Introduction to Probability
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lecture 22: Bivariate Normal Distribution Distribution
6.5 Conditional Distributions General Bivariate Normal Let Z1; Z2 ∼ N (0; 1), which we will use to build a general bivariate normal Lecture 22: Bivariate Normal Distribution distribution. 1 1 2 2 f (z1; z2) = exp − (z1 + z2 ) Statistics 104 2π 2 We want to transform these unit normal distributions to have the follow Colin Rundel arbitrary parameters: µX ; µY ; σX ; σY ; ρ April 11, 2012 X = σX Z1 + µX p 2 Y = σY [ρZ1 + 1 − ρ Z2] + µY Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 1 / 22 6.5 Conditional Distributions 6.5 Conditional Distributions General Bivariate Normal - Marginals General Bivariate Normal - Cov/Corr First, lets examine the marginal distributions of X and Y , Second, we can find Cov(X ; Y ) and ρ(X ; Y ) Cov(X ; Y ) = E [(X − E(X ))(Y − E(Y ))] X = σX Z1 + µX h p i = E (σ Z + µ − µ )(σ [ρZ + 1 − ρ2Z ] + µ − µ ) = σX N (0; 1) + µX X 1 X X Y 1 2 Y Y 2 h p 2 i = N (µX ; σX ) = E (σX Z1)(σY [ρZ1 + 1 − ρ Z2]) h 2 p 2 i = σX σY E ρZ1 + 1 − ρ Z1Z2 p 2 2 Y = σY [ρZ1 + 1 − ρ Z2] + µY = σX σY ρE[Z1 ] p 2 = σX σY ρ = σY [ρN (0; 1) + 1 − ρ N (0; 1)] + µY = σ [N (0; ρ2) + N (0; 1 − ρ2)] + µ Y Y Cov(X ; Y ) ρ(X ; Y ) = = ρ = σY N (0; 1) + µY σX σY 2 = N (µY ; σY ) Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 2 / 22 Statistics 104 (Colin Rundel) Lecture 22 April 11, 2012 3 / 22 6.5 Conditional Distributions 6.5 Conditional Distributions General Bivariate Normal - RNG Multivariate Change of Variables Consequently, if we want to generate a Bivariate Normal random variable Let X1;:::; Xn have a continuous joint distribution with pdf f defined of S. -

Laws of Total Expectation and Total Variance
Laws of Total Expectation and Total Variance Definition of conditional density. Assume and arbitrary random variable X with density fX . Take an event A with P (A) > 0. Then the conditional density fXjA is defined as follows: 8 < f(x) 2 P (A) x A fXjA(x) = : 0 x2 = A Note that the support of fXjA is supported only in A. Definition of conditional expectation conditioned on an event. Z Z 1 E(h(X)jA) = h(x) fXjA(x) dx = h(x) fX (x) dx A P (A) A Example. For the random variable X with density function 8 < 1 3 64 x 0 < x < 4 f(x) = : 0 otherwise calculate E(X2 j X ≥ 1). Solution. Step 1. Z h i 4 1 1 1 x=4 255 P (X ≥ 1) = x3 dx = x4 = 1 64 256 4 x=1 256 Step 2. Z Z ( ) 1 256 4 1 E(X2 j X ≥ 1) = x2 f(x) dx = x2 x3 dx P (X ≥ 1) fx≥1g 255 1 64 Z ( ) ( )( ) h i 256 4 1 256 1 1 x=4 8192 = x5 dx = x6 = 255 1 64 255 64 6 x=1 765 Definition of conditional variance conditioned on an event. Var(XjA) = E(X2jA) − E(XjA)2 1 Example. For the previous example , calculate the conditional variance Var(XjX ≥ 1) Solution. We already calculated E(X2 j X ≥ 1). We only need to calculate E(X j X ≥ 1). Z Z Z ( ) 1 256 4 1 E(X j X ≥ 1) = x f(x) dx = x x3 dx P (X ≥ 1) fx≥1g 255 1 64 Z ( ) ( )( ) h i 256 4 1 256 1 1 x=4 4096 = x4 dx = x5 = 255 1 64 255 64 5 x=1 1275 Finally: ( ) 8192 4096 2 630784 Var(XjX ≥ 1) = E(X2jX ≥ 1) − E(XjX ≥ 1)2 = − = 765 1275 1625625 Definition of conditional expectation conditioned on a random variable. -

