Fixing the Curve: Improving Major League Baseball Pitch Classification with Model-Based Clustering
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Take Me out to the Old Yakyu
Take Me Out to the Old Yakyu You might never believe it when you look at American store shelves crowded with Japanese transistor radios, binoculars, and cameras, but ships also sail the other way, carrying American products and ideas to Japan. And at least one American game - baseball - has had amazing success there. Some ten million Japanese pay their way into the ball parks of the two six-team leagues every season, and uncounted other millions sit transfixed in front of TV sets, sloshing down their maki-zuski (raw-fish covered with rice and wrapped in seaweed) with good Japanese lager beer. The country is less than two-thirds the size of Texas, yet the Japanese boast forty stadiums, complete with lights for night ball, capable of staging major league ball games. Vacant lots of Japan are all one size - small - but kids play baseball on all of them. Profits are not a problem for Japanese baseball teams. Except for the Tokyo Giants, none of them makes money. Teams are all owned by corporations that use them for public relations, and the clubs are usually named not for cities but for the companies that control them. The Nankai Hawks and the Hankyu Braves both play in Osaka and are owned by railroads. Organized baseball has been part of the Japanese sports scene since the early 1930's. An American witnessing a Japanese game would certainly recognize it as baseball, but he would also realize that the game has acquired a distinct Japanese flavor, starting with the name of the game, which they call yakyu. -

National Pastime a REVIEW of BASEBALL HISTORY
THE National Pastime A REVIEW OF BASEBALL HISTORY CONTENTS The Chicago Cubs' College of Coaches Richard J. Puerzer ................. 3 Dizzy Dean, Brownie for a Day Ronnie Joyner. .................. .. 18 The '62 Mets Keith Olbermann ................ .. 23 Professional Baseball and Football Brian McKenna. ................ •.. 26 Wallace Goldsmith, Sports Cartoonist '.' . Ed Brackett ..................... .. 33 About the Boston Pilgrims Bill Nowlin. ..................... .. 40 Danny Gardella and the Reserve Clause David Mandell, ,................. .. 41 Bringing Home the Bacon Jacob Pomrenke ................. .. 45 "Why, They'll Bet on a Foul Ball" Warren Corbett. ................. .. 54 Clemente's Entry into Organized Baseball Stew Thornley. ................. 61 The Winning Team Rob Edelman. ................... .. 72 Fascinating Aspects About Detroit Tiger Uniform Numbers Herm Krabbenhoft. .............. .. 77 Crossing Red River: Spring Training in Texas Frank Jackson ................... .. 85 The Windowbreakers: The 1947 Giants Steve Treder. .................... .. 92 Marathon Men: Rube and Cy Go the Distance Dan O'Brien .................... .. 95 I'm a Faster Man Than You Are, Heinie Zim Richard A. Smiley. ............... .. 97 Twilight at Ebbets Field Rory Costello 104 Was Roy Cullenbine a Better Batter than Joe DiMaggio? Walter Dunn Tucker 110 The 1945 All-Star Game Bill Nowlin 111 The First Unknown Soldier Bob Bailey 115 This Is Your Sport on Cocaine Steve Beitler 119 Sound BITES Darryl Brock 123 Death in the Ohio State League Craig -

House-Ch-5-Flext Elbow Position at Release.Pdf
No one pitch, thrown properly, puts any more stress on the arm than any other pitch." Alan Blitzblau, Biomechanist The Pitching Edge crxratt....-rter hen I first heard Alan Blitzblau's remark on the previous page, 1 was more than a little skeptical. He had to be wrong. For many W years, I, like everyone else, had been telling parents of Little Leagu- ers that their youngsters should not throw curveballs, that curveballs were bad for a young arm. "Now wait a minute," I said, "you've just dis- counted what's been taught to young pitchers all over the United States. Are you sure?" "I'm sure," he responded. Alan sat down in front of the computer and showed me what he had discovered. From foot to throw- ing elbow, every pitch has exactly the same neuromuscular sequencing. The only body segments that change when a different type of pitch is thrown are the forearm, wrist, hand, and fingers, and they change only in angle. Arm speed is the same, the arm's external rotation into launch is the same, and pronation during deceleration is the same. It is the differ- ent angles of the forearm, wrist, hand, and fingers that alter velocity, rota- tion, and flight of a ball. He also revealed another surprise. The grip of a pitch is secondary to this angle, and all pitches leave the middle finger last! This was blasphemy I was stunned. But Alan wasn't finished. "Tom, for every one-eighth inch the middle finger misses the release point when the arm snaps straight at launch, it (the ball) is eight inches off location at home plate So throwing strikes means getting the middle finger to a quarter-sized spot on the middle of the baseball with every pitch." Wow! This chapter will dispel myths about what happens to pitcher's elbows, forearms, wrists, and fingers at release point, For years, pitching coaches (me included) taught pitchers to "pull" their glove-side elbow to their hip when throwing. -

