Appendix – Demonstration Processors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Computer Organization and Architecture Designing for Performance Ninth Edition
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION William Stallings Boston Columbus Indianapolis New York San Francisco Upper Saddle River Amsterdam Cape Town Dubai London Madrid Milan Munich Paris Montréal Toronto Delhi Mexico City São Paulo Sydney Hong Kong Seoul Singapore Taipei Tokyo Editorial Director: Marcia Horton Designer: Bruce Kenselaar Executive Editor: Tracy Dunkelberger Manager, Visual Research: Karen Sanatar Associate Editor: Carole Snyder Manager, Rights and Permissions: Mike Joyce Director of Marketing: Patrice Jones Text Permission Coordinator: Jen Roach Marketing Manager: Yez Alayan Cover Art: Charles Bowman/Robert Harding Marketing Coordinator: Kathryn Ferranti Lead Media Project Manager: Daniel Sandin Marketing Assistant: Emma Snider Full-Service Project Management: Shiny Rajesh/ Director of Production: Vince O’Brien Integra Software Services Pvt. Ltd. Managing Editor: Jeff Holcomb Composition: Integra Software Services Pvt. Ltd. Production Project Manager: Kayla Smith-Tarbox Printer/Binder: Edward Brothers Production Editor: Pat Brown Cover Printer: Lehigh-Phoenix Color/Hagerstown Manufacturing Buyer: Pat Brown Text Font: Times Ten-Roman Creative Director: Jayne Conte Credits: Figure 2.14: reprinted with permission from The Computer Language Company, Inc. Figure 17.10: Buyya, Rajkumar, High-Performance Cluster Computing: Architectures and Systems, Vol I, 1st edition, ©1999. Reprinted and Electronically reproduced by permission of Pearson Education, Inc. Upper Saddle River, New Jersey, Figure 17.11: Reprinted with permission from Ethernet Alliance. Credits and acknowledgments borrowed from other sources and reproduced, with permission, in this textbook appear on the appropriate page within text. Copyright © 2013, 2010, 2006 by Pearson Education, Inc., publishing as Prentice Hall. All rights reserved. Manufactured in the United States of America. -
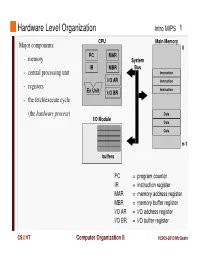
Instruction Register MAR = Memory Address Register MBR = Memory Buffer Register I/O AR = I/O Address Register I/O BR = I/O Buffer Register
Hardware Level Organization Intro MIPS 1 CPU Main Memory Major components: 0 PC MAR - memory System IR MBR Bus - central processing unit Instruction I/O AR Instruction - registers Instruction Ex Unit I/O BR - the fetch/execute cycle (the hardware process ) Data I/O Module Data Data n-1 buffers PC = program counter IR = instruction register MAR = memory address register MBR = memory buffer register I/O AR = I/O address register I/O BR = I/O buffer register CS @VT Computer Organization II ©2005-2013 McQuain Central Processing Unit Intro MIPS 2 Control - decodes instructions and manages CPU’s internal resources Registers - general-purpose registers available to user processes - special-purpose registers directly managed in fetch/execute cycle - other registers may be reserved for use of operating system - very fast and expensive (relative to memory) - hold all operands and results of arithmetic instructions (on RISC systems) - save bits in instruction representation Data path or arithmetic/logic unit (ALU) - operates on data CS @VT Computer Organization II ©2005-2013 McQuain Stored Program Concept Intro MIPS 3 Instructions are collections of bits Programs are stored in memory, to be read or written just like data Main Memory CPU 0 memory for data, programs, PC MAR compilers, editors, etc. Instruction IR MBR Instruction I/O AR Instruction Ex Unit I/O BR Data Data Data n-1 Fetch & Execute Cycle Instructions are fetched and put into a special register Bits in the register "control" the subsequent actions Fetch the “next” instruction and continue CS @VT Computer Organization II ©2005-2013 McQuain Stored Program Concept Intro MIPS 4 Of course, on most systems several programs will be stored in memory at any given time. -