Probability Cheatsheet V2.0 Thinking Conditionally Law of Total Probability (LOTP)
Probability Cheatsheet v2.0 Thinking Conditionally Law of Total Probability (LOTP) Let B1;B2;B3; :::Bn be a partition of the sample space (i.e., they are Compiled by William Chen (http://wzchen.com) and Joe Blitzstein, Independence disjoint and their union is the entire sample space). with contributions from Sebastian Chiu, Yuan Jiang, Yuqi Hou, and Independent Events A and B are independent if knowing whether P (A) = P (AjB )P (B ) + P (AjB )P (B ) + ··· + P (AjB )P (B ) Jessy Hwang. Material based on Joe Blitzstein's (@stat110) lectures 1 1 2 2 n n A occurred gives no information about whether B occurred. More (http://stat110.net) and Blitzstein/Hwang's Introduction to P (A) = P (A \ B1) + P (A \ B2) + ··· + P (A \ Bn) formally, A and B (which have nonzero probability) are independent if Probability textbook (http://bit.ly/introprobability). Licensed and only if one of the following equivalent statements holds: For LOTP with extra conditioning, just add in another event C! under CC BY-NC-SA 4.0. Please share comments, suggestions, and errors at http://github.com/wzchen/probability_cheatsheet. P (A \ B) = P (A)P (B) P (AjC) = P (AjB1;C)P (B1jC) + ··· + P (AjBn;C)P (BnjC) P (AjB) = P (A) P (AjC) = P (A \ B1jC) + P (A \ B2jC) + ··· + P (A \ BnjC) P (BjA) = P (B) Last Updated September 4, 2015 Special case of LOTP with B and Bc as partition: Conditional Independence A and B are conditionally independent P (A) = P (AjB)P (B) + P (AjBc)P (Bc) given C if P (A \ BjC) = P (AjC)P (BjC). -

Multicollinearity
Chapter 10 Multicollinearity 10.1 The Nature of Multicollinearity 10.1.1 Extreme Collinearity The standard OLS assumption that ( xi1; xi2; : : : ; xik ) not be linearly related means that for any ( c1; c2; : : : ; ck ) xik =6 c1xi1 + c2xi2 + ··· + ck 1xi;k 1 (10.1) − − for some i. If the assumption is violated, then we can find ( c1; c2; : : : ; ck 1 ) such that − xik = c1xi1 + c2xi2 + ··· + ck 1xi;k 1 (10.2) − − for all i. Define x12 ··· x1k xk1 c1 x22 ··· x2k xk2 c2 X1 = 0 . 1 ; xk = 0 . 1 ; and c = 0 . 1 : . B C B C B C B xn2 ··· xnk C B xkn C B ck 1 C B C B C B − C @ A @ A @ A Then extreme collinearity can be represented as xk = X1c: (10.3) We have represented extreme collinearity in terms of the last explanatory vari- able. Since we can always re-order the variables this choice is without loss of generality and the analysis could be applied to any non-constant variable by moving it to the last column. 10.1.2 Near Extreme Collinearity Of course, it is rare, in practice, that an exact linear relationship holds. Instead, we have xik = c1xi1 + c2xi2 + ··· + ck 1xi;k 1 + vi (10.4) − − 133 134 CHAPTER 10. MULTICOLLINEARITY or, more compactly, xk = X1c + v; (10.5) where the v's are small relative to the x's. If we think of the v's as random variables they will have small variance (and zero mean if X includes a column of ones). A convenient way to algebraically express the degree of collinearity is the sample correlation between xik and wi = c1xi1 +c2xi2 +···+ck 1xi;k 1, namely − − cov( xik; wi ) cov( wi + vi; wi ) rx;w = = (10.6) var(xi;k)var(wi) var(wi + vi)var(wi) d d Clearly, as the variancep of vi grows small, thisp value will go to unity. -

