On First Page
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Media Contacts
Media Contacts: Sarika Patel GolinHarris 972-341-2504 [email protected] Debbie Shemony Texas Instruments 301-407-9338 [email protected] (Please do not publish these numbers or e-mail addresses.) A better way to cloud: TI’s new KeyStone multicore SoCs revitalize cloud applications Announcement quote sheet 3L Ltd. “Supporting TI’s new KeyStone-based multicore SoCs is a natural extension for us, as we have been simplifying the development of solutions involving multiple processing elements for over 20 years,” said Peter Robertson, President and TechFounder, 3L Ltd. “Together with TI, we’re making designing with multicore easier for developers by automating the interconnection management when tasks are removed between cores or devices. The end result of our collaboration is making the development processes easier, faster and more efficient for designers.” 6WIND “We are delighted to support TI as it broadens its KeyStone-based SoC product line into additional markets with critical network performance requirements,” said Eric Carmès, CEO, 6WIND. “As one of the first members of the TI Design Network to announce support for the KeyStone multicore architecture, we look forward to providing the proven 6WINDGate™ packet processing software to our mutual customers. The combination of the 6WINDGate software and the newest KeyStone architecture-based SoCs represent an ideal system solution for the demanding network performance challenges faced in today’s mobile and cloud infrastructure markets.” Advantech “With TI’s new KeyStone-based multicore SoCs, Advantech is able to expand its product lines from existing DSP-based signal and media processing centric solutions to hybrid designs that leverage multiple ARM and DSP cores in a seamless integration for control and data processing,” said David Lin, senior director of DSP and video solutions, Advantech. -

1A APPENDIX a UNITED STATES COURT of APPEALS for THE
1a APPENDIX A UNITED STATES COURT OF APPEALS FOR THE FEDERAL CIRCUIT ___________________ MENTOR GRAPHICS CORPORATION, AN OREGON CORPORATION, Plaintiff-Cross-Appellant v. EVE-USA, INC., A DELAWARE CORPORA- TION, SYNOPSYS EMULATION AND VERIFI- CATION S.A.S., FORMED UNDER THE LAWS OF FRANCE, SYNOPSYS, INC., A DELAWARE CORPORATION, Defendants-Appellants ___________________ 2015-1470, 2015-1554, 2015-1556 ___________________ Appeals from the United States District Court for the District of Oregon in Nos. 3:10-cv-00954-MO, 3:12-cv-01500-MO, 3:13-cv-00579-MO, Judge Michael W. Mosman. ___________________ Decided: March 16, 2017 ___________________ MARK E. MILLER, O’Melveny & Myers LLP, San Francisco, CA, argued for plaintiff-cross-appellant. 2a Also represented by ANNE E. HUFFSMITH, LUANN LO- RAINE SIMMONS. E. JOSHUA ROSENKRANZ, Orrick, Herrington & Sutcliffe LLP, New York, NY, argued for defendants- appellants. Also represented by DANIEL A. RUBENS, ANDREW D. SILVERMAN; ROBERT M. LOEB, ERIC SHUM- SKY, Washington, DC; INDRA NEEL CHATTERJEE, VICKI L. FEEMAN, TRAVIS JENSEN, SCOTT T. LONARDO, Menlo Park, CA; WILLIAM H. WRIGHT, Los Angeles, CA. SEAN C. CUNNINGHAM, DLA Piper LLP (US), San Diego, CA, for amici curiae Hewlett-Packard Com- pany, Aruba Networks, Inc., NETGEAR, Inc., Newegg Inc., Oracle America, Inc., Ruckus Wireless, Inc., Safeway Inc., SAS Institute Inc., Varian Medical Sys- tems, Inc., VeriFone, Inc., VIZIO, Inc. ________________________ Before LOURIE, MOORE, and CHEN, Circuit Judges. MOORE, Circuit Judge. The present appeal arises from litigation in the District of Oregon between Mentor Graphics Corp. (“Mentor”) and Synopsys, Inc., Synopsys Emulation and Verification S.A.S., and EVE-USA, Inc. -