Intel® 4 Series Chipset Family Datasheet
Intel® 4 Series Chipset Family Datasheet For the Intel® 82Q45, 82Q43, 82B43, 82G45, 82G43, 82G41 Graphics and Memory Controller Hub (GMCH) and the Intel® 82P45, 82P43 Memory Controller Hub (MCH) March 2010 Document Number: 319970-007 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, life sustaining, critical control or safety systems, or in nuclear facility applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Intel® 4 Series Chipset family may contain design defects or errors known as errata, which may cause the product to deviate from published specifications. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. I2C is a two-wire communications bus/protocol developed by Philips. -

The Central Processor Unit
Systems Architecture The Central Processing Unit The Central Processing Unit – p. 1/11 The Computer System Application High-level Language Operating System Assembly Language Machine level Microprogram Digital logic Hardware / Software Interface The Central Processing Unit – p. 2/11 CPU Structure External Memory MAR: Memory MBR: Memory Address Register Buffer Register Address Incrementer R15 / PC R11 R7 R3 R14 / LR R10 R6 R2 R13 / SP R9 R5 R1 R12 R8 R4 R0 User Registers Booth’s Multiplier Barrel IR Shifter Control Unit CPSR 32-Bit ALU The Central Processing Unit – p. 3/11 CPU Registers Internal Registers Condition Flags PC Program Counter C Carry IR Instruction Register Z Zero MAR Memory Address Register N Negative MBR Memory Buffer Register V Overflow CPSR Current Processor Status Register Internal Devices User Registers ALU Arithmetic Logic Unit Rn Register n CU Control Unit n = 0 . 15 M Memory Store SP Stack Pointer MMU Mem Management Unit LR Link Register Note that each CPU has a different set of User Registers The Central Processing Unit – p. 4/11 Current Process Status Register • Holds a number of status flags: N True if result of last operation is Negative Z True if result of last operation was Zero or equal C True if an unsigned borrow (Carry over) occurred Value of last bit shifted V True if a signed borrow (oVerflow) occurred • Current execution mode: User Normal “user” program execution mode System Privileged operating system tasks Some operations can only be preformed in a System mode The Central Processing Unit – p. 5/11 Register Transfer Language NAME Value of register or unit ← Transfer of data MAR ← PC x: Guard, only if x true hcci: MAR ← PC (field) Specific field of unit ALU(C) ← 1 (name), bit (n) or range (n:m) R0 ← MBR(0:7) Rn User Register n R0 ← MBR num Decimal number R0 ← 128 2_num Binary number R1 ← 2_0100 0001 0xnum Hexadecimal number R2 ← 0x40 M(addr) Memory Access (addr) MBR ← M(MAR) IR(field) Specified field of IR CU ← IR(op-code) ALU(field) Specified field of the ALU(C) ← 1 Arithmetic and Logic Unit The Central Processing Unit – p. -

Register Are Used to Quickly Accept, Store, and Transfer Data And
Register are used to quickly accept, store, and transfer data and instructions that are being used immediately by the CPU, there are various types of Registers those are used for various purpose. Among of the some Mostly used Registers named as AC or Accumulator, Data Register or DR, the AR or Address Register, program counter (PC), Memory Data Register (MDR) ,Index register,Memory Buffer Register. These Registers are used for performing the various Operations. While we are working on the System then these Registers are used by the CPU for Performing the Operations. When We Gives Some Input to the System then the Input will be Stored into the Registers and When the System will gives us the Results after Processing then the Result will also be from the Registers. So that they are used by the CPU for Processing the Data which is given by the User. Registers Perform:- 1) Fetch: The Fetch Operation is used for taking the instructions those are given by the user and the Instructions those are stored into the Main Memory will be fetch by using Registers. 2) Decode: The Decode Operation is used for interpreting the Instructions means the Instructions are decoded means the CPU will find out which Operation is to be performed on the Instructions. 3) Execute: The Execute Operation is performed by the CPU. And Results those are produced by the CPU are then Stored into the Memory and after that they are displayed on the user Screen. Types of Registers are as Followings 1. MAR stand for Memory Address Register This register holds the memory addresses of data and instructions. -