Probability Cheatsheet
Probability Cheatsheet v1.1.1 Simpson's Paradox Expected Value, Linearity, and Symmetry P (A j B; C) < P (A j Bc;C) and P (A j B; Cc) < P (A j Bc;Cc) Expected Value (aka mean, expectation, or average) can be thought Compiled by William Chen (http://wzchen.com) with contributions yet still, P (A j B) > P (A j Bc) of as the \weighted average" of the possible outcomes of our random from Sebastian Chiu, Yuan Jiang, Yuqi Hou, and Jessy Hwang. variable. Mathematically, if x1; x2; x3;::: are all of the possible values Material based off of Joe Blitzstein's (@stat110) lectures Bayes' Rule and Law of Total Probability that X can take, the expected value of X can be calculated as follows: P (http://stat110.net) and Blitzstein/Hwang's Intro to Probability E(X) = xiP (X = xi) textbook (http://bit.ly/introprobability). Licensed under CC i Law of Total Probability with partitioning set B1; B2; B3; :::Bn and BY-NC-SA 4.0. Please share comments, suggestions, and errors at with extra conditioning (just add C!) Note that for any X and Y , a and b scaling coefficients and c is our http://github.com/wzchen/probability_cheatsheet. constant, the following property of Linearity of Expectation holds: P (A) = P (AjB1)P (B1) + P (AjB2)P (B2) + :::P (AjBn)P (Bn) Last Updated March 20, 2015 P (A) = P (A \ B1) + P (A \ B2) + :::P (A \ Bn) E(aX + bY + c) = aE(X) + bE(Y ) + c P (AjC) = P (AjB1; C)P (B1jC) + :::P (AjBn; C)P (BnjC) If two Random Variables have the same distribution, even when they are dependent by the property of Symmetry their expected values P (AjC) = P (A \ B jC) + P (A \ B jC) + :::P (A \ B jC) Counting 1 2 n are equal. -

CONDITIONAL EXPECTATION Definition 1. Let (Ω,F,P)
CONDITIONAL EXPECTATION 1. CONDITIONAL EXPECTATION: L2 THEORY ¡ Definition 1. Let (,F ,P) be a probability space and let G be a σ algebra contained in F . For ¡ any real random variable X L2(,F ,P), define E(X G ) to be the orthogonal projection of X 2 j onto the closed subspace L2(,G ,P). This definition may seem a bit strange at first, as it seems not to have any connection with the naive definition of conditional probability that you may have learned in elementary prob- ability. However, there is a compelling rationale for Definition 1: the orthogonal projection E(X G ) minimizes the expected squared difference E(X Y )2 among all random variables Y j ¡ 2 L2(,G ,P), so in a sense it is the best predictor of X based on the information in G . It may be helpful to consider the special case where the σ algebra G is generated by a single random ¡ variable Y , i.e., G σ(Y ). In this case, every G measurable random variable is a Borel function Æ ¡ of Y (exercise!), so E(X G ) is the unique Borel function h(Y ) (up to sets of probability zero) that j minimizes E(X h(Y ))2. The following exercise indicates that the special case where G σ(Y ) ¡ Æ for some real-valued random variable Y is in fact very general. Exercise 1. Show that if G is countably generated (that is, there is some countable collection of set B G such that G is the smallest σ algebra containing all of the sets B ) then there is a j 2 ¡ j G measurable real random variable Y such that G σ(Y ). -

