CS/COE1541: Introduction to Computer Architecture Dept
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lab 7: Floating-Point Addition 0.0
Lab 7: Floating-Point Addition 0.0 Introduction In this lab, you will write a MIPS assembly language function that performs floating-point addition. You will then run your program using PCSpim (just as you did in Lab 6). For testing, you are provided a program that calls your function to compute the value of the mathematical constant e. For those with no assembly language experience, this will be a long lab, so plan your time accordingly. Background You should be familiar with the IEEE 754 Floating-Point Standard, which is described in Section 3.6 of your book. (Hopefully you have read that section carefully!) Here we will be dealing only with single precision floating- point values, which are formatted as follows (this is also described in the “Floating-Point Representation” subsec- tion of Section 3.6 in your book): Sign Exponent (8 bits) Significand (23 bits) 31 30 29 ... 24 23 22 21 ... 0 Remember that the exponent is biased by 127, which means that an exponent of zero is represented by 127 (01111111). The exponent is not encoded using 2s-complement. The significand is always positive, and the sign bit is kept separately. Note that the actual significand is 24 bits long; the first bit is always a 1 and thus does not need to be stored explicitly. This will be important to remember when you write your function! There are several details of IEEE 754 that you will not have to worry about in this lab. For example, the expo- nents 00000000 and 11111111 are reserved for special purposes that are described in your book (representing zero, denormalized numbers and NaNs). -

File Systems and Disk Layout I/O: the Big Picture
File Systems and Disk Layout I/O: The Big Picture Processor interrupts Cache Memory Bus I/O Bridge Main I/O Bus Memory Disk Graphics Network Controller Controller Interface Disk Disk Graphics Network 1 Rotational Media Track Sector Arm Cylinder Platter Head Access time = seek time + rotational delay + transfer time seek time = 5-15 milliseconds to move the disk arm and settle on a cylinder rotational delay = 8 milliseconds for full rotation at 7200 RPM: average delay = 4 ms transfer time = 1 millisecond for an 8KB block at 8 MB/s Bandwidth utilization is less than 50% for any noncontiguous access at a block grain. Disks and Drivers Disk hardware and driver software provide basic facilities for nonvolatile secondary storage (block devices). 1. OS views the block devices as a collection of volumes. A logical volume may be a partition ofasinglediskora concatenation of multiple physical disks (e.g., RAID). 2. OS accesses each volume as an array of fixed-size sectors. Identify sector (or block) by unique (volumeID, sector ID). Read/write operations DMA data to/from physical memory. 3. Device interrupts OS on I/O completion. ISR wakes up process, updates internal records, etc. 2 Using Disk Storage Typical operating systems use disks in three different ways: 1. System calls allow user programs to access a “raw” disk. Unix: special device file identifies volume directly. Any process that can open thedevicefilecanreadorwriteany specific sector in the disk volume. 2. OS uses disk as backing storage for virtual memory. OS manages volume transparently as an “overflow area” for VM contents that do not “fit” in physical memory. -

Bit Nove Signal Interface Processor
www.audison.eu bit Nove Signal Interface Processor POWER SUPPLY CONNECTION Voltage 10.8 ÷ 15 VDC From / To Personal Computer 1 x Micro USB Operating power supply voltage 7.5 ÷ 14.4 VDC To Audison DRC AB / DRC MP 1 x AC Link Idling current 0.53 A Optical 2 sel Optical In 2 wire control +12 V enable Switched off without DRC 1 mA Mem D sel Memory D wire control GND enable Switched off with DRC 4.5 mA CROSSOVER Remote IN voltage 4 ÷ 15 VDC (1mA) Filter type Full / Hi pass / Low Pass / Band Pass Remote OUT voltage 10 ÷ 15 VDC (130 mA) Linkwitz @ 12/24 dB - Butterworth @ Filter mode and slope ART (Automatic Remote Turn ON) 2 ÷ 7 VDC 6/12/18/24 dB Crossover Frequency 68 steps @ 20 ÷ 20k Hz SIGNAL STAGE Phase control 0° / 180° Distortion - THD @ 1 kHz, 1 VRMS Output 0.005% EQUALIZER (20 ÷ 20K Hz) Bandwidth @ -3 dB 10 Hz ÷ 22 kHz S/N ratio @ A weighted Analog Input Equalizer Automatic De-Equalization N.9 Parametrics Equalizers: ±12 dB;10 pole; Master Input 102 dBA Output Equalizer 20 ÷ 20k Hz AUX Input 101.5 dBA OPTICAL IN1 / IN2 Inputs 110 dBA TIME ALIGNMENT Channel Separation @ 1 kHz 85 dBA Distance 0 ÷ 510 cm / 0 ÷ 200.8 inches Input sensitivity Pre Master 1.2 ÷ 8 VRMS Delay 0 ÷ 15 ms Input sensitivity Speaker Master 3 ÷ 20 VRMS Step 0,08 ms; 2,8 cm / 1.1 inch Input sensitivity AUX Master 0.3 ÷ 5 VRMS Fine SET 0,02 ms; 0,7 cm / 0.27 inch Input impedance Pre In / Speaker In / AUX 15 kΩ / 12 Ω / 15 kΩ GENERAL REQUIREMENTS Max Output Level (RMS) @ 0.1% THD 4 V PC connections USB 1.1 / 2.0 / 3.0 Compatible Microsoft Windows (32/64 bit): Vista, INPUT STAGE Software/PC requirements Windows 7, Windows 8, Windows 10 Low level (Pre) Ch1 ÷ Ch6; AUX L/R Video Resolution with screen resize min. -