Uwlink Interface / Development Platform
UWLink Interface / Development platform UWLink Mainboard User Guide Hardware / Tool description User Guide 1.0, 2010-06-01 Wireless Control Edition 2010-07-16 Published by Infineon Technologies AG 81726 Munich, Germany © 2010 Infineon Technologies AG All Rights Reserved. Legal Disclaimer The information given in this document shall in no event be regarded as a guarantee of conditions or characteristics. With respect to any examples or hints given herein, any typical values stated herein and/or any information regarding the application of the device, Infineon Technologies hereby disclaims any and all warranties and liabilities of any kind, including without limitation, warranties of non-infringement of intellectual property rights of any third party. Information For further information on technology, delivery terms and conditions and prices, please contact the nearest Infineon Technologies Office (www.infineon.com). Warnings Due to technical requirements, components may contain dangerous substances. For information on the types in question, please contact the nearest Infineon Technologies Office. Infineon Technologies components may be used in life-support devices or systems only with the express written approval of Infineon Technologies, if a failure of such components can reasonably be expected to cause the failure of that life-support device or system or to affect the safety or effectiveness of that device or system. Life support devices or systems are intended to be implanted in the human body or to support and/or maintain and sustain -

Siemens EDA / Mentor Graphics License Usage Reports
Siemens EDA / Mentor Graphics License Usage Reports Siemens EDA (formerly Mentor Graphics) is a US-based Effectively optimize your electronic design automation multinational corporation for Siemens EDA / Mentor Graphics electrical engineering and electronics. licenses and ensure all resource requirements are met. Tracking usage across the organization (location, team, etc.) is critical for optimizing license selection and expenditures. Product Suites: Optimize Siemens EDA (formerly Mentor Graphics) licenses All IC Products that your team uses by taking a look at patterns of historical All PCB Software All IC Packaging Software usage: Calibre Design Tanner EDA Groups and Projects Solid Edge License Denials And more License Efficiency License Harvesting License Pool - Total number of Siemens EDA (formerly Mentor Graphics) licenses and Users Real-Time / Actual usage Checkout times - Times and frequency Alerts Set up alerts to stay informed about the status of Siemens 1 EDA (formerly Mentor Graphics) licenses (See here). 2 0 2 . 5 1 . Generate Reports 6 - We have a full suite of reports available (more here). A D Our reports can also help you to look at license usage E m statistics according to organizational units. a e T Looking for a license optimization tool for growth and monitoring Siemens EDA / Mentor Graphics license servers? Looking to control access to high-cost, advanced features licenses offered by one of TeamEDA, Inc. the Siemens EDA / Mentor Graphics license servers? (603) 656-5200 [email protected] “License Asset Manager” and “LAMUM” are trademark names of TeamEDA and are products solely of TeamEDA.. -

Intro to T3ster
MicReDMicReD Hardware Hardware Products Products ThermalThermal Transient Transient Test Test and and Measurement Measurement MECHANICAL ANALYSIS www.mentor.com What our customers say about T3Ster “In our lab today the T3Ster is mainly used to measure the thermal resistance of our packages in customer-specific environments. Thanks to the T3Ster, these measurements are very quick and easy to perform. With the help of the T3Ster- Master software we are not only able to give customers strong confidence that our compact thermal models are correct, but also give them insights into how the heat can be dissipated to the environment and the impact of possible faults that may occur during board assembly. Furthermore, for determining the properties of SOI materials, we also measure special test chips with T3Ster, yielding reliable data for thermal simulations of our own SOI chips. T3Ster is a highly versatile piece of equipment. I am sure that we will find other application areas in the near future.” - Ir. John H.J. Janssen, Manager Virtual Prototyping, Senior Principal, NXP Semiconductors, Nijmegen, The Netherlands “As LEDs become more powerful, more attention should be paid to thermal management, which is essential to ensure “To reliably measure the interface resistance we needed a stable LED performance and long lifetime. This is why OSRAM transient measuring method. We chose the T3Ster is devoting considerable attention to thermal design. T3Ster’s because of its compactness and ease of use, allowing us accuracy and repeatability enable us to verify our thermal to improve data acquisition and processing of the designs and confirm the stability and reliability of our transient thermal data. -