Kannapolis Cannon Ballers (0-4) Vs
TODAY’S MATCH-UP KANNAPOLIS CANNON BALLERS (0-4) VS. DOWN EAST WOOD DUCKS (4-0) Kannapolis Wood Ducks 0-4 Record 4-0 0-4 Home -- -- Road 4-0 Saturday, May 8th, 2020 - Game #5- 6:00 p.m. - Atrium Health Ballpark, Kannapolis, N.C. L4 Streak W4 L4 Last 5 W4 LHP Bailey Horn (0-0, 0.00) vs. RHP Nick Krauth (0-0, 0.00) L4 Last 10 W4 ..219 Batting Avg. .246 4.75 ERA 3.25 Last Game .925 Fielding Pct. .979 ABOUT LAST NIGHT: The Down East Wood Ducks kept rolling to their 3.5 Runs/Game 6.5 fourth win in-a-row Friday night as they beat the Kannapolis Cannon Team R H E LOB 3 HR 2 13 RBI 18 Ballers 4-2. The Wood Ducks have started the 2021 season on fire as 17 BB 21 Down East 4 11 1 12 58 K 54 they continue to find clutch hits late in games to collect wins. 2 SB 9 Kannapolis 2 6 1 17 STANDINGS IF YOU AIN'T FIRST, YOU'RE LAST: Down East continued to get on WP: B. Anderson (1-0) LP: M. Thompson (0- 1) HR: Acu a (1) TOG: 2:47 ATT: 2,140 W/L PCT. GB the board early as they scored first in the top of the second against ñ North: Lynchburg 4-0 1.000 -- Kannapolis starter Matt Thompson. With one out, Keithron Moss sin- Delmarva 2-1 .667 1.5 gled and advanced to third on a single by José Rodriguez. -

Pitching Grips
Pitching Grips Pitch #1 – Four Seam Fastball The four seam fastball is a pitcher’s bread and butter pitch. It is the pitch you can throw the hardest and with the best control. Place your index and middle fingertips directly on the perpendicular seam of the baseball. The “horseshoe seam” should face into your ring finger of your throwing hand. Next, place your thumb directly beneath the baseball, resting on the smooth leather. Grip this pitch softly, like an egg, in your fingertips. A loose grip minimizes friction between your hand and the baseball. Less friction = more velocity. Pitch #2 – Change-up This pitch is important because: “hitting is timing and pitching is interrupting that timing.” Pitchers must throw a change-up to keep hitters honest, otherwise they will tee off on the fastball. Hold the ball deep in the palm. Circle around the ball with the hand. Use same mechanics as the fastball – except lengthen the stride and drag the back foot. BaseballTutorials.com 1 Pitch #3 – Cut Fastball While the four seam fastball is more or less a straight pitch, the cut fastball has late break toward the glove side of the pitcher. Start with a four-seam fastball grip, and move your top two fingers slightly off center. The arm motion and arm speed for the cutter are just like for a fastball. At the point of release, with the grip slightly off center and pressure from the middle finger, turn your wrist ever so lightly. This off center grip and slight turn of the wrist will result into a pitch with lots of velocity and a late downward break. -

Using Pitchf/X to Model the Dependence of Strikeout Rate on the Predictability of Pitch Sequences
Journal of Sports Analytics 3 (2017) 93–101 93 DOI 10.3233/JSA-170103 IOS Press Using PITCHf/x to model the dependence of strikeout rate on the predictability of pitch sequences Glenn Healey∗ and Shiyuan Zhao Electrical Engineering and Computer Science, University of California, Irvine, CA, USA Abstract. We develop a model for pitch sequencing in baseball that is defined by pitch-to-pitch correlation in location, velocity, and movement. The correlations quantify the average similarity of consecutive pitches and provide a measure of the batter’s ability to predict the properties of the upcoming pitch. We examine the characteristics of the model for a set of major league pitchers using PITCHf/x data for nearly three million pitches thrown over seven major league seasons. After partitioning the data according to batter handedness, we show that a pitcher’s correlations for velocity and movement are persistent from year-to-year. We also show that pitch-to-pitch correlations are significant in a model for pitcher strikeout rate and that a higher correlation, other factors being equal, is predictive of fewer strikeouts. This finding is consistent with experiments showing that swing errors by experienced batters tend to increase as the differences between the properties of consecutive pitches increase. We provide examples that demonstrate the role of pitch-to-pitch correlation in the strikeout rate model. Keywords: Baseball, pitch sequencing, strikeout rate, PITCHf/x, correlation 1. Introduction ball which alters its trajectory. Given the difficulty of the hitting task, batters can benefit from being The act of hitting a pitch in major league base- able to predict the characteristics of an upcoming ball places extraordinary demands on the batter’s pitch. -

