MARIE: an Introduction to a Simple Computer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fill Your Boots: Enhanced Embedded Bootloader Exploits Via Fault Injection and Binary Analysis
IACR Transactions on Cryptographic Hardware and Embedded Systems ISSN 2569-2925, Vol. 2021, No. 1, pp. 56–81. DOI:10.46586/tches.v2021.i1.56-81 Fill your Boots: Enhanced Embedded Bootloader Exploits via Fault Injection and Binary Analysis Jan Van den Herrewegen1, David Oswald1, Flavio D. Garcia1 and Qais Temeiza2 1 School of Computer Science, University of Birmingham, UK, {jxv572,d.f.oswald,f.garcia}@cs.bham.ac.uk 2 Independent Researcher, [email protected] Abstract. The bootloader of an embedded microcontroller is responsible for guarding the device’s internal (flash) memory, enforcing read/write protection mechanisms. Fault injection techniques such as voltage or clock glitching have been proven successful in bypassing such protection for specific microcontrollers, but this often requires expensive equipment and/or exhaustive search of the fault parameters. When multiple glitches are required (e.g., when countermeasures are in place) this search becomes of exponential complexity and thus infeasible. Another challenge which makes embedded bootloaders notoriously hard to analyse is their lack of debugging capabilities. This paper proposes a grey-box approach that leverages binary analysis and advanced software exploitation techniques combined with voltage glitching to develop a powerful attack methodology against embedded bootloaders. We showcase our techniques with three real-world microcontrollers as case studies: 1) we combine static and on-chip dynamic analysis to enable a Return-Oriented Programming exploit on the bootloader of the NXP LPC microcontrollers; 2) we leverage on-chip dynamic analysis on the bootloader of the popular STM8 microcontrollers to constrain the glitch parameter search, achieving the first fully-documented multi-glitch attack on a real-world target; 3) we apply symbolic execution to precisely aim voltage glitches at target instructions based on the execution path in the bootloader of the Renesas 78K0 automotive microcontroller. -

X86 Platform Coprocessor/Prpmc (PC on a PMC)
x86 Platform Coprocessor/PrPMC (PC on a PMC) 32b/33MHz PCI bus PN1/PN2 +5V to Kbd/Mouse/USB power Vcore Power +3.3V +2.5v Conditioning +3.3VIO 1K100 FPGA & 512KB 10/100TX TMS2250 PCI BIOS/PLA Ethernet RJ45 Compact to PCI bridge Flash Memory PLA I/O Flash site 8 32b/33MHz Internal PCI bus Analog SVGA Video Pwr Seq AMD SC2200 Signal COM 1 (RXD/TXD only) IDE "GEODE (tm)" Conditioning COM 2 (RXD/TXD only) Processor USB Port 1 Rear I/O PN4 I/O Rear 64 USB Port 2 LPC Keyboard/Mouse Floppy 36 Pin 36 Pin Connector PC87364 128MB SDRAM Status LEDs Super I/O (16MWx64b) PC Spkr This board is a Processor PMC (PrPMC) implementing A PrPMC implements a TMS2250 PCI-to-PCI bridge to an x86-based PC architecture on a single-wide, stan- the host, and a “Coprocessor” cofniguration implements dard height PMC form factor. This delivers a complete back-to-back 16550 compatible COM ports. The “Mon- x86 platform with comprehensive I/O support, a 10/100- arch” signal selects either PrPMC or Co-processor TX Ethernet interface, and disk access (both floppy and mode. IDE drives). The board features an on-board hard drive using Compact Flash. A 512Kbyte FLASH memory holds the 1K100 PLA im- age that is automatically loaded on power up. It also At the heart of the design is an Advanced Micro De- contains the General Software Embedded BIOS 2000™ vices SC2200 GEODE™ processor that integrates video, BIOS code that is included with each board. -

