Meta-Class Features for Large-Scale Object Categorization on a Budget
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bit Nove Signal Interface Processor
www.audison.eu bit Nove Signal Interface Processor POWER SUPPLY CONNECTION Voltage 10.8 ÷ 15 VDC From / To Personal Computer 1 x Micro USB Operating power supply voltage 7.5 ÷ 14.4 VDC To Audison DRC AB / DRC MP 1 x AC Link Idling current 0.53 A Optical 2 sel Optical In 2 wire control +12 V enable Switched off without DRC 1 mA Mem D sel Memory D wire control GND enable Switched off with DRC 4.5 mA CROSSOVER Remote IN voltage 4 ÷ 15 VDC (1mA) Filter type Full / Hi pass / Low Pass / Band Pass Remote OUT voltage 10 ÷ 15 VDC (130 mA) Linkwitz @ 12/24 dB - Butterworth @ Filter mode and slope ART (Automatic Remote Turn ON) 2 ÷ 7 VDC 6/12/18/24 dB Crossover Frequency 68 steps @ 20 ÷ 20k Hz SIGNAL STAGE Phase control 0° / 180° Distortion - THD @ 1 kHz, 1 VRMS Output 0.005% EQUALIZER (20 ÷ 20K Hz) Bandwidth @ -3 dB 10 Hz ÷ 22 kHz S/N ratio @ A weighted Analog Input Equalizer Automatic De-Equalization N.9 Parametrics Equalizers: ±12 dB;10 pole; Master Input 102 dBA Output Equalizer 20 ÷ 20k Hz AUX Input 101.5 dBA OPTICAL IN1 / IN2 Inputs 110 dBA TIME ALIGNMENT Channel Separation @ 1 kHz 85 dBA Distance 0 ÷ 510 cm / 0 ÷ 200.8 inches Input sensitivity Pre Master 1.2 ÷ 8 VRMS Delay 0 ÷ 15 ms Input sensitivity Speaker Master 3 ÷ 20 VRMS Step 0,08 ms; 2,8 cm / 1.1 inch Input sensitivity AUX Master 0.3 ÷ 5 VRMS Fine SET 0,02 ms; 0,7 cm / 0.27 inch Input impedance Pre In / Speaker In / AUX 15 kΩ / 12 Ω / 15 kΩ GENERAL REQUIREMENTS Max Output Level (RMS) @ 0.1% THD 4 V PC connections USB 1.1 / 2.0 / 3.0 Compatible Microsoft Windows (32/64 bit): Vista, INPUT STAGE Software/PC requirements Windows 7, Windows 8, Windows 10 Low level (Pre) Ch1 ÷ Ch6; AUX L/R Video Resolution with screen resize min. -

Objects and Classes in Python Documentation Release 0.1
Objects and classes in Python Documentation Release 0.1 Jonathan Fine Sep 27, 2017 Contents 1 Decorators 2 1.1 The decorator syntax.........................................2 1.2 Bound methods............................................3 1.3 staticmethod() .........................................3 1.4 classmethod() ..........................................3 1.5 The call() decorator.......................................4 1.6 Nesting decorators..........................................4 1.7 Class decorators before Python 2.6.................................5 2 Constructing classes 6 2.1 The empty class...........................................6 3 dict_from_class() 8 3.1 The __dict__ of the empty class...................................8 3.2 Is the doc-string part of the body?..................................9 3.3 Definition of dict_from_class() ...............................9 4 property_from_class() 10 4.1 About properties........................................... 10 4.2 Definition of property_from_class() ............................ 11 4.3 Using property_from_class() ................................ 11 4.4 Unwanted keys............................................ 11 5 Deconstructing classes 13 6 type(name, bases, dict) 14 6.1 Constructing the empty class..................................... 14 6.2 Constructing any class........................................ 15 6.3 Specifying __doc__, __name__ and __module__.......................... 15 7 Subclassing int 16 7.1 Mutable and immutable types.................................... 16 7.2 -

