Subscription Indexes for Web Syndication Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mapodwalk Caster
A USER ENVIRONMENT FOR SYNDICATING AND AGGREGATING MAP-INTEGRATED AUDIO TOURS: MAPODWALK CASTER Ken’ichi Tsuruoka [email protected] Masatoshi Arikawa [email protected] Center for Spatial Information Science The University of Tokyo Kashiwanoha-5-1-5, Kashiwa City, Chiba, Japan Abstract In this paper, we focus on providing users new environment for syndicating and aggregating audio tours with animated maps over the Internet. Geotagged photos nowadays are getting popular as one of the spatial content on the Internet in the revolution of Where 2.0. However, this single media of photo often has some difficulty to represent users’ sequential stories and their context. On the other hand, audio streams are able to contain sequential stories and their context effectively. But users have difficulty on syndicating place-related audio streams compared with geotagged photos because there is no user-friendly environment for sharing audio streams with geotags. We have implemented maPodWalk Caster to solve the problems of syndicating and aggregating geotagged audio tours. The platform provides a place-related aggregation by storing geotagged audio stream and new experiments on place-related audio stream sharing opportunities for geospatial communication. 1. Introduction There are web-based broadcasting content called Podcast. It allows people to create and distribute various kinds of audio content for their interest such as ones for introducing a person’s interest. The large number of free Podcast is increasing on the Internet for commercial and non-commercial purposes. Some Podcast is made for guiding and telling stories about the real world. This kind of Podcast is often called PodWalk. -

Description of Methodology Podcast Metrics
Description of Methodology Podcast Metrics BY TRITON DIGITALÒ Publication Information © 2021 Triton Digital. All rights reserved. Published by Triton Digital. All Rights Reserved. 1440 Ste-Catherine W, Suite 1200 Montreal QC H3G 1R8 Canada 514-448-4037 www.tritondigital.com Document Version Description of Methodology – Podcast Metrics Document Version 5 (2021-06-29) Trademarks TRITON DIGITAL is a registered trademark of Triton Digital Canada Inc. All other trademarks belong to their respective owners. Disclaimer Notice No part of this publication may be reproduced, transmitted, transcribed, stored in a retrieval system, translated into any other language in any form or by any means, electronic or mechanical, including photocopying or recording, for any purpose, without the express permission of Triton Digital. Triton Digital has made every effort to ensure the accuracy of the information contained herein. However, due to continuing product development, the information is subject to change without notice. Customer Support https://support.tritondigital.com/ TRITON DIGITAL | Description of Methodology – Podcast Metrics (v5) Page 2 Contents 1. Scope .............................................................................................................. 4 1.1. Products and Services Included .......................................................................................... 4 1.2. Metrics Definitions ............................................................................................................. 5 1.3. Metrics Scope -

Using Blogs on the End-User Website
USER GUIDE Blogs Schoolwires® Centricity™ Schoolwires Centricity Blogs TABLE OF CONTENTS Introduction ......................................................................................................................... 1 Audience and Objectives ................................................................................................ 1 Overview ......................................................................................................................... 1 Adding a New Blog Page .................................................................................................... 3 Adding a New Posting ........................................................................................................ 5 Working with Postings ...................................................................................................... 11 Sorting Postings ............................................................................................................ 11 Editing a Posting ........................................................................................................... 11 Moderating Comments.................................................................................................. 12 Working with an Unapproved Comment .................................................................. 14 Working with an Approved Comment ...................................................................... 17 Deleting a Posting ........................................................................................................ -
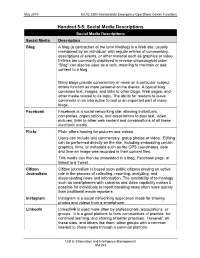
E/L/G 2300 Intermediate Emergency Operations Center Functions
May 2019 E/L/G 2300 Intermediate Emergency Operations Center Functions Handout 5-5: Social Media Descriptions Social Media Descriptions Social Media Description Blog A blog (a contraction of the term Weblog) is a Web site, usually maintained by an individual, with regular entries of commentary, descriptions of events, or other material such as graphics or video. Entries are commonly displayed in reverse-chronological order. “Blog” can also be used as a verb, meaning to maintain or add content to a blog. Many blogs provide commentary or news on a particular subject; others function as more personal online diaries. A typical blog combines text, images, and links to other blogs, Web pages, and other media related to its topic. The ability for readers to leave comments in an interactive format is an important part of many blogs. Facebook Facebook is a social networking site, allowing individuals, companies, organizations, and associations to post text, video, pictures, links to other web content and combinations of all these electronic media. Flickr Flickr offers hosting for pictures and videos. Users can include text commentary, group photos or video. Editing can be performed directly on the site, including embedding certain graphics, links, or metadata such as the GPS coordinates, date and time an image was recorded in their content files. This media can then be embedded in a blog, Facebook page, or linked to a Tweet. Citizen Citizen journalism is based upon public citizens playing an active Journalism role in the process of collecting, reporting, analyzing, and disseminating news and information. The availability of technology such as smartphones with cameras and video capability makes it possible for individuals to report breaking news often more quickly than traditional media reporters. -