Parallel Computing in Image Processing Using GPU and CUDA Architecture
Slovak University of Technology in Bratislava Faculty of Civil Engineering Department of Mathematics and Constructive Geometry Academic year: 2017/2018 Reg. No.: SvF-5343-63353 MASTER THESIS TOPIC Student: Bc. Alexander Baťka Student’s ID: 63353 Study programme: Mathematical and Computational Modeling Study field: 9.1.9. Applied Mathematics Thesis supervisor: Ing. Jozef Urbán, PhD. Topic: Parallel computing in image processing using GPU and CUDA architecture Language of thesis: English Specification of Assignment: Téma sa zaoberá paralelizáciou algoritmov spracovania obrazu pomocou grafických procesorov využitím architektúry CUDA (Compute Unified Device Architecture). Študent naštuduje problematiku využitia GPU pre všeobecné výpočty. Naučí sa pomocou CUDA paralelizovať výpočty používané v spracovaní obrazu ako BiConjugate Gradient Stabilized Method, filtrácia obrazu lineárnou rovnicou vedenia tepla, transformácia a registrácia obrazu. Dosiahnuté výsledky vhodne prezentuje. Selected bibliography: 1. Sanders, J. – Kandrot, E. CUDA by Example: An Introduction to General-Purpose GPU Programming. Upper Saddle River : Addison Wesley, 2011. 290 s. ISBN 978-0-13-138768-3. 2. Krivá, Z. – Mikula, K. – Stašová, O. Spracovanie obrazu: Vybrané kapitoly z prednášok. Bratislava : Slovenská technická univerzita v Bratislave, 2016. 149 s. ISBN 978-80-227-4535-2. 3. Bi-CGSTAB: A fast and smoothly converging variant of Bi-CG for the solution of nonsymmetric linear sys- tems, SIAM J. Sci. Statist. Comput., 13 (1992), pp. 631–644 4. CUDA programming: A Developers guide to parallel computing with GPUs, Shane Cook, 2013, ISBN-978- 0-12-415933-4 Assignment procedure from: 02. 10. 2017 Date of thesis submission: 10. 05. 2018 Bc. Alexander Baťka Student prof. RNDr. Radko Mesiar, DrSc. prof. RNDr. -

Chapter 2 - Computer Evolution and Performance
Chapter 2 - Computer Evolution and Performance A Brief History of Computers (Section 2.1) on pp. 16-38 Let's take a quick look at the history of computers so that we know where it all began. Further, we will find that most things have dramatically changed while some have not. ENIAC (Electronic Numerical Integrator and Computer) Designed by: John Mauchly and John Presper Eckert Reason: Response to wartime needs Completed: 1946 Specifics: 30 tons, 15,000 sq ft, 18000 vacuum tubes, 5000 additions/sec decimal machine with 20 accumulators each accumulator could hold a 10-digit decimal number Programming the ENIAC involved plugging and unplugging cables. If however, the program could be stored somehow and held in memory along with the data, this process would not be necessary. This is known as the "stored-program concept." Much of the credit was given to John von Neumann who helped engineer a computer (IAS) that utilized this concept and was completed in 1952. What is amazing is that today, most computers have the same general structure and function. Wow!! IAS Computer Designed by: John von Neumann Reason: Incorporate the stored-program concept Completed: 1952 Specifics: 1000 words (40-bit words) of storage, both data and instructions are stored, binary representations A word of storage can represent either an instruction or a number. The format for each is as follows: Number: bit 0 is sign bit, bits 1-39 are the number Instruction: bits 0-7 opcode of left instruction bits 8-19 address of one of the words of memory bits 20-27 opcode of right instruction bits 28-39 address of one of the words of memory Note: An instruction word really contains two instructions (left and right instructions). -

