Floating Point Arithmetic
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bit Nove Signal Interface Processor
www.audison.eu bit Nove Signal Interface Processor POWER SUPPLY CONNECTION Voltage 10.8 ÷ 15 VDC From / To Personal Computer 1 x Micro USB Operating power supply voltage 7.5 ÷ 14.4 VDC To Audison DRC AB / DRC MP 1 x AC Link Idling current 0.53 A Optical 2 sel Optical In 2 wire control +12 V enable Switched off without DRC 1 mA Mem D sel Memory D wire control GND enable Switched off with DRC 4.5 mA CROSSOVER Remote IN voltage 4 ÷ 15 VDC (1mA) Filter type Full / Hi pass / Low Pass / Band Pass Remote OUT voltage 10 ÷ 15 VDC (130 mA) Linkwitz @ 12/24 dB - Butterworth @ Filter mode and slope ART (Automatic Remote Turn ON) 2 ÷ 7 VDC 6/12/18/24 dB Crossover Frequency 68 steps @ 20 ÷ 20k Hz SIGNAL STAGE Phase control 0° / 180° Distortion - THD @ 1 kHz, 1 VRMS Output 0.005% EQUALIZER (20 ÷ 20K Hz) Bandwidth @ -3 dB 10 Hz ÷ 22 kHz S/N ratio @ A weighted Analog Input Equalizer Automatic De-Equalization N.9 Parametrics Equalizers: ±12 dB;10 pole; Master Input 102 dBA Output Equalizer 20 ÷ 20k Hz AUX Input 101.5 dBA OPTICAL IN1 / IN2 Inputs 110 dBA TIME ALIGNMENT Channel Separation @ 1 kHz 85 dBA Distance 0 ÷ 510 cm / 0 ÷ 200.8 inches Input sensitivity Pre Master 1.2 ÷ 8 VRMS Delay 0 ÷ 15 ms Input sensitivity Speaker Master 3 ÷ 20 VRMS Step 0,08 ms; 2,8 cm / 1.1 inch Input sensitivity AUX Master 0.3 ÷ 5 VRMS Fine SET 0,02 ms; 0,7 cm / 0.27 inch Input impedance Pre In / Speaker In / AUX 15 kΩ / 12 Ω / 15 kΩ GENERAL REQUIREMENTS Max Output Level (RMS) @ 0.1% THD 4 V PC connections USB 1.1 / 2.0 / 3.0 Compatible Microsoft Windows (32/64 bit): Vista, INPUT STAGE Software/PC requirements Windows 7, Windows 8, Windows 10 Low level (Pre) Ch1 ÷ Ch6; AUX L/R Video Resolution with screen resize min. -

Signedness-Agnostic Program Analysis: Precise Integer Bounds for Low-Level Code
Signedness-Agnostic Program Analysis: Precise Integer Bounds for Low-Level Code Jorge A. Navas, Peter Schachte, Harald Søndergaard, and Peter J. Stuckey Department of Computing and Information Systems, The University of Melbourne, Victoria 3010, Australia Abstract. Many compilers target common back-ends, thereby avoid- ing the need to implement the same analyses for many different source languages. This has led to interest in static analysis of LLVM code. In LLVM (and similar languages) most signedness information associated with variables has been compiled away. Current analyses of LLVM code tend to assume that either all values are signed or all are unsigned (except where the code specifies the signedness). We show how program analysis can simultaneously consider each bit-string to be both signed and un- signed, thus improving precision, and we implement the idea for the spe- cific case of integer bounds analysis. Experimental evaluation shows that this provides higher precision at little extra cost. Our approach turns out to be beneficial even when all signedness information is available, such as when analysing C or Java code. 1 Introduction The “Low Level Virtual Machine” LLVM is rapidly gaining popularity as a target for compilers for a range of programming languages. As a result, the literature on static analysis of LLVM code is growing (for example, see [2, 7, 9, 11, 12]). LLVM IR (Intermediate Representation) carefully specifies the bit- width of all integer values, but in most cases does not specify whether values are signed or unsigned. This is because, for most operations, two’s complement arithmetic (treating the inputs as signed numbers) produces the same bit-vectors as unsigned arithmetic. -