Convey Overview
THE WORLD’S FIRST HYBRID-CORE COMPUTER. CONVEY HYBRID-CORE COMPUTING Hybrid-core Computing Convey HC-1 High Performance of application- specific hardware Heterogenous solutions • can be much more efficient Performance/ • still hard to program Programmability and Power efficiency deployment ease of an x86 server Application Multicore solutions • don’t always scale well • parallel programming is hard Low Difficult Ease of Deployment Easy 1/22/2010 3 Hybrid-Core Computing Application-Specific Personalities Applications • Extend the x86 instruction set • Implement key operations in Convey Compilers hardware Life Sciences x86-64 ISA Custom ISA CAE Custom Financial Oil & Gas Shared Virtual Memory Cache-coherent, shared memory • Both ISAs address common memory *ISA: Instruction Set Architecture 7/12/2010 4 HC-1 Hardware PCI I/O FPGA FPGA Intel Personalities Chipset FPGA FPGA 8 GB/s 80 GB/s Memory Memory Cache Coherent, Shared Virtual Memory 1/22/2010 5 Using Personalities C/C++ Fortran • Personalities are user specifies reloadable personality at instruction sets Convey Software compile time Development Suite • Compiler instruction generates x86 descriptions and coprocessor instructions from Hybrid-Core Executable P ANSI standard x86-64 and Coprocessor Personalities C/C++ & Fortran Instructions • Executable can run on x86 nodes FPGA Convey HC-1 or Convey Hybrid- bitfiles Core nodes Intel x86 Coprocessor personality loaded at runtime by OS 1/22/2010 6 SYSTEM ARCHITECTURE HC-1 Architecture “Commodity” Intel Server Convey FPGA-based coprocessor Direct -

Pdp11-40.Pdf
processor handbook digital equipment corporation Copyright© 1972, by Digital Equipment Corporation DEC, PDP, UNIBUS are registered trademarks of Digital Equipment Corporation. ii TABLE OF CONTENTS CHAPTER 1 INTRODUCTION 1·1 1.1 GENERAL ............................................. 1·1 1.2 GENERAL CHARACTERISTICS . 1·2 1.2.1 The UNIBUS ..... 1·2 1.2.2 Central Processor 1·3 1.2.3 Memories ........... 1·5 1.2.4 Floating Point ... 1·5 1.2.5 Memory Management .............................. .. 1·5 1.3 PERIPHERALS/OPTIONS ......................................... 1·5 1.3.1 1/0 Devices .......... .................................. 1·6 1.3.2 Storage Devices ...................................... .. 1·6 1.3.3 Bus Options .............................................. 1·6 1.4 SOFTWARE ..... .... ........................................... ............. 1·6 1.4.1 Paper Tape Software .......................................... 1·7 1.4.2 Disk Operating System Software ........................ 1·7 1.4.3 Higher Level Languages ................................... .. 1·7 1.5 NUMBER SYSTEMS ..................................... 1-7 CHAPTER 2 SYSTEM ARCHITECTURE. 2-1 2.1 SYSTEM DEFINITION .............. 2·1 2.2 UNIBUS ......................................... 2-1 2.2.1 Bidirectional Lines ...... 2-1 2.2.2 Master-Slave Relation .. 2-2 2.2.3 Interlocked Communication 2-2 2.3 CENTRAL PROCESSOR .......... 2-2 2.3.1 General Registers ... 2-3 2.3.2 Processor Status Word ....... 2-4 2.3.3 Stack Limit Register 2-5 2.4 EXTENDED INSTRUCTION SET & FLOATING POINT .. 2-5 2.5 CORE MEMORY . .... 2-6 2.6 AUTOMATIC PRIORITY INTERRUPTS .... 2-7 2.6.1 Using the Interrupts . 2-9 2.6.2 Interrupt Procedure 2-9 2.6.3 Interrupt Servicing ............ .. 2-10 2.7 PROCESSOR TRAPS ............ 2-10 2.7.1 Power Failure .............. -

6.004 Computation Structures Spring 2009
MIT OpenCourseWare http://ocw.mit.edu 6.004 Computation Structures Spring 2009 For information about citing these materials or our Terms of Use, visit: http://ocw.mit.edu/terms. M A S S A C H U S E T T S I N S T I T U T E O F T E C H N O L O G Y DEPARTMENT OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE 6.004 Computation Structures β Documentation 1. Introduction This handout is a reference guide for the β, the RISC processor design for 6.004. This is intended to be a complete and thorough specification of the programmer-visible state and instruction set. 2. Machine Model The β is a general-purpose 32-bit architecture: all registers are 32 bits wide and when loaded with an address can point to any location in the byte-addressed memory. When read, register 31 is always 0; when written, the new value is discarded. Program Counter Main Memory PC always a multiple of 4 0x00000000: 3 2 1 0 0x00000004: 32 bits … Registers SUB(R3,R4,R5) 232 bytes R0 ST(R5,1000) R1 … … R30 0xFFFFFFF8: R31 always 0 0xFFFFFFFC: 32 bits 32 bits 3. Instruction Encoding Each β instruction is 32 bits long. All integer manipulation is between registers, with up to two source operands (one may be a sign-extended 16-bit literal), and one destination register. Memory is referenced through load and store instructions that perform no other computation. Conditional branch instructions are separated from comparison instructions: branch instructions test the value of a register that can be the result of a previous compare instruction. -

