Proposal for a Tamil Script Root Zone Label Generation Rule-Set (LGR)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

75 Characters Maximum
Kannada Script LGR Proposal Introduction, Current Analysis and Next Steps Dr. U.B. Pavanaja NBGP F2F Meeting, Colombo 14 December 2017 | 1 Agenda 1 2 3 Introduction to Repertoire Analysis Within Script Kannada Script Variants 4 5 6 Cross-Script WLE Rules Current Status and Variants Next Steps for Completion | 2 Introduction to Kannada Script Population – there are about 60 million speakers of Kannada language which uses Kannada script. Geographical area - Kannada is spoken predominantly by the people of Karnataka State of India. It is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad Languages written in Kannada script – Kannada, Tulu, Kodava (Coorgi), Konkani, Havyaka, Sanketi, Beary (byaari), Arebaase, Koraga | 3 Classification of Characters Swaras (vowels) Letter ಅ ಆ ಇ ಈ ಉ ಊ ಋ ಎ ಏ ಐ ಒ ಓ ಔ Vowel sign/ N/Aಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ matra Yogavahas In Kannada, all consonants Anusvara ಅಂ (vyanjanas) when written as ಕ (ka), ಖ (kha), ಗ (ga), etc. actually have a built-in vowel sign (matra) Visarga ಅಃ of vowel ಅ (a) in them. | 4 Classification of Characters Vargeeya vyanjana (structured consonants) voiceless voiceless aspirate voiced voiced aspirate nasal Velars ಕ ಖ ಗ ಘ ಙ Palatals ಚ ಛ ಜ ಝ ಞ Retroflex ಟ ಠ ಡ ಢ ಣ Dentals ತ ಥ ದ ಧ ನ Labials ಪ ಫ ಬ ಭ ಮ Avargeeya vyanjana (unstructured consonants) ಯ ರ ಱ (obsolete) ಲ ವ ಶ ಷ ಸ ಹ ಳ ೞ (obsolete) | 5 Repertoire Included-1 Sr. Unicode Glyph Character Name Unicode Indic Ref Widespread No. Code General Syllabic use ? Point Category Category [Yes/No] 1 0C82 ಂ KANNADA SIGN ANUSVARA Mc Anusvara Yes 2 0C83 ಂ KANNADA SIGN VISARGA Mc Visarga Yes 3 0C85 ಅ KANNADA LETTER A Lo Vowel Yes 4 0C86 ಆ KANNADA LETTER AA Lo Vowel Yes 5 0C87 ಇ KANNADA LETTER I Lo Vowel Yes 6 0C88 ಈ KANNADA LETTER II Lo Vowel Yes 7 0C89 ಉ KANNADA LETTER U Lo Vowel Yes 8 0C8A ಊ KANNADA LETTER UU Lo Vowel Yes KANNADA LETTER VOCALIC 9 0C8B ಋ R Lo Vowel Yes 10 0C8E ಎ KANNADA LETTER E Lo Vowel Yes | 6 Repertoire Included-2 Sr. -