Insight MFR By
Manufacturers, Publishers and Suppliers by Product Category 11/6/2017 10/100 Hubs & Switches ASCEND COMMUNICATIONS CIS SECURE COMPUTING INC DIGIUM GEAR HEAD 1 TRIPPLITE ASUS Cisco Press D‐LINK SYSTEMS GEFEN 1VISION SOFTWARE ATEN TECHNOLOGY CISCO SYSTEMS DUALCOMM TECHNOLOGY, INC. GEIST 3COM ATLAS SOUND CLEAR CUBE DYCONN GEOVISION INC. 4XEM CORP. ATLONA CLEARSOUNDS DYNEX PRODUCTS GIGAFAST 8E6 TECHNOLOGIES ATTO TECHNOLOGY CNET TECHNOLOGY EATON GIGAMON SYSTEMS LLC AAXEON TECHNOLOGIES LLC. AUDIOCODES, INC. CODE GREEN NETWORKS E‐CORPORATEGIFTS.COM, INC. GLOBAL MARKETING ACCELL AUDIOVOX CODI INC EDGECORE GOLDENRAM ACCELLION AVAYA COMMAND COMMUNICATIONS EDITSHARE LLC GREAT BAY SOFTWARE INC. ACER AMERICA AVENVIEW CORP COMMUNICATION DEVICES INC. EMC GRIFFIN TECHNOLOGY ACTI CORPORATION AVOCENT COMNET ENDACE USA H3C Technology ADAPTEC AVOCENT‐EMERSON COMPELLENT ENGENIUS HALL RESEARCH ADC KENTROX AVTECH CORPORATION COMPREHENSIVE CABLE ENTERASYS NETWORKS HAVIS SHIELD ADC TELECOMMUNICATIONS AXIOM MEMORY COMPU‐CALL, INC EPIPHAN SYSTEMS HAWKING TECHNOLOGY ADDERTECHNOLOGY AXIS COMMUNICATIONS COMPUTER LAB EQUINOX SYSTEMS HERITAGE TRAVELWARE ADD‐ON COMPUTER PERIPHERALS AZIO CORPORATION COMPUTERLINKS ETHERNET DIRECT HEWLETT PACKARD ENTERPRISE ADDON STORE B & B ELECTRONICS COMTROL ETHERWAN HIKVISION DIGITAL TECHNOLOGY CO. LT ADESSO BELDEN CONNECTGEAR EVANS CONSOLES HITACHI ADTRAN BELKIN COMPONENTS CONNECTPRO EVGA.COM HITACHI DATA SYSTEMS ADVANTECH AUTOMATION CORP. BIDUL & CO CONSTANT TECHNOLOGIES INC Exablaze HOO TOO INC AEROHIVE NETWORKS BLACK BOX COOL GEAR EXACQ TECHNOLOGIES INC HP AJA VIDEO SYSTEMS BLACKMAGIC DESIGN USA CP TECHNOLOGIES EXFO INC HP INC ALCATEL BLADE NETWORK TECHNOLOGIES CPS EXTREME NETWORKS HUAWEI ALCATEL LUCENT BLONDER TONGUE LABORATORIES CREATIVE LABS EXTRON HUAWEI SYMANTEC TECHNOLOGIES ALLIED TELESIS BLUE COAT SYSTEMS CRESTRON ELECTRONICS F5 NETWORKS IBM ALLOY COMPUTER PRODUCTS LLC BOSCH SECURITY CTC UNION TECHNOLOGIES CO FELLOWES ICOMTECH INC ALTINEX, INC. -

Siemens Annual Report 2020
Annual Report 2020 Table of A. contents Combined Management Report A.1 Organization of the Siemens Group and basis of presentation 2 A.2 Financial performance system 3 A.3 Segment information 6 A.4 Results of operations 18 A.5 Net assets position 22 A.6 Financial position 23 A.7 Overall assessment of the economic position 27 A.8 Report on expected developments and as sociated material opportunities and risks 29 A.9 Siemens AG 46 A.10 Compensation Report 50 A.11 Takeover-relevant information 82 B. Consolidated Financial Statements B.1 Consolidated Statements of Income 88 B.2 Consolidated Statements of Comprehensive Income 89 B.3 Consolidated Statements of Financial Position 90 B.4 Consolidated Statements of Cash Flows 92 B.5 Consolidated Statements of Changes in Equity 94 B.6 Notes to Consolidated Financial Statements 96 C. Additional Information C.1 Responsibility Statement 166 C.2 Independent Auditor ʼs Report 167 C.3 Report of the Super visory Board 176 C.4 Corporate Governance 184 C.5 Notes and forward-looking s tatements 199 PAGES 1 – 86 A. Combined Management Report Combined Management Report A.1 Organization of the Siemens Group and basis of presentation A.1 Organization of the Siemens Group and basis of presentation Siemens is a technology company that is active in nearly all Reconciliation to Consolidated Financial Statements is countries of the world, focusing on the areas of automation Siemens Advanta, formerly Siemens IoT Services, a stra- and digitalization in the process and manufacturing indus- tegic advisor and implementation partner in digital trans- tries, intelligent infrastructure for buildings and distributed formation and industrial internet of things (IIoT). -

