Data Curation Issues in the Chemical Sciences
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Carbon Dioxide Adsorption by Metal Organic Frameworks (Synthesis, Testing and Modeling)
Western University Scholarship@Western Electronic Thesis and Dissertation Repository 8-8-2013 12:00 AM Carbon Dioxide Adsorption by Metal Organic Frameworks (Synthesis, Testing and Modeling) Rana Sabouni The University of Western Ontario Supervisor Prof. Sohrab Rohani The University of Western Ontario Graduate Program in Chemical and Biochemical Engineering A thesis submitted in partial fulfillment of the equirr ements for the degree in Doctor of Philosophy © Rana Sabouni 2013 Follow this and additional works at: https://ir.lib.uwo.ca/etd Part of the Other Chemical Engineering Commons Recommended Citation Sabouni, Rana, "Carbon Dioxide Adsorption by Metal Organic Frameworks (Synthesis, Testing and Modeling)" (2013). Electronic Thesis and Dissertation Repository. 1472. https://ir.lib.uwo.ca/etd/1472 This Dissertation/Thesis is brought to you for free and open access by Scholarship@Western. It has been accepted for inclusion in Electronic Thesis and Dissertation Repository by an authorized administrator of Scholarship@Western. For more information, please contact [email protected]. i CARBON DIOXIDE ADSORPTION BY METAL ORGANIC FRAMEWORKS (SYNTHESIS, TESTING AND MODELING) (Thesis format: Integrated Article) by Rana Sabouni Graduate Program in Chemical and Biochemical Engineering A thesis submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy The School of Graduate and Postdoctoral Studies The University of Western Ontario London, Ontario, Canada Rana Sabouni 2013 ABSTRACT It is essential to capture carbon dioxide from flue gas because it is considered one of the main causes of global warming. Several materials and various methods have been reported for the CO2 capturing including adsorption onto zeolites, porous membranes, and absorption in amine solutions. -

The Royal Society of Chemistry Turns Its Focus on Researchers with Better Search and Measurement Tools
The Royal Society of Chemistry turns its focus on researchers with better search and measurement tools The Royal Society of Chemistry offers a publishing platform providing access to over a million chemical science articles, book chapters and abstracts. Like many publishers of high quality peer-reviewed content, they are under pressure from their community to innovate quickly and harness digital technology in new ways that add value, simplicity and easier access to the research workflow. About Will Russell is responsible for some of the new technical developments • pubs.rsc.org at the Royal Society of Chemistry. “Although we do a lot of in-house • rsc.org development, we need to understand where developments can be • Location: Cambridge UK with improved by working with partners,” he says. “I really believe in the additional editorial teams in Beijing, benefit of strategic technology partnerships with an external partner. China, Bangalore India and There is the speed of getting a key utility to the market and this offers Washington D.C. USA us a tremendous business advantage.” • Scientific publisher of high-impact journals and books “We have journals going back to 1841,” he says. “We started migrating People print content online in the late 1990s. Our biggest challenge now is how • Will Russell we will deliver content in the future in the most useful way for the Business Relationship Manager researcher.” Goals Will pinpoints a way forward. “There are new opportunities presented • Embrace new technology to remain by open science and alternative metrics, and increasing importance competitive against innovative attached to data and open data,” he says. -

New Journal and Database Subscriptions – 2012 -2013
NEW JOURNAL AND DATABASE SUBSCRIPTIONS – 2012 -2013 New Journals Afterall: A Journal of Art, Context and Enquiry American Biology Teacher American Journal of Bioethics American Political Thought Annals of Tourism Research Art Documentation Biodiversity and Conservation Biomaterials Science BioScience Boom: A Journal of California California Archaeology California Management Review Catalysis Science & Technology Chemical Hazards in Industry China Journal Classical Antiquity Classical Philology Crime and Justice Critical Review of International Social and Political Philosophy Education in Chemistry Educational Technology Research Development Elephant Ethics Federal Sentencing Reporter Food & Function Frankie Gastronomica: The Journal of Food and Culture Haaretz Historical Studies in the Natural Sciences HOPOS: The Journal of the International Society for the History of Philosophy of Science Huntington Library Quarterly Indian Country Today Indonesia Journal Information, Communication & Society Innovation Policy and the Economy Integrative Biology Issues in Environmental Science and Technology Journal of Applied Remote Sensing Journal of Digital Media Management Journal of Empirical Research on Human Research Ethics Journal of Environmental Studies and Sciences Journal of Human Capital Journal of Labor Economics Journal of Leisure Research Journal of Micro/Nanolithography, MEMS, and MOEMS Journal of Modern History Journal of Nanophotonics Journal of North African Studies Journal of Palestine Studies Journal of Photonics for Energy Journal -