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

“Lost in Translation”: a Study of the History of Sri Lankan Literature
Karunakaran / Lost in Translation “Lost in Translation”: A Study of the History of Sri Lankan Literature Shamila Karunakaran Abstract This paper provides an overview of the history of Sri Lankan literature from the ancient texts of the precolonial era to the English translations of postcolonial literature in the modern era. Sri Lanka’s book history is a cultural record of texts that contains “cultural heritage and incorporates everything that has survived” (Chodorow, 2006); however, Tamil language works are written with specifc words, ideas, and concepts that are unique to Sri Lankan culture and are “lost in translation” when conveyed in English. Keywords book history, translation iJournal - Journal Vol. 4 No. 1, Fall 2018 22 Karunakaran / Lost in Translation INTRODUCTION The phrase “lost in translation” refers to when the translation of a word or phrase does not convey its true or complete meaning due to various factors. This is a common problem when translating non-Western texts for North American and British readership, especially those written in non-Roman scripts. Literature and texts are tangible symbols, containing signifed cultural meaning, and they represent varying aspects of an existing international ethnic, social, or linguistic culture or group. Chodorow (2006) likens it to a cultural record of sorts, which he defnes as an object that “contains cultural heritage and incorporates everything that has survived” (pg. 373). In particular, those written in South Asian indigenous languages such as Tamil, Sanskrit, Urdu, Sinhalese are written with specifc words, ideas, and concepts that are unique to specifc culture[s] and cannot be properly conveyed in English translations. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Updated Proposal to Encode Tulu-Tigalari Script in Unicode
Updated proposal to encode Tulu-Tigalari script in Unicode Vaishnavi Murthy Kodipady Yerkadithaya [ [email protected] ] Vinodh Rajan [ [email protected] ] 04/03/2021 Document History & Background Documents : (This document replaces L2/17-378) L2/11-120R Preliminary proposal for encoding the Tulu script in the SMP of the UCS – Michael Everson L2/16-241 Preliminary proposal to encode Tigalari script – Vaishnavi Murthy K Y L2/16-342 Recommendations to UTC #149 November 2016 on Script Proposals – Deborah Anderson, Ken Whistler, Roozbeh Pournader, Andrew Glass and Laurentiu Iancu L2/17-182 Comments on encoding the Tigalari script – Srinidhi and Sridatta L2/18-175 Replies to Script Ad Hoc Recommendations (L2/16-342) and Comments (L2/17-182) on Tigalari proposal (L2/16-241) – Vaishnavi Murthy K Y L2/17-378 Preliminary proposal to encode Tigalari script – Vaishnavi Murthy K Y, Vinodh Rajan L2/17-411 Letter in support of preliminary proposal to encode Tigalari – Guru Prasad (Has withdrawn support. This letter needs to be disregarded.) L2/17-422 Letter to Vaishnavi Murthy in support of Tigalari encoding proposal – A. V. Nagasampige L2/18-039 Recommendations to UTC #154 January 2018 on Script Proposals – Deborah Anderson, Ken Whistler, Roozbeh Pournader, Lisa Moore, Liang Hai, and Richard Cook PROPOSAL TO ENCODE TIGALARI SCRIPT IN UNICODE 2 A note on recent updates : −−−Tigalari Script is renamed Tulu-Tigalari script. The reason for the same is discussed under section 1.1 (pp. 4-5) of this paper & elaborately in the supplementary paper Tulu Language and Tulu-Tigalari script (pp. 5-13). −−−This proposal attempts to harmonize the use of the Tulu-Tigalari script for Tulu, Sanskrit and Kannada languages for archival use. -

Intelligence System for Tamil Vattezhuttuoptical
Mr R.Vinoth et al. / International Journal of Computer Science & Engineering Technology (IJCSET) INTELLIGENCE SYSTEM FOR TAMIL VATTEZHUTTUOPTICAL CHARACTER RCOGNITION Mr R.Vinoth Assistant Professor, Department of Information Technology Agni college of Technology, Chennai, India [email protected] Rajesh R. UG Student, Department of Information Technology Agni college of Technology, Chennai, India [email protected] Yoganandhan P. UG Student, Department of Information Technology Agni college of Technology, Chennai, India [email protected] Abstract--A system that involves character recognition and information retrieval of Palm Leaf Manuscript. The conversion of ancient Tamil to the present Tamil digital text format. Various algorithms were used to find the OCR for different languages, Ancient letter conversion still possess a big challenge. Because Image recognition technology has reached near-perfection when it comes to scanning Tamil text. The proposed system overcomes such a situation by converting all the palm manuscripts into Tamil digital text format. Though the Tamil scripts are difficult to understand. We are using this approach to solve the existing problems and convert it to Tamil digital text. Keyword - Vatteluttu Tamil (VT); Data set; Character recognition; Neural Network. I. INTRODUCTION Tamil language is one of the longest surviving classical languages in the world. Tamilnadu is a place, where the Palm Leaf Manuscript has been preserved. There are some difficulties to preserve the Palm Leaf Manuscript. So, we need to preserve the Palm Leaf Manuscript by converting to the form of digital text format. Computers and Smart devices are used by mostof them now a day. So, this system helps to convert and preserve in a fine manner. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