Intel High Level Synthesis Compiler Pro Edition: Getting Started Guide Send Feedback
Intel® High Level Synthesis Compiler Pro Edition Getting Started Guide Updated for Intel® Quartus® Prime Design Suite: 21.2 Subscribe UG-20036 | 2021.06.21 Send Feedback Latest document on the web: PDF | HTML Contents Contents 1. Intel® High Level Synthesis (HLS) Compiler Pro Edition Getting Started Guide...............3 1.1. Intel High Level Synthesis Compiler Pro Edition Prerequisites.......................................4 1.1.1. Intel HLS Compiler Pro Edition Backwards Compatibility.................................. 5 1.2. Downloading the Intel HLS Compiler Pro Edition.........................................................5 1.3. Installing the Intel HLS Compiler Pro Edition for Cyclone® V Device Support.................. 6 1.4. Installing the Intel HLS Compiler Pro Edition on Linux Systems.................................... 7 1.5. Installing the Intel HLS Compiler Pro Edition on Microsoft Windows* Systems................ 9 1.6. Initializing the Intel HLS Compiler Pro Edition Environment........................................11 2. High Level Synthesis (HLS) Design Examples and Tutorials.......................................... 14 2.1. Running an Intel HLS Compiler Design Example (Linux)............................................ 19 2.2. Running an Intel HLS Compiler Design Example (Windows)....................................... 21 3. Troubleshooting the Setup of the Intel HLS Compiler................................................... 22 3.1. Intel HLS Compiler Licensing Issues...................................................................... -

Welcome to CSE467! Highlights
Welcome to CSE467! Highlights: Course Staff: Bruce Hemingway and Charles Giefer We'll be reading hand-outs and papers from various sources. Course web:http://www.cs.washington.edu/467/ The course work will be built around an embedded-core processor in an FPGA. My office: CSE 464 Allen Center, 206 543-6274 Tools are Active-HDL from Aldec, Synplify, and Xilinx ISE. Today: Course overview Languages are verilog and C. What is computer engineering? Applications in the FPGA will include some audio. What we will cover in this class What is “design”, and how do we do it? You may do this week’s lab at your own time. Basis for FPGAs The project- audio string model CSE467 1 CSE467 2 What is computer engineering? What we will cover in CSE467 CE is not PC design Basic digital design (much of it review) It includes PC design Combinational logic Truth tables & logic gates CE is not necessarily digital design Logic minimization Analog computers Special functions (muxes, decoders, ROMs, etc.) Real-world (analog) interfaces Sequential logic CE is about designing information-processing systems Flip-flops and registers Computers Clocking Networks and networking HW Synchronization and timing State machines Automation/controllers (smart appliances, etc.) Counters Medical/test equipment (CT scanners, etc.) State minimization and encoding Much, much more Moore vs Mealy CSE467 3 CSE467 4 What we will cover (con’t) CSE467 is about design Advanced topics Design is an art Field-programmable gate arrays (FPGAs) You learn -