Chapter 1 + Basic Concepts and Computer Evolution Computer Architecture 2 Computer Organization
1 Chapter 1 + Basic Concepts and Computer Evolution Computer Architecture 2 Computer Organization • Attributes of a • Instruction set, system visible to number of bits used to represent various the programmer data types, I/O • Have a direct mechanisms, impact on the techniques for logical execution addressing memory of a program Architectural Computer attributes Architecture include: Organizational Computer attributes Organization include: • The operational • Hardware details units and their transparent to the interconnections programmer, control that realize the signals, interfaces between the computer and architectural peripherals, memory specifications technology used + IBM System 370 Architecture 3 ◼ IBM System/370 architecture ◼ Was introduced in 1970 ◼ Included a number of models ◼ Could upgrade to a more expensive, faster model without having to abandon original software ◼ New models are introduced with improved technology, but retain the same architecture so that the customer’s software investment is protected ◼ Architecture has survived to this day as the architecture of IBM’s mainframe product line System/370-145 system console. + 4 Structure and Function ◼Structure ◼ The way in which ◼ Hierarchical system components relate to each other ◼ Set of interrelated subsystems ◼Function ◼ Hierarchical nature of complex ◼ The operation of individual systems is essential to both components as part of the their design and their structure description ◼ Designer need only deal with a particular level of the system at a time ◼ Concerned -

Microsoft Powerpoint
William Stallings Computer Organization and Architecture Chapter 12 CPU Structure and Function Rev. 3.3 (2009-10) by Enrico Nardelli12 - 1 CPU Functions • CPU must: Fetch instructions Decode instructions Fetch operands Execute instructions / Process data Store data Check (and possibly serve) interrupts Rev. 3.3 (2009-10) by Enrico Nardelli 12 - 2 CPU Components Registri PC IR Data Lines ALU ControlControl Lines Lines AddressAddressLines Lines AC MBR CPU Internal Bus Bus InternalInternal CPU CPU MAR Control Unit Control Signals Rev. 3.3 (2009-10) by Enrico Nardelli 12 - 3 Kind of Registers • User visible and modifiable General Purpose Data (e.g. accumulator) Address (e.g. base addressing, index addressing) • Control registers (not visible to user) Program Counter (PC) Instruction Decoding Register (IR) Memory Address Register (MAR) Memory Buffer Register (MBR) • State register (visible to user but not directly modifiable) Program Status Word (PSW) Rev. 3.3 (2009-10) by Enrico Nardelli 12 - 4 Kind of General Purpose Registers • May be used in a general way or be restricted to contains only data or only addresses • Advantages of general purpose registers Increase flexibility and programmer options Increase instruction size & complexity • Advantages of specialized (data/address) registers Smaller (faster) instructions Less flexibility Rev. 3.3 (2009-10) by Enrico Nardelli 12 - 5 How Many General Purposes Registers? • Between 8 - 32 • Fewer = more memory references • More does not reduce memory references and takes up processor real estate Rev. 3.3 (2009-10) by Enrico Nardelli 12 - 6 How many bits per register? • Large enough to hold full address value • Large enough to hold full data value • Often possible to combine two data registers to obtain a single register with a double length Rev. -

Computer System Overview: Part 1 1 What Is Operating System
CSc33200: Operating Systems, CS-CCNY, Fall 2003 Jinzhong Niu Sep. 07, 2003 Computer System Overview: Part 1 1 What is operating system We don’t know what an OS is exactly until we have learned this course, but we may have some clues about the answer. Let’s think about it. Whenever we want to use computers, we have to boot them up first. Whatever happens in this period, we know it is the OS that is in charge of it. After the computer is available for use, we then interact with the computer through a graphical interface or text-only console. We may run programs, install or uninstall applications in the OS as we need. Thus the following picture may be suitable for describing a computer system: Users | | | | | v v v | | +---------------+ | | | Applications | v v +---------------+---------+ | OS | +-------------------------+ | Hardware | +-------------------------+ Thus, we may conclude that an operating system exploits and manages all kinds of computer hardware to provide a set of services directly or indirectly to the users. Services may be functions the human users can use directly, e.g. file creation, user management, etc., and also those that may be used indirectly, which embody as application programming interface, all kinds of libraries and functions they provide. 1 2 Computer hardware overview To build an OS, as we can see from the figure, I need to know more details about the hardware. In a computer system, there are all kinds of hardware, CPUs, mainboards, monitors, network adapters, sound cards, mice, keyboards, printers, hard disks, etc. Mainboard is not something that provides a specific function, instead it is a collection of all kinds of slots and modules. -

