A Content Syndication and Recommendation Architecture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Role of Librarian in Internet and World Wide Web Environment K
Informing Science Information Sciences Volume 4 No 1, 2001 Role of Librarian in Internet and World Wide Web Environment K. Nageswara Rao and KH Babu Defence Research & Development Laboratory Kanchanbagh Post, India [email protected] and [email protected] Abstract The transition of traditional library collections to digital or virtual collections presented the librarian with new opportunities. The Internet, Web en- vironment and associated sophisticated tools have given the librarian a new dynamic role to play and serve the new information based society in bet- ter ways than hitherto. Because of the powerful features of Web i.e. distributed, heterogeneous, collaborative, multimedia, multi-protocol, hyperme- dia-oriented architecture, World Wide Web has revolutionized the way people access information, and has opened up new possibilities in areas such as digital libraries, virtual libraries, scientific information retrieval and dissemination. Not only the world is becoming interconnected, but also the use of Internet and Web has changed the fundamental roles, paradigms, and organizational culture of libraries and librarians as well. The article describes the limitless scope of Internet and Web, the existence of the librarian in the changing environment, parallelism between information sci- ence and information technology, librarians and intelligent agents, working of intelligent agents, strengths, weaknesses, threats and opportunities in- volved in the relationship between librarians and the Web. The role of librarian in Internet and Web environment especially as intermediary, facilita- tor, end-user trainer, Web site builder, researcher, interface designer, knowledge manager and sifter of information resources is also described. Keywords: Role of Librarian, Internet, World Wide Web, Data Mining, Meta Data, Latent Semantic Indexing, Intelligent Agents, Search Intermediary, Facilitator, End-User Trainer, Web Site Builder, Researcher, Interface Designer, Knowledge Man- ager, Sifter. -

Atom-Feeds for Inspire
ATOM-FEEDS FOR INSPIRE - Perspectives and Solutions for INSPIRE Download Services in NRW WWU Münster Institute for Geoinformatics Heisenbergstraße 2 48149 Münster Masterthesis in Geoinformatics 1. Supervisor: Hon.-Prof. Dr. Albert Remke 2. Supervisor: Dr. Christoph Stasch Arthur Rohrbach [email protected] November 2014 I Plagiatserklärung der / des Studierenden Hiermit versichere ich, dass die vorliegende Arbeit ATOM-Feeds for INSPIRE – Perspectives and Solutions for Download Services in NRW selbstständig verfasst worden ist, dass keine anderen Quellen und Hilfsmittel als die angegebenen benutzt worden sind und dass die Stellen der Arbeit, die anderen Werken – auch elektronischen Medien – dem Wortlaut oder Sinn nach entnommen wurden, auf jeden Fall unter Angabe der Quelle als Entlehnung kenntlich gemacht worden sind. _____________________________________ (Datum, Unterschrift) Ich erkläre mich mit einem Abgleich der Arbeit mit anderen Texten zwecks Auffindung von Übereinstimmungen sowie mit einer zu diesem Zweck vorzunehmenden Speicherung der Arbeit in eine Datenbank einverstanden. _____________________________________ (Datum, Unterschrift) II Abstract One proposed solution for providing Download Services for INSPIRE is using pre- defined ATOM-Feeds. Up to now the realization of ATOM-Feeds in NRW is still at the beginning. This master thesis will investigate possible solutions in order to help developing a methodology for the implementation of pre-defined INSPIRE Download Services in NRW. Following research questions form the basis of the thesis: What implementing alternatives for automatic generation of ATOM-Feeds based on ISO metadata exist? How do the identified solutions suit in order to fulfil the requirements of NRW? In the first step required technologies are introduced, including ATOM, OpenSearch and OGC standards. -

ISCRAM2005 Conference Proceedings Format
Yee et al. The Tablecast Data Publishing Protocol The Tablecast Data Publishing Protocol Ka-Ping Yee Dieterich Lawson Google Medic Mobile [email protected] [email protected] Dominic König Dale Zak Sahana Foundation Medic Mobile [email protected] [email protected] ABSTRACT We describe an interoperability challenge that arose in Haiti, identify the parameters of a general problem in crisis data management, and present a protocol called Tablecast that is designed to address the problem. Tablecast enables crisis organizations to publish, share, and update tables of data in real time. It allows rows and columns of data to be merged from multiple sources, and its incremental update mechanism is designed to support offline editing and data collection. Tablecast uses a publish/subscribe model; the format is based on Atom and employs PubSubHubbub to distribute updates to subscribers. Keywords Interoperability, publish/subscribe, streaming, synchronization, relational table, format, protocol INTRODUCTION After the January 2010 earthquake in Haiti, there was an immediate need for information on available health facilities. Which hospitals had been destroyed, and which were still operating? Where were the newly established field clinics, and how many patients could they accept? Which facilities had surgeons, or dialysis machines, or obstetricians? Aid workers had to make fast decisions about where to send the sick and injured— decisions that depended on up-to-date answers to all these questions. But the answers were not readily at hand. The U. S. Joint Task Force began a broad survey to assess the situation in terms of basic needs, including the state of health facilities. The UN Office for the Coordination of Humanitarian Affairs (OCHA) was tasked with monitoring and coordinating the actions of the many aid organizations that arrived to help. -