Design of 32 Bit Floating Point Addition and Subtraction Units Based on IEEE 754 Standard Ajay Rathor, Lalit Bandil Department of Electronics & Communication Eng
International Journal of Engineering Research & Technology (IJERT) ISSN: 2278-0181 Vol. 2 Issue 6, June - 2013 Design Of 32 Bit Floating Point Addition And Subtraction Units Based On IEEE 754 Standard Ajay Rathor, Lalit Bandil Department of Electronics & Communication Eng. Acropolis Institute of Technology and Research Indore, India Abstract Precision format .Single precision format, Floating point arithmetic implementation the most basic format of the ANSI/IEEE described various arithmetic operations like 754-1985 binary floating-point arithmetic addition, subtraction, multiplication, standard. Double precision and quad division. In science computation this circuit precision described more bit operation so at is useful. A general purpose arithmetic unit same time we perform 32 and 64 bit of require for all operations. In this paper operation of arithmetic unit. Floating point single precision floating point arithmetic includes single precision, double precision addition and subtraction is described. This and quad precision floating point format paper includes single precision floating representation and provide implementation point format representation and provides technique of various arithmetic calculation. implementation technique of addition and Normalization and alignment are useful for subtraction arithmetic calculations. Low operation and floating point number should precision custom format is useful for reduce be normalized before any calculation [3]. the associated circuit costs and increasing their speed. I consider the implementation ofIJERT IJERT2. Floating Point format Representation 32 bit addition and subtraction unit for floating point arithmetic. Floating point number has mainly three formats which are single precision, double Keywords: Addition, Subtraction, single precision and quad precision. precision, doubles precision, VERILOG Single Precision Format: Single-precision HDL floating-point format is a computer number 1. -

Metaclasses: Generative C++
Metaclasses: Generative C++ Document Number: P0707 R3 Date: 2018-02-11 Reply-to: Herb Sutter ([email protected]) Audience: SG7, EWG Contents 1 Overview .............................................................................................................................................................2 2 Language: Metaclasses .......................................................................................................................................7 3 Library: Example metaclasses .......................................................................................................................... 18 4 Applying metaclasses: Qt moc and C++/WinRT .............................................................................................. 35 5 Alternatives for sourcedefinition transform syntax .................................................................................... 41 6 Alternatives for applying the transform .......................................................................................................... 43 7 FAQs ................................................................................................................................................................. 46 8 Revision history ............................................................................................................................................... 51 Major changes in R3: Switched to function-style declaration syntax per SG7 direction in Albuquerque (old: $class M new: constexpr void M(meta::type target, -

Meta-Class Features for Large-Scale Object Categorization on a Budget
Meta-Class Features for Large-Scale Object Categorization on a Budget Alessandro Bergamo Lorenzo Torresani Dartmouth College Hanover, NH, U.S.A. faleb, [email protected] Abstract cation accuracy over a predefined set of classes, and without consideration of the computational costs of the recognition. In this paper we introduce a novel image descriptor en- We believe that these two assumptions do not meet the abling accurate object categorization even with linear mod- requirements of modern applications of large-scale object els. Akin to the popular attribute descriptors, our feature categorization. For example, test-recognition efficiency is a vector comprises the outputs of a set of classifiers evaluated fundamental requirement to be able to scale object classi- on the image. However, unlike traditional attributes which fication to Web photo repositories, such as Flickr, which represent hand-selected object classes and predefined vi- are growing at rates of several millions new photos per sual properties, our features are learned automatically and day. Furthermore, while a fixed set of object classifiers can correspond to “abstract” categories, which we name meta- be used to annotate pictures with a set of predefined tags, classes. Each meta-class is a super-category obtained by the interactive nature of searching and browsing large im- grouping a set of object classes such that, collectively, they age collections calls for the ability to allow users to define are easy to distinguish from other sets of categories. By us- their own personal query categories to be recognized and ing “learnability” of the meta-classes as criterion for fea- retrieved from the database, ideally in real-time. -