Proposal to Encode Tamil Fractions and Symbols §1. Thanks §2
Proposal to encode Tamil fractions and symbols Shriramana Sharma, jamadagni-at-gmail-dot-com, India 2012-Jul-17 §1. Thanks I owe much to everyone who helped with this proposal. G Balachandran of Sri Lanka heavily contributed to this proposal by sharing the attestations and data which he had collected over five years back in researching this very same topic. Dr Jean-Luc Chevillard of France and Dr Elmar Kniprath of Germany provided the second majority of attestations. Dr Kalyanasundaram (Switzerland), Dr Jayabarathi (Malaysia), K Ramanraj (Chennai), Vijayaraghavan Vanbakkam (Germany), Dr Rajam (US), Dr Vijayavenugopal (Pondicherry), Mani Manivannan (Chennai/US) and A E Elangovan (Chennai) also helped with attestations. Various members of the CTamil list also contributed to related discussions. Vinodh Rajan of Chennai is my personal sounding board for all my proposals and he contributes in too many ways for me to specify. Deborah Anderson continuously helped out with encouragement and enthusiasm-bolstering :-). I express my sincere thanks to all these people and to anyone else not mentioned (my apologies!). Preparing this has been a lengthy journey, and you all helped me through! §2. Introduction Compared to other Indic scripts/regions, the Tamil-speaking region has employed a larger set of symbols for fractions and abbreviations. These symbols, especially the fractions, have been referred to in various documents already submitted to the UTC, including my Grantha proposal L2/09-372 (p 6). A comprehensive proposal has been desirable for quite some time for the addition of characters to Unicode to enable the textual representation of these rare heritage written forms which are to be found in old Tamil manuscripts and books. -

Islamic Legal Cosmopolis and Its Arabic and Malay Microcosmoi
Languages of Law: Islamic Legal Cosmopolis and its Arabic and Malay Microcosmoi MAHMOOD KOORIA Abstract In premodern monsoon Asia, the legal worlds of major and minor traditions formed a cosmopolis of laws which expanded chronologically and geographically. Without necessarily replacing one another, they all coexisted in a larger domain with fluctuating influences over time and place. In this legal cosmopolis, each tradition had its own aggregation of diverse juridical, linguistic and contextual variants. In South and Southeast Asia, Islam has accordingly formed its own cosmopolis of law by incorporating a network of different juridical texts, institutions, jurists and scholars and by the meaningful use of these variants through shared vocabularies and languages. Focusing on the Shafīʿı ̄School of Islamic law and its major proponents in Malay and Arabic textual productions, this article argues that the intentional choice of a lingua franca contributed to the wider reception and longer sustainability of this particular legal school. The Arabic and Malay microcosmoi thus strengthened the larger cosmopolis of Islamic law through trans- regional and translinguistic exchanges across legal, cultural and continental borders. Keywords: Shaf̄iʿı School;̄ Malay and Arabic textual productions. Introduction Law was one of the most important realms that set frameworks for transregional interactions among individuals, communities and institutions in the premodern world. It synchronised structures of exchange through commonly agreed practices and expectations.1 The written legal treatises, along with unwritten customs, norms and rituals, prescribed ideal forms of social, cultural, economic and political relations to maintain order, peace and affinity in the societies in which they operated. These written and unwritten laws influenced each other in the long run both internally and externally through spatial and temporal concur- rences. -