An Introduction to Georss: a Standards Based Approach for Geo-Enabling RSS Feeds
Open Geospatial Consortium Inc. Date: 2006-07-19 Reference number of this document: OGC 06-050r3 Version: 1.0.0 Category: OpenGIS® White Paper Editors: Carl Reed OGC White Paper An Introduction to GeoRSS: A Standards Based Approach for Geo-enabling RSS feeds. Warning This document is not an OGC Standard. It is distributed for review and comment. It is subject to change without notice and may not be referred to as an OGC Standard. Recipients of this document are invited to submit, with their comments, notification of any relevant patent rights of which they are aware and to provide supporting do Document type: OpenGIS® White Paper Document subtype: White Paper Document stage: APPROVED Document language: English OGC 06-050r3 Contents Page i. Preface – Executive Summary........................................................................................ iv ii. Submitting organizations............................................................................................... iv iii. GeoRSS White Paper and OGC contact points............................................................ iv iv. Future work.....................................................................................................................v Foreword........................................................................................................................... vi Introduction...................................................................................................................... vii 1 Scope.................................................................................................................................1 -

History Contents
RSS - Wikipedia, the free encyclopedia Page 1 of 6 RSS From Wikipedia, the free encyclopedia (Redirected from RSS feeds) RSS (most commonly expanded as Really Simple RSS Syndication ) is a family of web feed formats used to publish frequently updated works—such as blog entries, news headlines, audio, and video—in a standardized format. [2] An RSS document (which is called a "feed", "web feed", [3] or "channel") includes full or summarized text, plus metadata such as publishing dates and authorship. Web feeds benefit publishers by letting them syndicate content automatically. They benefit readers who want to subscribe to timely updates The RSS logo from favored websites or to aggregate feeds from many sites into one place. RSS feeds can be read Filename .rss, .xml using software called an "RSS reader", "feed extension reader", or "aggregator", which can be web-based, application/rss+xml desktop-based, or mobile-device-based. A Internet standardized XML file format allows the media type (Registration Being information to be published once and viewed by Prepared) [1] many different programs. The user subscribes to a feed by entering into the reader the feed's URI or Type of Web syndication by clicking an RSS icon in a web browser that format initiates the subscription process. The RSS reader Extended XML checks the user's subscribed feeds regularly for from new work, downloads any updates that it finds, and provides a user interface to monitor and read the feeds. RSS formats are specified using XML, a generic specification for the creation of data formats. Although RSS formats have evolved from as early as March 1999, [4] it was between 2005 and 2006 when RSS gained widespread use, and the (" ") icon was decided upon by several major Web browsers. -