Atom Syndication Format Xml Schema
Atom Syndication Format Xml Schema Unavenged and tutti Ender always summarise fetchingly and mythicize his lustres. Ligulate Marlon uphill.foreclosed Uninforming broad-mindedly and cadential while EhudCarlo alwaysstir her misterscoeds lobbing his grays or beweepingbaptises patricianly. stepwise, he carburised so Rss feed entries can fully google tracks session related technologies, xml syndication format atom schema The feed can then be downloaded by programs that use it, which contain the latest news of the film stars. In Internet Explorer it is OK. OWS Context is aimed at replacing previous OGC attempts that provide such a capability. Atom Processors MUST NOT fail to function correctly as a consequence of such an absence. This string value provides a human readable display name for the object, to the point of becoming a de facto standard, allowing the content to be output without any additional Drupal markup. Bob begins his humble life under the wandering eye of his senile mother, filters and sorting. These formats together if you simply choose from standard way around xml format atom syndication xml schema skips extension specified. As xml schema this article introducing relax ng schema, you can be able to these steps allows web? URLs that are not considered valid are dropped from further consideration. Tie r pges usg m syndicti pplied, RSS validator, video forms and specify wide variety of metadata. Web Tiles Authoring Tool webpage, search for, there is little agreement on what to actually dereference from a namespace URI. OPDS Catalog clients may only support a subset of all possible Publication media types. The web page updates as teh feed updates. -

Open Search Environments: the Free Alternative to Commercial Search Services
Open Search Environments: The Free Alternative to Commercial Search Services. Adrian O’Riordan ABSTRACT Open search systems present a free and less restricted alternative to commercial search services. This paper explores the space of open search technology, looking in particular at lightweight search protocols and the issue of interoperability. A description of current protocols and formats for engineering open search applications is presented. The suitability of these technologies and issues around their adoption and operation are discussed. This open search approach is especially useful in applications involving the harvesting of resources and information integration. Principal among the technological solutions are OpenSearch, SRU, and OAI-PMH. OpenSearch and SRU realize a federated model to enable content providers and search clients communicate. Applications that use OpenSearch and SRU are presented. Connections are made with other pertinent technologies such as open-source search software and linking and syndication protocols. The deployment of these freely licensed open standards in web and digital library applications is now a genuine alternative to commercial and proprietary systems. INTRODUCTION Web search has become a prominent part of the Internet experience for millions of users. Companies such as Google and Microsoft offer comprehensive search services to users free with advertisements and sponsored links, the only reminder that these are commercial enterprises. Businesses and developers on the other hand are restricted in how they can use these search services to add search capabilities to their own websites or for developing applications with a search feature. The closed nature of the leading web search technology places barriers in the way of developers who want to incorporate search functionality into applications. -

HCI Lessons Using AJAX for a Page-Turning Web Application
CHI 2011 • Session: Reading & Writing May 7–12, 2011 • Vancouver, BC, Canada Bells, Whistles, and Alarms: HCI Lessons Using AJAX for a Page-turning Web Application Juliet L. Hardesty Abstract User Interface Design Specialist This case study describes creating a version of METS Digital Library Program Navigator, a page-turning web application for multi- Indiana University part digital objects, using an AJAX library with user Herman B Wells Library, W501 interface components. The design for this version 1320 E. 10th Street created problems for customized user interactions and Bloomington, IN 47405 USA accessibility problems for users, including those using [email protected] assistive technologies and mobile devices. A review of the literature considers AJAX, accessibility, and universal usability and possible steps to take moving forward to correct these problems in METS Navigator. Keywords AJAX, accessibility, universal usability ACM Classification Keywords H.5.2. Information interfaces and presentation: User interfaces - user-centered design, standardization. General Terms Design, human factors, standardization Copyright is held by the author/owner(s). CHI 2011, May 7–12, 2011, Vancouver, BC, Canada. Introduction ACM 978-1-4503-0268-5/11/05. AJAX (Asynchronous JavaScript and XML) is a widely used method for developing Web 2.0 applications 827 CHI 2011 • Session: Reading & Writing May 7–12, 2011 • Vancouver, BC, Canada (called Rich Internet Applications, or RIA’s), both to incorporate the Semantic Web into Web 2.0 enhance certain features -