Unified Modeling Language 2.0 Part 1 - Introduction
UML 2.0 – Tutorial (v4) 1 Unified Modeling Language 2.0 Part 1 - Introduction Prof. Dr. Harald Störrle Dr. Alexander Knapp University of Innsbruck University of Munich mgm technology partners (c) 2005-2006, Dr. H. Störrle, Dr. A. Knapp UML 2.0 – Tutorial (v4) 2 1 - Introduction History and Predecessors • The UML is the “lingua franca” of software engineering. • It subsumes, integrates and consolidates most predecessors. • Through the network effect, UML has a much broader spread and much better support (tools, books, trainings etc.) than other notations. • The transition from UML 1.x to UML 2.0 has – resolved a great number of issues; – introduced many new concepts and notations (often feebly defined); – overhauled and improved the internal structure completely. • While UML 2.0 still has many problems, current version (“the standard”) it is much better than what we ever had formal/05-07-04 of August ‘05 before. (c) 2005-2006, Dr. H. Störrle, Dr. A. Knapp UML 2.0 – Tutorial (v4) 3 1 - Introduction Usage Scenarios • UML has not been designed for specific, limited usages. • There is currently no consensus on the role of the UML: – Some see UML only as tool for sketching class diagrams representing Java programs. – Some believe that UML is “the prototype of the next generation of programming languages”. • UML is a really a system of languages (“notations”, “diagram types”) each of which may be used in a number of different situations. • UML is applicable for a multitude of purposes, during all phases of the software lifecycle, and for all sizes of systems - to varying degrees. -

Signedness-Agnostic Program Analysis: Precise Integer Bounds for Low-Level Code
Signedness-Agnostic Program Analysis: Precise Integer Bounds for Low-Level Code Jorge A. Navas, Peter Schachte, Harald Søndergaard, and Peter J. Stuckey Department of Computing and Information Systems, The University of Melbourne, Victoria 3010, Australia Abstract. Many compilers target common back-ends, thereby avoid- ing the need to implement the same analyses for many different source languages. This has led to interest in static analysis of LLVM code. In LLVM (and similar languages) most signedness information associated with variables has been compiled away. Current analyses of LLVM code tend to assume that either all values are signed or all are unsigned (except where the code specifies the signedness). We show how program analysis can simultaneously consider each bit-string to be both signed and un- signed, thus improving precision, and we implement the idea for the spe- cific case of integer bounds analysis. Experimental evaluation shows that this provides higher precision at little extra cost. Our approach turns out to be beneficial even when all signedness information is available, such as when analysing C or Java code. 1 Introduction The “Low Level Virtual Machine” LLVM is rapidly gaining popularity as a target for compilers for a range of programming languages. As a result, the literature on static analysis of LLVM code is growing (for example, see [2, 7, 9, 11, 12]). LLVM IR (Intermediate Representation) carefully specifies the bit- width of all integer values, but in most cases does not specify whether values are signed or unsigned. This is because, for most operations, two’s complement arithmetic (treating the inputs as signed numbers) produces the same bit-vectors as unsigned arithmetic. -

Csci 658-01: Software Language Engineering Python 3 Reflexive
CSci 658-01: Software Language Engineering Python 3 Reflexive Metaprogramming Chapter 3 H. Conrad Cunningham 4 May 2018 Contents 3 Decorators and Metaclasses 2 3.1 Basic Function-Level Debugging . .2 3.1.1 Motivating example . .2 3.1.2 Abstraction Principle, staying DRY . .3 3.1.3 Function decorators . .3 3.1.4 Constructing a debug decorator . .4 3.1.5 Using the debug decorator . .6 3.1.6 Case study review . .7 3.1.7 Variations . .7 3.1.7.1 Logging . .7 3.1.7.2 Optional disable . .8 3.2 Extended Function-Level Debugging . .8 3.2.1 Motivating example . .8 3.2.2 Decorators with arguments . .9 3.2.3 Prefix decorator . .9 3.2.4 Reformulated prefix decorator . 10 3.3 Class-Level Debugging . 12 3.3.1 Motivating example . 12 3.3.2 Class-level debugger . 12 3.3.3 Variation: Attribute access debugging . 14 3.4 Class Hierarchy Debugging . 16 3.4.1 Motivating example . 16 3.4.2 Review of objects and types . 17 3.4.3 Class definition process . 18 3.4.4 Changing the metaclass . 20 3.4.5 Debugging using a metaclass . 21 3.4.6 Why metaclasses? . 22 3.5 Chapter Summary . 23 1 3.6 Exercises . 23 3.7 Acknowledgements . 23 3.8 References . 24 3.9 Terms and Concepts . 24 Copyright (C) 2018, H. Conrad Cunningham Professor of Computer and Information Science University of Mississippi 211 Weir Hall P.O. Box 1848 University, MS 38677 (662) 915-5358 Note: This chapter adapts David Beazley’s debugly example presentation from his Python 3 Metaprogramming tutorial at PyCon’2013 [Beazley 2013a]. -

