociedad de la información..................................9 1.3. El cerebro............................................. 10 1.4. Procesando la información.................................... 11 1.5. Elaboración de los mapas mentales............................... 11 1.6. Ejemplos............................................. 12 1.6.1. Mapas al estilo de Tony Buzan............................. 12 1.6.2. Mapa de Gestión..................................... 13 1.6.3. Mapa circular....................................... 15 2. Comenzando con Freeplane 17 2.1. Instalación............................................ 17 2.2. La ventana de la aplicación................................... 17 2.3. Creando el primer mapa..................................... 19 2.4. Uso del mapa........................................... 20 2.5. Elementos de un mapa...................................... 22 2.6. Elementos de un nodo...................................... 23 3. Personalizando nuestro mapa 25 3.1. El panel de formato....................................... 25 3.2. Modificando el texto del nodo................................. -

Snapshots of Open Source Project Management Software
International Journal of Economics, Commerce and Management United Kingdom ISSN 2348 0386 Vol. VIII, Issue 10, Oct 2020 http://ijecm.co.uk/ SNAPSHOTS OF OPEN SOURCE PROJECT MANAGEMENT SOFTWARE Balaji Janamanchi Associate Professor of Management Division of International Business and Technology Studies A.R. Sanchez Jr. School of Business, Texas A & M International University Laredo, Texas, United States of America [email protected] Abstract This study attempts to present snapshots of the features and usefulness of Open Source Software (OSS) for Project Management (PM). The objectives include understanding the PM- specific features such as budgeting project planning, project tracking, time tracking, collaboration, task management, resource management or portfolio management, file sharing and reporting, as well as OSS features viz., license type, programming language, OS version available, review and rating in impacting the number of downloads, and other such usage metrics. This study seeks to understand the availability and accessibility of Open Source Project Management software on the well-known large repository of open source software resources, viz., SourceForge. Limiting the search to “Project Management” as the key words, data for the top fifty OS applications ranked by the downloads is obtained and analyzed. Useful classification is developed to assist all stakeholders to understand the state of open source project management (OSPM) software on the SourceForge forum. Some updates in the ranking and popularity of software since -

Business Process Modeling
Saint-Petersburg State University Graduate School of Management Information Technologies in Management Department Tatiana A. Gavrilova DSc, PhD, Professor [email protected] Sofya V. Zhukova PhD, Associate Professor [email protected] Knowledge Engineering Workbook for E-portfolio (Version 1). Student’s name ________________________________ Group ________________________________ E-mail ________________________________ Spring Term 2010 2 Content Introduction Chapter 1. Methodical recommendations and examples for Assinment list 1 Chapter 2. Methodical recommendations and examples for Assinment list 2 Chapter 3. Lists 1 and 2 of personal assignments Chapter 4. Reading for the course Conclusion References Appendces Appendix 1. Mind mapping software Appendix 2. History of Computer science Appendix 3. Information Mapping Software Appendiix 4. Template for E-Portfolio (list 1) 3 Chapter 1 Methodic recommendations and examples 1.1. Intensional/extensional A rather large and especially useful portion of our active vocabularies is taken up by general terms, words or phrases that stand for whole groups of individual things sharing a common attribute. But there are two distinct ways of thinking about the meaning of any such term. The extensional of a general term is just the collection of individual things to which it is correctly applied. Thus, the extension of the word "chair" includes every chair that is (or ever has been or ever will be) in the world. The intension of a general term, on the other hand, is the set of features which are shared by everything to which it applies. Thus, the intensional of the word "chair" is (something like) "a piece of furniture designed to be sat upon by one person at a time." Fig. -