The Hexadecimal Number System and Memory Addressing
C5537_App C_1107_03/16/2005 APPENDIX C The Hexadecimal Number System and Memory Addressing nderstanding the number system and the coding system that computers use to U store data and communicate with each other is fundamental to understanding how computers work. Early attempts to invent an electronic computing device met with disappointing results as long as inventors tried to use the decimal number sys- tem, with the digits 0–9. Then John Atanasoff proposed using a coding system that expressed everything in terms of different sequences of only two numerals: one repre- sented by the presence of a charge and one represented by the absence of a charge. The numbering system that can be supported by the expression of only two numerals is called base 2, or binary; it was invented by Ada Lovelace many years before, using the numerals 0 and 1. Under Atanasoff’s design, all numbers and other characters would be converted to this binary number system, and all storage, comparisons, and arithmetic would be done using it. Even today, this is one of the basic principles of computers. Every character or number entered into a computer is first converted into a series of 0s and 1s. Many coding schemes and techniques have been invented to manipulate these 0s and 1s, called bits for binary digits. The most widespread binary coding scheme for microcomputers, which is recog- nized as the microcomputer standard, is called ASCII (American Standard Code for Information Interchange). (Appendix B lists the binary code for the basic 127- character set.) In ASCII, each character is assigned an 8-bit code called a byte. -

POINTER (IN C/C++) What Is a Pointer?
POINTER (IN C/C++) What is a pointer? Variable in a program is something with a name, the value of which can vary. The way the compiler and linker handles this is that it assigns a specific block of memory within the computer to hold the value of that variable. • The left side is the value in memory. • The right side is the address of that memory Dereferencing: • int bar = *foo_ptr; • *foo_ptr = 42; // set foo to 42 which is also effect bar = 42 • To dereference ted, go to memory address of 1776, the value contain in that is 25 which is what we need. Differences between & and * & is the reference operator and can be read as "address of“ * is the dereference operator and can be read as "value pointed by" A variable referenced with & can be dereferenced with *. • Andy = 25; • Ted = &andy; All expressions below are true: • andy == 25 // true • &andy == 1776 // true • ted == 1776 // true • *ted == 25 // true How to declare pointer? • Type + “*” + name of variable. • Example: int * number; • char * c; • • number or c is a variable is called a pointer variable How to use pointer? • int foo; • int *foo_ptr = &foo; • foo_ptr is declared as a pointer to int. We have initialized it to point to foo. • foo occupies some memory. Its location in memory is called its address. &foo is the address of foo Assignment and pointer: • int *foo_pr = 5; // wrong • int foo = 5; • int *foo_pr = &foo; // correct way Change the pointer to the next memory block: • int foo = 5; • int *foo_pr = &foo; • foo_pr ++; Pointer arithmetics • char *mychar; // sizeof 1 byte • short *myshort; // sizeof 2 bytes • long *mylong; // sizeof 4 byts • mychar++; // increase by 1 byte • myshort++; // increase by 2 bytes • mylong++; // increase by 4 bytes Increase pointer is different from increase the dereference • *P++; // unary operation: go to the address of the pointer then increase its address and return a value • (*P)++; // get the value from the address of p then increase the value by 1 Arrays: • int array[] = {45,46,47}; • we can call the first element in the array by saying: *array or array[0]. -