Sinker Most Effective on the ADI and VMI Scale? by Clifton Neeley
When is the Sinker Most Effective on the ADI and VMI Scale? by Clifton Neeley www.baseballvmi.com Since we can divide MLB data into performance categories that show how much ball movement the pitcher had purely from the makeup of the air, we can see the pitcher’s performance against the ADI. We can also see the hitter’s performance when the ball is moving more and when the hitter is not used to the movement vs when he is comfortable in the climate. It gets very intriguing when we include different types of pitches within that same grid. You can do a similar study on the pitcher and hitter stats on our website, but you may glean some good information from our study on the “Pitch-Mix.” Sinker - Used (7%) League Wide Average Hit/Strike Rate For 2016 =11.02% "Reverse" pitcher throws the Sinker or Two-Seamer far more often than the traditional four-seamer The Sinker is another pitch, which if used in more than 20% of the total pitches thrown by the starting pitcher, identifies him as a Reverse Pitcher. If you note that the pitcher your hitting team or player is matched up against in today's or tomorrow's game is prone to throwing a high number of Sinkers, then he will be more successful against a High Plus VMI team than a High Minus VMI team with that pitch. A "Reverse" pitcher is one who throws a Sinker above 90 mph as one of his primary two pitches. So, a High Plus team will be more successful against a Tight Pitcher and a High Minus team will be more successful against a Reverse Pitcher. -
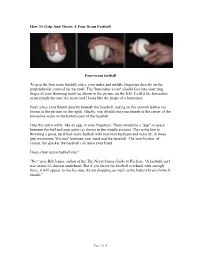
How to Grip and Throw a Four Seam Fastball
How To Grip And Throw A Four Seam Fastball Four-seam fastball To grip the four seam fastball, place your index and middle fingertips directly on the perpendicular seam of the baseball. The "horseshoe seam" should face into your ring finger of your throwing hand (as shown in the picture on the left). I call it the horseshoe seam simply because the seam itself looks like the shape of a horseshoe. Next, place your thumb directly beneath the baseball, resting on the smooth leather (as shown in the picture on the right). Ideally, you should rest your thumb in the center of the horseshoe seam on the bottom part of the baseball. Grip this pitch softly, like an egg, in your fingertips. There should be a "gap" or space between the ball and your palm (as shown in the middle picture). This is the key to throwing a good, hard four-seam fastball with maximal backspin and velocity: A loose grip minimizes "friction" between your hand and the baseball. The less friction, of course, the quicker the baseball can leave your hand. Does a four-seam fastball rise? "No," says Bill James, author of the The Neyer/James Guide to Pitchers. "A fastball can't rise unless it's thrown underhand. But if you throw the fastball overhand with enough force, it will appear to rise because it's not dropping as much as the batter's brain thinks it should." Page 1 of 10 How To Grip And Throw A Two Seam Fastball Two seam fastball A two seam fastball, much like a sinker or cutter (cut fastball), is gripped slightly tighter and deeper in the throwing-hand than the four-seam fastball. -

The Physics of Pitching in the Wind David Kagan
The Physics of Pitching In The Wind David Kagan Recently, I was sitting in front of the tube watching the Giants play the Phillies at Citizens Bank Park. In the top of the fifth, Cole Hamels fired a fastball. Gregor Blanco was barely able to foul it off. It was the fastest four-seamer Hamels had thrown all day inspiring Giants broadcaster Mike Krukow to comment, “One thing pitchers like, and you don’t see it very often in this ballpark, they like winds at their back. You know, wind at your back is just like a golfer with the wind at his back in the tee box. You feel like you can hit the ball farther. Well, the same thing for a pitcher. They think they can throw harder and you can.” Well Kruk (rhymes with “Duke”), I never made it very far playing baseball so I don’t really know what pitchers think or why they think it. Some coaches even claim pitchers are better off not thinking. However, what I do have to offer is the knowledge to examine the physics of pitching in the wind. Let me start by reviewing the forces that act on the ball on its journey from pitcher to catcher. Forces on a Pitched Baseball There are two things that exert forces on a pitch in flight. The gravitational force is exerted by Earth. This steady downward inescapable pull is highly structured and predictable. In contrast, the forces air exert on the ball are complex and subtle. They give rise to the beauty and nuance of pitching. -