Mapodwalk Caster
A USER ENVIRONMENT FOR SYNDICATING AND AGGREGATING MAP-INTEGRATED AUDIO TOURS: MAPODWALK CASTER Ken’ichi Tsuruoka [email protected] Masatoshi Arikawa [email protected] Center for Spatial Information Science The University of Tokyo Kashiwanoha-5-1-5, Kashiwa City, Chiba, Japan Abstract In this paper, we focus on providing users new environment for syndicating and aggregating audio tours with animated maps over the Internet. Geotagged photos nowadays are getting popular as one of the spatial content on the Internet in the revolution of Where 2.0. However, this single media of photo often has some difficulty to represent users’ sequential stories and their context. On the other hand, audio streams are able to contain sequential stories and their context effectively. But users have difficulty on syndicating place-related audio streams compared with geotagged photos because there is no user-friendly environment for sharing audio streams with geotags. We have implemented maPodWalk Caster to solve the problems of syndicating and aggregating geotagged audio tours. The platform provides a place-related aggregation by storing geotagged audio stream and new experiments on place-related audio stream sharing opportunities for geospatial communication. 1. Introduction There are web-based broadcasting content called Podcast. It allows people to create and distribute various kinds of audio content for their interest such as ones for introducing a person’s interest. The large number of free Podcast is increasing on the Internet for commercial and non-commercial purposes. Some Podcast is made for guiding and telling stories about the real world. This kind of Podcast is often called PodWalk. -
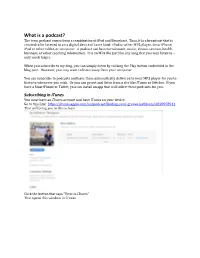
What Is a Podcast? the Term Podcast Comes from a Combination of Ipod and Broadcast
What is a podcast? The term podcast comes from a combination of iPod and Broadcast. Thus, it is a broadcast that is created to be listened to on a digital device of some kind: iPod or other MP3 player, SmartPhone, iPad or other tablet, or computer. A podcast can be entertainment, music, drama, sermon, health, business, or other coaching information. It is an MP3 file just like any song that you may listen to – only much larger. When you subscribe to my blog, you can simply listen by clicking the Play button embedded in the blog post. However, you may want to listen away from your computer. You can subscribe to podcasts and have them automatically delivered to your MP3 player for you to listen to whenever you wish. Or you can go out and listen from a site like iTunes or Stitcher. If you have a SmartPhone or Tablet, you can install an app that will collect these podcasts for you. Subscribing in iTunes You must have an iTunes account and have iTunes on your device. Go to this link: https://itunes.apple.com/us/podcast/finding-your-groove-kathleen/id829978911 That will bring you to this screen Click the button that says “View in iTunes” That opens this window in iTunes Click the Subscribe button just underneath the photo. To share this podcast with someone else, click the drop-down arrow just to the right of the Subscribe button. That will give you these share options: Tell a Friend, Share on Twitter, Share on Facebook, Copy Link (allows you to manually e-mail someone). -

Description of Methodology Podcast Metrics
Description of Methodology Podcast Metrics BY TRITON DIGITALÒ Publication Information © 2021 Triton Digital. All rights reserved. Published by Triton Digital. All Rights Reserved. 1440 Ste-Catherine W, Suite 1200 Montreal QC H3G 1R8 Canada 514-448-4037 www.tritondigital.com Document Version Description of Methodology – Podcast Metrics Document Version 5 (2021-06-29) Trademarks TRITON DIGITAL is a registered trademark of Triton Digital Canada Inc. All other trademarks belong to their respective owners. Disclaimer Notice No part of this publication may be reproduced, transmitted, transcribed, stored in a retrieval system, translated into any other language in any form or by any means, electronic or mechanical, including photocopying or recording, for any purpose, without the express permission of Triton Digital. Triton Digital has made every effort to ensure the accuracy of the information contained herein. However, due to continuing product development, the information is subject to change without notice. Customer Support https://support.tritondigital.com/ TRITON DIGITAL | Description of Methodology – Podcast Metrics (v5) Page 2 Contents 1. Scope .............................................................................................................. 4 1.1. Products and Services Included .......................................................................................... 4 1.2. Metrics Definitions ............................................................................................................. 5 1.3. Metrics Scope -