Signedness-Agnostic Program Analysis: Precise Integer Bounds for Low-Level Code
Signedness-Agnostic Program Analysis: Precise Integer Bounds for Low-Level Code Jorge A. Navas, Peter Schachte, Harald Søndergaard, and Peter J. Stuckey Department of Computing and Information Systems, The University of Melbourne, Victoria 3010, Australia Abstract. Many compilers target common back-ends, thereby avoid- ing the need to implement the same analyses for many different source languages. This has led to interest in static analysis of LLVM code. In LLVM (and similar languages) most signedness information associated with variables has been compiled away. Current analyses of LLVM code tend to assume that either all values are signed or all are unsigned (except where the code specifies the signedness). We show how program analysis can simultaneously consider each bit-string to be both signed and un- signed, thus improving precision, and we implement the idea for the spe- cific case of integer bounds analysis. Experimental evaluation shows that this provides higher precision at little extra cost. Our approach turns out to be beneficial even when all signedness information is available, such as when analysing C or Java code. 1 Introduction The “Low Level Virtual Machine” LLVM is rapidly gaining popularity as a target for compilers for a range of programming languages. As a result, the literature on static analysis of LLVM code is growing (for example, see [2, 7, 9, 11, 12]). LLVM IR (Intermediate Representation) carefully specifies the bit- width of all integer values, but in most cases does not specify whether values are signed or unsigned. This is because, for most operations, two’s complement arithmetic (treating the inputs as signed numbers) produces the same bit-vectors as unsigned arithmetic. -

Metaclasses: Generative C++
Metaclasses: Generative C++ Document Number: P0707 R3 Date: 2018-02-11 Reply-to: Herb Sutter ([email protected]) Audience: SG7, EWG Contents 1 Overview .............................................................................................................................................................2 2 Language: Metaclasses .......................................................................................................................................7 3 Library: Example metaclasses .......................................................................................................................... 18 4 Applying metaclasses: Qt moc and C++/WinRT .............................................................................................. 35 5 Alternatives for sourcedefinition transform syntax .................................................................................... 41 6 Alternatives for applying the transform .......................................................................................................... 43 7 FAQs ................................................................................................................................................................. 46 8 Revision history ............................................................................................................................................... 51 Major changes in R3: Switched to function-style declaration syntax per SG7 direction in Albuquerque (old: $class M new: constexpr void M(meta::type target, -

Semiconductor Memories
Semiconductor Memories Prof. MacDonald Types of Memories! l" Volatile Memories –" require power supply to retain information –" dynamic memories l" use charge to store information and require refreshing –" static memories l" use feedback (latch) to store information – no refresh required l" Non-Volatile Memories –" ROM (Mask) –" EEPROM –" FLASH – NAND or NOR –" MRAM Memory Hierarchy! 100pS RF 100’s of bytes L1 1nS SRAM 10’s of Kbytes 10nS L2 100’s of Kbytes SRAM L3 100’s of 100nS DRAM Mbytes 1us Disks / Flash Gbytes Memory Hierarchy! l" Large memories are slow l" Fast memories are small l" Memory hierarchy gives us illusion of large memory space with speed of small memory. –" temporal locality –" spatial locality Register Files ! l" Fastest and most robust memory array l" Largest bit cell size l" Basically an array of large latches l" No sense amps – bits provide full rail data out l" Often multi-ported (i.e. 8 read ports, 2 write ports) l" Often used with ALUs in the CPU as source/destination l" Typically less than 10,000 bits –" 32 32-bit fixed point registers –" 32 60-bit floating point registers SRAM! l" Same process as logic so often combined on one die l" Smaller bit cell than register file – more dense but slower l" Uses sense amp to detect small bit cell output l" Fastest for reads and writes after register file l" Large per bit area costs –" six transistors (single port), eight transistors (dual port) l" L1 and L2 Cache on CPU is always SRAM l" On-chip Buffers – (Ethernet buffer, LCD buffer) l" Typical sizes 16k by 32 Static Memory -

Meta-Class Features for Large-Scale Object Categorization on a Budget
Meta-Class Features for Large-Scale Object Categorization on a Budget Alessandro Bergamo Lorenzo Torresani Dartmouth College Hanover, NH, U.S.A. faleb, [email protected] Abstract cation accuracy over a predefined set of classes, and without consideration of the computational costs of the recognition. In this paper we introduce a novel image descriptor en- We believe that these two assumptions do not meet the abling accurate object categorization even with linear mod- requirements of modern applications of large-scale object els. Akin to the popular attribute descriptors, our feature categorization. For example, test-recognition efficiency is a vector comprises the outputs of a set of classifiers evaluated fundamental requirement to be able to scale object classi- on the image. However, unlike traditional attributes which fication to Web photo repositories, such as Flickr, which represent hand-selected object classes and predefined vi- are growing at rates of several millions new photos per sual properties, our features are learned automatically and day. Furthermore, while a fixed set of object classifiers can correspond to “abstract” categories, which we name meta- be used to annotate pictures with a set of predefined tags, classes. Each meta-class is a super-category obtained by the interactive nature of searching and browsing large im- grouping a set of object classes such that, collectively, they age collections calls for the ability to allow users to define are easy to distinguish from other sets of categories. By us- their own personal query categories to be recognized and ing “learnability” of the meta-classes as criterion for fea- retrieved from the database, ideally in real-time. -