Legal Notice
Altera Digital Library September 1996 P-CD-ADL-01 Legal Notice This CD contains documentation and other information related to products and services of Altera Corporation (“Altera”) which is provided as a courtesy to Altera’s customers and potential customers. By copying or using any information contained on this CD, you agree to be bound by the terms and conditions described in this Legal Notice. The documentation, software, and other materials contained on this CD are owned and copyrighted by Altera and its licensors. Copyright © 1994, 1995, 1996 Altera Corporation, 2610 Orchard Parkway, San Jose, California 95134, USA and its licensors. All rights reserved. You are licensed to download and copy documentation and other information from this CD provided you agree to the following terms and conditions: (1) You may use the materials for informational purposes only. (2) You may not alter or modify the materials in any way. (3) You may not use any graphics separate from any accompanying text. (4) You may distribute copies of the documentation available on this CD only to customers and potential customers of Altera products. However, you may not charge them for such use. Any other distribution to third parties is prohibited unless you obtain the prior written consent of Altera. (5) You may not use the materials in any way that may be adverse to Altera’s interests. (6) All copies of materials that you copy from this CD must include a copy of this Legal Notice. Altera, MAX, MAX+PLUS, FLEX, FLEX 10K, FLEX 8000, FLEX 8000A, MAX 9000, MAX 7000, -
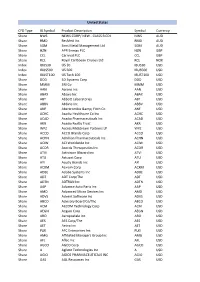
CFD Type IB Symbol Product Description Symbol
United States CFD Type IB Symbol Product Description Symbol Currency Share NWS NEWS CORP/ NEW - CLASS B CDI NWS AUD Share RMD ResMed Inc RMD AUD Share SGM Sims Metal Management Ltd SGM AUD Share HZN APR Energy PLC HZN GBP Share CCL Carnival PLC CCL GBP Share RCL Royal Caribbean Cruises Ltd RCL NOK Index IBUS30 US 30 IBUS30 USD Index IBUS500 US 500 IBUS500 USD Index IBUST100 US Tech 100 IBUST100 USD Share DDD 3D Systems Corp DDD USD Share MMM 3M Co MMM USD Share AAN Aarons Inc AAN USD Share ABAX Abaxis Inc ABAX USD Share ABT Abbott Laboratories ABT USD Share ABBV AbbVie Inc ABBV USD Share ANF Abercrombie & Fitch Co ANF USD Share ACHC Acadia Healthcare Co Inc ACHC USD Share ACAD Acadia Pharmaceuticals Inc ACAD USD Share AKR Acadia Realty Trust AKR USD Share WPZ Access Midstream Partners LP WPZ USD Share ACCO ACCO Brands Corp ACCO USD Share ACHN Achillion Pharmaceuticals Inc ACHN USD Share ACIW ACI Worldwide Inc ACIW USD Share ACOR Acorda Therapeutics Inc ACOR USD Share ATVI Activision Blizzard Inc ATVI USD Share ATU Actuant Corp ATU USD Share AYI Acuity Brands Inc AYI USD Share ACXM Acxiom Corp ACXM USD Share ADBE Adobe Systems Inc ADBE USD Share ADT ADT Corp/The ADT USD Share ADTN ADTRAN Inc ADTN USD Share AAP Advance Auto Parts Inc AAP USD Share AMD Advanced Micro Devices Inc AMD USD Share ADVS Advent Software Inc ADVS USD Share ABCO Advisory Board Co/The ABCO USD Share ACM AECOM Technology Corp ACM USD Share AEGN Aegion Corp AEGN USD Share ARO Aeropostale Inc ARO USD Share AES AES Corp/The AES USD Share AET Aetna Inc AET USD Share -

Teamcenter Integration for Mentor Graphics PADS Fact Sheet
Siemens PLM Software Teamcenter integration for Mentor Graphics PADS Integrating PADS printed circuit board design into your Teamcenter PLM environment Benefits Summary end-of-life disposition. The integration • Manages entire PCB product Teamcenter® software’s integration for enables users to store and manage all of lifecycle Mentor Graphics’ PADS PCB design system their part library, PCB design, collaboration enables users to capture and manage their and manufacturing data in Teamcenter – • Provides a single source of part library, schematic, printed circuit board Siemens PLM Software’s digital PLM product and process data (PCB) layout, bill of material (BOM), fabrica- platform. • Fosters environmental tion, assembly and visualization data in Teamcenter menus, which are embedded in compliance initiatives Teamcenter – the world’s most widely used the PADS user interface, allow the user to product lifecycle management (PLM) • Facilitates collaboration and automatically log-in to Teamcenter and platform. concurrent engineering open, save, check-in and check-out design initiatives Managing the electronics product lifecycle data. Adhering to the Teamcenter mecha- Teamcenter’s integration for PADS provides tronics data model, design teams are • Aligns ECAD design with a comprehensive solution for the entire assured their ECAD data is accurately cap- product requirements electronics product lifecycle that extends tured, consistently managed within the from initial inception through creation, Teamcenter environment and kept in synch analysis,