RSC Gold 2015 Flyer.Pdf
RSC Gold Want access to full content from the world’s leading chemistry society? Including regular new material and an Archive dating back to 1841? Caltech’s RSC Gold Plus voucher codes to publish package subscription has been a very Open Access (OA) free of charge? welcome development ... I am very appreciative of the RSC Gold is the Royal Society of Chemistry’s general excellence of articles in the RSC premium package comprising 41 international research journals, evidenced by strong journals, literature updating services and impact factors and magazines that will meet the needs of all your increases in local download statistics. end-users. And the accompanying Gold for Gold Dana L. Roth OA voucher codes ensure maximum visibility for Chemistry Librarian your institution’s quality research. Caltech, USA Take a look inside to see exactly what you get www.rsc.org/gold RSC Gold includes a wealth of quality RSC journal, database and magazine content that is all available online. Journals Natural Product Reports Analyst New Journal of Chemistry Analytical Methods Organic & Biomolecular Chemistry Biomaterials Science Photochemical & Photobiological Sciences Catalysis Science & Technology Physical Chemistry Chemical Physics (PCCP) Chemical Communications Polymer Chemistry Chemical Science* RSC Advances Chemical Society Reviews Soft Matter CrystEngComm Toxicology Research Dalton Transactions Energy & Environmental Science B a c k fi l e Environmental Science: Nano** RSC Journals Archive 1841-2007 lease Environmental Science: Processes & Impacts -

Publishing Price List 2016
Publishing Price List 2016 Royal Society of Chemistry Collections for 2016 RSC GOLD INCLUDES: Key Royal Society of Chemistry online Price on application ONLINE ONLY† journal, database and magazine content, plus a EMAIL [email protected] book series. or contact your Account Manager PRICES JOURNALS ARCHIVE ONLINE ONLY† RSC Journals Archive Outright Purchase (1841 – 2007) • £41,097 • $72,615 RSC Journals Archive Outright Purchase (2005 – 2007) • £4,867 • $8,271 RSC Journals Archive Lease (1841 – 2007) • £7,408 • $13,133 PRICES RSC Journals Archive Hosting Fee • £819 • $1,340 THE HISTORICAL COLLECTION INCLUDES: Price on application ONLINE ONLY† • Society Publications (1949 – 2012) EMAIL [email protected] • Society Minutes (1841 – 1966) or contact your Account Manager • Historical Papers (1505 – 1991) PRICES CORE CHEMISTRY COLLECTION INCLUDES: • Chemical Communications • Dalton Transactions • Journal of Materials Chemistry A, B & C • New Journal of Chemistry PRINT & ONLINE† ONLINE ONLY† • Organic & Biomolecular Chemistry • • • Physical Chemistry Chemical Physics £19,685 £18,701 • RSC Advances (online only) • $36,814 • $34,973 PRICES GENERAL CHEMISTRY COLLECTION INCLUDES: • Chemical Communications • Chemical Society Reviews PRINT & ONLINE† ONLINE ONLY† • Chemistry World • £8,360 • £7,942 • New Journal of Chemistry PRICES • $13,685 • $13,244 • RSC Advances (online only) ANALYTICAL SCIENCE COLLECTION INCLUDES: • Analyst • Analytical Abstracts (online only) • Analytical Methods PRINT & ONLINE† ONLINE ONLY† • Environmental Science: Processes & Impacts • -