List of New Applications Added in ARL #2543
List of New Applications Added in ARL #2543 Application Name Publisher 1-4a Rename 1.56 1-4a.com SyncBackFree 3.2 2BrightSparks SyncBackFree 7.6 2BrightSparks SyncBackFree 9.3 2BrightSparks IP Eye 1.4 2N Technologies 3DxPair 2.0 3Dconnexion 3DxSoftware 3.18 SpacePilot Pro 3Dconnexion 3DxCollage 3Dconnexion 3DxNumpad 3Dconnexion 3DxSoftware 3.17 3Dconnexion Picture Viewer 1.5 3Dconnexion 3DxSoftware 3.16 3Dconnexion 3DxPair 2.1 3Dconnexion 3DxTrainer 3.2 3Dconnexion Core Grouping Software Client 2017.0 3M Core Grouping Software Client 2017.1 3M 360 Encompass System Update Tool 2.1 3M EARfit 3M Core Grouping Software 2017.1 3M 3M Client 7.3 3M Core Grouping Software Client 2018.1 3M Core Grouping Software 2017.3 3M Core Grouping Software 2018.1 3M Core Grouping Software Client 2018.0 3M 360 Encompass System WebCvConfig 30.2 3M Core Grouping Software 2018.0 3M CS Encryption Utility 2.0 3M Core Grouping Software 2017.0 3M Core Grouping Software 2017.2 3M 3M Client 7.2 3M 360 Encompass System WebCvConfig 18.2 3M 360 Encompass System WebCvConfig 24.1 3M Core Grouping Software Client 2018.2 3M WinAppLink 1.0 3M 360 Encompass System WebCvConfig 22.2 3M Core Grouping Software 2018.2 3M Core Grouping Software Client 2017.2 3M Core Grouping Software Client 2017.3 3M 360 Encompass System Application Services 3.3 3M 360 Encompass System 3M 3D Lift Plan A1A Software AAONECat32 4.0 AAON StriePlan ABB MineScape SDK 5.12 ABB MineScape Help 5.12 ABB HostsMan 3.2 abelhadigital PC Gateway ABM Sensor Technology HAZUS ABS Consulting Custodium Plugin 1.1 Acepta -

Manual Freeplane.Pdf
Manual de Freeplane Luis Javier González Caballero [email protected] 13 de noviembre de 2018 Índice general 1. Mapas mentales 5 1.1. Introducción............................................5 1.2. La sociedad de la información..................................5 1.3. El cerebro.............................................6 1.4. Uso................................................6 1.5. Elaboración de los mapas mentales...............................7 1.6. Ejemplos.............................................7 1.6.1. Mapas al estilo de Tony Buzan.............................8 1.6.2. Mapa de Gestión.....................................9 1.6.3. Mapa circular....................................... 11 2. Comenzando con Freeplane 13 2.1. Instalación............................................ 13 2.2. La ventana de la aplicación................................... 13 2.3. Creando el primer mapa..................................... 15 2.4. Uso del mapa........................................... 16 2.5. Elementos de un mapa...................................... 17 2.6. Elementos de un nodo...................................... 18 3. Operaciones avanzadas 20 3.1. Insertando imágenes....................................... 20 3.1.1. Imagen externa...................................... 20 3.1.2. Imagen interna...................................... 20 3.1.3. Imagen del fondo del mapa............................... 20 3.2. Formatos manuales........................................ 21 3.2.1. Formatos básicos..................................... 21 3.2.2. Formatos -