Generalized Linear Models (Glms)
San Jos´eState University Math 261A: Regression Theory & Methods Generalized Linear Models (GLMs) Dr. Guangliang Chen This lecture is based on the following textbook sections: • Chapter 13: 13.1 – 13.3 Outline of this presentation: • What is a GLM? • Logistic regression • Poisson regression Generalized Linear Models (GLMs) What is a GLM? In ordinary linear regression, we assume that the response is a linear function of the regressors plus Gaussian noise: 0 2 y = β0 + β1x1 + ··· + βkxk + ∼ N(x β, σ ) | {z } |{z} linear form x0β N(0,σ2) noise The model can be reformulate in terms of • distribution of the response: y | x ∼ N(µ, σ2), and • dependence of the mean on the predictors: µ = E(y | x) = x0β Dr. Guangliang Chen | Mathematics & Statistics, San Jos´e State University3/24 Generalized Linear Models (GLMs) beta=(1,2) 5 4 3 β0 + β1x b y 2 y 1 0 −1 0.0 0.2 0.4 0.6 0.8 1.0 x x Dr. Guangliang Chen | Mathematics & Statistics, San Jos´e State University4/24 Generalized Linear Models (GLMs) Generalized linear models (GLM) extend linear regression by allowing the response variable to have • a general distribution (with mean µ = E(y | x)) and • a mean that depends on the predictors through a link function g: That is, g(µ) = β0x or equivalently, µ = g−1(β0x) Dr. Guangliang Chen | Mathematics & Statistics, San Jos´e State University5/24 Generalized Linear Models (GLMs) In GLM, the response is typically assumed to have a distribution in the exponential family, which is a large class of probability distributions that have pdfs of the form f(x | θ) = a(x)b(θ) exp(c(θ) · T (x)), including • Normal - ordinary linear regression • Bernoulli - Logistic regression, modeling binary data • Binomial - Multinomial logistic regression, modeling general cate- gorical data • Poisson - Poisson regression, modeling count data • Exponential, Gamma - survival analysis Dr. -

The Hexadecimal Number System and Memory Addressing
C5537_App C_1107_03/16/2005 APPENDIX C The Hexadecimal Number System and Memory Addressing nderstanding the number system and the coding system that computers use to U store data and communicate with each other is fundamental to understanding how computers work. Early attempts to invent an electronic computing device met with disappointing results as long as inventors tried to use the decimal number sys- tem, with the digits 0–9. Then John Atanasoff proposed using a coding system that expressed everything in terms of different sequences of only two numerals: one repre- sented by the presence of a charge and one represented by the absence of a charge. The numbering system that can be supported by the expression of only two numerals is called base 2, or binary; it was invented by Ada Lovelace many years before, using the numerals 0 and 1. Under Atanasoff’s design, all numbers and other characters would be converted to this binary number system, and all storage, comparisons, and arithmetic would be done using it. Even today, this is one of the basic principles of computers. Every character or number entered into a computer is first converted into a series of 0s and 1s. Many coding schemes and techniques have been invented to manipulate these 0s and 1s, called bits for binary digits. The most widespread binary coding scheme for microcomputers, which is recog- nized as the microcomputer standard, is called ASCII (American Standard Code for Information Interchange). (Appendix B lists the binary code for the basic 127- character set.) In ASCII, each character is assigned an 8-bit code called a byte. -