Journal Automatic Opt-In Unknown When Available After Acceptance
Journal Automatic Opt-In Unknown When Available After Acceptance American Chemical Society Accounts of Chemical Research X 30 minutes - 24 hours ACS Applied Materials & Interfaces X 30 minutes - 24 hours ACS Biomaterials Science & Engineering X 30 minutes - 24 hours ACS Catalysis X 30 minutes - 24 hours ACS Chemical Biology X 30 minutes - 24 hours ACS Chemical Neuroscience X 30 minutes - 24 hours ACS Combinatorial Science X 30 minutes - 24 hours ACS Infectious Diseases X 30 minutes - 24 hours ACS Macro Letters X 30 minutes - 24 hours ACS Medicinal Chemistry Letters X 30 minutes - 24 hours ACS Nano X 30 minutes - 24 hours ACS Photonics X 30 minutes - 24 hours ACS Sustainable Chemistry & Engineering X 30 minutes - 24 hours ACS Symposium Series X 30 minutes - 24 hours ACS Synthetic Biology X 30 minutes - 24 hours Advances in Chemistry X 30 minutes - 24 hours Analytical Chemistry X 30 minutes - 24 hours Biochemistry X 30 minutes - 24 hours Bioconjugate Chemistry X 30 minutes - 24 hours Biomacromolecules X 30 minutes - 24 hours Biotechnology Progress X 30 minutes - 24 hours Chemical & Engineering New Archives X 30 minutes - 24 hours C&EN Online X 30 minutes - 24 hours Chemical Research in Toxicology X 30 minutes - 24 hours Chemical Reviews X 30 minutes - 24 hours Chemistry of Materials X 30 minutes - 24 hours Inorganic Chemistry X 30 minutes - 24 hours Journal of the American Chemical Society X 30 minutes - 24 hours Journal of Chemical & Engineering Data X 30 minutes - 24 hours Journal of Chemical Information & Modeling X 30 minutes - 24 hours -

Chemical Society Reviews REVIEW
Please do not adjust margins Chemical Society Reviews REVIEW Aerosol processing: a wind of innovation in the field of advanced heterogeneous catalysts a, a b c Received 00th January 20xx, Damien P. Debecker, * Solène Le Bras, Cédric Boissière, Alexandra Chaumonnot, Clément Accepted 00th January 20xx Sanchezb* DOI: 10.1039/x0xx00000x Aerosol processing is long known and implemented industrially to obtain various types of divided materials and nanomaterials. The atomisation of a liquid solution or suspension produces a mist of aerosol droplets which can then be www.rsc.org/ transformed via a diversity of processes including spray-drying, spray pyrolysis, flame spray pyrolysis, thermal decomposition, micronisation, gas atomisation, etc. The attractive technical features of these aerosol processes make them highly interesting for the continuous, large scale, and tailored production of heterogeneous catalysts. Indeed, during aerosol processing, each liquid droplet undergoes well-controlled physical and chemical transformations, allowing for example to dry and aggregate pre-existing solid particles or to synthesise new micro- or nanoparticles from mixtures of molecular or colloidal precursors. In the last two decades, more advanced reactive aerosol processes have emerged as innovative means to synthesise tailored-made nanomaterials with tunable surface properties, textures, compositions, etc. In particular, the “aerosol-assisted sol-gel” process (AASG) has demonstrated tremendous potential for the preparation of high-performance heterogeneous catalysts. The method is mainly based on the low-cost, scalable, and environmentally benign sol-gel chemistry process, often coupled with the evaporation-induced self-assembly (EISA) concept. It allows producing micronic or submicronic, inorganic or hybrid organic-inorganic particles bearing tuneable and calibrated porous structures at different scale. -