Floating Point Representation (Unsigned) Fixed-Point Representation
Floating point representation (Unsigned) Fixed-point representation The numbers are stored with a fixed number of bits for the integer part and a fixed number of bits for the fractional part. Suppose we have 8 bits to store a real number, where 5 bits store the integer part and 3 bits store the fractional part: 1 0 1 1 1.0 1 1 $ 2& 2% 2$ 2# 2" 2'# 2'$ 2'% Smallest number: Largest number: (Unsigned) Fixed-point representation Suppose we have 64 bits to store a real number, where 32 bits store the integer part and 32 bits store the fractional part: "# "% + /+ !"# … !%!#!&. (#(%(" … ("% % = * !+ 2 + * (+ 2 +,& +,# "# "& & /# % /"% = !"#× 2 +!"&× 2 + ⋯ + !&× 2 +(#× 2 +(%× 2 + ⋯ + ("%× 2 0 ∞ (Unsigned) Fixed-point representation Range: difference between the largest and smallest numbers possible. More bits for the integer part ⟶ increase range Precision: smallest possible difference between any two numbers More bits for the fractional part ⟶ increase precision "#"$"%. '$'#'( # OR "$"%. '$'#'(') # Wherever we put the binary point, there is a trade-off between the amount of range and precision. It can be hard to decide how much you need of each! Scientific Notation In scientific notation, a number can be expressed in the form ! = ± $ × 10( where $ is a coefficient in the range 1 ≤ $ < 10 and + is the exponent. 1165.7 = 0.0004728 = Floating-point numbers A floating-point number can represent numbers of different order of magnitude (very large and very small) with the same number of fixed bits. In general, in the binary system, a floating number can be expressed as ! = ± $ × 2' $ is the significand, normally a fractional value in the range [1.0,2.0) . -

Floating Point Numbers and Arithmetic
Overview Floating Point Numbers & • Floating Point Numbers Arithmetic • Motivation: Decimal Scientific Notation – Binary Scientific Notation • Floating Point Representation inside computer (binary) – Greater range, precision • Decimal to Floating Point conversion, and vice versa • Big Idea: Type is not associated with data • MIPS floating point instructions, registers CS 160 Ward 1 CS 160 Ward 2 Review of Numbers Other Numbers •What about other numbers? • Computers are made to deal with –Very large numbers? (seconds/century) numbers 9 3,155,760,00010 (3.1557610 x 10 ) • What can we represent in N bits? –Very small numbers? (atomic diameter) -8 – Unsigned integers: 0.0000000110 (1.010 x 10 ) 0to2N -1 –Rationals (repeating pattern) 2/3 (0.666666666. .) – Signed Integers (Two’s Complement) (N-1) (N-1) –Irrationals -2 to 2 -1 21/2 (1.414213562373. .) –Transcendentals e (2.718...), π (3.141...) •All represented in scientific notation CS 160 Ward 3 CS 160 Ward 4 Scientific Notation Review Scientific Notation for Binary Numbers mantissa exponent Mantissa exponent 23 -1 6.02 x 10 1.0two x 2 decimal point radix (base) “binary point” radix (base) •Computer arithmetic that supports it called •Normalized form: no leadings 0s floating point, because it represents (exactly one digit to left of decimal point) numbers where binary point is not fixed, as it is for integers •Alternatives to representing 1/1,000,000,000 –Declare such variable in C as float –Normalized: 1.0 x 10-9 –Not normalized: 0.1 x 10-8, 10.0 x 10-10 CS 160 Ward 5 CS 160 Ward 6 Floating -