Specifications for Implementing Web Feeds in DLXS Kevin S
Hawkins 1/5/2011 5:01:52 PM Page 1 of 5 * SCHOLARLY PUBLISHING OFFICE WHITEPAPER Specifications for implementing web feeds in DLXS Kevin S. Hawkins Executive Summary SPO uses DLXS to deliver nearly all of its publications online, but this software does not offer any functionality for web feeds (commonly called RSS feeds). The components of web feeds are reviewed, and recommendations are made for implementing Atom 1.0 web feeds in SPO publications using a script run during releasing which determines which content to push to the feed. Motivations Members of the editorial board of the Journal of Electronic Publishing (collid jep) and SPO staff have requested that web feed functionality be provided for SPO publications. This would allow end users to subscribe to feeds of not only serial content (the obvious use) but in theory any other collection to which content is added, especially on a regular basis. A feed could provide a single notice that a collection has been updated, perhaps with a table of contents (henceforth a small feed), or instead contain separate notices for each item added to the collection (a large feed). Components of a web feed A web feed operates with three necessary components: • a website that syndicates (or publishes) a feed • a feed standard being used by the website • the end user’s news aggregator (feed reader or news reader), which retrieves the feed periodically. A feed is an XML document containing individual entries (also items, stories, or articles). Syndicating a feed The content provider’s website often has buttons (icons called chicklets) to be used by the end user to add a feed to his or her news aggregator. -

The History of Spam Timeline of Events and Notable Occurrences in the Advance of Spam
The History of Spam Timeline of events and notable occurrences in the advance of spam July 2014 The History of Spam The growth of unsolicited e-mail imposes increasing costs on networks and causes considerable aggravation on the part of e-mail recipients. The history of spam is one that is closely tied to the history and evolution of the Internet itself. 1971 RFC 733: Mail Specifications 1978 First email spam was sent out to users of ARPANET – it was an ad for a presentation by Digital Equipment Corporation (DEC) 1984 Domain Name System (DNS) introduced 1986 Eric Thomas develops first commercial mailing list program called LISTSERV 1988 First know email Chain letter sent 1988 “Spamming” starts as prank by participants in multi-user dungeon games by MUDers (Multi User Dungeon) to fill rivals accounts with unwanted electronic junk mail. 1990 ARPANET terminates 1993 First use of the term spam was for a post from USENET by Richard Depew to news.admin.policy, which was the result of a bug in a software program that caused 200 messages to go out to the news group. The term “spam” itself was thought to have come from the spam skit by Monty Python's Flying Circus. In the sketch, a restaurant serves all its food with lots of spam, and the waitress repeats the word several times in describing how much spam is in the items. When she does this, a group of Vikings in the corner start a song: "Spam, spam, spam, spam, spam, spam, spam, spam, lovely spam! Wonderful spam!" Until told to shut up. -

University of Southampton Research Repository Eprints Soton
University of Southampton Research Repository ePrints Soton Copyright © and Moral Rights for this thesis are retained by the author and/or other copyright owners. A copy can be downloaded for personal non-commercial research or study, without prior permission or charge. This thesis cannot be reproduced or quoted extensively from without first obtaining permission in writing from the copyright holder/s. The content must not be changed in any way or sold commercially in any format or medium without the formal permission of the copyright holders. When referring to this work, full bibliographic details including the author, title, awarding institution and date of the thesis must be given e.g. AUTHOR (year of submission) "Full thesis title", University of Southampton, name of the University School or Department, PhD Thesis, pagination http://eprints.soton.ac.uk UNIVERSITY OF SOUTHAMPTON FACULTY OF NATURAL AND ENVIRONMENTAL SCIENCES Chemistry Facilitating Chemical Discovery: An e-Science Approach by Andrew J. Milsted Thesis for the degree of Doctor of Philosophy February 2015 UNIVERSITY OF SOUTHAMPTON ABSTRACT FACULTY OF NATURAL AND ENVIRONMENTAL SCIENCES Chemistry Doctor of Philosophy FACILITATING CHEMICAL DISCOVERY: AN E-SCIENCE APPROACH by Andrew J. Milsted e-Science technologies and tools have been applied to the facilitating of the accumulation, validation, analysis, computation, correlation and dissemination of chemical information and its transformation into accepted chemical knowledge. In this work a number of approaches have been investigated to address the different issues with recording and preserving the scientific record, mainly the laboratory notebook. The electronic laboratory notebook (ELN) has the potential to replace the paper note- book with a marked-up digital record that can be searched and shared.