The Use of UML for Software Requirements Expression and Management
The Use of UML for Software Requirements Expression and Management Alex Murray Ken Clark Jet Propulsion Laboratory Jet Propulsion Laboratory California Institute of Technology California Institute of Technology Pasadena, CA 91109 Pasadena, CA 91109 818-354-0111 818-393-6258 [email protected] [email protected] Abstract— It is common practice to write English-language 1. INTRODUCTION ”shall” statements to embody detailed software requirements in aerospace software applications. This paper explores the This work is being performed as part of the engineering of use of the UML language as a replacement for the English the flight software for the Laser Ranging Interferometer (LRI) language for this purpose. Among the advantages offered by the of the Gravity Recovery and Climate Experiment (GRACE) Unified Modeling Language (UML) is a high degree of clarity Follow-On (F-O) mission. However, rather than use the real and precision in the expression of domain concepts as well as project’s model to illustrate our approach in this paper, we architecture and design. Can this quality of UML be exploited have developed a separate, ”toy” model for use here, because for the definition of software requirements? this makes it easier to avoid getting bogged down in project details, and instead to focus on the technical approach to While expressing logical behavior, interface characteristics, requirements expression and management that is the subject timeliness constraints, and other constraints on software using UML is commonly done and relatively straight-forward, achiev- of this paper. ing the additional aspects of the expression and management of software requirements that stakeholders expect, especially There is one exception to this choice: we will describe our traceability, is far less so. -

Metaclasses: Generative C++
Metaclasses: Generative C++ Document Number: P0707 R3 Date: 2018-02-11 Reply-to: Herb Sutter ([email protected]) Audience: SG7, EWG Contents 1 Overview .............................................................................................................................................................2 2 Language: Metaclasses .......................................................................................................................................7 3 Library: Example metaclasses .......................................................................................................................... 18 4 Applying metaclasses: Qt moc and C++/WinRT .............................................................................................. 35 5 Alternatives for sourcedefinition transform syntax .................................................................................... 41 6 Alternatives for applying the transform .......................................................................................................... 43 7 FAQs ................................................................................................................................................................. 46 8 Revision history ............................................................................................................................................... 51 Major changes in R3: Switched to function-style declaration syntax per SG7 direction in Albuquerque (old: $class M new: constexpr void M(meta::type target, -

Sysml Distilled: a Brief Guide to the Systems Modeling Language
ptg11539604 Praise for SysML Distilled “In keeping with the outstanding tradition of Addison-Wesley’s techni- cal publications, Lenny Delligatti’s SysML Distilled does not disappoint. Lenny has done a masterful job of capturing the spirit of OMG SysML as a practical, standards-based modeling language to help systems engi- neers address growing system complexity. This book is loaded with matter-of-fact insights, starting with basic MBSE concepts to distin- guishing the subtle differences between use cases and scenarios to illu- mination on namespaces and SysML packages, and even speaks to some of the more esoteric SysML semantics such as token flows.” — Jeff Estefan, Principal Engineer, NASA’s Jet Propulsion Laboratory “The power of a modeling language, such as SysML, is that it facilitates communication not only within systems engineering but across disci- plines and across the development life cycle. Many languages have the ptg11539604 potential to increase communication, but without an effective guide, they can fall short of that objective. In SysML Distilled, Lenny Delligatti combines just the right amount of technology with a common-sense approach to utilizing SysML toward achieving that communication. Having worked in systems and software engineering across many do- mains for the last 30 years, and having taught computer languages, UML, and SysML to many organizations and within the college setting, I find Lenny’s book an invaluable resource. He presents the concepts clearly and provides useful and pragmatic examples to get you off the ground quickly and enables you to be an effective modeler.” — Thomas W. Fargnoli, Lead Member of the Engineering Staff, Lockheed Martin “This book provides an excellent introduction to SysML. -

Metaclass Functions: Generative C++
Metaclass functions: Generative C++ Document Number: P0707 R4 Date: 2019-06-16 Reply-to: Herb Sutter ([email protected]) Audience: SG7, EWG Contents 1 Overview .............................................................................................................................................................2 2 Language: “Metaclass” functions .......................................................................................................................6 3 Library: Example metaclasses .......................................................................................................................... 18 4 Applying metaclasses: Qt moc and C++/WinRT .............................................................................................. 35 5 FAQs ................................................................................................................................................................. 41 R4: • Updated notes in §1.3 to track the current prototype, which now also has consteval support. • Added using metaclass function in the class body. Abstract The only way to make a language more powerful, but also make its programs simpler, is by abstraction: adding well-chosen abstractions that let programmers replace manual code patterns with saying directly what they mean. There are two major categories: Elevate coding patterns/idioms into new abstractions built into the language. For example, in current C++, range-for lets programmers directly declare “for each” loops with compiler support and enforcement. -