Floating Point Numbers Dr
Numbers Representaion Floating point numbers Dr. Tassadaq Hussain Riphah International University Real Numbers • Two’s complement representation deal with signed integer values only. • Without modification, these formats are not useful in scientific or business applications that deal with real number values. • Floating-point representation solves this problem. Floating-Point Representation • If we are clever programmers, we can perform floating-point calculations using any integer format. • This is called floating-point emulation, because floating point values aren’t stored as such; we just create programs that make it seem as if floating- point values are being used. • Most of today’s computers are equipped with specialized hardware that performs floating-point arithmetic with no special programming required. —Not embedded processors! Floating-Point Representation • Floating-point numbers allow an arbitrary number of decimal places to the right of the decimal point. For example: 0.5 0.25 = 0.125 • They are often expressed in scientific notation. For example: 0.125 = 1.25 10-1 5,000,000 = 5.0 106 Floating-Point Representation • Computers use a form of scientific notation for floating-point representation • Numbers written in scientific notation have three components: Floating-Point Representation • Computer representation of a floating-point number consists of three fixed-size fields: • This is the standard arrangement of these fields. Note: Although “significand” and “mantissa” do not technically mean the same thing, many people use these terms interchangeably. We use the term “significand” to refer to the fractional part of a floating point number. Floating-Point Representation • The one-bit sign field is the sign of the stored value. -
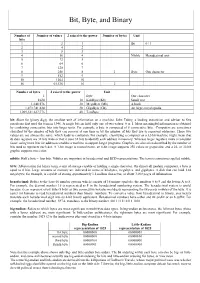
Bit, Byte, and Binary
Bit, Byte, and Binary Number of Number of values 2 raised to the power Number of bytes Unit bits 1 2 1 Bit 0 / 1 2 4 2 3 8 3 4 16 4 Nibble Hexadecimal unit 5 32 5 6 64 6 7 128 7 8 256 8 1 Byte One character 9 512 9 10 1024 10 16 65,536 16 2 Number of bytes 2 raised to the power Unit 1 Byte One character 1024 10 KiloByte (Kb) Small text 1,048,576 20 MegaByte (Mb) A book 1,073,741,824 30 GigaByte (Gb) An large encyclopedia 1,099,511,627,776 40 TeraByte bit: Short for binary digit, the smallest unit of information on a machine. John Tukey, a leading statistician and adviser to five presidents first used the term in 1946. A single bit can hold only one of two values: 0 or 1. More meaningful information is obtained by combining consecutive bits into larger units. For example, a byte is composed of 8 consecutive bits. Computers are sometimes classified by the number of bits they can process at one time or by the number of bits they use to represent addresses. These two values are not always the same, which leads to confusion. For example, classifying a computer as a 32-bit machine might mean that its data registers are 32 bits wide or that it uses 32 bits to identify each address in memory. Whereas larger registers make a computer faster, using more bits for addresses enables a machine to support larger programs. -

A Decimal Floating-Point Speciftcation
A Decimal Floating-point Specification Michael F. Cowlishaw, Eric M. Schwarz, Ronald M. Smith, Charles F. Webb IBM UK IBM Server Division P.O. Box 31, Birmingham Rd. 2455 South Rd., MS:P310 Warwick CV34 5JL. UK Poughkeepsie, NY 12601 USA [email protected] [email protected] Abstract ing is required. In the fixed point formats, rounding must be explicitly applied in software rather than be- Even though decimal arithmetic is pervasive in fi- ing provided by the hardware. To address these and nancial and commercial transactions, computers are other limitations, we propose implementing a decimal stdl implementing almost all arithmetic calculations floating-point format. But what should this format be? using binary arithmetic. As chip real estate becomes This paper discusses the issues of defining a decimal cheaper it is becoming likely that more computer man- floating-point format. ufacturers will provide processors with decimal arith- First, we consider the goals of the specification. It metic engines. Programming languages and databases must be compliant with standards already in place. are expanding the decimal data types available whale One standard we consider is the ANSI X3.274-1996 there has been little change in the base hardware. As (Programming Language REXX) [l]. This standard a result, each language and application is defining a contains a definition of an integrated floating-point and different arithmetic and few have considered the efi- integer decimal arithmetic which avoids the need for ciency of hardware implementations when setting re- two distinct data types and representations. The other quirements. relevant standard is the ANSI/IEEE 854-1987 (Radix- In this paper, we propose a decimal format which Independent Floating-point Arithmetic) [a]. -