Subtyping Recursive Types
ACM Transactions on Programming Languages and Systems, 15(4), pp. 575-631, 1993. Subtyping Recursive Types Roberto M. Amadio1 Luca Cardelli CNRS-CRIN, Nancy DEC, Systems Research Center Abstract We investigate the interactions of subtyping and recursive types, in a simply typed λ-calculus. The two fundamental questions here are whether two (recursive) types are in the subtype relation, and whether a term has a type. To address the first question, we relate various definitions of type equivalence and subtyping that are induced by a model, an ordering on infinite trees, an algorithm, and a set of type rules. We show soundness and completeness between the rules, the algorithm, and the tree semantics. We also prove soundness and a restricted form of completeness for the model. To address the second question, we show that to every pair of types in the subtype relation we can associate a term whose denotation is the uniquely determined coercion map between the two types. Moreover, we derive an algorithm that, when given a term with implicit coercions, can infer its least type whenever possible. 1This author's work has been supported in part by Digital Equipment Corporation and in part by the Stanford-CNR Collaboration Project. Page 1 Contents 1. Introduction 1.1 Types 1.2 Subtypes 1.3 Equality of Recursive Types 1.4 Subtyping of Recursive Types 1.5 Algorithm outline 1.6 Formal development 2. A Simply Typed λ-calculus with Recursive Types 2.1 Types 2.2 Terms 2.3 Equations 3. Tree Ordering 3.1 Subtyping Non-recursive Types 3.2 Folding and Unfolding 3.3 Tree Expansion 3.4 Finite Approximations 4. -

A Variable Precision Hardware Acceleration for Scientific Computing Andrea Bocco
A variable precision hardware acceleration for scientific computing Andrea Bocco To cite this version: Andrea Bocco. A variable precision hardware acceleration for scientific computing. Discrete Mathe- matics [cs.DM]. Université de Lyon, 2020. English. NNT : 2020LYSEI065. tel-03102749 HAL Id: tel-03102749 https://tel.archives-ouvertes.fr/tel-03102749 Submitted on 7 Jan 2021 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. N°d’ordre NNT : 2020LYSEI065 THÈSE de DOCTORAT DE L’UNIVERSITÉ DE LYON Opérée au sein de : CEA Grenoble Ecole Doctorale InfoMaths EDA N17° 512 (Informatique Mathématique) Spécialité de doctorat :Informatique Soutenue publiquement le 29/07/2020, par : Andrea Bocco A variable precision hardware acceleration for scientific computing Devant le jury composé de : Frédéric Pétrot Président et Rapporteur Professeur des Universités, TIMA, Grenoble, France Marc Dumas Rapporteur Professeur des Universités, École Normale Supérieure de Lyon, France Nathalie Revol Examinatrice Docteure, École Normale Supérieure de Lyon, France Fabrizio Ferrandi Examinateur Professeur associé, Politecnico di Milano, Italie Florent de Dinechin Directeur de thèse Professeur des Universités, INSA Lyon, France Yves Durand Co-directeur de thèse Docteur, CEA Grenoble, France Cette thèse est accessible à l'adresse : http://theses.insa-lyon.fr/publication/2020LYSEI065/these.pdf © [A. -
Bit, Byte, and Binary
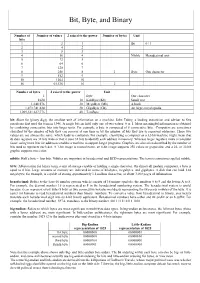
Bit, Byte, and Binary Number of Number of values 2 raised to the power Number of bytes Unit bits 1 2 1 Bit 0 / 1 2 4 2 3 8 3 4 16 4 Nibble Hexadecimal unit 5 32 5 6 64 6 7 128 7 8 256 8 1 Byte One character 9 512 9 10 1024 10 16 65,536 16 2 Number of bytes 2 raised to the power Unit 1 Byte One character 1024 10 KiloByte (Kb) Small text 1,048,576 20 MegaByte (Mb) A book 1,073,741,824 30 GigaByte (Gb) An large encyclopedia 1,099,511,627,776 40 TeraByte bit: Short for binary digit, the smallest unit of information on a machine. John Tukey, a leading statistician and adviser to five presidents first used the term in 1946. A single bit can hold only one of two values: 0 or 1. More meaningful information is obtained by combining consecutive bits into larger units. For example, a byte is composed of 8 consecutive bits. Computers are sometimes classified by the number of bits they can process at one time or by the number of bits they use to represent addresses. These two values are not always the same, which leads to confusion. For example, classifying a computer as a 32-bit machine might mean that its data registers are 32 bits wide or that it uses 32 bits to identify each address in memory. Whereas larger registers make a computer faster, using more bits for addresses enables a machine to support larger programs.