GUT RSC Journals List
SCHEDULE A Publisher Content Section A Customer has access to the electronic versions of the following journals via an External route: Access Post - Copyright Journals E-ISSN years cancellation Owner* during Term access Analyst 1364-5528 2008-2018 2012-2018 RSC Analytical Methods 1 1759-9679 2009-2018 2012-2018 RSC Annual Reports on the Progress of Chemistry, A 1460-4760 2008-2013 2012-2013 RSC B 1460 4779 2008-2013 2012-2013 RSC C 1460-4787 2008-2013 2012-2013 RSC Biomaterials Science 1 2047-4849 2013-2018 2016-2018 RSC Catalysis Science & Technology 1 2044-4761 2011-2018 2013-2018 RSC Chemical Communications 1364-548X 2008-2018 2012-2018 RSC Chemical Science 1, 2 2041-6539 2010-2014 2012-2014 RSC Chemical Society Reviews 1460-4744 2008-2018 2012-2018 RSC Chemistry World 1749-5318 2012-2016 2012-2016 RSC CrystEngComm 1466-8033 2008-2018 2012-2018 RSC Dalton Transactions 1477-9234 2008-2018 2012-2018 RSC Education in Chemistry 1749-5326 2012-2016 2012-2016 RSC Energy & Environmental Science 1 1754-5706 2008-2018 2012-2018 RSC Environmental Science: Nano 1 2051-8161 2014-2018 2016-2018 RSC Environmental Science: Processes & Impacts including 2050-7895 2013-2018 2013-2018 RSC Journal of Environmental Monitoring (1464-0333) 2008-2012 2012 Environmental Science: Water Research & Technology 1 2053-1419 2015-2018 2017-2018 RSC Faraday Discussions 1364-5498 2008-2018 2012-2018 RSC Food & Function 1 2042-650X 2010-2018 2012-2018 RSC Green Chemistry 1463-9270 2008-2018 2012-2018 RSC Inorganic Chemistry Frontiers 1 2052-1553 2014-2018 2017-2018 -
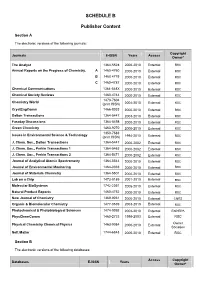
SCHEDULE B Publisher Content
SCHEDULE B Publisher Content Section A The electronic versions of the following journals: Copyright Journals E-ISSN Years Access Owner* The Analyst 1364-5528 2000-2010 External RSC Annual Reports on the Progress of Chemistry, A 1460-4760 2000-2010 External RSC B 1460 4779 2000-2010 External RSC C 1460-4787 2000-2010 External RSC Chemical Communications 1364-548X 2000-2010 External RSC Chemical Society Reviews 1460-4744 2000-2010 External RSC 1473-7604 Chemistry World (print ISSN) 2004-2010 External RSC CrystEngComm 1466-8033 2000-2010 External RSC Dalton Transactions 1364-5447 2003-2010 External RSC Faraday Discussions 1364-5498 2000-2010 External RSC Green Chemistry 1463-9270 2000-2010 External RSC 1350-7583 Issues in Environmental Science & Technology (print ISSN) 1994-2010 External RSC J. Chem. Soc., Dalton Transactions 1364-5447 2000-2002 External RSC J. Chem. Soc., Perkin Transactions 1 1364-5463 2000-2002 External RSC J. Chem. Soc., Perkin Transactions 2 1364-5471 2000-2002 External RSC Journal of Analytical Atomic Spectrometry 1364-5544 2000-2010 External RSC Journal of Environmental Monitoring 1464-0333 2000-2010 External RSC Journal of Materials Chemistry 1364-5501 2000-2010 External RSC Lab on a Chip 1473-0189 2001-2010 External RSC Molecular BioSystems 1742-2051 2005-2010 External RSC Natural Product Reports 1460-4752 2000-2010 External RSC New Journal of Chemistry 1369-9261 2000-2010 External CNRS Organic & Biomolecular Chemistry 1477-0539 2003-2010 External RSC Photochemical & Photobiological Sciences 1474-9092 2002-2010 -

Alexander Ruf Dissertation
TECHNISCHE UNIVERSITÄT MÜNCHEN Previously unknown organomagnesium compounds in astrochemical context Alexander Ruf Dissertation TECHNISCHE UNIVERSITÄT MÜNCHEN Fakultät Wissenschaftszentrum Weihenstephan für Ernährung, Landnutzung und Umwelt Lehrstuhl für Analytische Lebensmittelchemie Previously unknown organomagnesium compounds in astrochemical context Alexander Ruf Vollständiger Abdruck der von der Fakultät Wissenschaftszentrum Weihenstephan für Ernährung, Landnutzung und Umwelt der Technischen Universität München zur Erlangung des akademischen Grades eines Doktors der Naturwissenschaften (Dr. rer. nat.) genehmigten Dissertation. Vorsitzender: Prof. Dr. Erwin Grill Prüfer der Dissertation: 1. apl. Prof. Dr. Philippe Schmitt-Kopplin 2. Prof. Dr. Michael Rychlik 3. Prof. Eric Quirico, PhD (Université Grenoble Alpes) Die Dissertation wurde am 06.12.2017 bei der Technischen Universität München ein- gereicht und durch die Fakultät Wissenschaftszentrum Weihenstephan für Ernährung, Landnutzung und Umwelt am 18.01.2018 angenommen. Do we feel less open-minded, the more open-minded we are? A tribute to sensitivity and resolution... Acknowledgments This work has been prepared at the Helmholtz Zentrum München in the research unit Analytical BioGeoChemistry of apl. Prof. Dr. Philippe Schmitt-Kopplin, in collaboration with the Chair of Analytical Food Chemistry at the Technical Uni- versity of Munich. In the course of these years, I have relied on the courtesy and support of many to which I am grateful. The success of this PhD thesis would not have been possible without help and support of many wonderful people. First of all, I would like to thank the whole research group Analytical BioGeo- Chemistry for a very friendly, informal, and emancipated working atmosphere that formed day-by-day an enjoyable period of residence - it has felt like freedom! Small issues like having stimulating lunch discussions or going out into a bar, friendly peo- ple could be found herein to setting up a balance to scientific work. -