Floating Point Arithmetic
Systems Architecture Lecture 14: Floating Point Arithmetic Jeremy R. Johnson Anatole D. Ruslanov William M. Mongan Some or all figures from Computer Organization and Design: The Hardware/Software Approach, Third Edition, by David Patterson and John Hennessy, are copyrighted material (COPYRIGHT 2004 MORGAN KAUFMANN PUBLISHERS, INC. ALL RIGHTS RESERVED). Lec 14 Systems Architecture 1 Introduction • Objective: To provide hardware support for floating point arithmetic. To understand how to represent floating point numbers in the computer and how to perform arithmetic with them. Also to learn how to use floating point arithmetic in MIPS. • Approximate arithmetic – Finite Range – Limited Precision • Topics – IEEE format for single and double precision floating point numbers – Floating point addition and multiplication – Support for floating point computation in MIPS Lec 14 Systems Architecture 2 Distribution of Floating Point Numbers e = -1 e = 0 e = 1 • 3 bit mantissa 1.00 X 2^(-1) = 1/2 1.00 X 2^0 = 1 1.00 X 2^1 = 2 1.01 X 2^(-1) = 5/8 1.01 X 2^0 = 5/4 1.01 X 2^1 = 5/2 • exponent {-1,0,1} 1.10 X 2^(-1) = 3/4 1.10 X 2^0 = 3/2 1.10 X 2^1= 3 1.11 X 2^(-1) = 7/8 1.11 X 2^0 = 7/4 1.11 X 2^1 = 7/2 0 1 2 3 Lec 14 Systems Architecture 3 Floating Point • An IEEE floating point representation consists of – A Sign Bit (no surprise) – An Exponent (“times 2 to the what?”) – Mantissa (“Significand”), which is assumed to be 1.xxxxx (thus, one bit of the mantissa is implied as 1) – This is called a normalized representation • So a mantissa = 0 really is interpreted to be 1.0, and a mantissa of all 1111 is interpreted to be 1.1111 • Special cases are used to represent denormalized mantissas (true mantissa = 0), NaN, etc., as will be discussed. -

OMG Meta Object Facility (MOF) Core Specification
Date : October 2019 OMG Meta Object Facility (MOF) Core Specification Version 2.5.1 OMG Document Number: formal/2019-10-01 Standard document URL: https://www.omg.org/spec/MOF/2.5.1 Normative Machine-Readable Files: https://www.omg.org/spec/MOF/20131001/MOF.xmi Informative Machine-Readable Files: https://www.omg.org/spec/MOF/20131001/CMOFConstraints.ocl https://www.omg.org/spec/MOF/20131001/EMOFConstraints.ocl Copyright © 2003, Adaptive Copyright © 2003, Ceira Technologies, Inc. Copyright © 2003, Compuware Corporation Copyright © 2003, Data Access Technologies, Inc. Copyright © 2003, DSTC Copyright © 2003, Gentleware Copyright © 2003, Hewlett-Packard Copyright © 2003, International Business Machines Copyright © 2003, IONA Copyright © 2003, MetaMatrix Copyright © 2015, Object Management Group Copyright © 2003, Softeam Copyright © 2003, SUN Copyright © 2003, Telelogic AB Copyright © 2003, Unisys USE OF SPECIFICATION - TERMS, CONDITIONS & NOTICES The material in this document details an Object Management Group specification in accordance with the terms, conditions and notices set forth below. This document does not represent a commitment to implement any portion of this specification in any company's products. The information contained in this document is subject to change without notice. LICENSES The companies listed above have granted to the Object Management Group, Inc. (OMG) a nonexclusive, royalty-free, paid up, worldwide license to copy and distribute this document and to modify this document and distribute copies of the modified version. Each of the copyright holders listed above has agreed that no person shall be deemed to have infringed the copyright in the included material of any such copyright holder by reason of having used the specification set forth herein or having conformed any computer software to the specification.