UML Basics: the Component Diagram
English Sign in (or register) Technical topics Evaluation software Community Events UML basics: The component diagram Donald Bell ([email protected]), IT Architect, IBM Corporation Summary: from The Rational Edge: This article introduces the component diagram, a structure diagram within the new Unified Modeling Language 2.0 specification. Date: 15 Dec 2004 Level: Introductory Also available in: Chinese Vietnamese Activity: 259392 views Comments: 3 (View | Add comment - Sign in) Average rating (629 votes) Rate this article This is the next installment in a series of articles about the essential diagrams used within the Unified Modeling Language, or UML. In my previous article on the UML's class diagram, (The Rational Edge, September 2004), I described how the class diagram's notation set is the basis for all UML 2's structure diagrams. Continuing down the track of UML 2 structure diagrams, this article introduces the component diagram. The diagram's purpose The component diagram's main purpose is to show the structural relationships between the components of a system. In UML 1.1, a component represented implementation items, such as files and executables. Unfortunately, this conflicted with the more common use of the term component," which refers to things such as COM components. Over time and across successive releases of UML, the original UML meaning of components was mostly lost. UML 2 officially changes the essential meaning of the component concept; in UML 2, components are considered autonomous, encapsulated units within a system or subsystem that provide one or more interfaces. Although the UML 2 specification does not strictly state it, components are larger design units that represent things that will typically be implemented using replaceable" modules. -
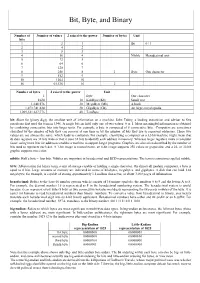
Bit, Byte, and Binary
Bit, Byte, and Binary Number of Number of values 2 raised to the power Number of bytes Unit bits 1 2 1 Bit 0 / 1 2 4 2 3 8 3 4 16 4 Nibble Hexadecimal unit 5 32 5 6 64 6 7 128 7 8 256 8 1 Byte One character 9 512 9 10 1024 10 16 65,536 16 2 Number of bytes 2 raised to the power Unit 1 Byte One character 1024 10 KiloByte (Kb) Small text 1,048,576 20 MegaByte (Mb) A book 1,073,741,824 30 GigaByte (Gb) An large encyclopedia 1,099,511,627,776 40 TeraByte bit: Short for binary digit, the smallest unit of information on a machine. John Tukey, a leading statistician and adviser to five presidents first used the term in 1946. A single bit can hold only one of two values: 0 or 1. More meaningful information is obtained by combining consecutive bits into larger units. For example, a byte is composed of 8 consecutive bits. Computers are sometimes classified by the number of bits they can process at one time or by the number of bits they use to represent addresses. These two values are not always the same, which leads to confusion. For example, classifying a computer as a 32-bit machine might mean that its data registers are 32 bits wide or that it uses 32 bits to identify each address in memory. Whereas larger registers make a computer faster, using more bits for addresses enables a machine to support larger programs. -

Middlesex University Research Repository
Middlesex University Research Repository An open access repository of Middlesex University research http://eprints.mdx.ac.uk Clark, Tony (1997) Metaclasses and reflection in smalltalk. Technical Report. University of Bradford. Available from Middlesex University’s Research Repository at http://eprints.mdx.ac.uk/6181/ Copyright: Middlesex University Research Repository makes the University’s research available electronically. Copyright and moral rights to this thesis/research project are retained by the author and/or other copyright owners. The work is supplied on the understanding that any use for commercial gain is strictly forbidden. A copy may be downloaded for personal, non-commercial, research or study without prior permission and without charge. Any use of the thesis/research project for private study or research must be properly acknowledged with reference to the work’s full bibliographic details. This thesis/research project may not be reproduced in any format or medium, or extensive quotations taken from it, or its content changed in any way, without first obtaining permission in writing from the copyright holder(s). If you believe that any material held in the repository infringes copyright law, please contact the Repository Team at Middlesex University via the following email address: [email protected] The item will be removed from the repository while any claim is being investigated. Metaclasses and Reection in Smalltalk A N Clark Department of Computing University of Bradford Bradford West Yorkshire BD DP UK email ANClarkcompbradacuk