18-447 Computer Architecture Lecture 6: Multi-Cycle and Microprogrammed Microarchitectures
18-447 Computer Architecture Lecture 6: Multi-Cycle and Microprogrammed Microarchitectures Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 1/28/2015 Agenda for Today & Next Few Lectures n Single-cycle Microarchitectures n Multi-cycle and Microprogrammed Microarchitectures n Pipelining n Issues in Pipelining: Control & Data Dependence Handling, State Maintenance and Recovery, … n Out-of-Order Execution n Issues in OoO Execution: Load-Store Handling, … 2 Reminder on Assignments n Lab 2 due next Friday (Feb 6) q Start early! n HW 1 due today n HW 2 out n Remember that all is for your benefit q Homeworks, especially so q All assignments can take time, but the goal is for you to learn very well 3 Lab 1 Grades 25 20 15 10 5 Number of Students 0 30 40 50 60 70 80 90 100 n Mean: 88.0 n Median: 96.0 n Standard Deviation: 16.9 4 Extra Credit for Lab Assignment 2 n Complete your normal (single-cycle) implementation first, and get it checked off in lab. n Then, implement the MIPS core using a microcoded approach similar to what we will discuss in class. n We are not specifying any particular details of the microcode format or the microarchitecture; you can be creative. n For the extra credit, the microcoded implementation should execute the same programs that your ordinary implementation does, and you should demo it by the normal lab deadline. n You will get maximum 4% of course grade n Document what you have done and demonstrate well 5 Readings for Today n P&P, Revised Appendix C q Microarchitecture of the LC-3b q Appendix A (LC-3b ISA) will be useful in following this n P&H, Appendix D q Mapping Control to Hardware n Optional q Maurice Wilkes, “The Best Way to Design an Automatic Calculating Machine,” Manchester Univ. -

Computer Organization and Architecture Designing for Performance Ninth Edition
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION William Stallings Boston Columbus Indianapolis New York San Francisco Upper Saddle River Amsterdam Cape Town Dubai London Madrid Milan Munich Paris Montréal Toronto Delhi Mexico City São Paulo Sydney Hong Kong Seoul Singapore Taipei Tokyo Editorial Director: Marcia Horton Designer: Bruce Kenselaar Executive Editor: Tracy Dunkelberger Manager, Visual Research: Karen Sanatar Associate Editor: Carole Snyder Manager, Rights and Permissions: Mike Joyce Director of Marketing: Patrice Jones Text Permission Coordinator: Jen Roach Marketing Manager: Yez Alayan Cover Art: Charles Bowman/Robert Harding Marketing Coordinator: Kathryn Ferranti Lead Media Project Manager: Daniel Sandin Marketing Assistant: Emma Snider Full-Service Project Management: Shiny Rajesh/ Director of Production: Vince O’Brien Integra Software Services Pvt. Ltd. Managing Editor: Jeff Holcomb Composition: Integra Software Services Pvt. Ltd. Production Project Manager: Kayla Smith-Tarbox Printer/Binder: Edward Brothers Production Editor: Pat Brown Cover Printer: Lehigh-Phoenix Color/Hagerstown Manufacturing Buyer: Pat Brown Text Font: Times Ten-Roman Creative Director: Jayne Conte Credits: Figure 2.14: reprinted with permission from The Computer Language Company, Inc. Figure 17.10: Buyya, Rajkumar, High-Performance Cluster Computing: Architectures and Systems, Vol I, 1st edition, ©1999. Reprinted and Electronically reproduced by permission of Pearson Education, Inc. Upper Saddle River, New Jersey, Figure 17.11: Reprinted with permission from Ethernet Alliance. Credits and acknowledgments borrowed from other sources and reproduced, with permission, in this textbook appear on the appropriate page within text. Copyright © 2013, 2010, 2006 by Pearson Education, Inc., publishing as Prentice Hall. All rights reserved. Manufactured in the United States of America. -

ARM Instruction Set
4 ARM Instruction Set This chapter describes the ARM instruction set. 4.1 Instruction Set Summary 4-2 4.2 The Condition Field 4-5 4.3 Branch and Exchange (BX) 4-6 4.4 Branch and Branch with Link (B, BL) 4-8 4.5 Data Processing 4-10 4.6 PSR Transfer (MRS, MSR) 4-17 4.7 Multiply and Multiply-Accumulate (MUL, MLA) 4-22 4.8 Multiply Long and Multiply-Accumulate Long (MULL,MLAL) 4-24 4.9 Single Data Transfer (LDR, STR) 4-26 4.10 Halfword and Signed Data Transfer 4-32 4.11 Block Data Transfer (LDM, STM) 4-37 4.12 Single Data Swap (SWP) 4-43 4.13 Software Interrupt (SWI) 4-45 4.14 Coprocessor Data Operations (CDP) 4-47 4.15 Coprocessor Data Transfers (LDC, STC) 4-49 4.16 Coprocessor Register Transfers (MRC, MCR) 4-53 4.17 Undefined Instruction 4-55 4.18 Instruction Set Examples 4-56 ARM7TDMI-S Data Sheet 4-1 ARM DDI 0084D Final - Open Access ARM Instruction Set 4.1 Instruction Set Summary 4.1.1 Format summary The ARM instruction set formats are shown below. 3 3 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 9876543210 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 Cond 0 0 I Opcode S Rn Rd Operand 2 Data Processing / PSR Transfer Cond 0 0 0 0 0 0 A S Rd Rn Rs 1 0 0 1 Rm Multiply Cond 0 0 0 0 1 U A S RdHi RdLo Rn 1 0 0 1 Rm Multiply Long Cond 0 0 0 1 0 B 0 0 Rn Rd 0 0 0 0 1 0 0 1 Rm Single Data Swap Cond 0 0 0 1 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 Rn Branch and Exchange Cond 0 0 0 P U 0 W L Rn Rd 0 0 0 0 1 S H 1 Rm Halfword Data Transfer: register offset Cond 0 0 0 P U 1 W L Rn Rd Offset 1 S H 1 Offset Halfword Data Transfer: immediate offset Cond 0 -