Conditional Expectation and Prediction Conditional Frequency Functions and Pdfs Have Properties of Ordinary Frequency and Density Functions
Conditional expectation and prediction Conditional frequency functions and pdfs have properties of ordinary frequency and density functions. Hence, associated with a conditional distribution is a conditional mean. Y and X are discrete random variables, the conditional frequency function of Y given x is pY|X(y|x). Conditional expectation of Y given X=x is Continuous case: Conditional expectation of a function: Consider a Poisson process on [0, 1] with mean λ, and let N be the # of points in [0, 1]. For p < 1, let X be the number of points in [0, p]. Find the conditional distribution and conditional mean of X given N = n. Make a guess! Consider a Poisson process on [0, 1] with mean λ, and let N be the # of points in [0, 1]. For p < 1, let X be the number of points in [0, p]. Find the conditional distribution and conditional mean of X given N = n. We first find the joint distribution: P(X = x, N = n), which is the probability of x events in [0, p] and n−x events in [p, 1]. From the assumption of a Poisson process, the counts in the two intervals are independent Poisson random variables with parameters pλ and (1−p)λ (why?), so N has Poisson marginal distribution, so the conditional frequency function of X is Binomial distribution, Conditional expectation is np. Conditional expectation of Y given X=x is a function of X, and hence also a random variable, E(Y|X). In the last example, E(X|N=n)=np, and E(X|N)=Np is a function of N, a random variable that generally has an expectation Taken w.r.t. -
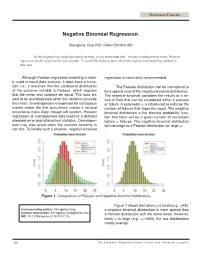
Negative Binomial Regression
STATISTICS COLUMN Negative Binomial Regression Shengping Yang PhD ,Gilbert Berdine MD In the hospital stay study discussed recently, it was mentioned that “in case overdispersion exists, Poisson regression model might not be appropriate.” I would like to know more about the appropriate modeling method in that case. Although Poisson regression modeling is wide- regression is commonly recommended. ly used in count data analysis, it does have a limita- tion, i.e., it assumes that the conditional distribution The Poisson distribution can be considered to of the outcome variable is Poisson, which requires be a special case of the negative binomial distribution. that the mean and variance be equal. The data are The negative binomial considers the results of a se- said to be overdispersed when the variance exceeds ries of trials that can be considered either a success the mean. Overdispersion is expected for contagious or failure. A parameter ψ is introduced to indicate the events where the first occurrence makes a second number of failures that stops the count. The negative occurrence more likely, though still random. Poisson binomial distribution is the discrete probability func- regression of overdispersed data leads to a deflated tion that there will be a given number of successes standard error and inflated test statistics. Overdisper- before ψ failures. The negative binomial distribution sion may also result when the success outcome is will converge to a Poisson distribution for large ψ. not rare. To handle such a situation, negative binomial 0 5 10 15 20 25 0 5 10 15 20 25 Figure 1. Comparison of Poisson and negative binomial distributions. -

Section 1: Regression Review
Section 1: Regression review Yotam Shem-Tov Fall 2015 Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 1 / 58 Contact information Yotam Shem-Tov, PhD student in economics. E-mail: [email protected]. Office: Evans hall room 650 Office hours: To be announced - any preferences or constraints? Feel free to e-mail me. Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 2 / 58 R resources - Prior knowledge in R is assumed In the link here is an excellent introduction to statistics in R . There is a free online course in coursera on programming in R. Here is a link to the course. An excellent book for implementing econometric models and method in R is Applied Econometrics with R. This is my favourite for starting to learn R for someone who has some background in statistic methods in the social science. The book Regression Models for Data Science in R has a nice online version. It covers the implementation of regression models using R . A great link to R resources and other cool programming and econometric tools is here. Yotam Shem-Tov STAT 239A/ PS 236A September 3, 2015 3 / 58 Outline There are two general approaches to regression 1 Regression as a model: a data generating process (DGP) 2 Regression as an algorithm (i.e., an estimator without assuming an underlying structural model). Overview of this slides: 1 The conditional expectation function - a motivation for using OLS. 2 OLS as the minimum mean squared error linear approximation (projections). 3 Regression as a structural model (i.e., assuming the conditional expectation is linear). -

Chapter 3: Expectation and Variance
44 Chapter 3: Expectation and Variance In the previous chapter we looked at probability, with three major themes: 1. Conditional probability: P(A | B). 2. First-step analysis for calculating eventual probabilities in a stochastic process. 3. Calculating probabilities for continuous and discrete random variables. In this chapter, we look at the same themes for expectation and variance. The expectation of a random variable is the long-term average of the ran- dom variable. Imagine observing many thousands of independent random values from the random variable of interest. Take the average of these random values. The expectation is the value of this average as the sample size tends to infinity. We will repeat the three themes of the previous chapter, but in a different order. 1. Calculating expectations for continuous and discrete random variables. 2. Conditional expectation: the expectation of a random variable X, condi- tional on the value taken by another random variable Y . If the value of Y affects the value of X (i.e. X and Y are dependent), the conditional expectation of X given the value of Y will be different from the overall expectation of X. 3. First-step analysis for calculating the expected amount of time needed to reach a particular state in a process (e.g. the expected number of shots before we win a game of tennis). We will also study similar themes for variance. 45 3.1 Expectation The mean, expected value, or expectation of a random variable X is writ- ten as E(X) or µX . If we observe N random values of X, then the mean of the N values will be approximately equal to E(X) for large N. -