Materiały Dydaktyczne Zchidch up Opracowanie – Dr Małgorzata
Materiały dydaktyczne ZChiDCh UP MAPY MYŚLI Wstęp W poniższym rozdziale omówiono mapy myśli i pojęć oraz jakie są różnice pomiędzy nimi a co jest wspólne, jak je tworzyć i do czego mogą być stosowane. Zestawiono w nim listę programów komputerowych do tworzenia map oraz pokrótce opisano kilka programów komputerowych, które pozwalają na łatwe i szybkie tworzenie map myśli i pojęć. Opisano jak w poszczególnych programach rozpocząć pracę nad mapą a także podano linki do stron Internetowych z samoczkami (tutorialami). Definicja terminów Dwie definicje, które w najlepszy sposób opisują czym są mapy myśli i pojęć to: Mapy myśli to rewolucyjna metoda błyskawicznego, graficznego notowania wszelkiego rodzaju informacji, wspomagająca twórcze myślenie. Technika ta ma umożliwić jej użytkownikom efektywniejsze wykorzystanie możliwości swojego mózgu, zmuszając do współpracy obie półkule mózgowe, rozwijając zdolności twórcze oraz wspomagając kreatywne myślenie. Pomaga w zapisywaniu, porządkowaniu i zapamiętywaniu informacji głównie osobom o modalności wzrokowej. Jest to metoda stosunkowo młoda, została opracowana przez Tony’ego i Barry’ego Buzana. (W Polsce popularna książka opisująca ta metodę Tony Buzana to „Mapy myśli”, 2006). Zasady tworzenia map myśli: w środku zapisujemy centralne pojęcie, którego ma dotyczyć mapa, naokoło centralnego pojęcia rysuje się od kilku do kilkunastu pojęć głównych, które odnoszą się do środkowego pojęcia. Następne podgałęzie mają znowu od kilku do kilkunastu pojęć odnoszących się do sąsiadujących pojęć. Mapy myśli stosuje się do robienia notatek, rozwiązywanie problemów, planowania. Mapy myśli odzwierciedlają nasz indywidualny tok rozumowania i nasze indywidualne skojarzenia dlatego też nie można ich oceniać! Każda narysowana mapa myśli jest poprawna. Mapy Pojęć są dwuwymiarowymi reprezentacjami pojęć i ich wzajemnych relacji ze sobą. -

OSINT Handbook September 2020
OPEN SOURCE INTELLIGENCE TOOLS AND RESOURCES HANDBOOK 2020 OPEN SOURCE INTELLIGENCE TOOLS AND RESOURCES HANDBOOK 2020 Aleksandra Bielska Noa Rebecca Kurz, Yves Baumgartner, Vytenis Benetis 2 Foreword I am delighted to share with you the 2020 edition of the OSINT Tools and Resources Handbook. Once again, the Handbook has been revised and updated to reflect the evolution of this discipline, and the many strategic, operational and technical challenges OSINT practitioners have to grapple with. Given the speed of change on the web, some might question the wisdom of pulling together such a resource. What’s wrong with the Top 10 tools, or the Top 100? There are only so many resources one can bookmark after all. Such arguments are not without merit. My fear, however, is that they are also shortsighted. I offer four reasons why. To begin, a shortlist betrays the widening spectrum of OSINT practice. Whereas OSINT was once the preserve of analysts working in national security, it now embraces a growing class of professionals in fields as diverse as journalism, cybersecurity, investment research, crisis management and human rights. A limited toolkit can never satisfy all of these constituencies. Second, a good OSINT practitioner is someone who is comfortable working with different tools, sources and collection strategies. The temptation toward narrow specialisation in OSINT is one that has to be resisted. Why? Because no research task is ever as tidy as the customer’s requirements are likely to suggest. Third, is the inevitable realisation that good tool awareness is equivalent to good source awareness. Indeed, the right tool can determine whether you harvest the right information. -

Digital Mind Mapping Software: a New Horizon in the Modern Teaching- Learning Strategy Dipak Bhattacharya1*, Ramakanta Mohalik2
Journal of Advances in Education and Philosophy Abbreviated Key Title: J Adv Educ Philos ISSN 2523-2665 (Print) |ISSN 2523-2223 (Online) Scholars Middle East Publishers, Dubai, United Arab Emirates Journal homepage: https://saudijournals.com/jaep Review Article Digital Mind Mapping Software: A New Horizon in the Modern Teaching- Learning Strategy Dipak Bhattacharya1*, Ramakanta Mohalik2 1Ph.D. Scholar, Department of Education, Regional Institute of Education, NCERT, Bhubaneswar, India 2Professor, Department of Education, Regional Institute of Education, NCERT, Bhubaneswar, India DOI: 10.36348/jaep.2020.v04i10.001 | Received: 22.09.2020 | Accepted: 30.09.2020 | Published: 03.10.2020 *Corresponding author: Dipak Bhattacharya Abstract Digital mind mapping is a unique method which improves productivity by helping to build and analyze ideas, and facilitates information structuring and retrieval. Educators and learners can use different types of software to create digital mind map for teaching learning. The objectives of the paper are: to describe about different types of software used in creating digital mind maps; to highlight the process of digital mind map development through software and to provide an overview of benefits and usefulness of digital mind mapping software. It’s a review-based study. Articles published in various leading journals, conference proceedings, online materials have been referred in the present article. The first part of the paper describes concept of digital mind mapping software. Second part of the paper provides a brief description about different software used in creating digital mind maps. The third part of the article explains about the process of digital mind map creation through software. The last part of the paper elaborates benefits and usefulness of digital mind mapping software. -