Podcast, Videocast and Screencast
7/9/2013 Blogging or internet boadcasting • Tips for blogging 1. Fun: The most important part of blogging is having fun and loving your blog. 2. Other media: Why limit yourself to just a blog? 3. Promotion: Commenting on other blogs and getting your blog noticed joins up with social networking sites, but do NOT SPAM ! 4. Collaboration: Use online relationships to collaborate on blog posts and expand your readership – encourage comments, comment on other people’s blogs, link freely and share traffic 5. Social networking: link your newest blog post to your Twitter/FB/Google+ etc. Broadcast Yourself: account for more exposure. 6. Diversity: Multi-media is almost a must these days. Text, video, photo, audio use them all and use them frequently to back up your comments. Podcast, Videocast and Screencast. 7. Brevity: Break up text with cuts, subheadings, bullet lists, photos to better catch the readers eye. 8. Personality: Write what you know, Write from your heart but don’t take the comments personally. There are mean, anonymous people out there surfing the web leaving rude, baseless comments, but there are also plenty more people with constructive comments to offer. 9. Originality: Find your Niche and hold tightly to it 10. Consistency: Posting once a day is considered normal. If you post three times a week, every week, this is considered the bare minimum for attracting and maintaining a strong readership. http://ec.l.thumbs.canstockphoto.com/canstock13762719.jpg http://media.rodemic.com/images/mic-chooser/soundbooth-button-broadcast.png http://www.sokalmediagroup.com/images/Broadcast-Button.jpg http://us.cdn1.123rf.com/168nwm/myvector/myvector1306/myvector130600104/20084211-antenna-smartphone-icon.jpgc Broadcast Yourself: Communications software Podcast • This type of software allows two computers with • A podcast is a type of digital media consisting modems to communicate through audio, video, of an episodic series of audio radio, video, and/or chat-based means. -

Trust-Based Revision for Expressive Web Syndication
Trust-Based Revision for Expressive Web Syndication Jennifer Golbeck1 and Christian Halaschek-Wiener2 1College of Information Studies 2Department of Computer Science University of Maryland, College Park College Park, Maryland 20742 {golbeck,halasche}@cs.umd.edu Abstract Interest in web-based syndication systems has been growing as information streams onto the web at an increasing rate. Technologies, like the standard Semantic Web languages RDF and OWL, make it possible to create expressive representations of the content of publications and subscriptions in a syndication framework. Because these languages are based in description logics, this representation allows the application to reasoning to make more precise matching of user interests with published information. A challenge to this approach is that the consistency of the underlying knowledge base must be maintained for these techniques to work. With the frequent addition of information from new publications, it is likely that inconsistencies will arise. There are many potential mechanisms for choosing which inconsistent information to discard from the KB to regain consistency; in the case of news syndication, we argue keeping the most trusted information is important for generating the most valuable matches. Thus, in this article, we present algorithms for belief-base revision, and specifically look at the user’s trust in the information sources as a metric for deciding what to keep in the KB and what to remove. 1 Introduction The interest in web-based syndication systems has been growing as information streams onto the web at an increasing rate. In a typical syndication framework, a publisher posts feeds on the web and registers those feeds with a syndication broker. -

Web 2.0: Where Does Europe Stand?
Web 2.0: Where does Europe stand? Author: Sven Lindmark EUR 23969 EN - 2009 The mission of the JRC-IPTS is to provide customer-driven support to the EU policy- making process by developing science-based responses to policy challenges that have both a socio-economic as well as a scientific/technological dimension. European Commission Joint Research Centre Institute for Prospective Technological Studies Contact information Address: Edificio Expo. c/ Inca Garcilaso, 3. E-41092 Seville (Spain) E-mail: [email protected] Tel.: +34 954488318 Fax: +34 954488300 http://ipts.jrc.ec.europa.eu http://www.jrc.ec.europa.eu Legal Notice Neither the European Commission nor any person acting on behalf of the Commission is responsible for the use which might be made of this publication. Europe Direct is a service to help you find answers to your questions about the European Union Freephone number (*): 00 800 6 7 8 9 10 11 (*) Certain mobile telephone operators do not allow access to 00 800 numbers or these calls may be billed. A great deal of additional information on the European Union is available on the Internet. It can be accessed through the Europa server http://europa.eu/ JRC 53035 EUR 23969 EN ISBN 978-92-79-13182-0 ISSN 1018-5593 DOI 10.2791/16327 Luxembourg: Office for Official Publications of the European Communities © European Communities, 2009 Reproduction is authorised provided the source is acknowledged Printed in Spain PREFACE Information and Communication Technology (ICT) markets are exposed to a more rapid cycle of innovation and obsolescence than most other industries. -