System Design for a Computational-RAM Logic-In-Memory Parailel-Processing Machine
System Design for a Computational-RAM Logic-In-Memory ParaIlel-Processing Machine Peter M. Nyasulu, B .Sc., M.Eng. A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of the requirements for the degree of Doctor of Philosophy Ottaw a-Carleton Ins titute for Eleceical and Computer Engineering, Department of Electronics, Faculty of Engineering, Carleton University, Ottawa, Ontario, Canada May, 1999 O Peter M. Nyasulu, 1999 National Library Biôiiothkque nationale du Canada Acquisitions and Acquisitions et Bibliographie Services services bibliographiques 39S Weiiington Street 395. nie WeUingtm OnawaON KlAW Ottawa ON K1A ON4 Canada Canada The author has granted a non- L'auteur a accordé une licence non exclusive licence allowing the exclusive permettant à la National Library of Canada to Bibliothèque nationale du Canada de reproduce, ban, distribute or seU reproduire, prêter, distribuer ou copies of this thesis in microform, vendre des copies de cette thèse sous paper or electronic formats. la forme de microficbe/nlm, de reproduction sur papier ou sur format électronique. The author retains ownership of the L'auteur conserve la propriété du copyright in this thesis. Neither the droit d'auteur qui protège cette thèse. thesis nor substantial extracts fkom it Ni la thèse ni des extraits substantiels may be printed or otherwise de celle-ci ne doivent être imprimés reproduced without the author's ou autrement reproduits sans son permission. autorisation. Abstract Integrating several 1-bit processing elements at the sense amplifiers of a standard RAM improves the performance of massively-paralle1 applications because of the inherent parallelism and high data bandwidth inside the memory chip. -
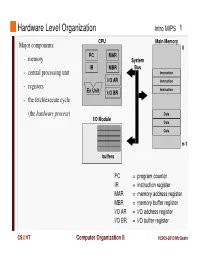
Instruction Register MAR = Memory Address Register MBR = Memory Buffer Register I/O AR = I/O Address Register I/O BR = I/O Buffer Register
Hardware Level Organization Intro MIPS 1 CPU Main Memory Major components: 0 PC MAR - memory System IR MBR Bus - central processing unit Instruction I/O AR Instruction - registers Instruction Ex Unit I/O BR - the fetch/execute cycle (the hardware process ) Data I/O Module Data Data n-1 buffers PC = program counter IR = instruction register MAR = memory address register MBR = memory buffer register I/O AR = I/O address register I/O BR = I/O buffer register CS @VT Computer Organization II ©2005-2013 McQuain Central Processing Unit Intro MIPS 2 Control - decodes instructions and manages CPU’s internal resources Registers - general-purpose registers available to user processes - special-purpose registers directly managed in fetch/execute cycle - other registers may be reserved for use of operating system - very fast and expensive (relative to memory) - hold all operands and results of arithmetic instructions (on RISC systems) - save bits in instruction representation Data path or arithmetic/logic unit (ALU) - operates on data CS @VT Computer Organization II ©2005-2013 McQuain Stored Program Concept Intro MIPS 3 Instructions are collections of bits Programs are stored in memory, to be read or written just like data Main Memory CPU 0 memory for data, programs, PC MAR compilers, editors, etc. Instruction IR MBR Instruction I/O AR Instruction Ex Unit I/O BR Data Data Data n-1 Fetch & Execute Cycle Instructions are fetched and put into a special register Bits in the register "control" the subsequent actions Fetch the “next” instruction and continue CS @VT Computer Organization II ©2005-2013 McQuain Stored Program Concept Intro MIPS 4 Of course, on most systems several programs will be stored in memory at any given time.