Chapter 4 Objectives
Chapter 4 Objectives • Learn the components common to every modern computer system. • Be able to explain how each component Chapter 4 contributes to program execution. MARIE: An Introduction • Understand a simple architecture invented to to a Simple Computer illuminate these basic concepts, and how it relates to some real architectures. • Know how the program assembly process works. 2 4.1 Introduction 4.2 CPU Basics • Chapter 1 presented a general overview of • The computer’s CPU fetches, decodes, and computer systems. executes program instructions. • In Chapter 2, we discussed how data is stored and • The two principal parts of the CPU are the datapath manipulated by various computer system and the control unit. components. – The datapath consists of an arithmetic-logic unit and • Chapter 3 described the fundamental components storage units (registers) that are interconnected by a data of digital circuits. bus that is also connected to main memory. • Having this background, we can now understand – Various CPU components perform sequenced operations how computer components work, and how they fit according to signals provided by its control unit. together to create useful computer systems. 3 4 4.2 CPU Basics 4.3 The Bus • Registers hold data that can be readily accessed by • The CPU shares data with other system components the CPU. by way of a data bus. • They can be implemented using D flip-flops. – A bus is a set of wires that simultaneously convey a single bit along each line. – A 32-bit register requires 32 D flip-flops. • Two types of buses are commonly found in computer • The arithmetic-logic unit (ALU) carries out logical and systems: point-to-point, and multipoint buses. -

Computing Architectures Exploiting Optical Interconnect and Optical Memory Technologies
ARISTOTLE UNIVERSITY OF THESSALONIKI FACULTY OF SCIENCES SCHOOL OF INFORMATICS Computing Architectures exploiting Optical Interconnect and Optical Memory Technologies DOCTORAL THESIS Pavlos Maniotis Submitted to the School of Informatics of Aristotle University of Thessaloniki Thessaloniki, November 2017 Advisory Committee: N. Pleros, Assistant Professor, A.U.TH. (Supervisor) A. Miliou, Associate Professor, A.U.TH. K. Tsichlas, Lecturer, A.U.TH. Examination Committee: A. Gounaris, Assistant Professor, A.U.TH. A. Miliou, Associate Professor, A.U.TH. G. Papadimitriou, Professor, A.U.TH. A. Papadopoulos, Associate Professor, A.U.TH. N. Pleros, Assistant Professor, A.U.TH. K. Tsichlas, Lecturer, A.U.TH. K. Vyrsokinos, Lecturer, A.U.TH. i Copyright © 2017 Pavlos Maniotis Η έγκρισή της παρούσας Διδακτορικής διατριβής από το τμήμα Πληροφορικής του Αριστοτελείου Πανεπιστημίου Θεσσαλονίκης δεν υποδηλώνει αποδοχή των γνωμών του συγγραφέως. (Ν. 5343/1932, αρ. 202, παρ. 2) iii Ευχαριστίες Η παρούσα διδακτορική διατριβή αποτελεί τον καρπό των ερευνητικών εργασιών μου που πραγματοποιήθηκαν κατά τη διάρκεια της συμμετοχής μου στην ερευνητική ομάδα των Υωτονικών υστημάτων και Δικτύων (Photonic Systems and Networks – PhoS-net) του τμήματος Πληροφορικής του Αριστοτελείου Πανεπιστημίου Θεσσαλονίκης. το σημείο αυτό, έχοντας πλέον ολοκληρώσει τη συγγραφή του τεχνικού κειμένου που ακολουθεί, θέλω να εκφράσω τις ειλικρινείς μου ευχαριστίες προς τα πρόσωπα των ανθρώπων που με την καθοδήγηση τους, τις συμβουλές τους αλλά και τη στήριξη τους συνέβαλαν στην πραγματοποίηση της παρούσας διατριβής. Πρώτα από όλους, θέλω να ευχαριστήσω ολόψυχα τον επιβλέποντα της διδακτορικής μου διατριβής κ. Νίκο Πλέρο, Επίκουρο Καθηγητή του τμήματος Πληροφορικής του Αριστοτελείου Πανεπιστημίου Θεσσαλονίκης. Η οκταετής και πλέον γνωριμία-συνεργασία μας ξεκινά πίσω στο 2009, όταν και ανέλαβα να εκπονήσω την πτυχιακή μου εργασία ως προπτυχιακός φοιτητής υπό την επίβλεψη του.