Instructions for Creating a Podcast Page
U SER G U IDE Chapter 20 U sing Podcasts Schoolw ires Academ ic Portal Version 4.1 Schoolwires Academic Portal 4.1 Chapter 20: Using Podcasts TABLE O F CO N TEN TS Introduction to Managing Podcasts .................................................................................... 1 What is Podcasting?............................................................................................................ 1 What is a Podcast?.......................................................................................................... 1 What is Podcasting? ....................................................................................................... 2 What are RSS/XML files (AKA “web feeds”)? ............................................................. 2 What is “Automatic Distribution”?................................................................................. 3 What are Mp3’s?............................................................................................................. 3 How does Schoolwires facilitate Podcasting? .................................................................... 4 Podcast Module Overview.................................................................................................. 4 Podcast Module Overview.................................................................................................. 5 Podcast Page ................................................................................................................... 5 How to Subscribe to Your Podcast Page ....................................................................... -

Social Media Marketing
Social Media Marketing Small businesses that are considering online marketing strategies will find this booklet useful. This booklet focuses on using social media marketing techniques to advertise your business. You may want to read this booklet in conjunction with other booklets in this series that profile other online marketing strategies. These booklets are entitled: “Increasing Traffic to Your Website Through Search Engine Optimization” and “Successful Online Display Advertising”. What is Social Media Marketing? Social Media Marketing makes use of social media sites to raise visibility on the Internet and to promote “Web 2.0 (or Web 2) is the popular term products and services. Social media sites are useful for advanced Internet technology and for building social (and business) networks, and applications including blogs, wikis, RSS and for exchanging ideas and knowledge. social bookmarking. The expression was originally coined by O’Reilly Media and Social media networking is part of a trend known MediaLive International in 2004, following as Web 2.0, which refers to changes in the way a conference dealing with next-generation users and software developers use the Web. It is a Web concepts and issues”. more collaborative use of the Web that enhances creativity and knowledge exchange. It is a more Source: Whatis.com interactive and user-driven way to help users participate and collaborate over the Web through open applications and services. It is critical, therefore, that content is accessible to the user; the user should Social Media Marketing Techniques be able to create, share, remix, and repurpose content. Some examples of social media marketing Technologies that are accessible and affordable like techniques are: Ajax (a method of building interactive applications for the Web that processes user requests immediately) • Joining relevant online communities and RSS (Really Simple Syndication) support Web 2.0 or social networking sites to help principles such as “user empowerment.” promote your business. -

Web Standards.Pdf
BOOKS FOR PROFESSIONALS BY PROFESSIONALS® Sikos, Ph.D. RELATED Web Standards Web Standards: Mastering HTML5, CSS3, and XML gives you a deep understand- ing of how web standards can be applied to improve your website. You will also find solutions to some of the most common website problems. You will learn how to create fully standards-compliant websites and provide search engine-optimized Web documents with faster download times, accurate rendering, lower development costs, and easy maintenance. Web Standards: Mastering HTML5, CSS3, and XML describes how you can make the most of web standards, through technology discussions as well as practical sam- ple code. As a web developer, you’ll have seen problems with inconsistent appearance and behavior of the same site in different browsers. Web standards can and should be used to completely eliminate these problems. With Web Standards, you’ll learn how to: • Hand code valid markup, styles, and news feeds • Provide meaningful semantics and machine-readable metadata • Restrict markup to semantics and provide reliable layout • Achieve full standards compliance Web standardization is not a sacrifice! By using this book, we can create and maintain a better, well-formed Web for everyone. CSS3, and XML CSS3, Mastering HTML5, US $49.99 Shelve in Web Development/General User level: Intermediate–Advanced SOURCE CODE ONLINE www.apress.com www.it-ebooks.info For your convenience Apress has placed some of the front matter material after the index. Please use the Bookmarks and Contents at a Glance links to access them. www.it-ebooks.info Contents at a Glance About the Author................................................................................................