Pitching Made Simple
Pitching Made Simple I. Today we will cover the following areas: i. Basic Mechanics ii. Debunking Myths iii. Grips/Pitches iv. Core Drills v. Feedback vi. Age appropriate content II. Basic Mechanics Balance Point *Lift to get to the balance point *Should be at least to 90 degrees *Head and chin should stay over your pivot/posting leg Separation and Landing *After you hit your “balance point,” get the ball out of your glove (“hand separation”) *Arm action should be long and loose (“thumb to thigh, ball to sky”) *Front-side direction (front foot, glove, and eyes simultaneously go to the target) *Angles of elbow/wrist in front arm should be the same as in the back arm at landing (“opposite and equal”) Acceleration toward the plate *Squeeze and swivel glove *Separate hips (hips go first, delivering the shoulders) *Firm front side (Glove stays fixed at the target as long as possible) *Take your chest to your glove Extension and finish *Release the ball in front of your stride foot *Momentum directly at the catcher (DO NOT fall off to the side) *Back foot is pulled/ripped off the rubber *Flat back, heel to sky *Eyes stay fixed on the target III. Debunking some common myths a. In order to throw harder, kids must push off the rubber. FALSE. Actually, the back foot is pulled off the rubber. b. You must pull down with your front elbow. FALSE. Actually, your front side stays firm and at the target. c. Kids must get their elbow up and throw over the top. -

A STATISTICAL ANALYSIS of RETALIATION PITCHES in MAJOR LEAGUE BASEBALL Peter Jurewicz Clemson University, [email protected]
Clemson University TigerPrints All Theses Theses 12-2013 CHIN MUSIC: A STATISTICAL ANALYSIS OF RETALIATION PITCHES IN MAJOR LEAGUE BASEBALL Peter Jurewicz Clemson University, [email protected] Follow this and additional works at: https://tigerprints.clemson.edu/all_theses Part of the Economics Commons Recommended Citation Jurewicz, Peter, "CHIN MUSIC: A STATISTICAL ANALYSIS OF RETALIATION PITCHES IN MAJOR LEAGUE BASEBALL" (2013). All Theses. 1793. https://tigerprints.clemson.edu/all_theses/1793 This Thesis is brought to you for free and open access by the Theses at TigerPrints. It has been accepted for inclusion in All Theses by an authorized administrator of TigerPrints. For more information, please contact [email protected]. CHIN MUSIC: A STATISTICAL ANALYSIS OF RETALIATION PITCHES IN MAJOR LEAGUE BASEBALL A Thesis Presented to the Graduate School of Clemson University In Partial Fulfillment of the Requirements for the Degree Master of Arts Economics By Peter Jurewicz December 2013 Accepted by: Dr. Raymond Sauer, Committee Chair Dr. Scott Baier Dr. Robert Tollison ABSTRACT This paper is focused on hit batsmen in Major League Baseball from the 2008 season through August 20th of the 2013 season. More specifically, this paper examines the characteristics of retaliation pitches and attempts to determine the intent of the pitcher. The paper also takes into account moral hazard and cost-benefit analysis of hitting an opposing batsman. There has been a vast amount of literature in economics with regard to hit batsmen in Major League Baseball. However, very few of these papers have been able to evaluate economic theories in Major League Baseball using Pitchf/x data. -

Applying Matching Equation to Pitch Selection in Major League Baseball
APPLYING MATCHING EQUATION TO PITCH SELECTION IN MAJOR LEAGUE BASEBALL __________________________________________________________________ A Thesis Submitted to the Temple University Graduate Board In Partial Fulfillment of the Requirements for the Degree Masters of Education in Applied Behavior Analysis __________________________________________________________________ David Dragone August 2018 Examining Committee Members: Donald Hantula, Ph.D., Thesis Advisor, Department of Psychology Matt Tincani, Ph. D., BCBA-D, Department of Education Amanda Guld Fisher, Ph. D., BCBA-D, College of Education ABSTRACT This study applied the generalized matching equation (GME) to pitch selection in MLB during the 2016 regular season. The GME was used to evaluate the pitch selection of 21 groups of pitchers as well as 144 individual pitchers. The GME described pitch selection well for four of the 21 pitching groups and 32 of the 144 individual pitchers. Of the remaining groups and individual pitchers, behavior may be explained by rule following behavior or be impacted by distant reinforcers such as salary. All 21 groups demonstrated a bias for fastballs as well as 119 of the 144 individual pitchers. The results extend the use of the GME to natural contexts and suggest an alternative view to evaluating pitchers. KEYWORDS: general matching theory, general matching equation, sports, baseball, reinforcement ii DEDICATION This study is dedicated to the countless number of people who have supported me throughout the years both in this degree and professionally. Thank you, to my wife, Jen, and Children, Aurora and Rose, who gave me the motivation to keep working through this process and seeing it through to the end. iii ACKNOWLEDGMENTS I would like to thank Dr.