Comment on L2/13-065: Grantha Characters from Other Indic Blocks Such As Devanagari, Tamil, Bengali Are NOT the Solution
Comment on L2/13-065: Grantha characters from other Indic blocks such as Devanagari, Tamil, Bengali are NOT the solution Dr. Naga Ganesan ([email protected]) Here is a brief comment on L2/13-065 which suggests Devanagari block for Grantha characters to write both Aryan and Dravidian languages. From L2/13-065, which suggests Devanagari block for writing Sanskrit and Dravidian languages, we read: “Similar dedicated characters were provided to cater different fonts as URUDU MARATHI SINDHI MARWARI KASHMERE etc for special conditions and needs within the shared DEVANAGARI range. There are provisions made to suit Dravidian specials also as short E short O LLLA RRA NNNA with new created glyptic forms in rhythm with DEVANAGARI glyphs (with suitable combining ortho-graphic features inside DEVANAGARI) for same special functions. These will help some aspirant proposers as a fall out who want to write every Indian language contents in Grantham when it is unified with DEVANAGARI because those features were already taken care of by the presence in that DEVANAGARI. Even few objections seen in some docs claim them as Tamil characters to induce a bug inside Grantham like letters from GoTN and others become tangential because it is going to use the existing Sanskrit properties inside shared DEVANAGARI and also with entirely new different glyph forms nothing connected with Tamil. In my doc I have shown rhythmic non-confusable glyphs for Grantham LLLA RRA NNNA for which I believe there cannot be any varied opinions even by GoTN etc which is very much as Grantham and not like Tamil form at all to confuse (as provided in proposals).” Grantha in Devanagari block to write Sanskrit and Dravidian languages will not work. -
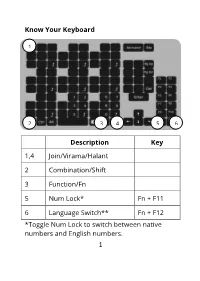
Know Your Keyboard Description Key 1,4 Join/Virama/Halant 2
Know Your Keyboard 1 2 3 4 5 6 Description Key 1,4 Join/Virama/Halant 2 Combination/Shift 3 Function/Fn 5 Num Lock* Fn + F11 6 Language Switch** Fn + F12 *Toggle Num Lock to switch between native numbers and English numbers. 1 ** Language Switch works on Windows, Linux and Android. For macOS, a configuration in settings is required. Note: If numbers are appearing in English, turn off Num Lock. Connecting Your Keyboard To Computer – Plug-in the cable to USB port on your computer. To Android Phone/Tablet 3 2 1 Use USB-to-OTG connector to plug-in keyboard. 2 Language and Layout You can use one keyboard to type multiple languages. You need to install at least one language to type. Language Layout Bengali Ka-Naada Bengali Keyboard Assamese Devanagari Sanskrit Hindi Ka-Naada Hindi Keyboard Marathi Neapli English Ka-Naada English Keyboard Guajarati Ka-Naada Guajarati Keyboard Kannada Ka-Naada Kannada Keyboard Malayalam Ka-Naada Malayalam Keyboard Tulu Odiya Ka-Naada Odiya Keyboard Panjabi Ka-Naada Gurmukhi Keyboard Telugu Ka-Naada Telugu Keyboard 3 Note: You need to switch to Ka-Naada input language before typing. Note: To switch between the languages you’re using, repeatedly press Language Switch key to cycle through all your installed languages. Language Pack Installation Go to https://ka-naada.com/downloads/ and click on the “Download” button in front of your operating system. Installation – Windows 1. Open your “Downloads” folder and locate “kanaada_keyboards.zip”. 2. Right click on zip file and choose “Extract Here” from the option menu. 3. -

Analysis of Comments for Telugu Script LGR Proposal for the Root Zone Revision: June 30, 2019
Neo-Brahmi Generation Panel: Analysis of comments for Telugu script LGR Proposal for the Root Zone Revision: June 30, 2019 Neo-Brahmi Generation Panel (NBGP) published the Telugu script LGR Propsoal for the Root Zone for public comment on 8 August 2018. This document is an additional document of the public comment report, collecting NBGP analyses as well as the concluded responses. There is 1 (one) comment submission. The analysis is as follow: No. 1 From Liang Hai Subject A Quick review of the Telugu proposal Comment 2, “telɯgɯ”: This is probably a phonetic transcription, not an accurate transliteration that should be used in this document. NBGP The NBGP acknowledges the comment. Analysis NBGP Updated the proposal in section 2 to use ‘Telugu’ Response Comment 3.5, “… and 16 dependent signs”: 15. NBGP There are 16 Matras: 14 Matras are in the repertoire, 2 Matras are Analysis excluded from the repertoire. NBGP No action required. Response Comment 3.5.1: Vocalic l should be categorized with vocalic rr and vocalic ll. Transliteration of vocalic ll is wrong. NBGP Agree. Analysis NBGP Update as suggested. Response 1 Comment 3.5.1, R1, “ca= a consonant with an inherent ‘a’”: When discussing text encoding, Indic consonants naturally are with an inherent vowel. Try to distinguish phonetic seQuence and written forms and encoded character sequence. The 3 lines under R1 are not helpful. NBGP The comment does not affect the normative part of the LGR. Analysis NBGP No action required. Response Comment 3.5.3: The introduction of arasunna usage is unclear. Is it commonly used today or not? NBGP The arsunna is not used frequently and it is not in the MSR.