Lecture Notes 4 Expectation • Definition and Properties
Lecture Notes 4 Expectation • Definition and Properties • Covariance and Correlation • Linear MSE Estimation • Sum of RVs • Conditional Expectation • Iterated Expectation • Nonlinear MSE Estimation • Sum of Random Number of RVs Corresponding pages from B&T: 81-92, 94-98, 104-115, 160-163, 171-174, 179, 225-233, 236-247. EE 178/278A: Expectation Page 4–1 Definition • We already introduced the notion of expectation (mean) of a r.v. • We generalize this definition and discuss it in more depth • Let X ∈X be a discrete r.v. with pmf pX(x) and g(x) be a function of x. The expectation or expected value of g(X) is defined as E(g(X)) = g(x)pX(x) x∈X • For a continuous r.v. X ∼ fX(x), the expected value of g(X) is defined as ∞ E(g(X)) = g(x)fX(x) dx −∞ • Examples: ◦ g(X)= c, a constant, then E(g(X)) = c ◦ g(X)= X, E(X)= x xpX(x) is the mean of X k k ◦ g(X)= X , E(X ) is the kth moment of X ◦ g(X)=(X − E(X))2, E (X − E(X))2 is the variance of X EE 178/278A: Expectation Page 4–2 • Expectation is linear, i.e., for any constants a and b E[ag1(X)+ bg2(X)] = a E(g1(X)) + b E(g2(X)) Examples: ◦ E(aX + b)= a E(X)+ b ◦ Var(aX + b)= a2Var(X) Proof: From the definition Var(aX + b) = E ((aX + b) − E(aX + b))2 = E (aX + b − a E(X) − b)2 = E a2(X − E(X))2 = a2E (X − E(X))2 = a2Var( X) EE 178/278A: Expectation Page 4–3 Fundamental Theorem of Expectation • Theorem: Let X ∼ pX(x) and Y = g(X) ∼ pY (y), then E(Y )= ypY (y)= g(x)pX(x)=E(g(X)) y∈Y x∈X • The same formula holds for fY (y) using integrals instead of sums • Conclusion: E(Y ) can be found using either fX(x) or fY (y). -

Probabilities, Random Variables and Distributions A
Probabilities, Random Variables and Distributions A Contents A.1 EventsandProbabilities................................ 318 A.1.1 Conditional Probabilities and Independence . ............. 318 A.1.2 Bayes’Theorem............................... 319 A.2 Random Variables . ................................. 319 A.2.1 Discrete Random Variables ......................... 319 A.2.2 Continuous Random Variables ....................... 320 A.2.3 TheChangeofVariablesFormula...................... 321 A.2.4 MultivariateNormalDistributions..................... 323 A.3 Expectation,VarianceandCovariance........................ 324 A.3.1 Expectation................................. 324 A.3.2 Variance................................... 325 A.3.3 Moments................................... 325 A.3.4 Conditional Expectation and Variance ................... 325 A.3.5 Covariance.................................. 326 A.3.6 Correlation.................................. 327 A.3.7 Jensen’sInequality............................. 328 A.3.8 Kullback–LeiblerDiscrepancyandInformationInequality......... 329 A.4 Convergence of Random Variables . 329 A.4.1 Modes of Convergence . 329 A.4.2 Continuous Mapping and Slutsky’s Theorem . 330 A.4.3 LawofLargeNumbers........................... 330 A.4.4 CentralLimitTheorem........................... 331 A.4.5 DeltaMethod................................ 331 A.5 ProbabilityDistributions............................... 332 A.5.1 UnivariateDiscreteDistributions...................... 333 A.5.2 Univariate Continuous Distributions . 335