August 6, 2021 1 RICHARD L. BRUTCHEY, Ph.D. Professor Of
August 6, 2021 RICHARD L. BRUTCHEY, Ph.D. Professor of Chemistry University of Southern California Los Angeles, CA 90089-0744 Tel: (213) 821-2554 · E-mail: [email protected] · http://chem.usc.edu/~brutchey_group/Home.html Twitter: @BrutcheyGroup Professional Experience Professor of Chemistry, University of Southern California 2016-Present Joseph Meyerhoff Visiting Professor, Weizmann Institute of SCienCe 2022 ViCe Chair, Department of Chemistry, University of Southern California 2014-2021 AssoCiate Professor of Chemistry, University of Southern California 2013-2016 Visiting Professor of Chemistry, Swiss Federal Institute of TeChnology Zurich 2014 Assistant Professor of Chemistry, University of Southern California 2007-2013 Postdoctoral Fellow, UCSB-MIT-CalteCh Institute for Collaborative BioteChnologies 2005-2007 Graduate ResearCher, Department of Chemistry, UC Berkeley 2000-2005 Undergraduate ResearCher, Department of Chemistry, UC Irvine 1997-2000 Professional Preparation B.S., Chemistry (magna cum laude), UC Irvine 2000 Honors thesis title: “New Polymer Precursors from Polyhedral Oligosilsesquioxane Frameworks” Advisor: Professor Frank J. Feher Ph.D., Chemistry, UC Berkeley 2005 Thesis title: “Design and Synthesis of Heterogeneous Catalysts and Catalyst Supports Derived from Molecular Precursors” Advisor: Professor T. Don Tilley Postdoctoral Fellow, Materials, UC Santa Barbara 2005-2007 Advisor: Professor Daniel E. Morse Honors and Awards • Phi Kappa Phi Faculty Recognition Award, 2021 • ACS Inorganic Nanoscience Award, 2020 • RCSA -

Gas Hydrates in Sustainable Chemistry
Heriot-Watt University Research Gateway Gas hydrates in sustainable chemistry Citation for published version: Hassanpouryouzband, A, Joonaki, E, Vasheghani Farahani, M, Takeya, S, Ruppel, C, Yang, J, English, NJ, Schicks, JM, Edlmann, K, Mehrabian, H, Aman, ZM & Tohidi, B 2020, 'Gas hydrates in sustainable chemistry', Chemical Society Reviews, vol. 49, no. 15, pp. 5225-5309. https://doi.org/10.1039/c8cs00989a Digital Object Identifier (DOI): 10.1039/c8cs00989a Link: Link to publication record in Heriot-Watt Research Portal Document Version: Publisher's PDF, also known as Version of record Published In: Chemical Society Reviews General rights Copyright for the publications made accessible via Heriot-Watt Research Portal is retained by the author(s) and / or other copyright owners and it is a condition of accessing these publications that users recognise and abide by the legal requirements associated with these rights. Take down policy Heriot-Watt University has made every reasonable effort to ensure that the content in Heriot-Watt Research Portal complies with UK legislation. If you believe that the public display of this file breaches copyright please contact [email protected] providing details, and we will remove access to the work immediately and investigate your claim. Download date: 23. Sep. 2021 Chem Soc Rev View Article Online REVIEW ARTICLE View Journal Gas hydrates in sustainable chemistry abc ad Cite this: DOI: 10.1039/c8cs00989a Aliakbar Hassanpouryouzband, * Edris Joonaki,† Mehrdad Vasheghani Farahani,†a Satoshi Takeya, e Carolyn Ruppel,f Jinhai Yang, *a Niall J. English, g Judith M. Schicks,h Katriona Edlmann,b Hadi Mehrabian,c Zachary M.