Business Process Modeling
Saint-Petersburg State University Graduate School of Management Information Technologies in Management Department Knowledge Engineering Workbook for E-portfolio (V. 2) Tatiana A. Gavrilova DSc, PhD, Professor [email protected] Sofya V. Zhukova PhD, Associate Professor [email protected] 2010 2 Content Introduction Chapter 1. Methodical recommendations and examples for Assignment list 1 Chapter 2. Methodical recommendations and examples for Assignment list 2 Chapter 3. Lists 1 and 2 of personal assignments Chapter 4. Reading for the course Conclusion References Appendices Appendix 1. Mind mapping software Appendix 2. History of Computer science Appendix 3. Information Mapping Software Appendiix 4. Text to create Genealogy 3 Introduction This course introduces students to the practical application of intelligent technologies into the different subject domains (business, social, economical, educational, human, etc.). It will give students insight and experience in key issues of data and knowledge processing in companies. In class and discussion sections, students will be able to discuss issues and tradeoffs in visual knowledge modeling, and invent and evaluate different alternative methods and solutions to better knowledge representation and understanding, sharing and transfer. It is targeted at managers of different level, involved in any kind of knowledge work. Lecture course’ goals are focused at using the results of multidisciplinary research in knowledge engineering, data structuring and cognitive sciences into information processing and modern management. The hand-on practice will be targeted at e-doodling with Mind Manager and Cmap software tools. The class features lectures, discussions, short tests and, students will have 20 hand-on practices (or assignments) using mind-mapping and concept mapping software. -
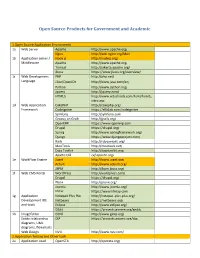
Open Source Products for Government and Academic
Open Source Products for Government and Academic 1.Open Source Application Environment 1a Web Server Apache http://www.apache.org/ Nginx http://wiki.nginx.org/Main 1b Application server / Node.js http://nodejs.org/ Middleware Apache http://www.apache.org/ Tomcat http://jakarta.apache.org/ Jboss https://www.jboss.org/overview/ 1c Web Development PHP http://php.net/ Language J2ee/OpenJDK http://www.java.com/en/ Python http://www.python.org/ Jquery http://jquery.com/ HTML5 http://www.w3schools.com/html/html5_ intro.asp 1d Web Application CakePHP http://cakephp.org/ Framework CodeIgniter https://ellislab.com/codeigniter Symfony http://symfony.com Groovy on Grails http://grails.org/ OpenERP https://www.openerp.com Drupal https://drupal.org/ Spring http://www.springframework.org/ Django https://www.djangoproject.com/ Rails http://rubyonrails.org/ MooTools http://mootools.net/ Dojo Toolkit http://dojotoolkit.org/ Apache CXF cxf.apache.org/ 1e WorkFlow Engine Joget http://www.joget.org/ Activiti http://www.activiti.org/ JBPM http://jbpm.jboss.org/ 1f Web CMS Portal WordPress http://wordpress.com/ Drupal https://drupal.org/ Plone http://plone.org/ Joomla http://www.joomla.org/ Liferay https://www.liferay.com 1g Application Notepad Plus Plus http://notepad-plus-plus.org/ Development IDE Netbeans https://netbeans.org/ and tools Eclipse http://www.eclipse.org/ GEdit https://projects.gnome.org/gedit/ 1h ImageEditor GIMP http://www.gimp.org/ Entity relationship DIA https://projects.gnome.org/dia/ diagrams, UML diagrams, flowcharts Web Design NVU http://www.nvu.com/